4주차 -2. EKS Observability (Container Insights metrics & Fluent Bit , Metrics-server & kwatch, 프로메테우스 - 스택)
AEWS 3기 스터디
목록 보기
9/18
3. Container Insights metrics in Amazon CloudWatch & Fluent Bit (Logs)
CCI(CloudWatch Container Observability)
주요 기능
- 컨테이너 메트릭 수집
- CPU, 메모리 사용량, 네트워크 트래픽 등의 컨테이너 및 태스크(Task)/파드(Pod) 레벨 메트릭을 모니터링
- Container Insights를 활용하여 자동으로 메트릭 수집 및 시각화
- EKS/Kubernetes 클러스터의 노드, 네임스페이스, 서비스, 파드별 메트릭 모니터링 지원
- 로그 수집 및 분석
- CloudWatch Logs를 통해 컨테이너 로그 수집
- Fluent Bit, AWS FireLens 등의 로그 수집 에이전트와 통합 가능
- Athena, OpenSearch와 연계하여 로그 분석 가능
- 트레이싱 및 프로파일링
- AWS Distro for OpenTelemetry (ADOT) 을 이용해 AWS X-Ray와 연동하여 컨테이너 애플리케이션의 트레이싱 지원
- 요청 지연 시간 및 병목 현상 분석
- 이벤트 기반 경고 및 자동화
- 특정 조건 충족 시 CloudWatch Alarms를 이용한 알림 및 Auto Scaling 트리거
- AWS Lambda 또는 Step Functions과 연동하여 자동 대응 시스템 구축
Fluent Bit
- 경량 로그 및 메트릭 수집, 처리, 전달을 위한 오픈소스 데이터 수집기(Data Collector)
- 주요 특징
- 경량 및 성능 최적화 : 단일 바이너리로 작동하며, 낮은 CPU & 메모리 사용량을 유지
- 다양한 입력(Input) & 출력(Output) 플러그인 지원
- 입력(Input): 로그 파일, TCP/UDP, Kafka, MQTT, Docker, Kubernetes API, Systemd 등
- 출력(Output): Elasticsearch, OpenSearch, Kafka, Splunk, AWS S3, Google Cloud, Fluentd, Prometheus, InfluxDB 등
- 스트리밍 처리 & 필터링 기능
- 실시간으로 로그를 수집, 필터링, 변환 후 다양한 대상에 전달
- JSON 변환, 정규식 기반 필터링, 특정 키 제거/추가 가능
- k8s 친화적
- Kubernetes의 로깅 아키텍처에서 핵심 구성 요소로 활용
kube-apiserver와 통합하여 Pod 메타데이터 자동 태깅
4. Metrics-server & kwatch
Metrics-server 확인
- kubelet으로부터 수집한 리소스 메트릭을 수집 및 집계하는 클러스터 애드온 구성 요소
- cAdvisor : kubelet에 포함된 컨테이너 메트릭을 수집, 집계, 노출하는 데몬
- AWS Add-on에 이미 배포 되어 있으므로 추가적인 배포 불 필요
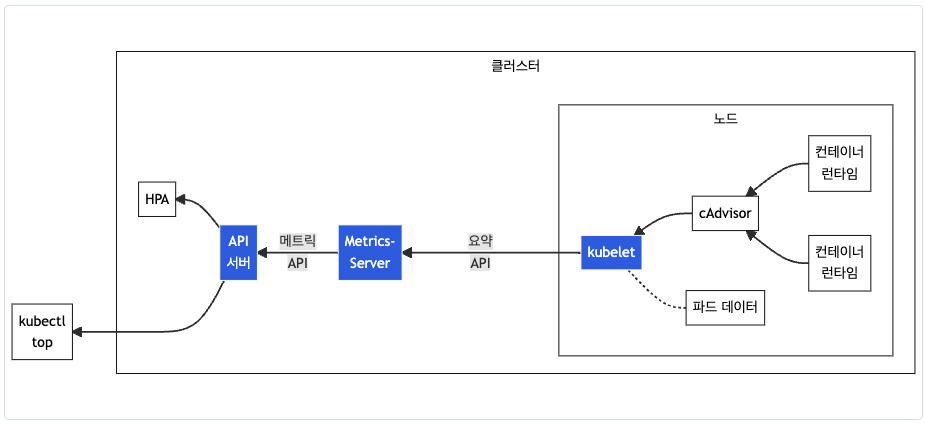 출처 : https://kubernetes.io/ko/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/
