0. 실습 환경 배포
사전 준비 : AWS 계정, SSH 키 페어, IAM 계정 생성 후 키
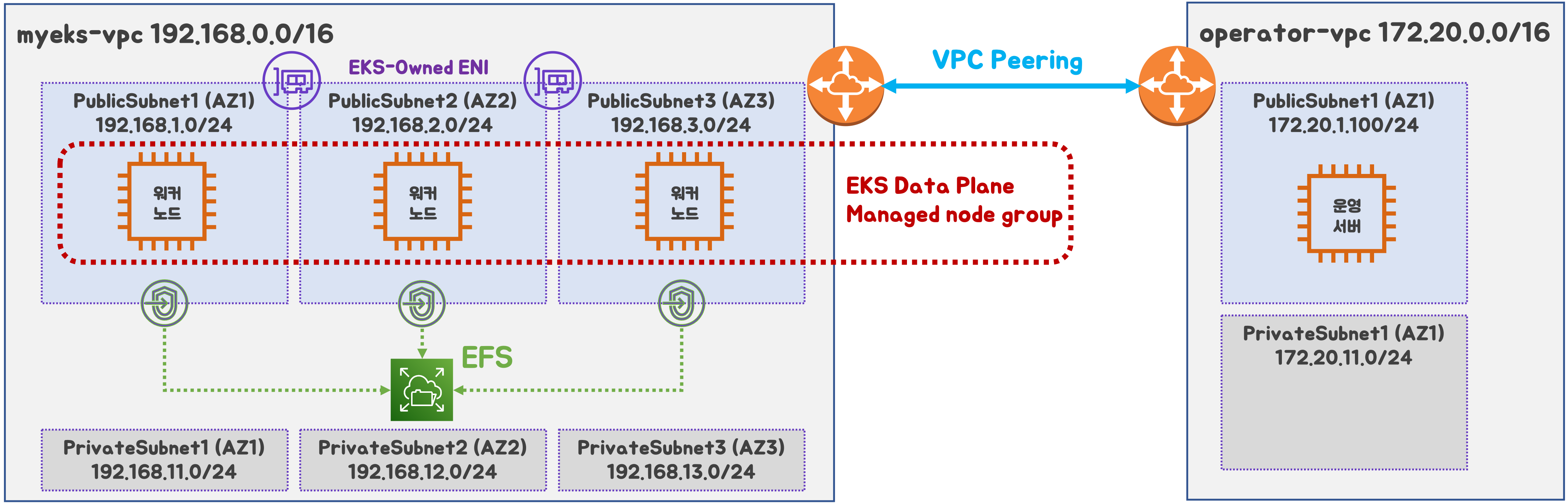
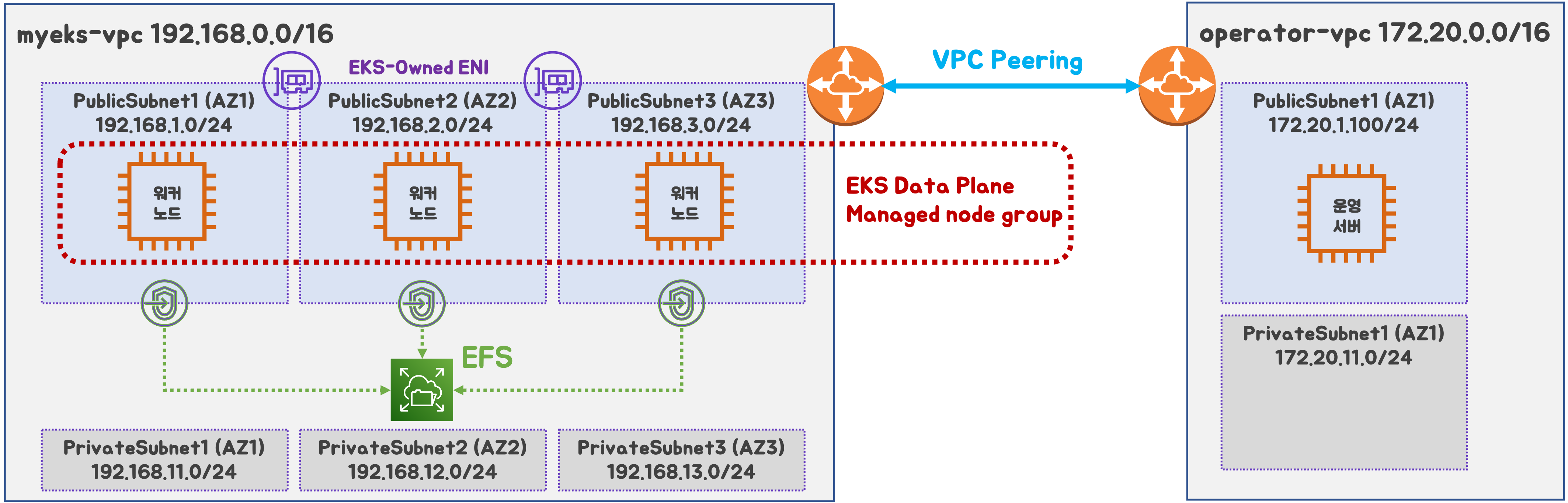
최종 구성도 : 2개의 VPC(EKS 배포, 운영용 구분), 운영서버 EC2, 워커노드 t3.xlarge
 출처 : AEWS 스터디 3기
출처 : AEWS 스터디 3기
- CloudFormation 스택 실행 시 파라미터를 기입하면, 해당 정보가 반영되어 배포
- myeks-vpc 에 각기 AZ를 사용하는 퍼블릭/프라이빗 서브넷 배치
- operator-vpc 에 AZ1를 사용하는 퍼블릭/프라이빗 서브넷 배치 : 172.20.1.100 운영서버 EC2 배포
- 내부 통신을 위한 VPC Peering 배치
1. 배경
Monitoring vs observability(o11y)
(1) Monitoring
- 사전에 정의 된 기준을 기반으로 시스템 상태를 감시
- IT 시스템의 운영 상태를 추적, 성능지표를 수집, 예상치 못한 문제를 조기에 감지하는 과정
- 하드웨어, 소프트웨어의 메트릭 수집하여 정상적으로 동작하는지 확인하고, 문제를 탐지 및 해결하는데 사용 (https://www.techtarget.com/searchitoperations/definition/IT-monitoring)
- 주로 단순하고 잘 알려진 시스템에 적합
- 미리 설계된 임계 값을 초과 하면 알림을 발송하는 방식으로 작동
| 대상 | 내용 |
|---|---|
| 주요 활동 | CPU/ Memory 사용량, 응답시간, 오류율 등의 특정 지표를 지속적으로 측정 |
| 목적 | 시스템 다운타임 방지, 경고를 통하여 빠르게 대응할 수 있도록 함 |
| 빈도 | 연속적 이거나 일정 간격 (일,주,월간)으로 수행 |
(2) Observability
- 수집된 다양한 데이터를 활용하여 예측하지 못했던 문제까지 분석
