7. 관찰가능성 Observability: Understanding the behavior of your services
7.1 Observability란?
개념
관찰 가능성(Observability)이란 외부에서 확인 가능한 신호와 특성만을 가지고 시스템의 내부 상태를 이해하고 추론할 수 있는 능력을 의미합니다. 이는 시스템의 안정성과 효과적인 제어를 구현하는 데 필수적인 특성 중 하나입니다. 이 개념은 1960년 루돌프 칼만(Rudolf E. Kalman)이 발표한 제어 이론에서 처음 등장하였습니다.
실제로 시스템의 안정적 운영을 위해서는 평소 시스템이 어떻게 동작하는지 명확히 이해하고 있어야 합니다. 그래야 문제가 발생했을 때 신속하게 파악하고, 적절한 자동 또는 수동 제어를 통해 시스템을 다시 안정적인 상태로 되돌릴 수 있기 때문입니다.
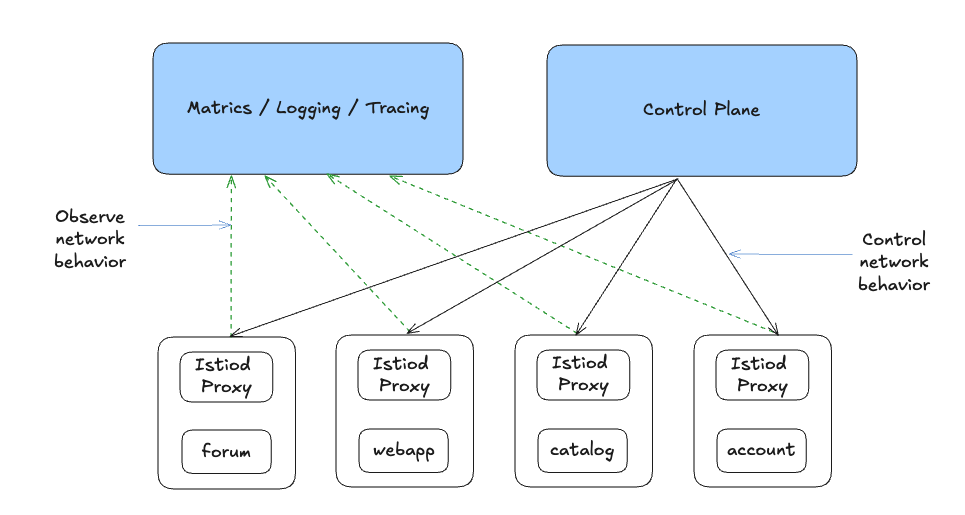
이스티오(Istio)는 이러한 관찰 가능성을 높이는 데 중요한 역할을 합니다. 특히 이스티오는 트래픽 관리, 복원력 향상, 정책 강제 등 다양한 제어 기능을 제공합니다. 이 기능들은 주로 네트워크 수준에서 이루어지며, 시스템을 거쳐가는 요청의 동작에 직접적으로 영향을 줄 수 있는 위치에서 작동합니다.
흥미롭게도 이스티오는 시스템의 네트워크 수준에서 메트릭을 수집하여 관찰 가능성을 지원합니다. 즉, 시스템 내부에서 어떤 일이 벌어지고 있는지 더욱 정밀하게 파악할 수 있게 해줍니다. 그러나 이스티오만으로는 완벽한 관찰 가능성을 구현할 수 없습니다. 진정한 관찰 가능성 확보를 위해서는 애플리케이션 계측, 네트워크 계측, 데이터 수집 인프라 구축 등 다양한 계층의 전략이 함께 필요합니다.
결론적으로 이스티오는 관찰 가능성을 구성하는 여러 요소 중 하나인 애플리케이션 수준의 네트워크 계측을 지원하는 중요한 보조 수단입니다. 전체적인 시스템의 관찰 가능성을 높이려면 이스티오 외에도 다양한 수준의 계측과 인프라가 함께 고려되어야 합니다.
Observability vs monitoring
최근 시스템 관리와 관련하여 '관찰 가능성(Observability)'이란 용어가 등장하면서 기존의 '모니터링'과 혼란이 생기기도 한다. 이 두 용어는 비슷해 보이지만 실제로는 목적과 접근 방식이 다릅니다.
monitoring 이란?
모니터링은 미리 정의한 기준에 따라 시스템의 상태를 확인하는 활동입니다.