출처 : https://kubernetes.io/ko/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/
- 매트릭 서버 확인
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴 kubectl get pod -n kube-system -l app.kubernetes.io/name=metrics-server kubectl api-resources | grep metrics kubectl get apiservices |egrep '(AVAILABLE|metrics)'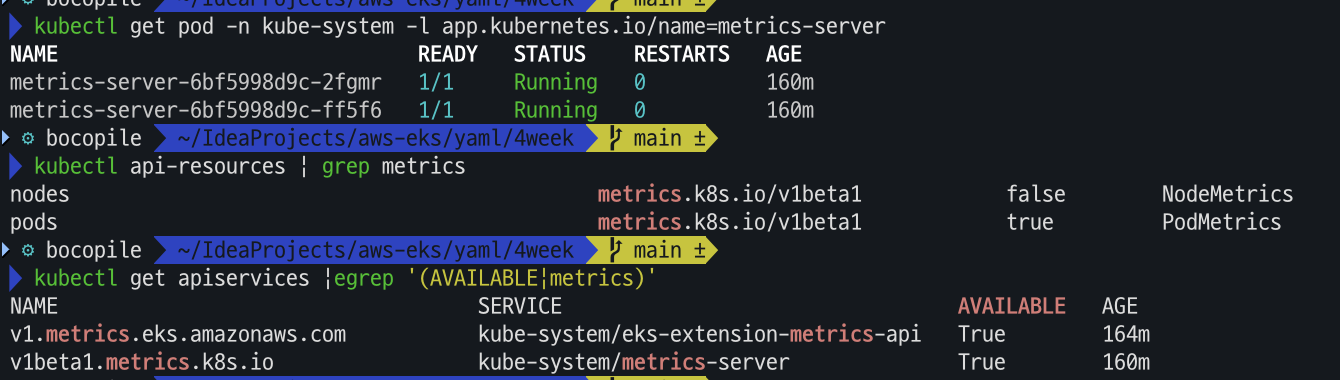
- 노드 메트릭 확인
kubectl top node
- 파드 메트릭 확인
# 노드 메트릭 확인
kubectl top node
# 파드 메트릭 확인
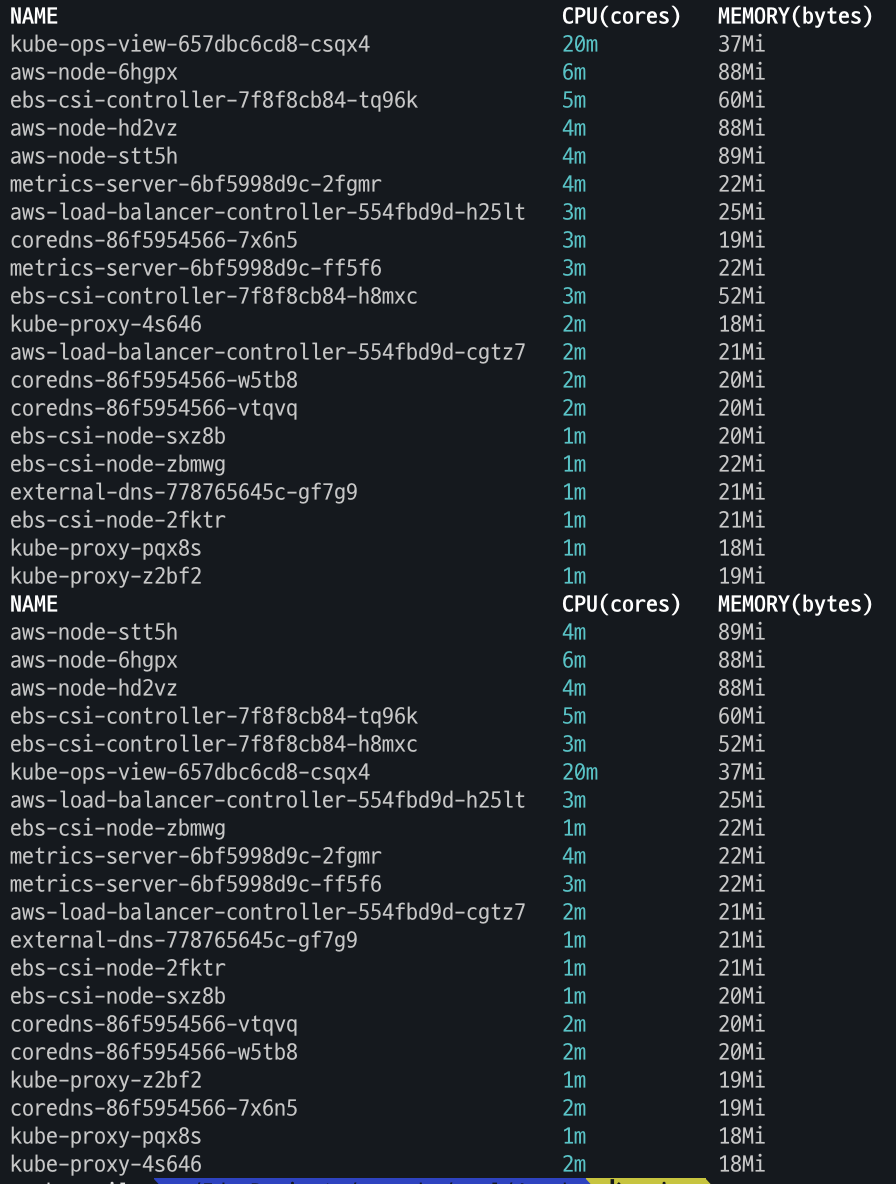
kubectl top pod -A
kubectl top pod -n kube-system --sort-by='cpu'
kubectl top pod -n kube-system --sort-by='memory'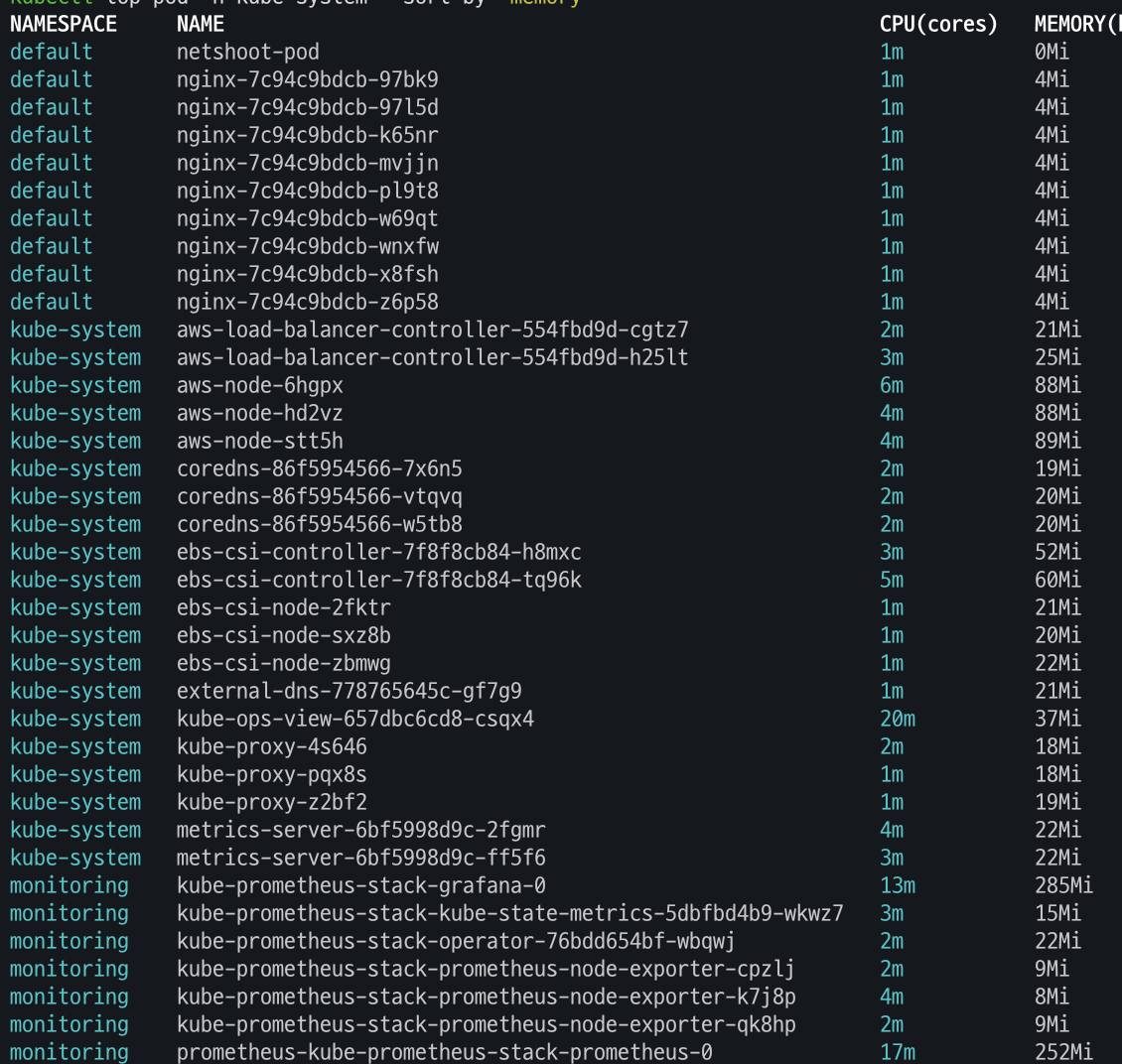
Kwatch 소개
- kwatch는 Kubernetes(K8s) 클러스터의 모든 변경 사항을 모니터링하고, 실행 중인 앱의 충돌을 실시간으로 감지하고, 즐겨찾는 채널(Slack, Discord 등)에 알림을 즉시 게시
설치
# 닉네임
NICK=<각자 자신의 닉네임>
NICK=gjrjr4545
# configmap 생성
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'https://hooks.slack.com/services/########' # slack webhook URL
title: $NICK-eks
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOF
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.5/deploy/deploy.yaml 
- 연동이 완료되면 slack 채널에 다음과 같이 메세지가 발생한다.

- 잘못된 이미지 파드 배포 및 확인
# 터미널1 watch kubectl get pod # 잘못된 이미지 정보의 파드 배포 cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: nginx-19 spec: containers: - name: nginx-pod image: nginx:1.19.19 # 존재하지 않는 이미지 버전 EOF kubectl get events -w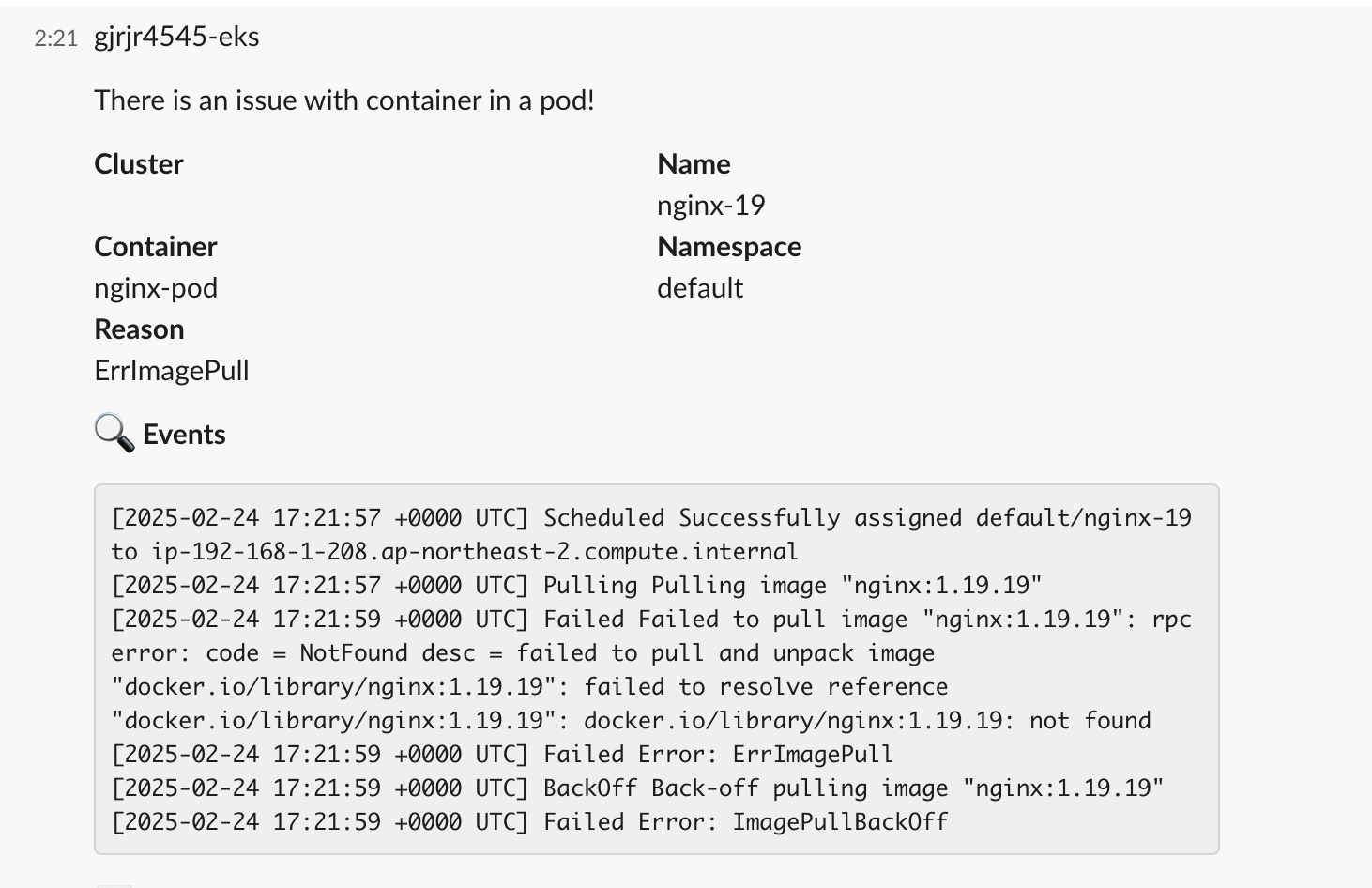
- kwatch 삭제:
kubectl delete -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.5/deploy/deploy.yaml
5. 프로메테우스 - 스택
프로메테우스
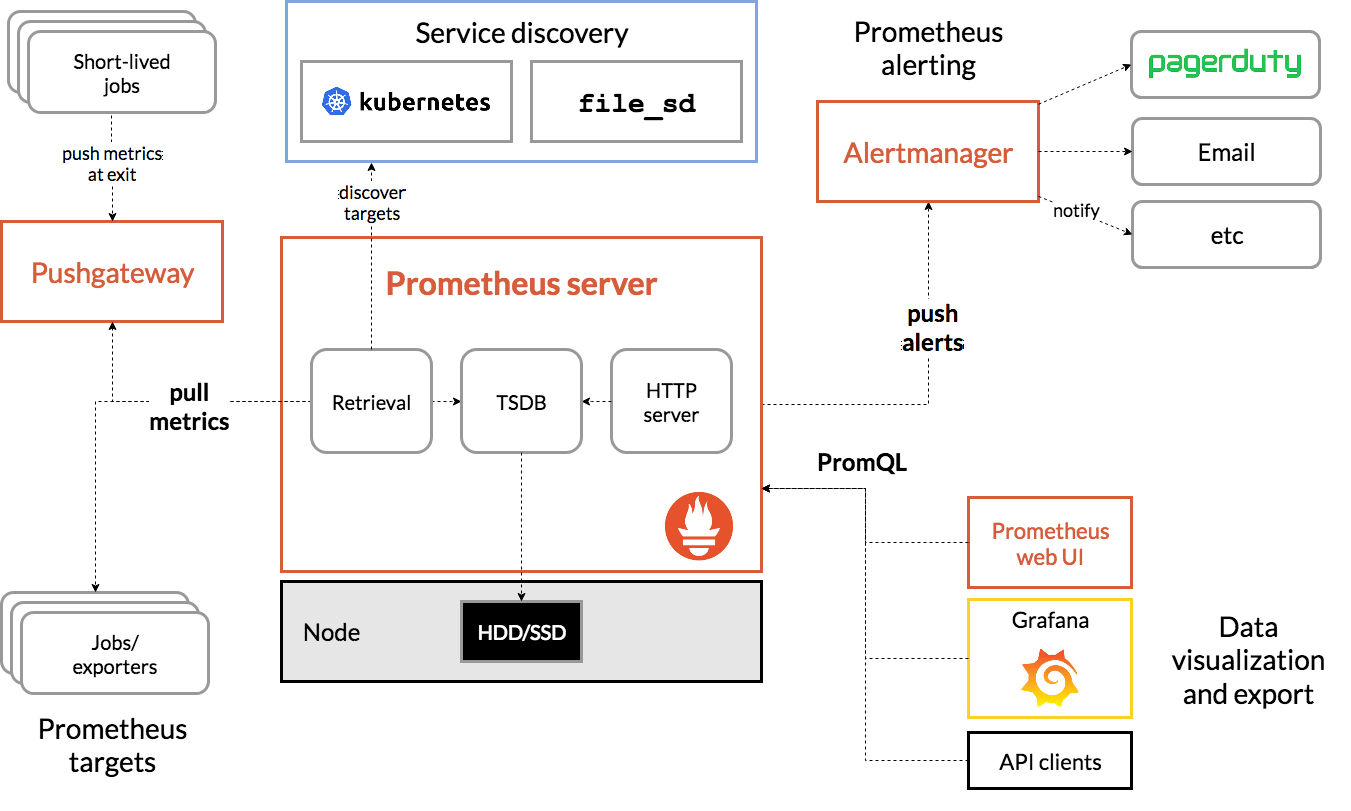 출처 : https://prometheus.io/docs/introduction/overview/
출처 : https://prometheus.io/docs/introduction/overview/
제공 기능