- 시스템의 내부 상태를 외부 출력 데이터 (로그, 메트릭, 트레이스)를 통해 이해 할수 있는 능력
- 소프트웨어 엔지니어링에서 프로그램 실행, 모듈 내부 상태, 컴포넌트 간 통신 데이터를 수집 하고 분석 (Observability (software) - Wikipedia)
- 현대의 분산 아키텍처 (마이크로서비스, 아키텍처 등)에 필수적이며, 미리 정의되지 않는 질문에 답할 수 있는 유연성을 제공
- 컨텍스트 context(문맥) 정보를 제공
- APM 대신 추적 tracing 이라고 부르며, 계측 instrumentation 과 텔레메트리(telemetry) 라는 용어를 범용적으로 사용함
| 대상 | 내용 |
|---|---|
| 핵심 데이터 | 로그 (이벤트 기록), 메트릭 (수치 데이터), 트레이스 (요청 흐름 추적), 이벤트 |
| 목적 | 복잡한 분산 시스템에서 문제를 진단, 새로운 문제를 탐지, 시스템 동작을 최적화 |
(3) 비교
| 측면 | Monitoring | Observability |
|---|---|---|
| 정의 | 특정 메트릭 추적으로 문제 감지 | 외부 출력 데이터로 시스템 상태 이해 |
| 목표 | 문제 발생 시 감지 및 경고 | 문제 원인 진단 및 시스템 최적화 |
| 데이터 소스 | 미리 정의된 메트릭 (CPU, 메모리 등) | 로그, 메트릭, 트레이스, 이벤트 등 |
| 시스템 유형 | 단순한 시스템, 잘 알려진 파라미터 | 복잡한 분산 시스템, 다중 컴포넌트 |
| 상호작용 방식 | 정적 경고 (임계값 기반) | 동적 쿼리 및 분석 (질문 기반) |
Observability 의 메트릭, 로그,추적 정의
(1) Metrics
- 시스템의 성능, 건강 상태를 수치로 표현한 데이터
- 예) CPU 사용량, 메모리 사용량, 요청 지연시간, 오류율
- 시스템의 전반적인 상태를 확인, 이상 징후를 빠르게 감지 가능
(2) Logs