주로 메트릭(Metric), 로그(Log), 트레이스(Trace)와 같은 데이터를 수집하고 분석하여 특정 임계값을 넘는지 감시합니다.
예를 들어, 데이터베이스의 디스크 사용량이 정해진 임계값에 가까워지면 운영자는 디스크 공간을 추가하는 등의 예방 조치를 즉시 취할 수 있습니다.
즉, 모니터링은 이미 알려진 문제를 예방하기 위한 명확한 기준을 가지고 있습니다..
Observability 이란?
반면에 관찰 가능성은 시스템을 예측하기 어려운 복잡한 것으로 간주하여, 모든 가능한 장애를 사전에 예측할 수 없다고 가정합니다. 그래서 훨씬 더 많은 데이터를 수집하고, 빠르게 탐색하며 유연하게 질문할 수 있는 능력을 강조합니다.
예를 들어, 특정 사용자(홍길동)가 결제 과정에서 10초간 지연을 겪었다면, 기존 모니터링 메트릭에서는 이상이 없어 보일 수 있다. 하지만 관찰 가능성이 확보된 환경이라면, 사용자 ID, 요청 ID, IP와 같은 고유 식별자를 통해 서비스의 모든 계층을 상세히 살펴보고 문제가 발생한 정확한 원인을 빠르게 찾을 수 있습니다.
즉, 관찰 가능성은 예상치 못한 문제를 신속히 탐지하고 진단할 수 있게 합니다.
요약
요약하자면, 모니터링은 관찰 가능성의 일부입니다.
- 모니터링은 이미 알려진 문제에 대응하기 위한 선제적이고 수동적인 접근 방식입니다.
- 관찰 가능성은 미지의 문제까지 대응할 수 있도록 시스템 내부를 심층적으로 이해하고, 유연하게 분석할 수 있는 능력을 제공합니다.
이스티오는 어떻게 Observability를 하는가?
시스템이 점점 복잡해지고, 마이크로서비스가 늘어나면서 장애나 성능 저하의 원인을 빠르게 찾아내고 해결하는 것이 매우 중요해졌다.. 이런 상황에서 서비스 메시인 이스티오(Istio)는 관찰 가능한 시스템을 구축하는 데 매우 유용한 도구로 각광받고 있습니다.
이스티오가 관찰 가능성에서 갖는 특별한 위치
이스티오는 서비스 메시 내부에서 모든 요청이 통과하는 데이터 플레인 프록시인 엔보이(Envoy)를 중심으로 작동한다. 이 엔보이 프록시가 서비스 간 네트워크 요청의 경로에 직접 위치하고 있기 때문에, 이스티오는 다른 솔루션보다도 서비스 간 상호작용에 대한 매우 상세한 데이터를 얻을 수 있습니다.
이스티오는 엔보이를 통해 다음과 같은 중요한 메트릭을 수집할 수 있습니다.
- 초당 요청 수(RPS, Requests Per Second)
- 요청 처리 시간(지연시간, Latency)의 백분위 수(percentile)
- 실패한 요청의 수 및 비율 등
더불어 이스티오는 시스템 운영 중에도 새로운 메트릭을 동적으로 추가할 수 있는 능력을 제공합니다. 이는 시스템 설계 당시 미처 예상하지 못했던 문제를 신속히 감지하고 해결하는 데 큰 도움을 줍니다.
분산 트레이싱으로 요청 흐름을 파악하기
관찰 가능성을 높이는 또 다른 핵심 방법은 분산 트레이싱(Distributed Tracing)이다. 분산 트레이싱을 사용하면 요청이 시스템 내의 어떤 서비스와 구성 요소를 거쳐가는지, 각 서비스가 처리하는 데 얼마나 시간이 걸리는지를 매우 정확히 파악할 수 있습니다.
이스티오 기본 제공 도구와 실제 활용
이스티오는 기본적으로 관찰 가능성을 높이기 위한 여러 샘플 도구를 제공합니다. 대표적으로 프로메테우스(Prometheus), 그라파나(Grafana), 키알리(Kiali)가 있다. 이들 도구는 서비스 메시의 상태와 서비스 간 상호작용을 시각화하여 보다 손쉬운 분석과 탐색을 지원합니다.