- 다차원 데이터 모델
- 시계열 데이터베이스(TSDB, Time Series Database) 기반
- 메트릭 이름과 key/value 을 통해 식별됨
- PromQL
- 시계열 데이터를 효과적으로 조회할 수 있는 유연한 쿼리 언어
- 분산 스토리지에 의존하지 않음
- 개별 서버 노드가 독립적으로 동작 (Autonomous)
- Pull 기반 데이터 수집
- HTTP를 통해 데이터를 Pull 방식으로 가져옴
- Push 방식 지원
- 직접 Push는 불가능하지만, Pushgateway를 통한 간접적인 Push 지원
- 서비스 디스커버리 또는 정적 설정 기반 타겟 검색
- 모니터링 대상(타겟)을 자동으로 발견하거나 수동으로 설정 가능
- 다양한 시각화 및 대시보드 지원
- Grafana 등과 연동하여 효과적인 데이터 시각화 가능
구성 요소
- Prometheus 서버
- 시계열 데이터를 스크래핑(Scraping) 및 저장하는 핵심 컴포넌트
- 클라이언트 라이브러리 (Client Libraries)
- 애플리케이션을 모니터링할 수 있도록 코드 계측(Instrumentation) 지원
- Push Gateway
- 단기 실행(Short-lived) 작업의 메트릭을 수집할 수 있도록 지원
- 직접 Push 방식 지원이 아닌 게이트웨이를 통해 간접적으로 Push
- Exporters
- 외부 시스템(HAProxy, StatsD, Graphite 등)의 메트릭을 Prometheus 형식으로 변환
- Alertmanager
- 설정된 규칙에 따라 경고(Alert)를 관리하고 알림을 전송
- 기타 지원 도구
- 데이터 시각화, 관리 및 디버깅을 위한 다양한 도구 포함
프로메테우스-스택 설치
-
모니터링에 필요한 여러 요소를 단일 차트(스택)으로 제공 ← 시각화(그라파나), 이벤트 메시지 정책(경고 임계값/수준) 등
- 배포
# 모니터링 watch kubectl get pod,pvc,svc,ingress -n monitoring # repo 추가 helm repo add prometheus-community https://prometheus-community.github.io/helm-charts # 파라미터 파일 생성 cat <<EOT > monitor-values.yaml prometheus: prometheusSpec: scrapeInterval: "15s" evaluationInterval: "15s" podMonitorSelectorNilUsesHelmValues: false serviceMonitorSelectorNilUsesHelmValues: false retention: 5d retentionSize: "10GiB" storageSpec: volumeClaimTemplate: spec: storageClassName: gp3 accessModes: ["ReadWriteOnce"] resources: requests: storage: 30Gi ingress: enabled: true ingressClassName: alb hosts: - prometheus.