- 시스템에서 발생한 이벤트를 기록한 텍스트나 구조화된 데이터
- 특정 행동이나 오류가 발생한 시점을 자세히 알수 있어 디버깅에 유용
(3) Tracing
- 분산 시스템의 여러 구성요소를 통해 어떻게 이동하는지 추적
- 요청의 흐름을 시각화하고, 성능 병목 현상을 찾거나 , 여러 서비스에 걸친 문제를 진단하는데 도움을 준다.
SLI, SLO, SLA
(1) SLI (Service Level Indicator, 서비스 수준 지표)
- 서비스의 품질을 정량적으로 측정한 주요지표
- 서비스의 신뢰성과 성능을 평가하는 데 사용되는 실제 측정된 값
- 예시)
- 가용성 : 30일 동안 시스템 가동률 99.9995%
- 웹 서비스 응답 시간 : 100ms 이내의 응답률
- 오류율 : 총 요청 중 오류 응답 (4xx, 5xx) 이 발생한 비율
(2) SLO (Service Level Objective, 서비스 수준 목표)
- 서비스가 유지 해야 하는 자체적인 목표 수준을 정의
- SLI에 대한 기준 선을 설정
- 즉 “이 정도의 성능을 유지” 라는 목표를 의미
- 예시)
- 가용성 : 한달 동안 서비스 가용성 99.9% 이상 유지
- 응답시간 : 모든 요청의 95%는 200ms 이내에 응답
- 오류율 : 한달 이내의 오류율을 0.1% 이하 유지
(3) SLA (Service Level Agreement, 서비스 수준 계약)
- 서비스 공급자와 고객간의 채결된 공식적인 계약으로 서비스 품질을 보장 하는 법적 문서
- 계약 의무 불이행, 위반시 패널티(배상) 이 존재할 수 있다.
- 예시)
- 가용성 : 한달 동안 서비스 가용성 99.9% 미만인 경우, 고객에게 요금의 10% 환불
- 응답시간 : 트랜잭션 응답시간이 500ms 초과하면, 서비스 제공자가 손해 배상
(4) 비교
| 비교 항목 | SLI (서비스 수준 지표) | SLO (서비스 수준 목표) | SLA (서비스 수준 계약) |
|---|---|---|---|