하지만 이번 글에서는 데모용으로 제공된 이 기본 도구를 사용하지 않고, 실무 환경에 더 가까운 현실적인 설정을 사용할 예정이다. 따라서 실습 환경에서는 샘플 도구 설치를 생략합니다.
정리
이스티오는 서비스 메시 구조 덕분에 뛰어난 관찰 가능성을 제공하며, 엔보이를 활용해 상세한 메트릭을 수집하고, 필요에 따라 동적으로 새로운 메트릭을 추가할 수 있다. 또한 분산 트레이싱을 통해 서비스의 상호작용과 성능 문제를 깊이 있게 분석할 수 있다.
7.2 Istio 메트릭 살펴보기
데이터 플레인의 메트릭
초기화 및 실습 환경 구축
- catalog 앱 기동
kubectl apply -f services/catalog/kubernetes/catalog.yaml -n istioinaction
- webapp 앱 기동
kubectl apply -f services/webapp/kubernetes/webapp.yaml -n istioinaction
- gateway, virtualservice 설정
kubectl apply -f services/webapp/istio/webapp-catalog-gw-vs.yaml -n istioinaction
- 배포 확인
kubectl get deploy,pod,svc,ep,gw,vs -n istioinaction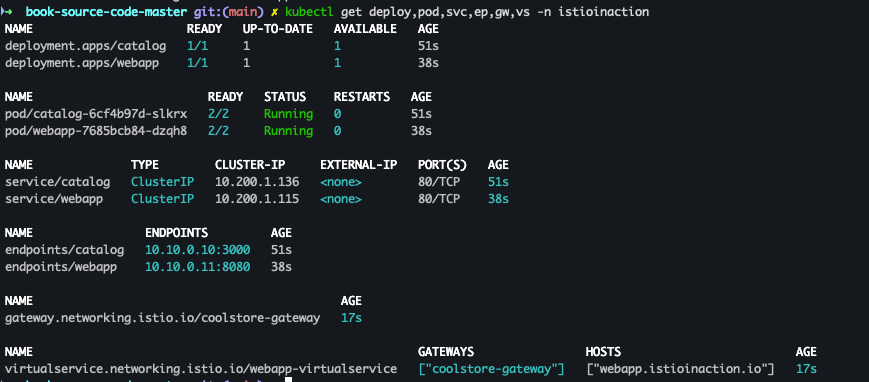