$MyDomain paths: - /* annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: ip alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]' alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN alb.ingress.kubernetes.io/success-codes: 200-399 alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb alb.ingress.kubernetes.io/group.name: study alb.ingress.kubernetes.io/ssl-redirect: '443' grafana: defaultDashboardsTimezone: Asia/Seoul adminPassword: prom-operator ingress: enabled: true ingressClassName: alb hosts: - grafana.$MyDomain paths: - /* annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: ip alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]' alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN alb.ingress.kubernetes.io/success-codes: 200-399 alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb alb.ingress.kubernetes.io/group.name: study alb.ingress.kubernetes.io/ssl-redirect: '443' persistence: enabled: true type: sts storageClassName: "gp3" accessModes: - ReadWriteOnce size: 20Gi alertmanager: enabled: false defaultRules: create: false kubeControllerManager: enabled: false kubeEtcd: enabled: false kubeScheduler: enabled: false prometheus-windows-exporter: prometheus: monitor: enabled: false EOT cat monitor-values.yaml # 배포 helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 69.3.1 \ -f monitor-values.yaml --create-namespace --namespace monitoring-
확인
# 확인 helm list -n monitoring kubectl get sts,ds,deploy,pod,svc,ep,ingress,pvc,pv -n monitoring kubectl get-all -n monitoring kubectl get prometheus,servicemonitors -n monitoring kubectl get crd | grep monitoring kubectl df-pv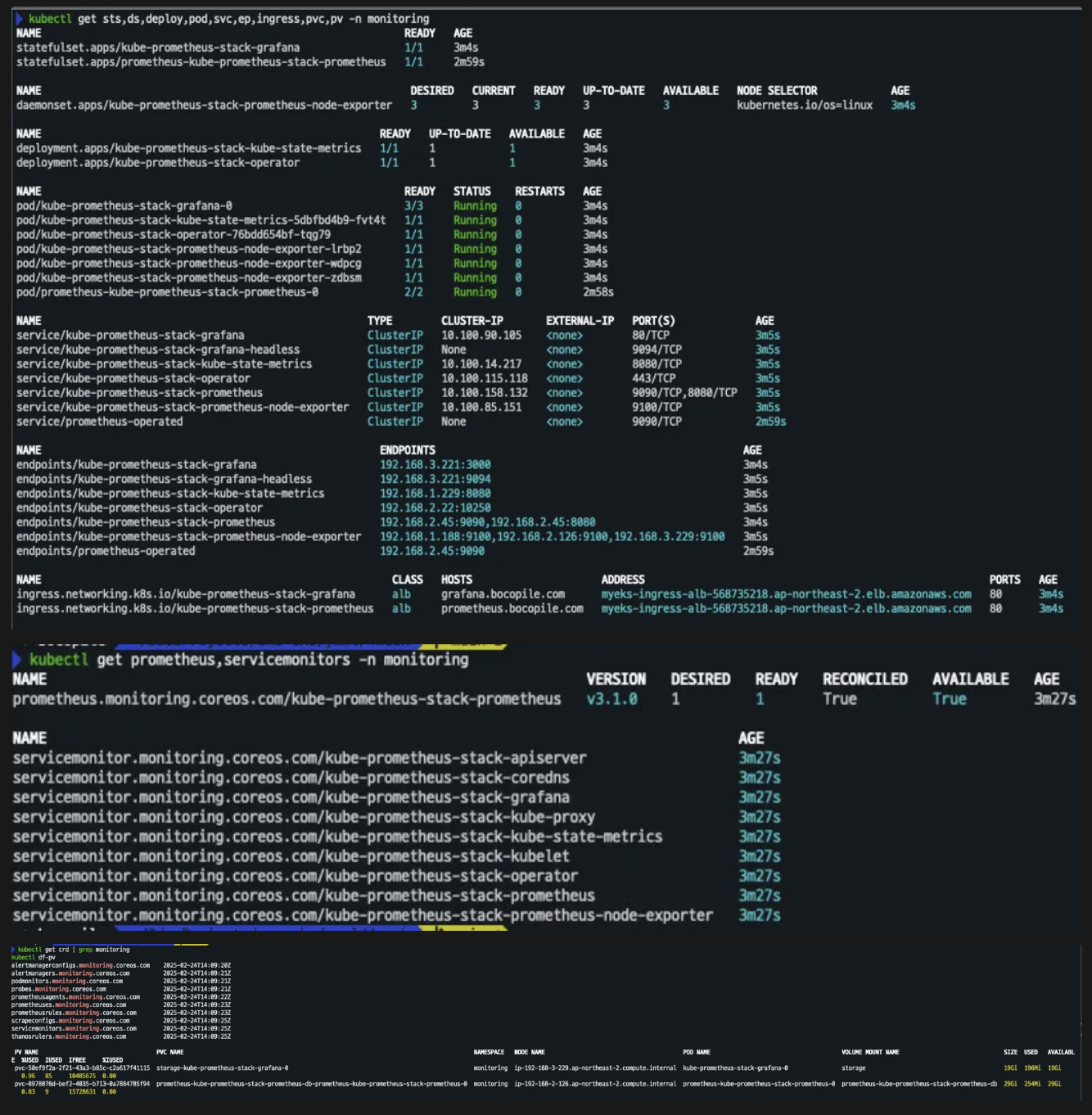
-
버전 확인 및 웹 접속