| 정의 | 서비스 성능을 측정하는 실제 값 | 유지해야 하는 성능 목표 | 고객과 맺은 공식 계약 |
| 목적 | 현재 서비스 상태를 모니터링 | 내부적으로 목표 수준을 설정 | 고객과의 계약 보장 |
| 예제 | 99.95%의 가용성 | 99.9% 이상의 가용성 목표 | 99.9% 미만이면 환불 제공 |
| 법적 구속력 | 없음 | 없음 | 있음 |
| 위반 시 결과 | 단순 데이터 측정 | 내부 경고 및 개선 조치 | 보상금 지급, 계약 위반 가능 |
-
k8s API를 통하여 리소스 및 정보를 확인 할수 있음 - Docs permissions
kubectl get ClusterRole | grep eks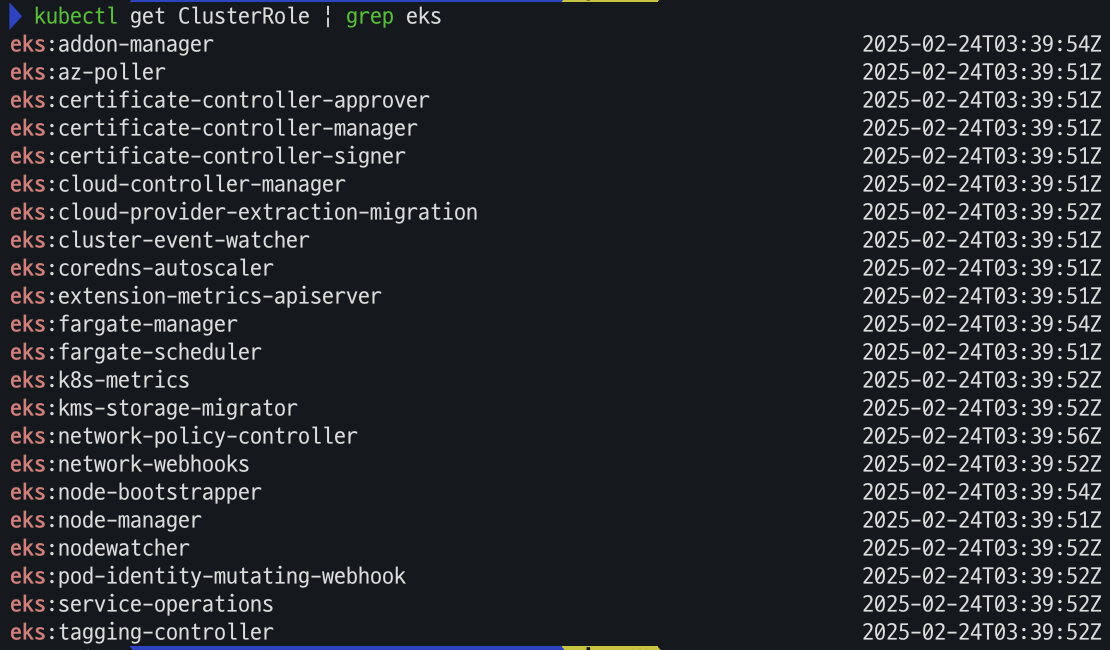
- 클러스터 ARN
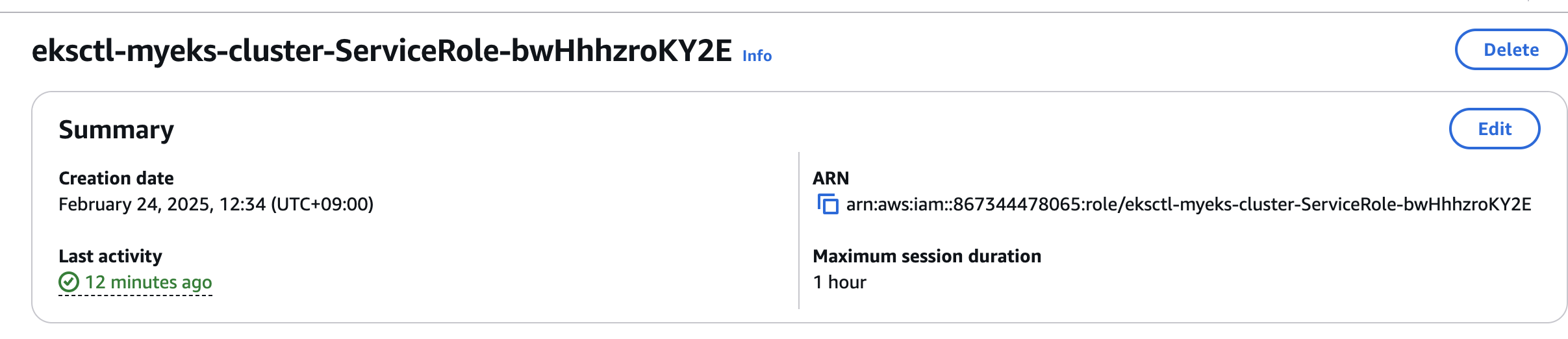
2. Logging in EKS
Control Plane Logging 확인
- Control Plane에서 발생하는 이벤트를 eks 설정에 따라 로그 남기는 것이 가능
- 종류
- Kubernetes API server component logs (
api) –kube-apiserver-<nnn...> - Audit (
audit) –kube-apiserver-audit-<nnn...> - Authenticator (
authenticator) –authenticator-<nnn...> - Controller manager (
controllerManager) –kube-controller-manager-<nnn...> - Scheduler (
scheduler) –kube-scheduler-<nnn...>
- Kubernetes API server component logs (
확인
- 로깅 활성화