- 호출 테스트
curl -s http://webapp.istioinaction.io:30000/api/catalog | jq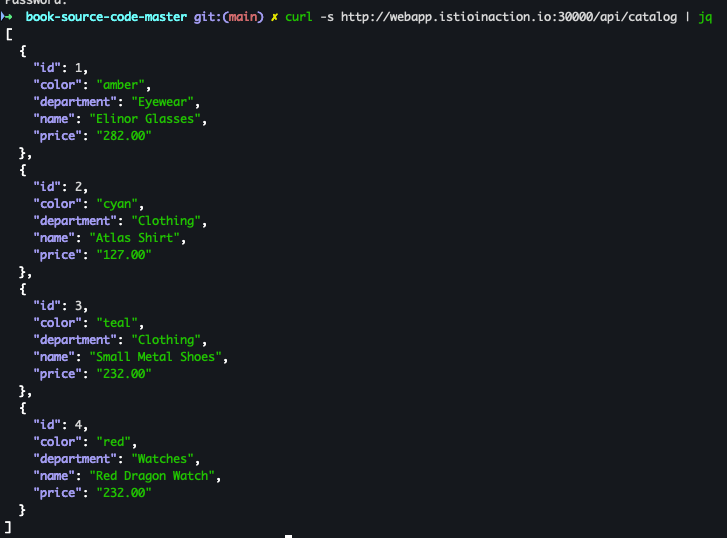
서비스의 사이드카 프록시가 유지하는 매트릭 확인
- pod 확인
kubectl get pod -n istioinaction
- proxy-status 확인
docker exec -it myk8s-control-plane istioctl proxy-status
-
쿼리를 실행해 파드의 통계 확인
kubectl exec -it deploy/catalog -c istio-proxy -n istioinaction -- curl localhost:15000/stats kubectl exec -it deploy/webapp -c istio-proxy -n istioinaction -- curl localhost:15000/stats- catalog
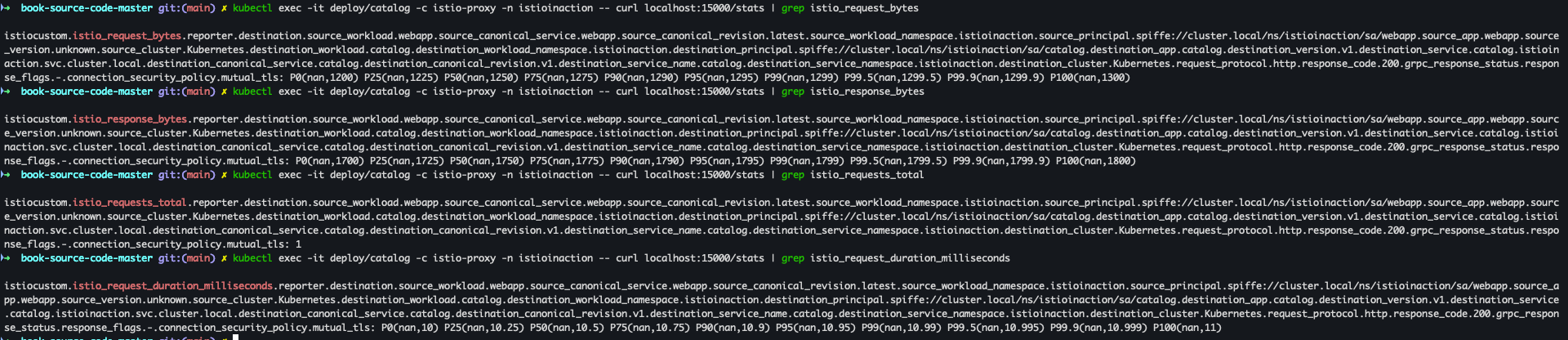
- webapp
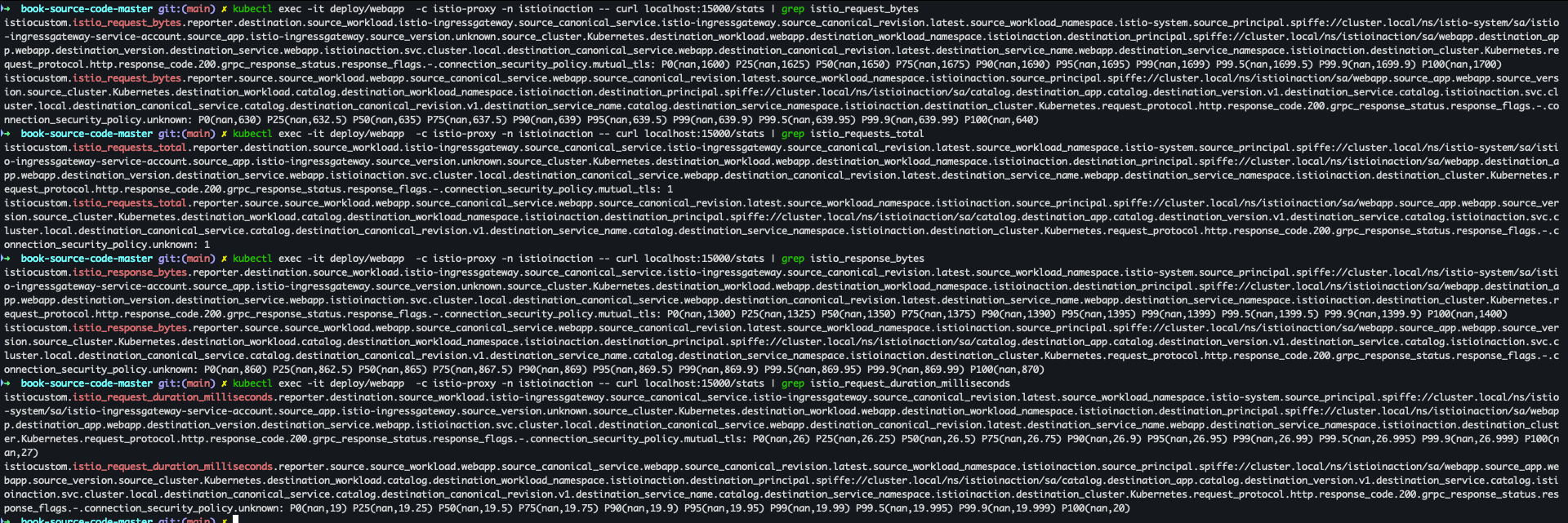
- catalog
프록시가 엔보이 통계를 더 많이 보고하도록 설정
가끔 네트워크 동작을 트러블슈팅하려면 표준 이스티오 메트릭보다 많은 정보들을 확인해야 할때가 있다.