# 프로메테우스 버전 확인 echo -e "https://prometheus.$MyDomain/api/v1/status/buildinfo" open https://prometheus.$MyDomain/api/v1/status/buildinfo # macOS kubectl exec -it sts/prometheus-kube-prometheus-stack-prometheus -n monitoring -c prometheus -- prometheus --version # 프로메테우스 웹 접속 echo -e "https://prometheus.$MyDomain" open "https://prometheus.$MyDomain" # macOS # 그라파나 웹 접속 echo -e "https://grafana.$MyDomain" open "https://grafana.$MyDomain" # macOS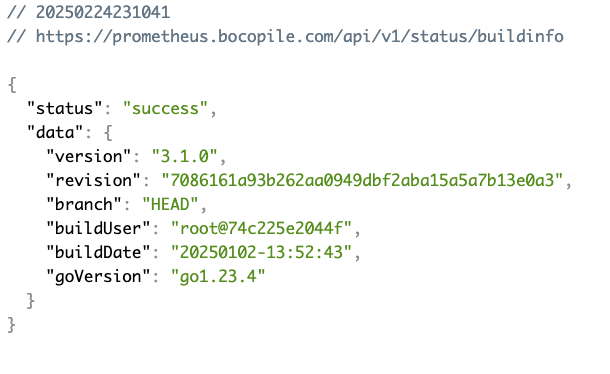

프로메테우스 기본 사용
- 모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출
- 이후 프로메테우스는 해당 경로에 http get 방식으로 메트릭 정보를 가져와 TSDB 형식으로 저장
# 아래 처럼 프로메테우스가 각 서비스의 포트 접속하여 메트릭 정보를 수집
kubectl get node -owide
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter
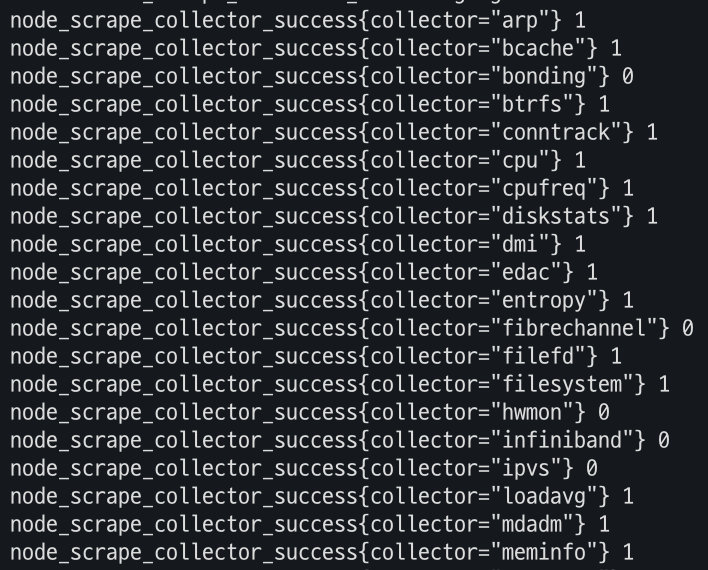
# (노드 익스포터 경우) 노드의 9100번 포트의 /metrics 접속 시 다양한 메트릭 정보를 확인할수 있음 : 마스터 이외에 워커노드도 확인 가능
ssh ec2-user@$N1 curl -s localhost:**9100**/metrics
-
프로메테우스 ingress 도메인으로 웹 접속
-
Ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-prometheus kubectl describe ingress -n monitoring kube-prometheus-stack-prometheus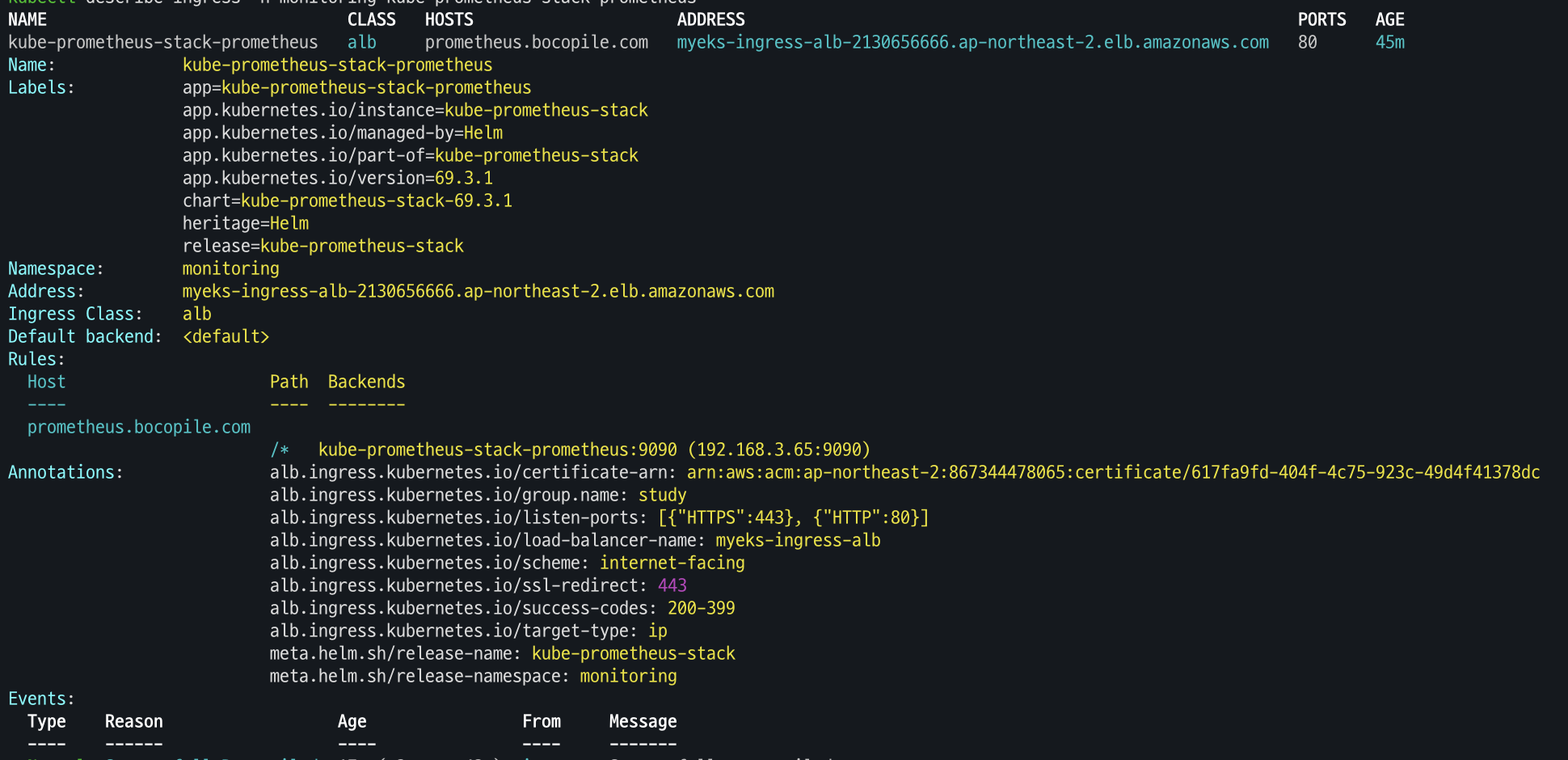
-
Web 접속
echo -e "Prometheus Web URL = https://prometheus.$MyDomain" open "https://prometheus.$MyDomain"
-
웹 상단 주요 매뉴
- 쿼리(Query) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회
- 경고(Alerts) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
- 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인 > 버전 정보
-
Node-Exporter , kube-state-metrics , kube-proxy
Node-Exporter
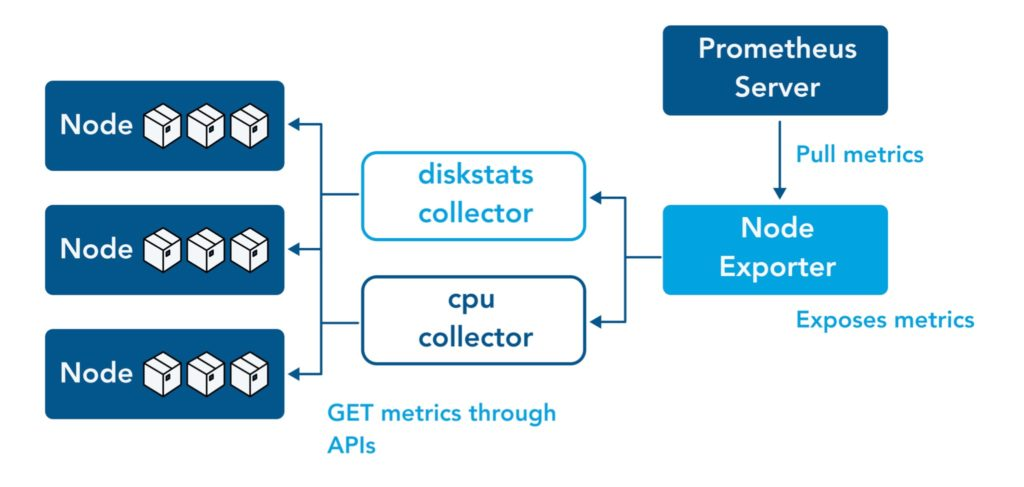 출처 : https://www.opsramp.com/guides/prometheus-monitoring/prometheus-node-exporter/
출처 : https://www.opsramp.com/guides/prometheus-monitoring/prometheus-node-exporter/
-
/proc, /sys 정보