# 모든 로깅 활성화 aws eks update-cluster-config --region ap-northeast-2 --name $CLUSTER_NAME \ --logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'
- 로그 그룹 확인
aws logs describe-log-groups | jq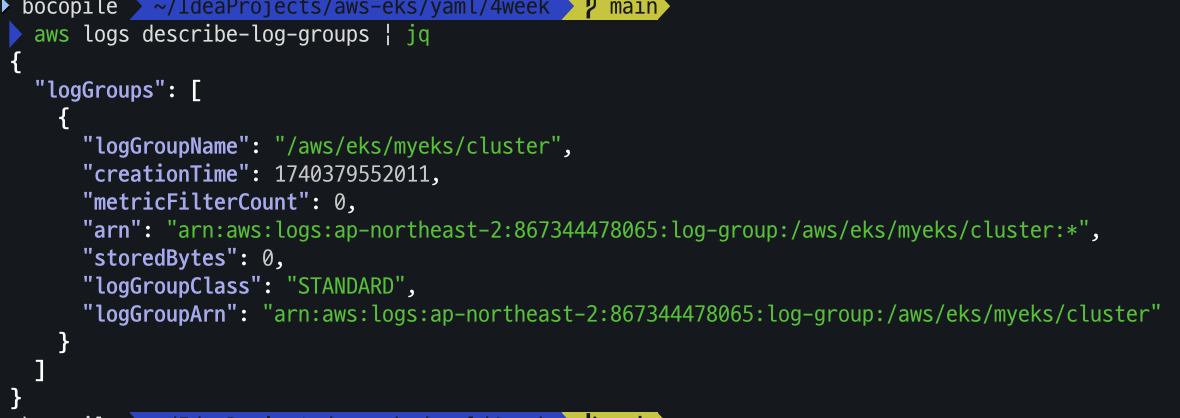
- 로그 tail 명령어 이용
aws logs tail /aws/eks/$CLUSTER_NAME/cluster | more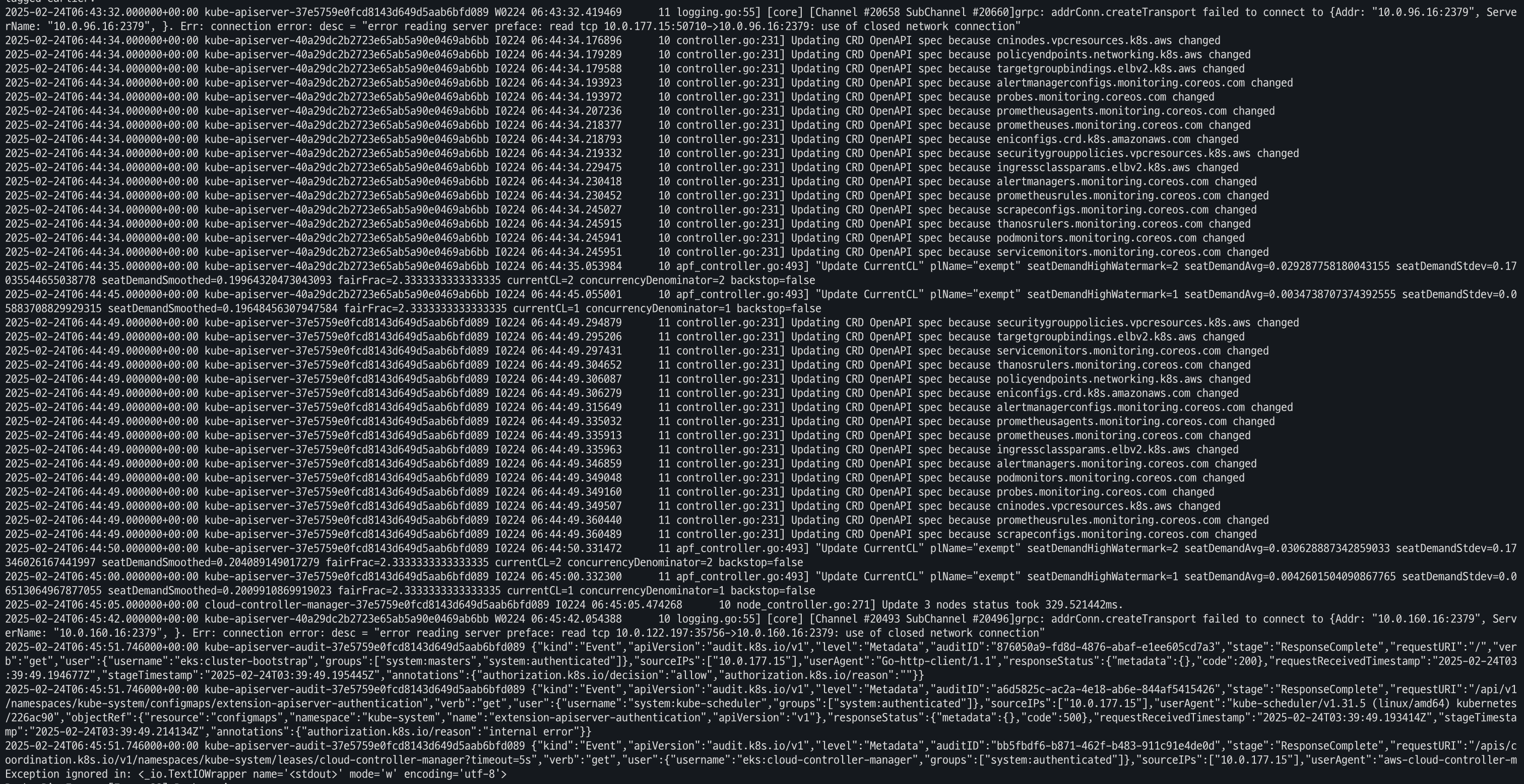
- 신규 로그를 바로 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --follow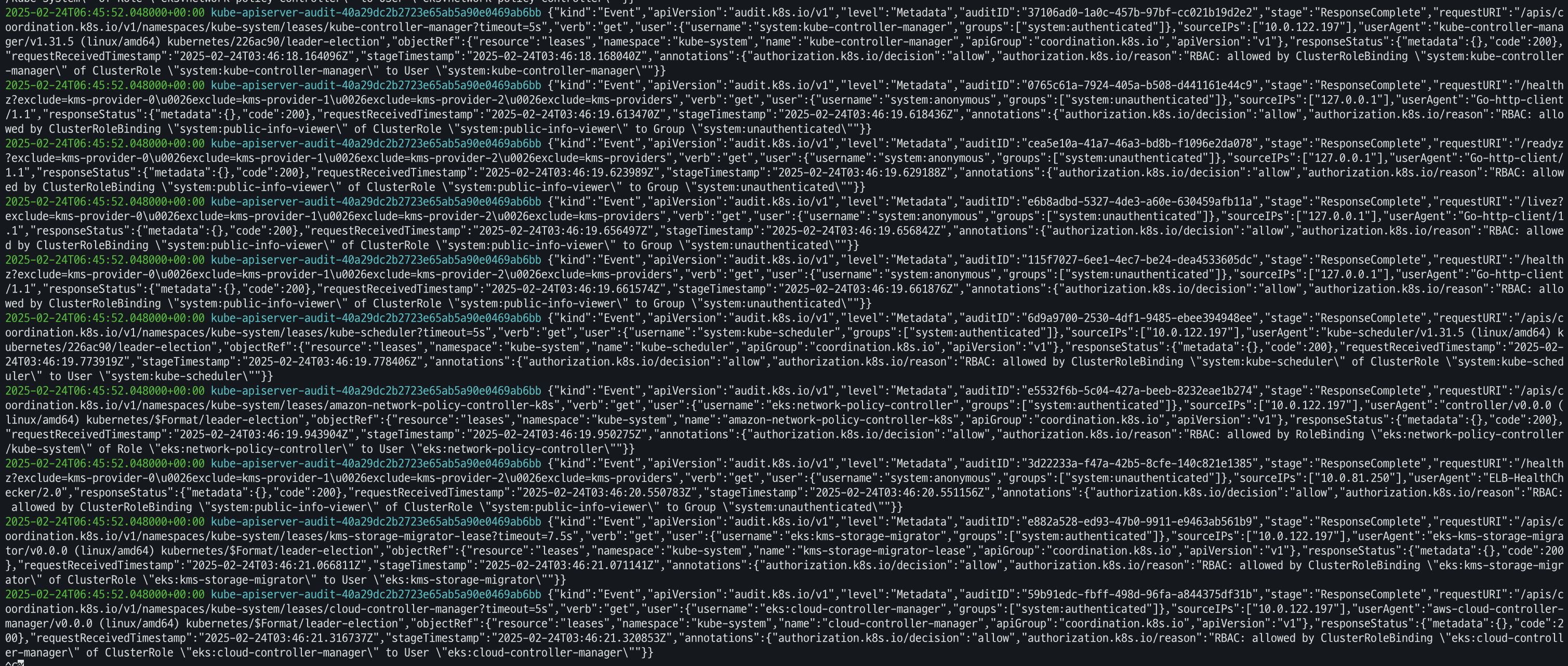
- 필터 패턴
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --filter-pattern <필터 패턴> -> aws logs tail /aws/eks/$CLUSTER_NAME/cluster --filter-pattern kube-apiserver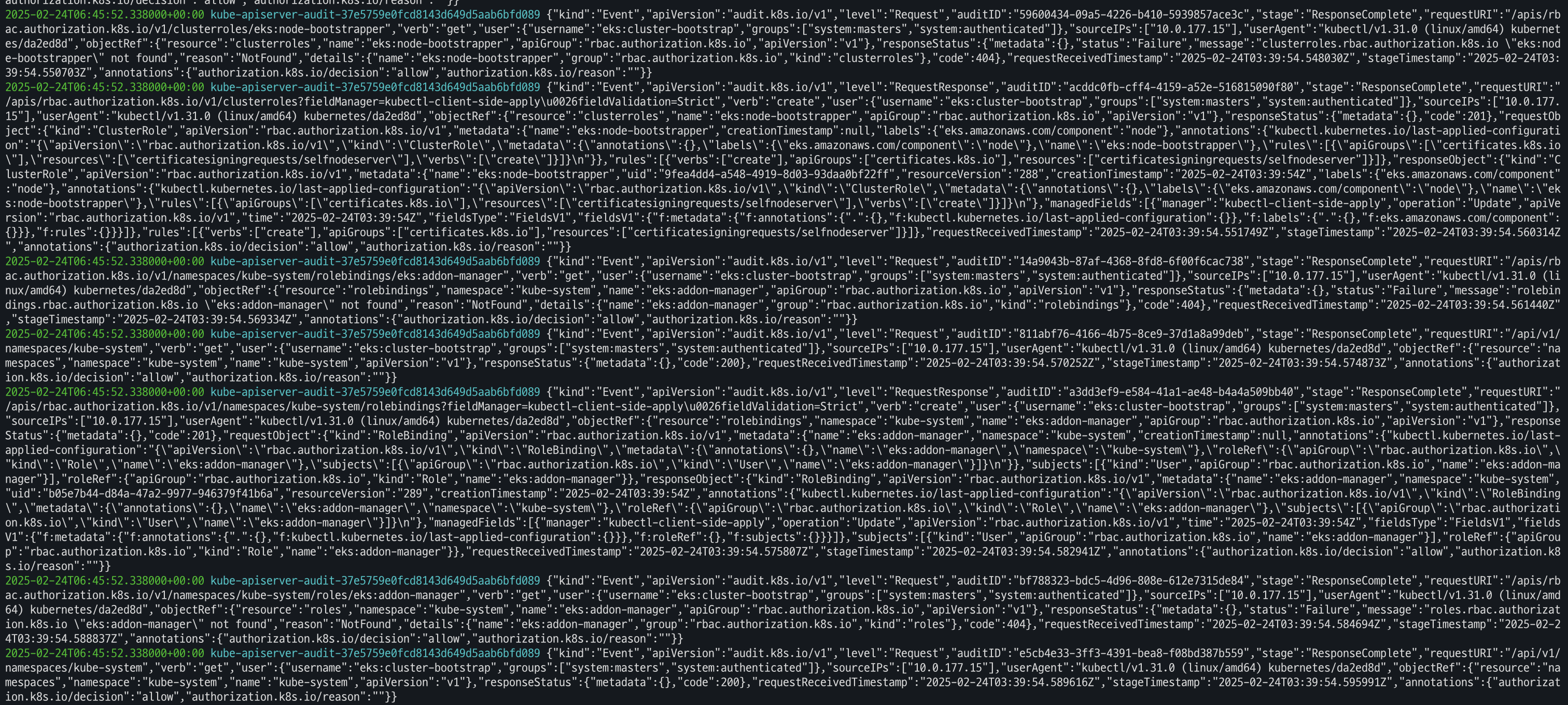
- 로그 스트림 이름
# 로그 스트림이름 aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix <로그 스트림 prefix> --follow aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-apiserver --follow aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-apiserver-audit --follow aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-scheduler --follow aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix authenticator --follow aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-controller-manager --follow aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix cloud-controller-manager --follow
- 시간 지정 (일정 시간 동안의 로깅을 보기 위함)
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m - 짧게 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m --format short
CloudWatch Log Insights
-
AWS Console 에 접속 후 CloudWatch > Log > LogInsight 매뉴 클릭
-
로그 그룹 선택 후 Run query
- EC2 Instance NodeNotReady 상태 로그 검색
# EC2 Instance가 NodeNotRea fields @timestamp, @message | filter @message like /NodeNotReady/ | sort @timestamp desc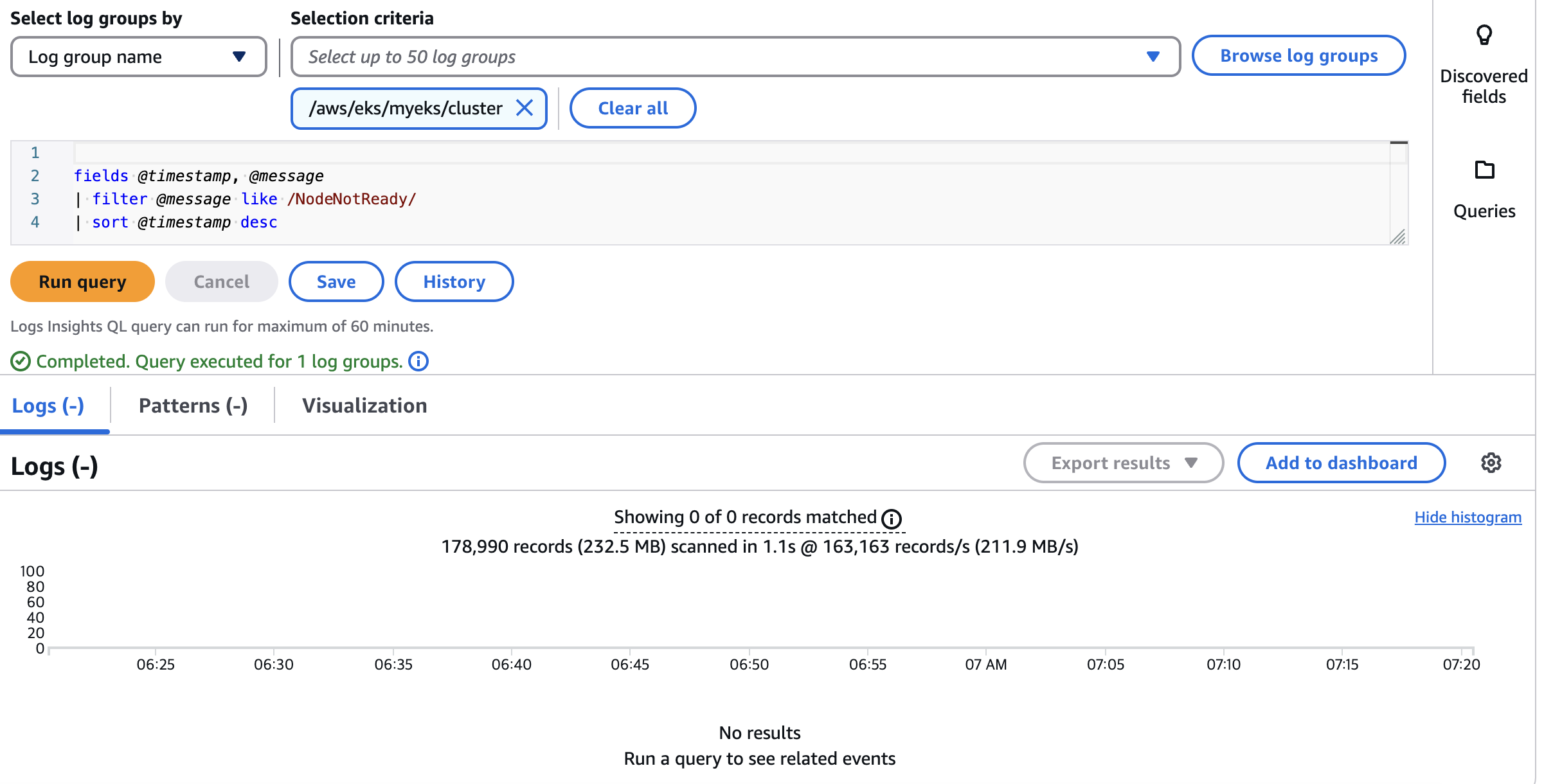
- kube-apiserver-audit 로그에서 userAgent 정렬해서 아래 4개 필드 정보 검색
fields userAgent, requestURI, @timestamp, @message | filter @logStream ~= "kube-apiserver-audit" | stats count(userAgent) as count by userAgent | sort count desc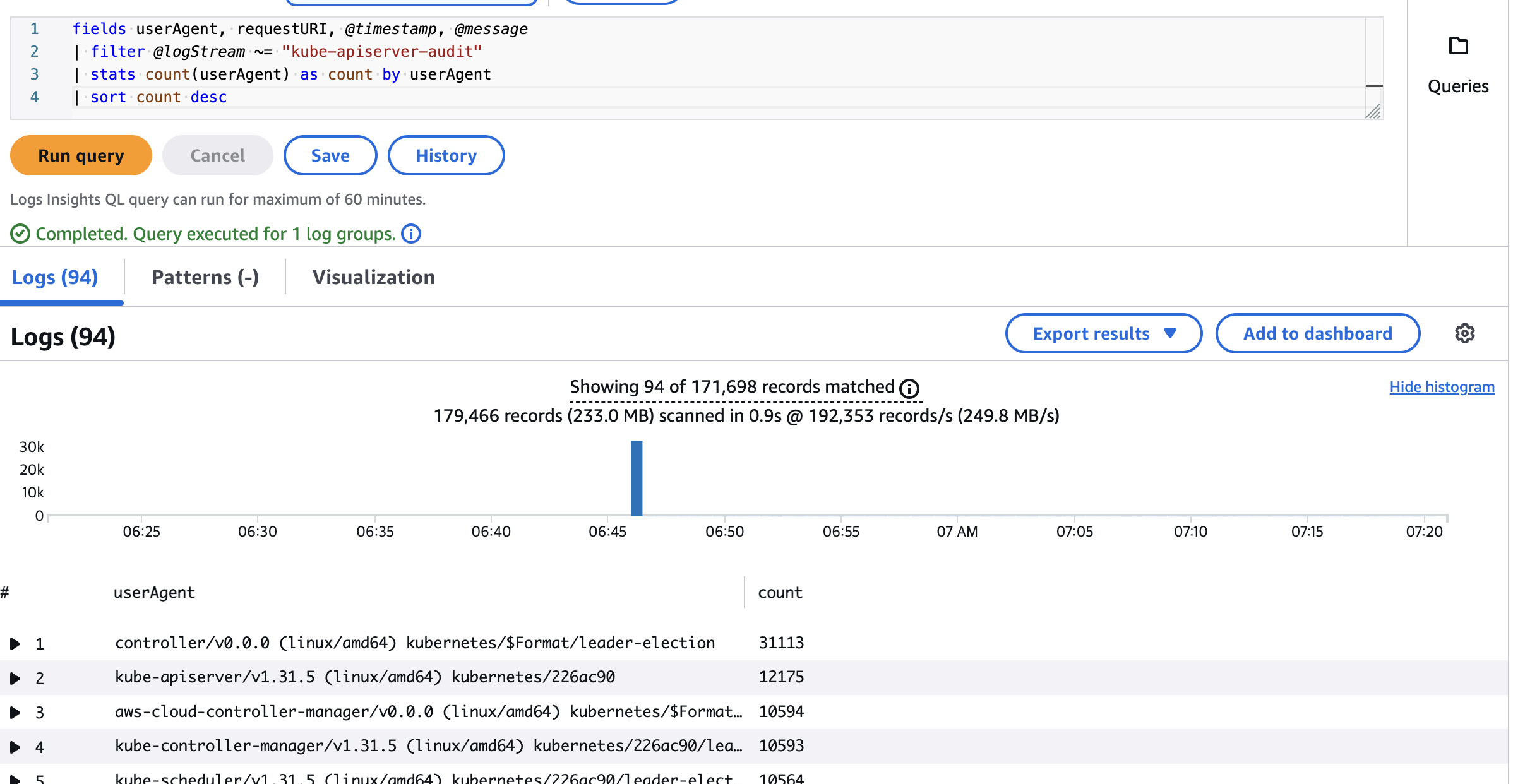
- kube-scheduler 조회