# Table 아래 쿼리 입력 후 Execute 클릭 -> Graph 확인 ## 출력되는 메트릭 정보는 node-exporter 를 통해서 노드에서 수집된 정보 node_memory_Active_bytes # 특정 노드(인스턴스) 필터링 : 아래 IP는 출력되는 자신의 인스턴스 PrivateIP 입력 후 Execute 클릭 -> Graph 확인 node_memory_Active_bytes{instance="192.168.1.208:9100"}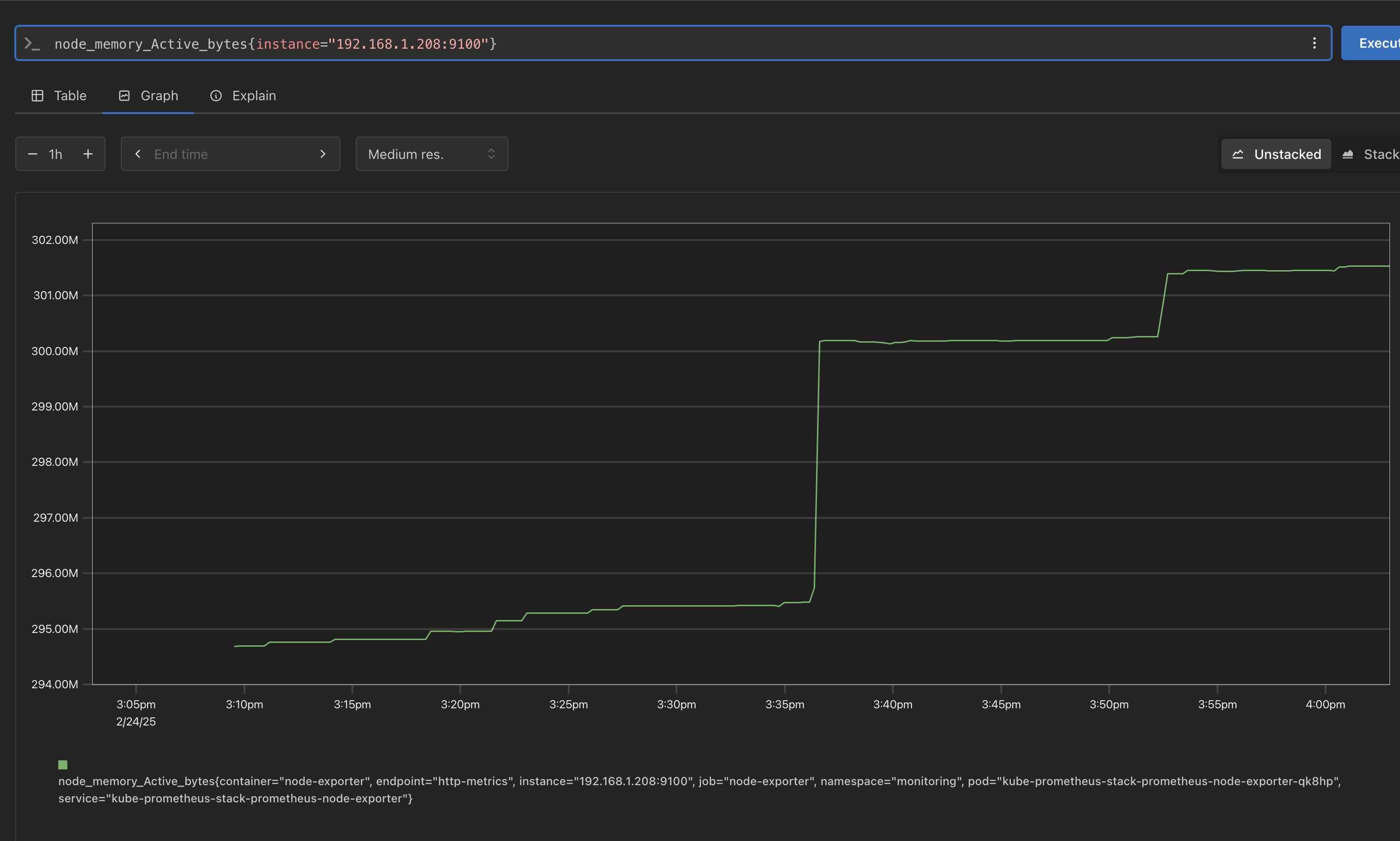
kube-state-metrics (ksm)
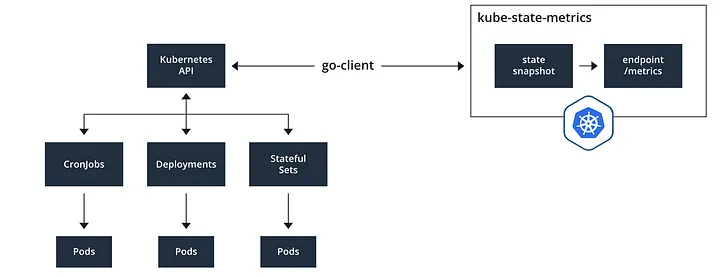 출처 : https://medium.com/@seifeddinerajhi/monitoring-kubernetes-clusters-with-kube-state-metrics-2b9e73a67895
출처 : https://medium.com/@seifeddinerajhi/monitoring-kubernetes-clusters-with-kube-state-metrics-2b9e73a67895

2b9e73a67895/){kind=link}
- k8s api 통해 k8s 오브젝트 정보 수집
-
기존 CoreDNS 확인
kube_deployment_status_replicas_available{deployment="coredns"} -
Scale out 후 재 확인
# scale out kubectl scale deployment -n kube-system coredns --replicas 3 # 확인 kube_deployment_status_replicas_available{deployment="coredns"} # scale in kubectl scale deployment -n kube-system coredns --replicas 1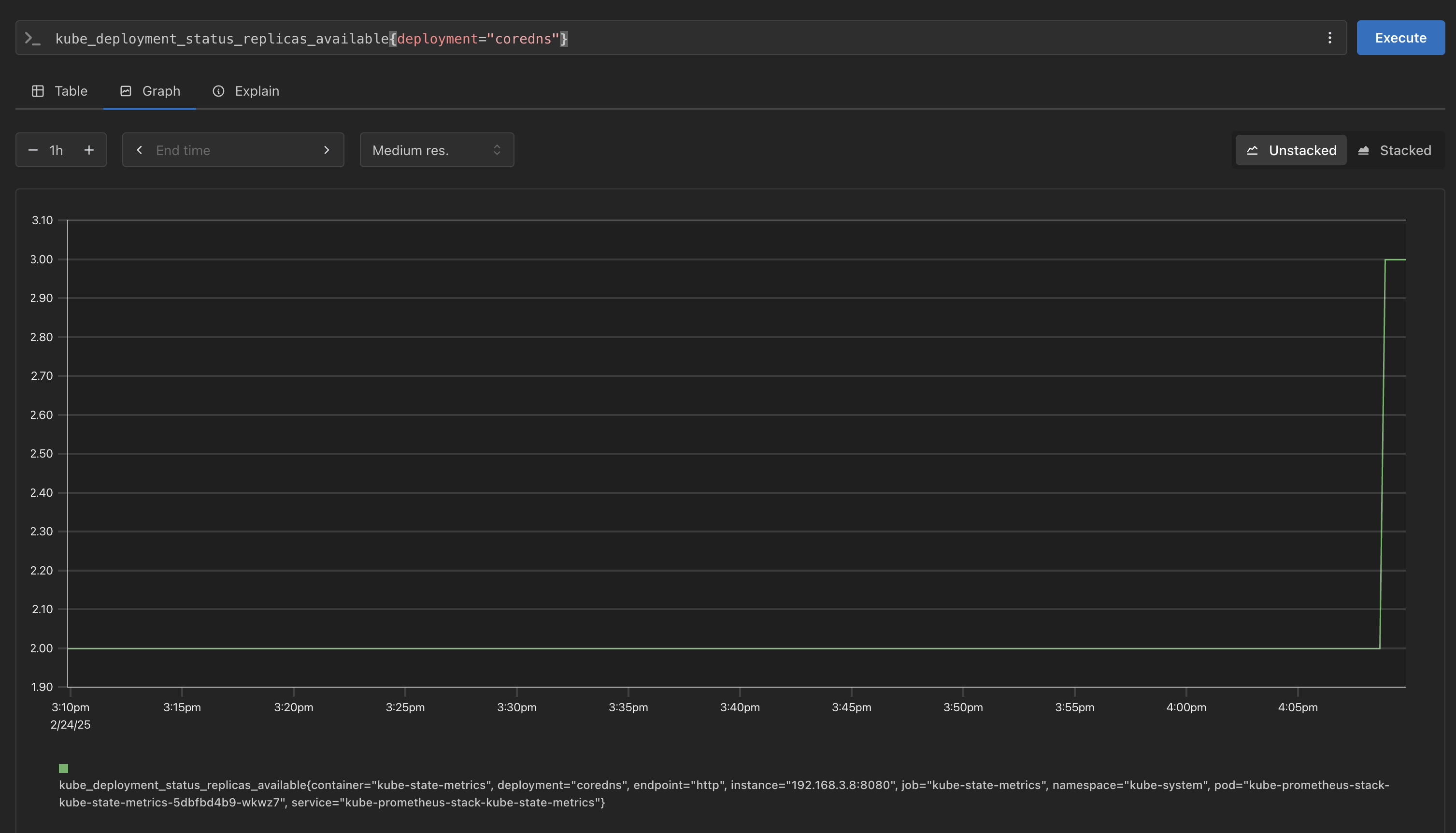
-
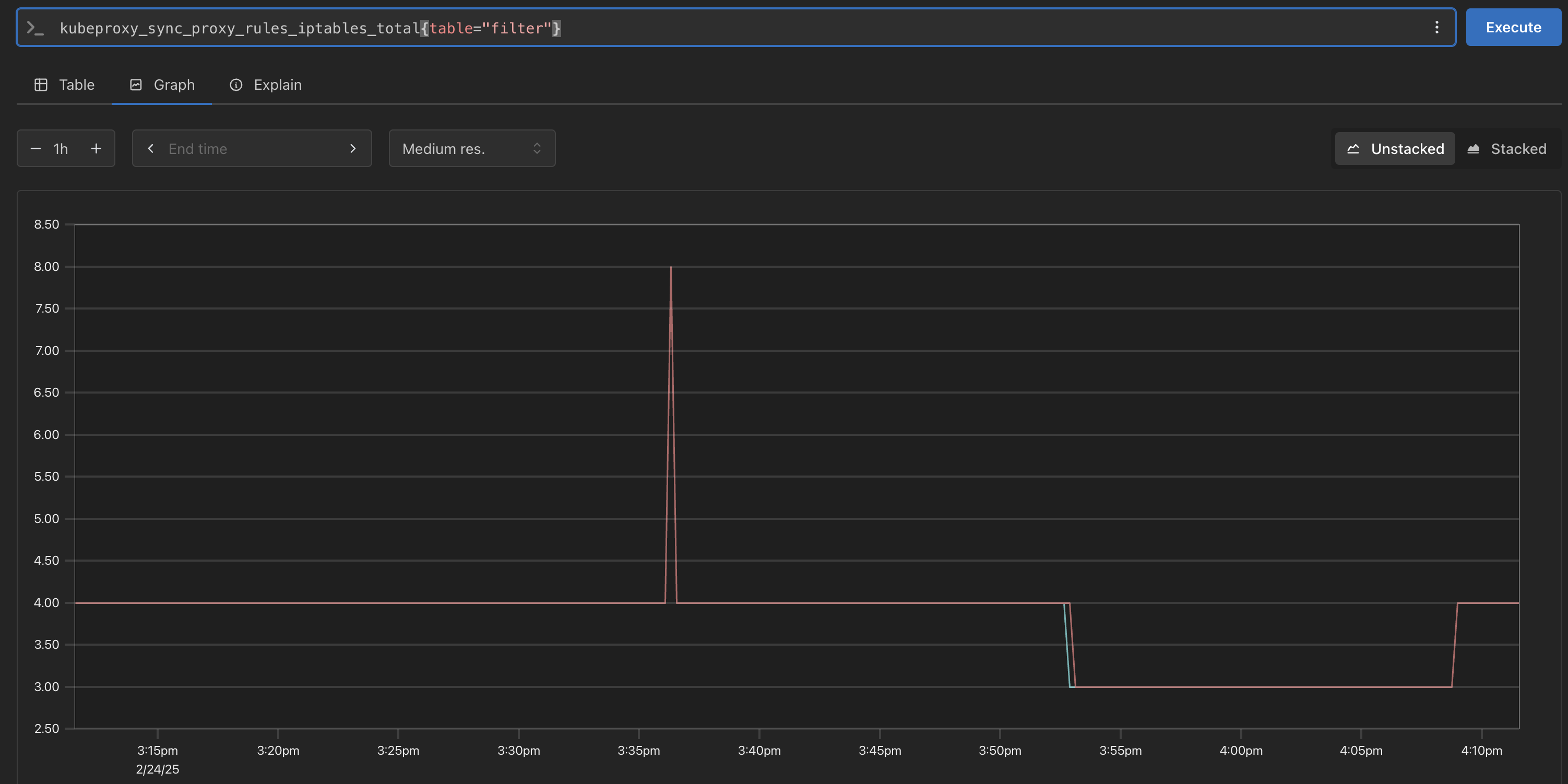
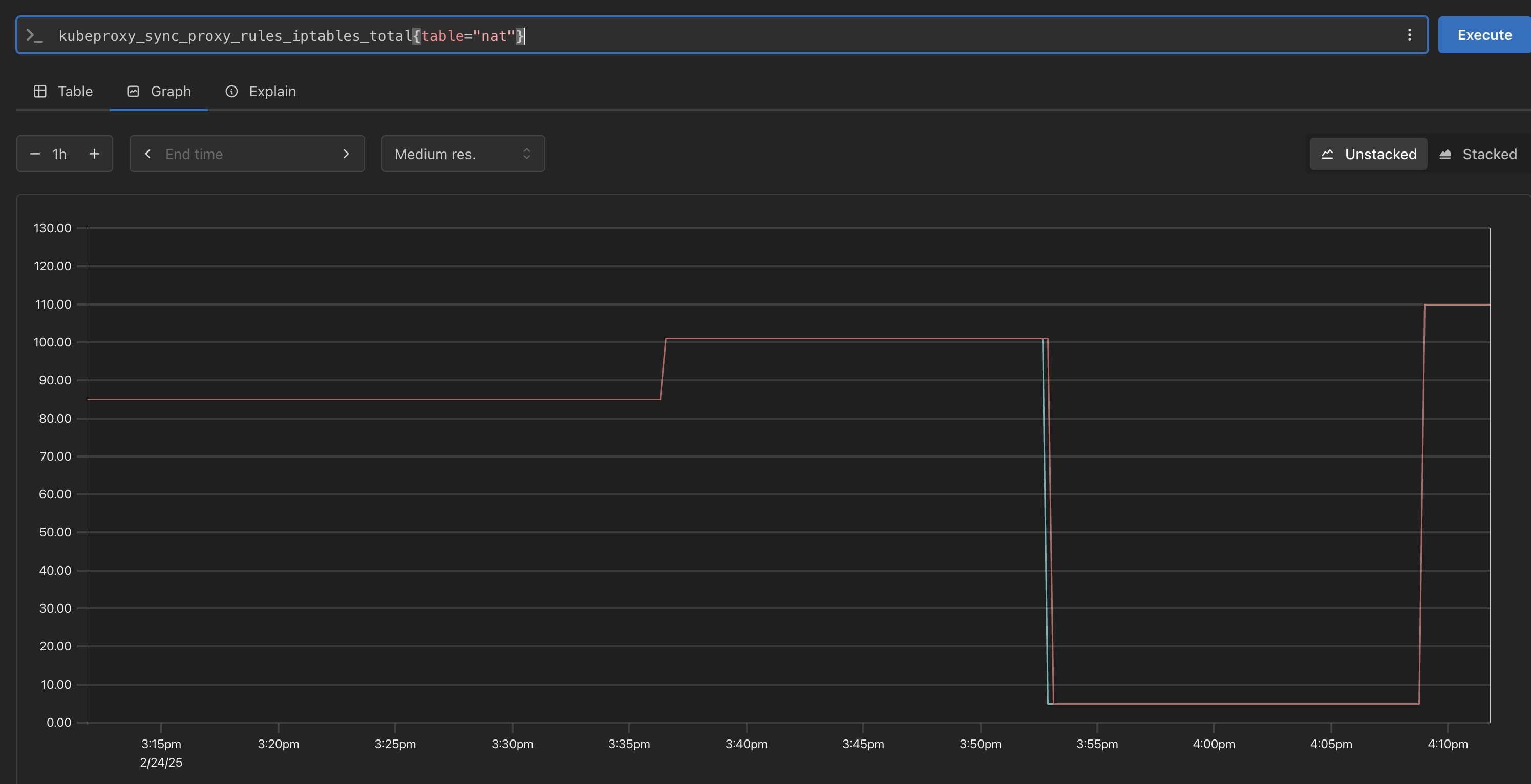
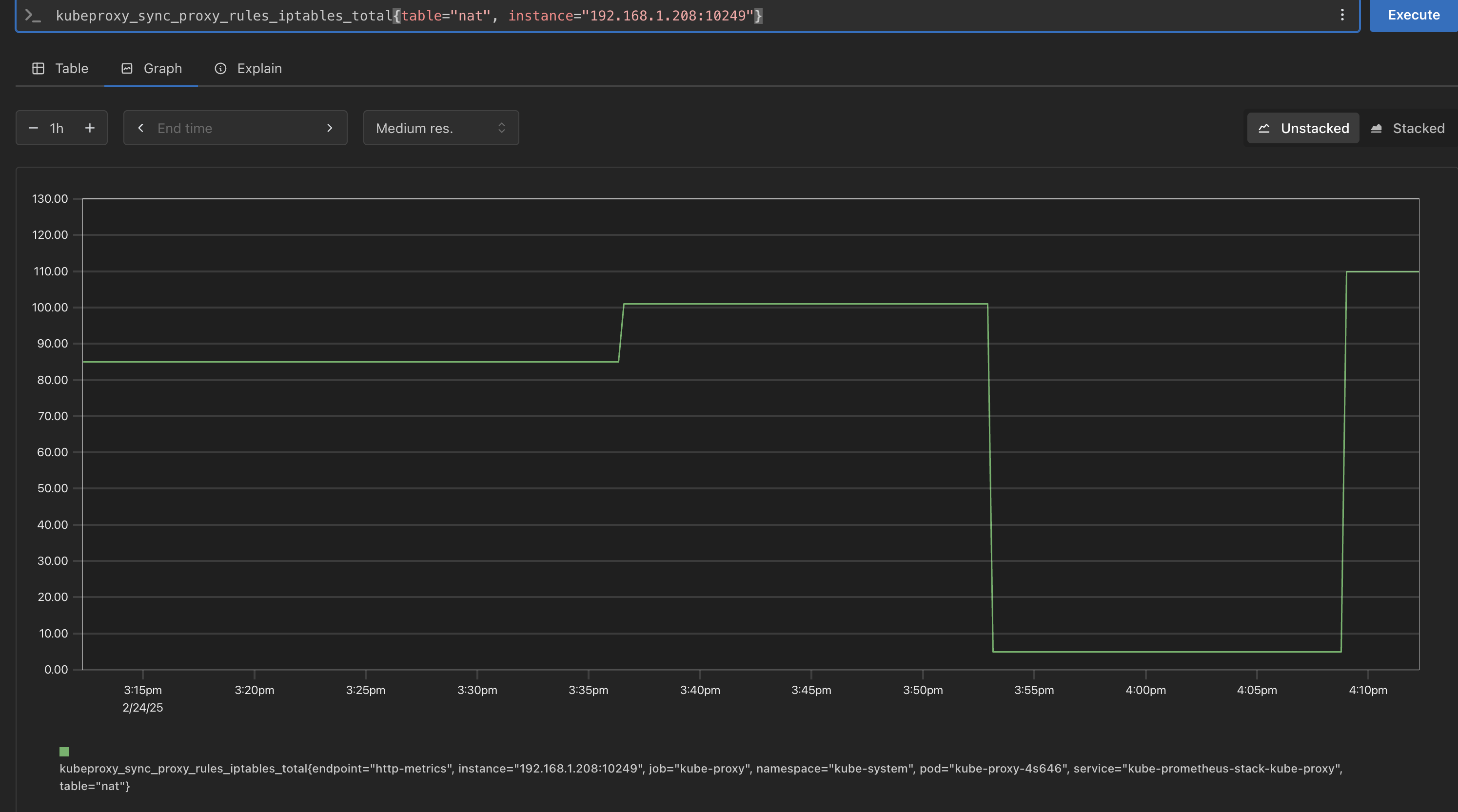
kube-proxy
-
이미 애플리케이션이 내장 되어 있어 별도의 설정 불필요
- k8s의 kube-proxy에서 사용되는 성능 및 상태 모니터링을 위한 메트릭을 정의하는 코드.
- iptables, IPVS, NFTables 등 프록시 모드별로 적절한 메트릭을 등록 및 관리한다.
- Netfilter 기반의 패킷 통계(nfacct)도 지원하여 패킷 드롭 및 로컬 트래픽 모니터링 기능을 포함
# kubeproxy_sync_proxy_rules_iptables_total kubeproxy_sync_proxy_rules_iptables_total{table="filter"} kubeproxy_sync_proxy_rules_iptables_total{table="nat"} kubeproxy_sync_proxy_rules_iptables_total{table="nat", instance="192.168.1.208:10249"}
PromQL
- 프로메테우스 메트릭 종류 (4종) : Counter, Gauge, Histogram, Summary
- 게이지 Gauge : 특정 시점의 값을 표현하기 위해서 사용하는 메트릭 타입, CPU 온도나 메모리 사용량에 대한 현재 시점 값