fields @timestamp, @message | filter @logStream ~= "kube-scheduler" | sort @timestamp desc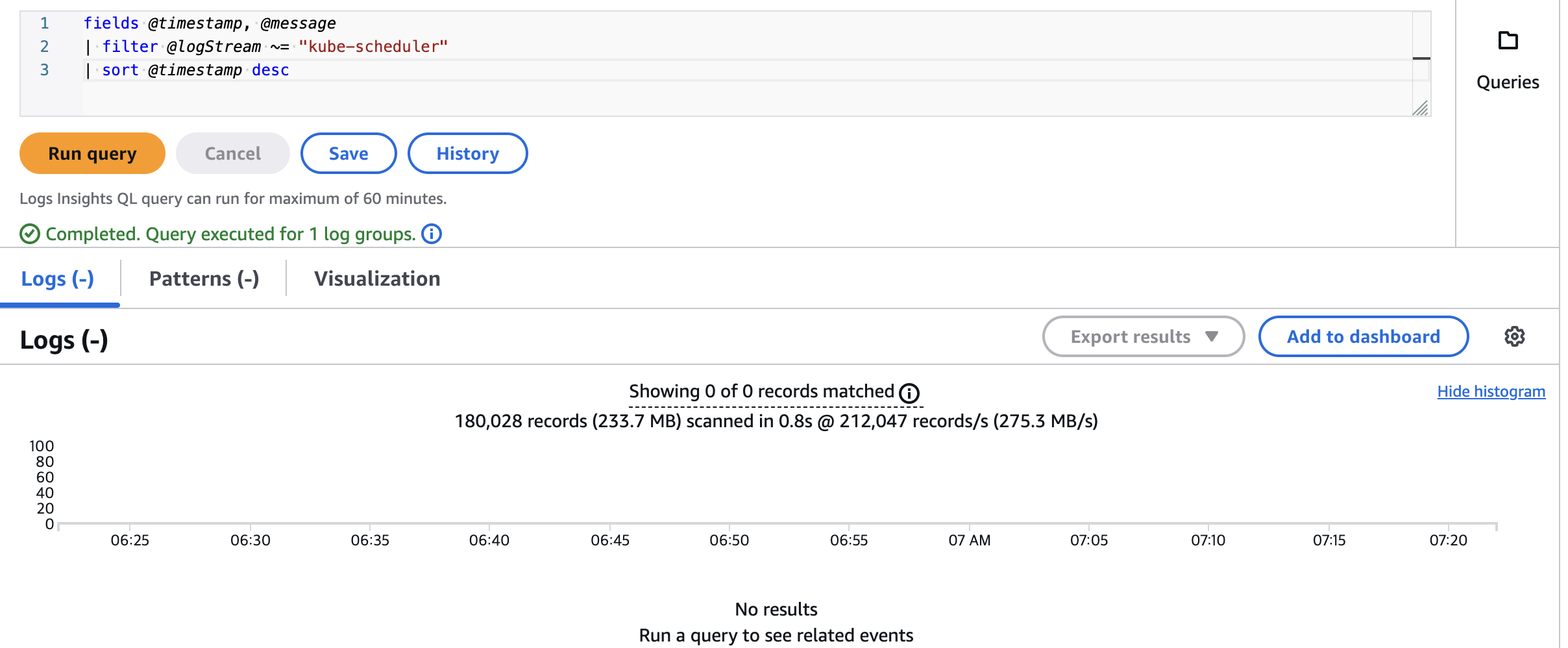
- authenticator 조회
fields @timestamp, @message | filter @logStream ~= "authenticator" | sort @timestamp desc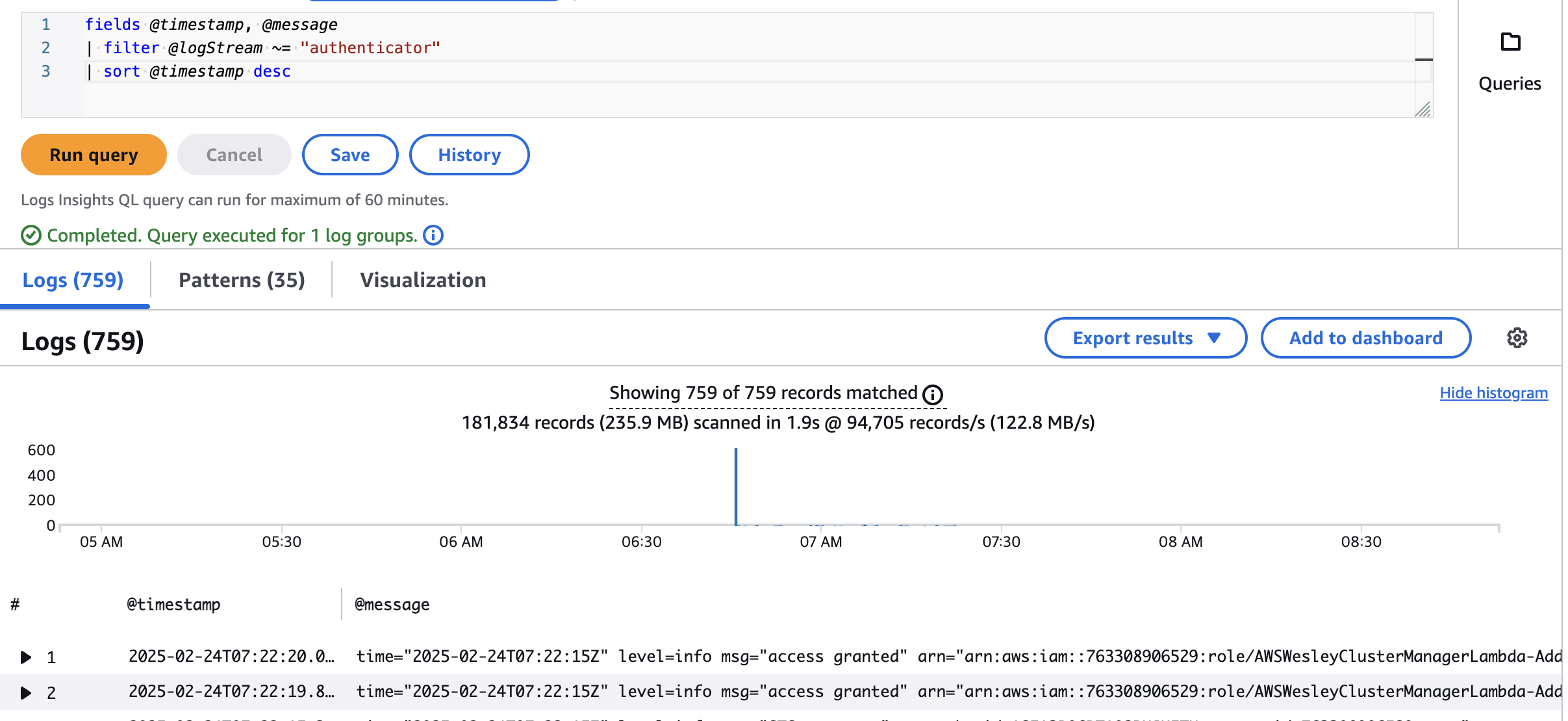
- kube-controller-manager
fields @timestamp, @message | filter @logStream ~= "kube-controller-manager" | sort @timestamp desc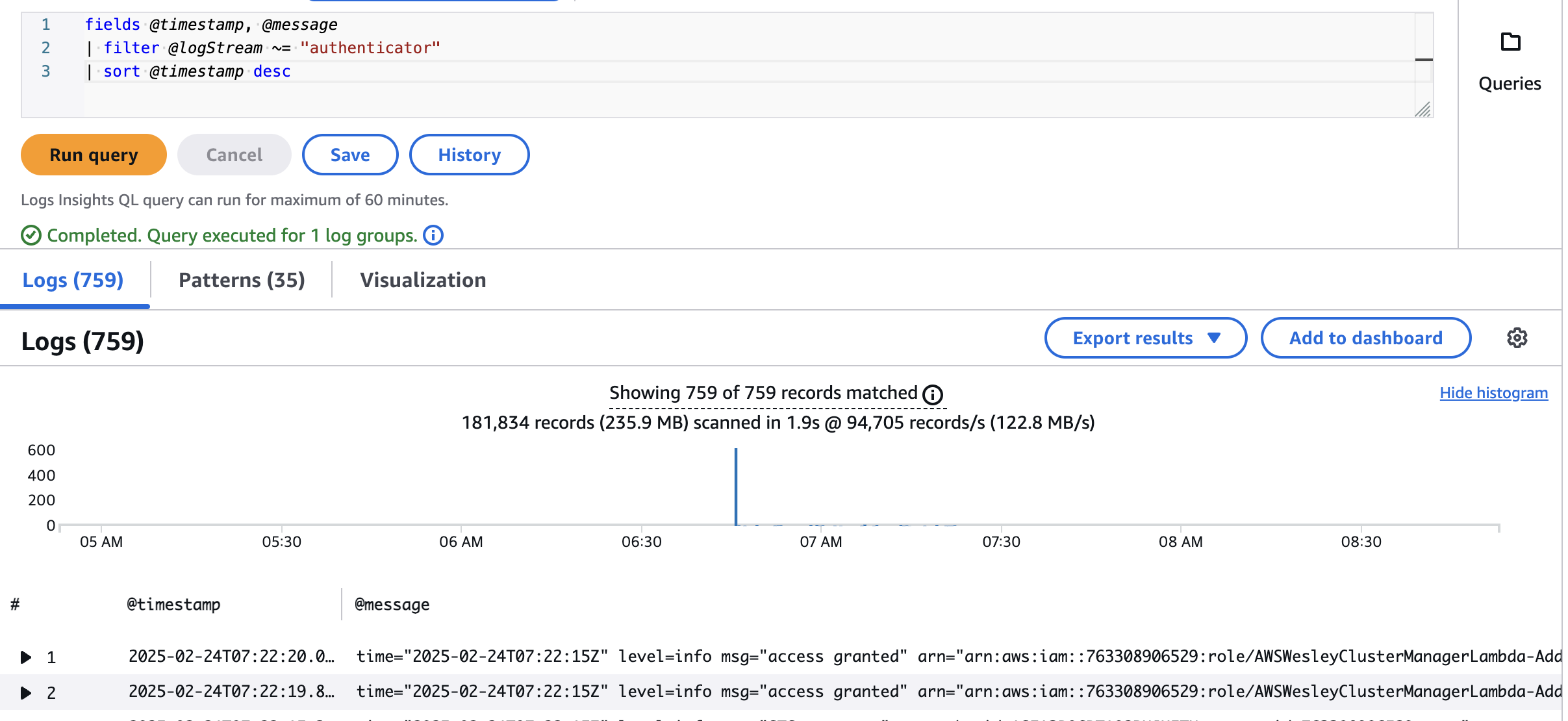
- 로깅 끄기
# EKS Control Plane 로깅(CloudWatch Logs) 비활성화 eksctl utils update-cluster-logging --cluster $CLUSTER_NAME --region ap-northeast-2 --disable-types all --approve # 로그 그룹 삭제 aws logs delete-log-group --log-group-name /aws/eks/$CLUSTER_NAME/cluster
컨테이너 (파드) 로깅
NGINX 웹서버 배포 with Ingress(ALB)
- Nginx 웹서버 배포
# NGINX 웹서버 배포 helm repo add bitnami https://charts.bitnami.com/bitnami helm repo update
- 도메인, 인증서 확인
# 도메인, 인증서 확인 echo $MyDomain $CERT_ARN
- yaml 생성