- 카운터 Counter : 누적된 값을 표현하기 위해 사용하는 메트릭 타입, 증가 시 구간 별로 변화(추세) 확인, 계속 증가 → 함수 등으로 활용
- 서머리 Summary : 구간 내에 있는 메트릭 값의 빈도, 중앙값 등 통계적 메트릭
- 히스토그램 Histogram : 사전에 미리 정의한 구간 내에 있는 메트릭 값의 빈도를 측정 → 함수로 측정 포맷을 변경
사용법
-
PromQL Query - Docs Operator Example
-
Label Matchers : = , ! = , =~ 정규표현식
```bash # 예시 node_memory_Active_bytes node_memory_Active_bytes{instance="192.168.1.208:9100"} node_memory_Active_bytes{instance**!=**"192.168.1.208:9100"} # 정규표현식 node_memory_Active_bytes{instance=~"192.168.+"} node_memory_Active_bytes{instance=~"192.168.1.+"} # 다수 대상 node_memory_Active_bytes{instance=~"192.168.1.208:9100|192.168.2.231:9100"} node_memory_Active_bytes{instance!~"192.168.1.208:9100|192.168.2.231:9100"} # 여러 조건 AND kube_deployment_status_replicas_available{namespace="kube-system"} kube_deployment_status_replicas_available{namespace="kube-system", deployment="coredns"}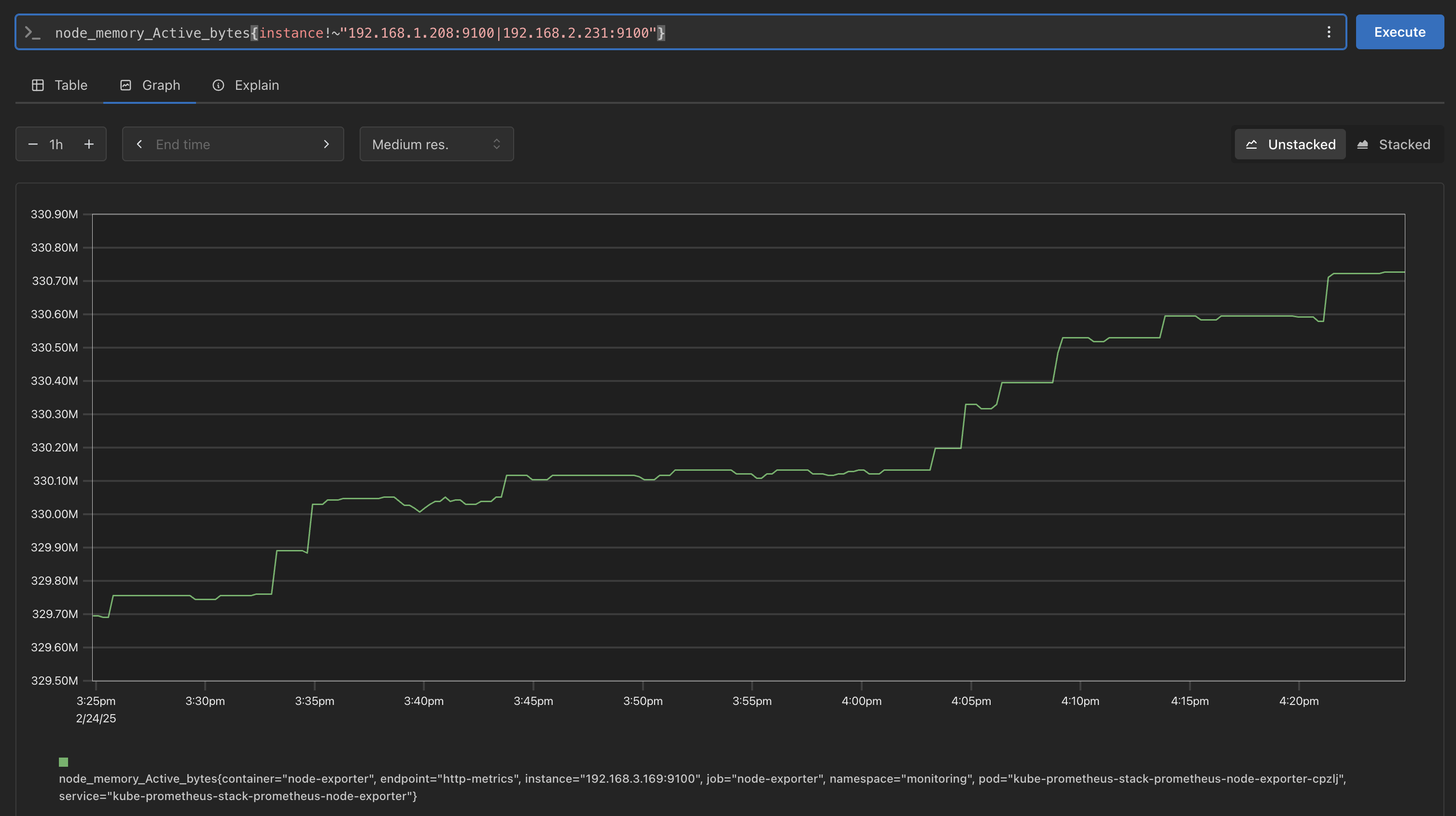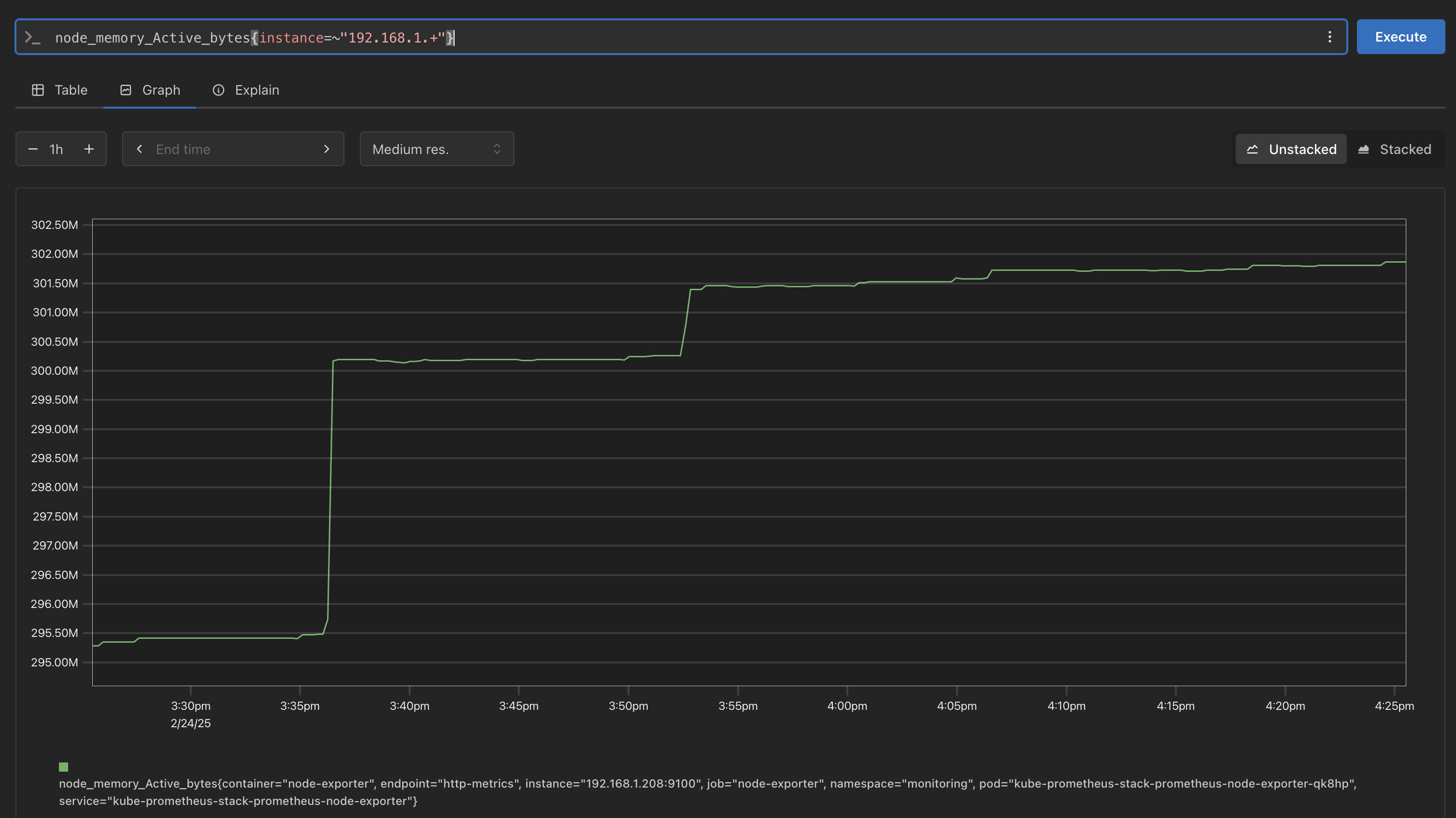 -
Binary Operators 이진 연산자 - Link
- 산술 이진 연산자 : + - / ^
- 비교 이진 연산자 : = = ! = > < > = < =
- 논리/집합 이진 연산자 : and 교집합 , or 합집합 , unless 차집합
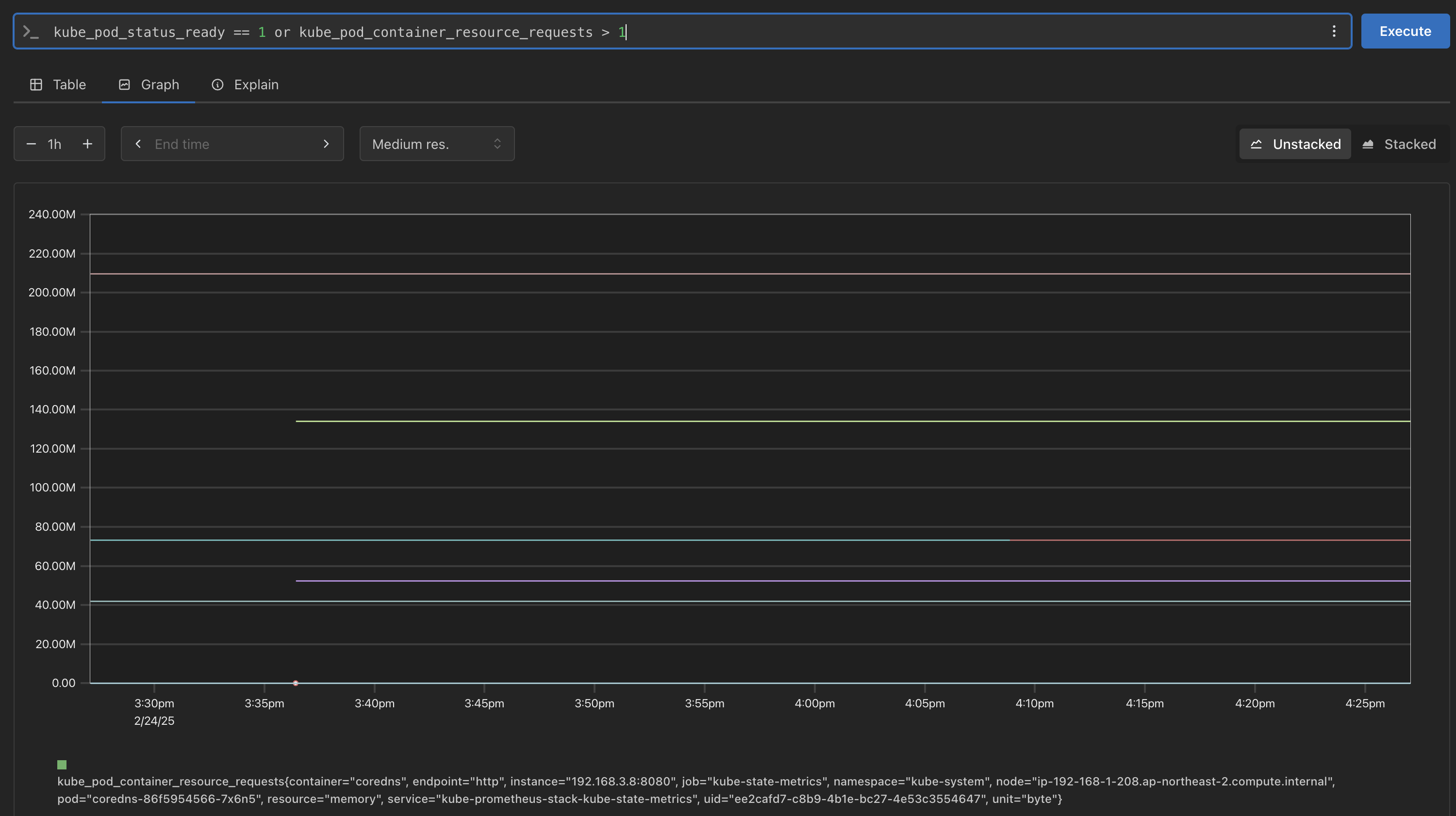
# 산술 이진 연산자 : + - * / * ^ node_memory_Active_bytes node_memory_Active_bytes**/1024** node_memory_Active_bytes**/1024/1024** # 비교 이진 연산자 : = = ! = > < > = < = nginx_http_requests_total nginx_http_requests_total > 100 nginx_http_requests_total > 10000 # 논리/집합 이진 연산자 : and 교집합 , or 합집합 , unless 차집합 kube_pod_status_ready kube_pod_container_resource_requests kube_pod_status_ready == 1 kube_pod_container_resource_requests > 1 kube_pod_status_ready == 1 or kube_pod_container_resource_requests > 1 kube_pod_status_ready == 1 and kube_pod_container_resource_requests > 1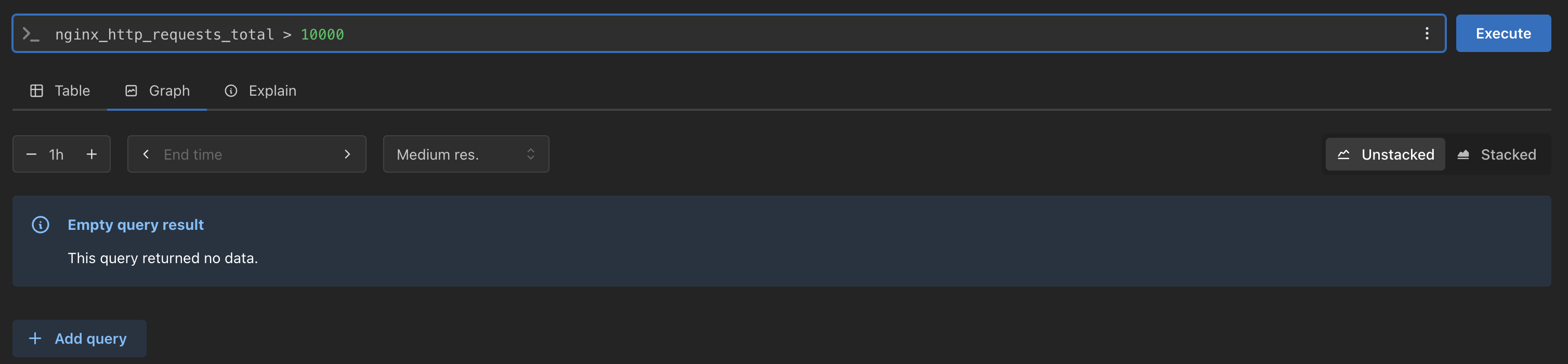
-
-
Aggregation Operators 집계 연산자 - Link
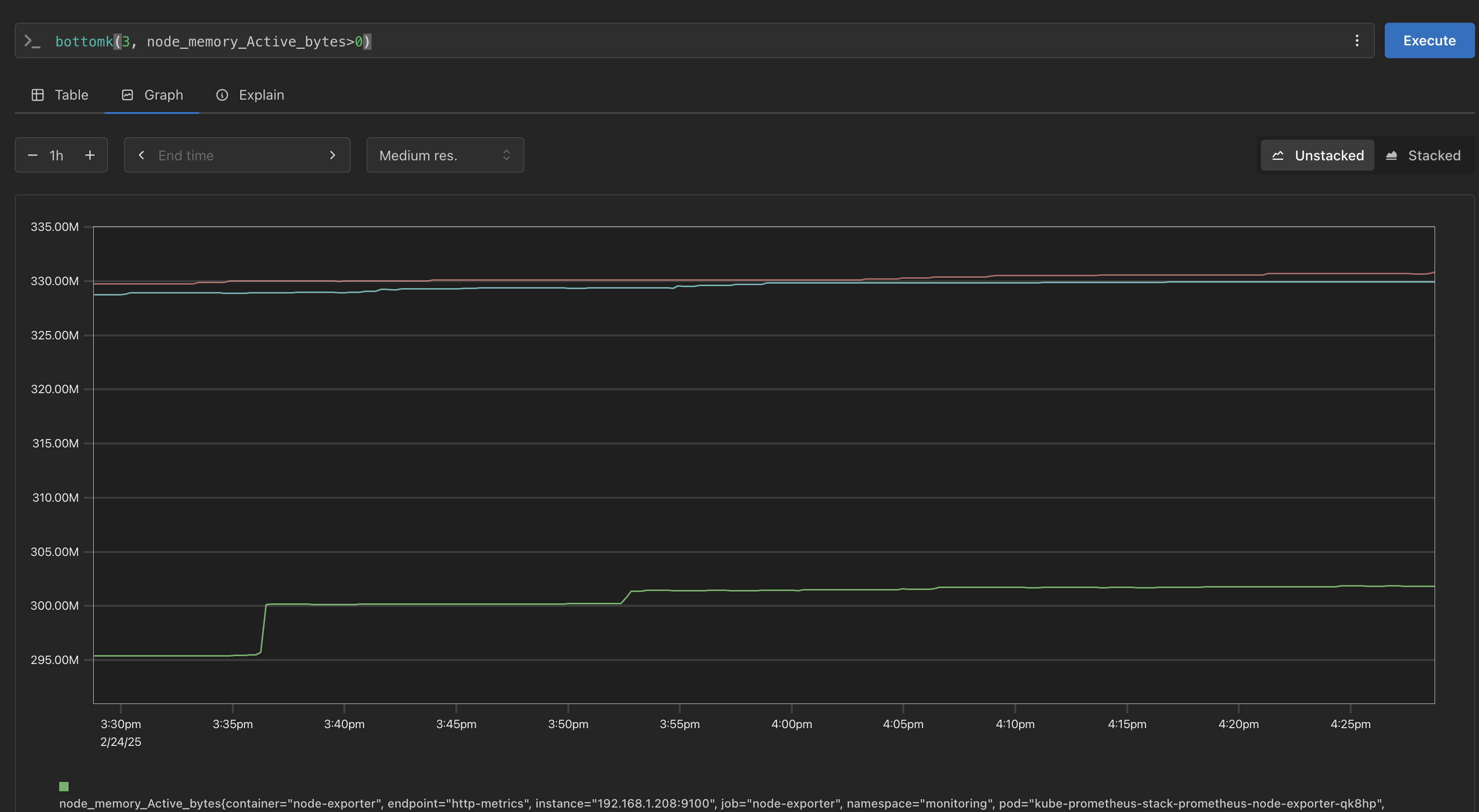
함수 설명 sum조회된 값들의 합을 계산합니다. min조회된 값 중 가장 작은 값을 선택합니다. max조회된 값 중 가장 큰 값을 선택합니다. avg조회된 값들의 평균을 계산합니다. group조회된 모든 값을 1로 변환합니다.stddev조회된 값들의 모 표준 편차를 계산합니다. stdvar조회된 값들의 모 표준 분산을 계산합니다. count조회된 요소의 개수를 출력합니다. (인스턴스 벡터에서만 사용 가능) count_values동일한 값을 가진 요소의 개수를 출력합니다. bottomk조회된 값들 중 가장 작은 k개를 출력합니다.topk조회된 값들 중 가장 큰 k개를 출력합니다.quantile조회된 값들을 분위수(0 ≤ φ ≤ 1)로 나누고, 해당 분위수에 해당하는 값을 출력합니다. # node_memory_Active_bytes # 출력 값 중 Top 3 topk(3, node_memory_Active_bytes) # 출력 값 중 하위 3 bottomk(3, node_memory_Active_bytes) bottomk(3, node_memory_Active_bytes>0) # node 그룹별: **by** node_cpu_seconds_total node_cpu_seconds_total{mode="**user**"} node_cpu_seconds_total{mode="system"} avg(node_cpu_seconds_total) avg(node_cpu_seconds_total) **by** (instance) avg(node_cpu_seconds_total{mode="user"}) **by** (instance) avg(node_cpu_seconds_total{mode="system"}) **by** (instance) # nginx_http_requests_total sum(nginx_http_requests_total) sum(nginx_http_requests_total) by (instance) # 특정 내용 제외하고 출력 : **without** nginx_http_requests_total sum(nginx_http_requests_total) without (instance) sum(nginx_http_requests_total) without (instance,container,endpoint,job,namespace)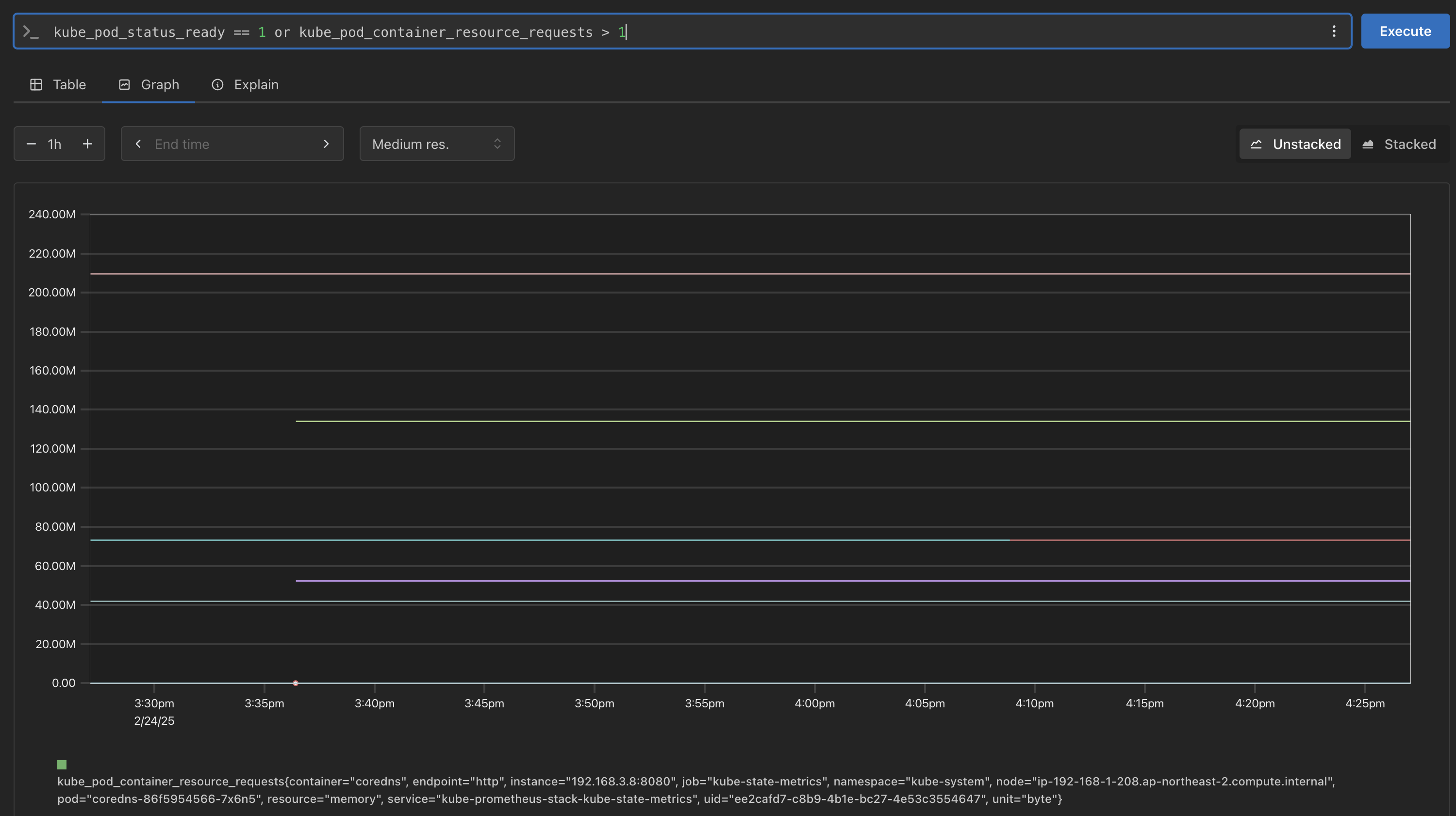
-
Time series selectors
- 인스턴스 벡터 Instant Vector : 시점에 대한 메트릭 값만을 가지는 데이터 타입
- 레인지 벡터 Range Vector : 시간의 구간을 가지는 데이터 타입
- 시간 단위 : ms, s, m(주로 분 사용), h, d, w, y
# 시점 데이터 node_cpu_seconds_total # 15초 마다 수집하니 아래는 지난 4회차/8회차의 값 출력 node_cpu_seconds_total[**1m**] node_cpu_seconds_total[**2m**]

DevOps Engineer