# 파라미터 파일 생성 cat <<EOT > nginx-values.yaml service: type: NodePort networkPolicy: enabled: false resourcesPreset: "nano" ingress: enabled: true ingressClassName: alb hostname: nginx.$MyDomain pathType: Prefix path: / annotations: alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN alb.ingress.kubernetes.io/group.name: study alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]' alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/ssl-redirect: "443" alb.ingress.kubernetes.io/success-codes: 200-399 alb.ingress.kubernetes.io/target-type: ip EOT
- yaml 파일 확인
cat nginx-values.yaml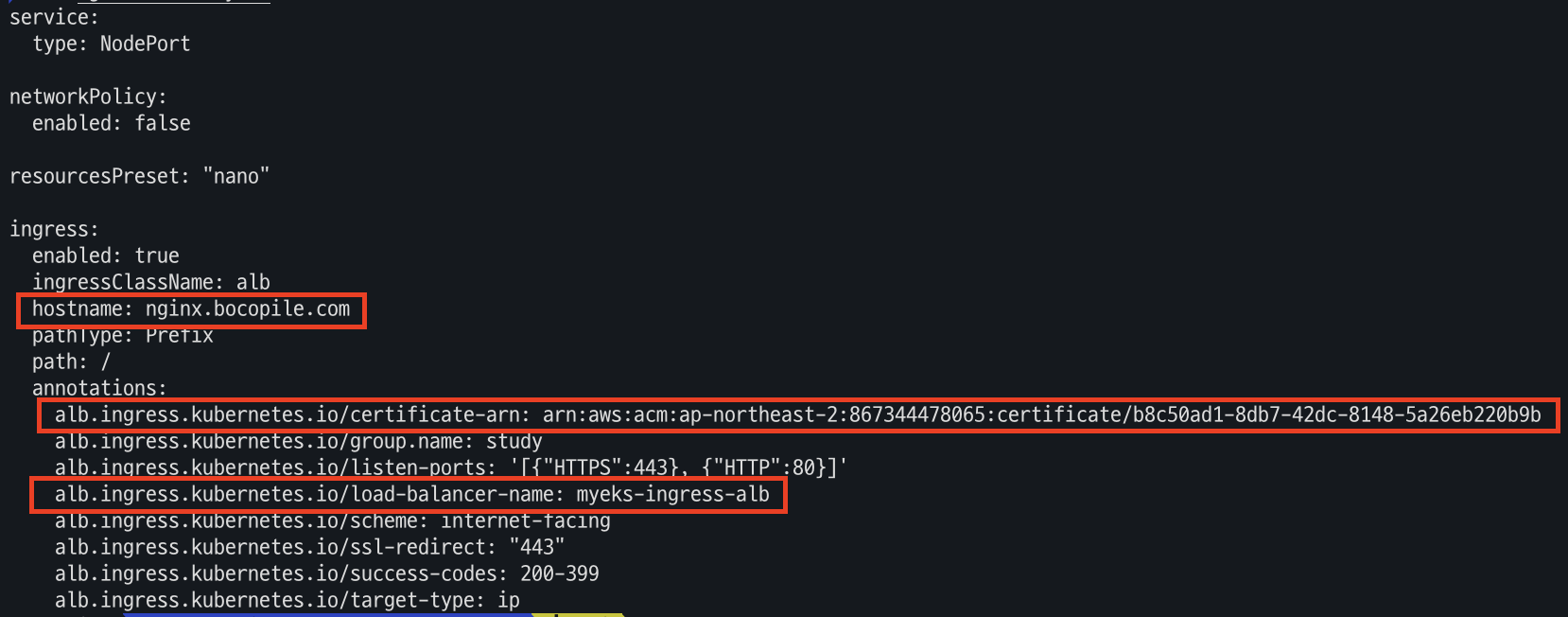
- 배포
**helm install nginx bitnami/nginx --version 19.0.0 -f nginx-values.yaml**
- 확인
# 확인 kubectl get ingress,deploy,svc,ep nginx kubectl describe deploy nginx # Resource - Limits/Requests 확인 kubectl get targetgroupbindings # ALB TG 확인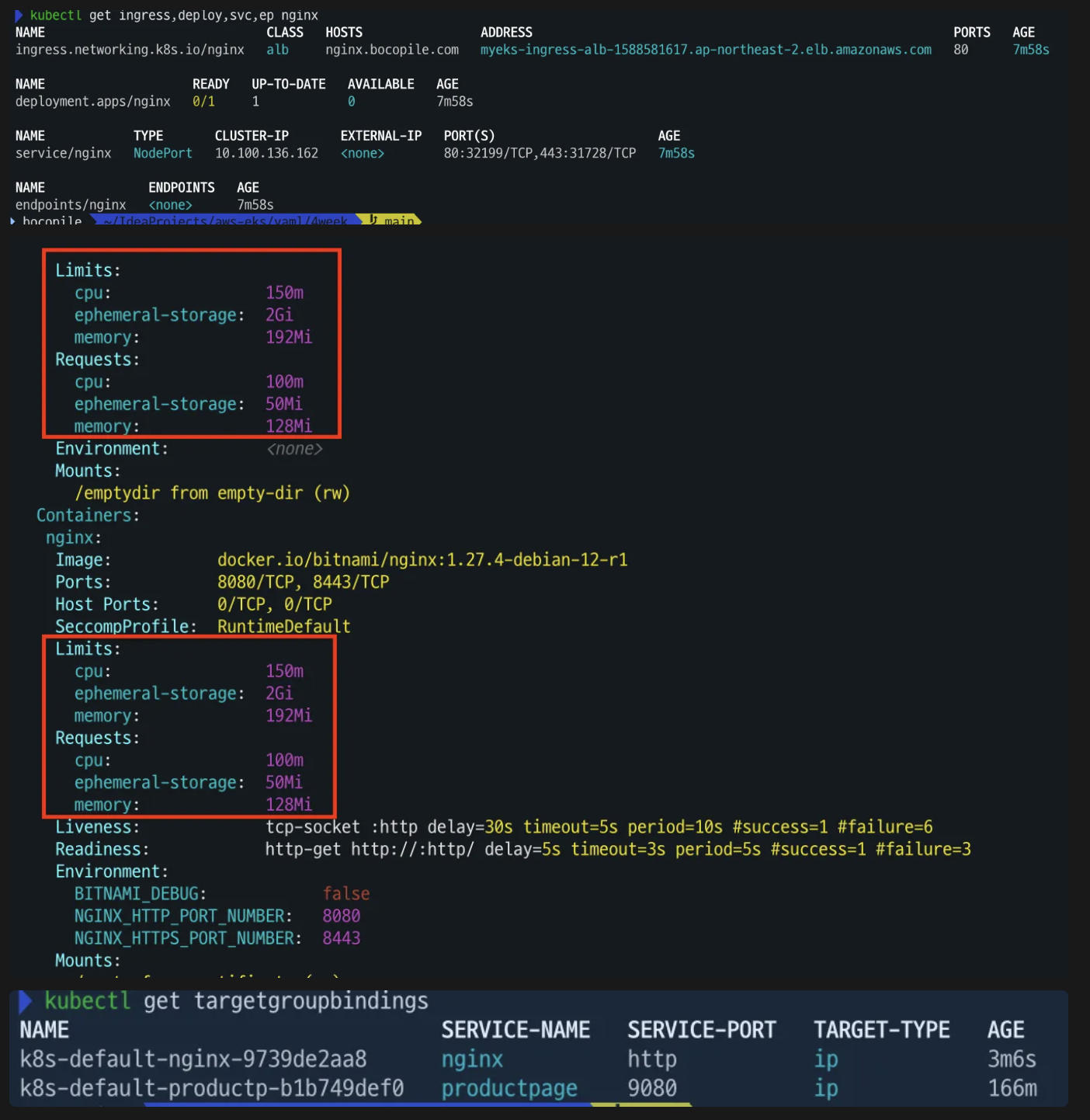
- 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = https://nginx.$MyDomain"

DevOps Engineer