추가 정보를 넣는 방법은 다음과 같습니다.
방법 1 : IstioOperator - 메시 전체 적용 (과부하 상태를 야기 할수 있음)
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
metadata:
name: control-plane
spec:
profile: demo
meshConfig:
defaultConfig: # Defines the default proxy configuration for all services
proxyStatsMatcher: # Customizes the reported metrics
inclusionPrefixes: # Metrics matching the prefix will be reported alongside the default ones.
- "cluster.outbound|80||catalog.istioinaction"방법 2: 워크로드 단위로 설정 → 애노테이션으로 포함할 메트릭 지정 (권장)
# cat ch7/webapp-deployment-stats-inclusion.yaml
...
template:
metadata:
annotations:
proxy.istio.io/config: |-
proxyStatsMatcher:
inclusionPrefixes:
- "cluster.outbound|80||catalog.istioinaction"
labels:
app: webapp- 적용 전 확인
kubectl exec -it deploy/webapp -c istio-proxy -n istioinaction -- curl localhost:15000/stats | grep catalog
- Deployment 적용
cat ch7/webapp-deployment-stats-inclusion.yaml kubectl apply -n istioinaction -f ch7/webapp-deployment-stats-inclusion.yaml
- 적용 후 호출 테스트 진행
curl -s http://webapp.istioinaction.io:30000/api/catalog | jq curl -s http://webapp.istioinaction.io:30000/api/catalog | jq
- 적용후 메트릭 확인
kubectl exec -it deploy/webapp -c istio-proxy -n istioinaction -- curl localhost:15000/stats | grep catalog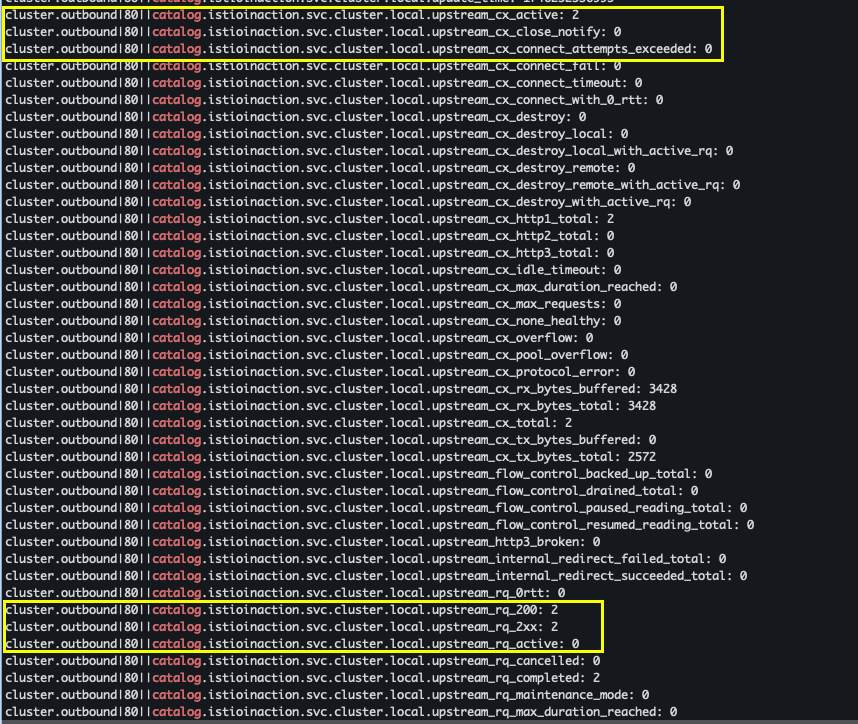
- cluster_name.internal.* : 내부(메시 내부 트레픽) 요청 확인
kubectl exec -it deploy/webapp -c istio-proxy -n istioinaction -- curl localhost:15000/stats | grep catalog | grep internal
- cluster_name.ssl.* : TLS로 업스트림 클러스터로 이동하는지 여부와 커넥션과 관련된 기타 세부 정보 확인
kubectl exec -it deploy/webapp -c istio-proxy -n istioinaction -- curl localhost:15000/stats | grep catalog | grep ssl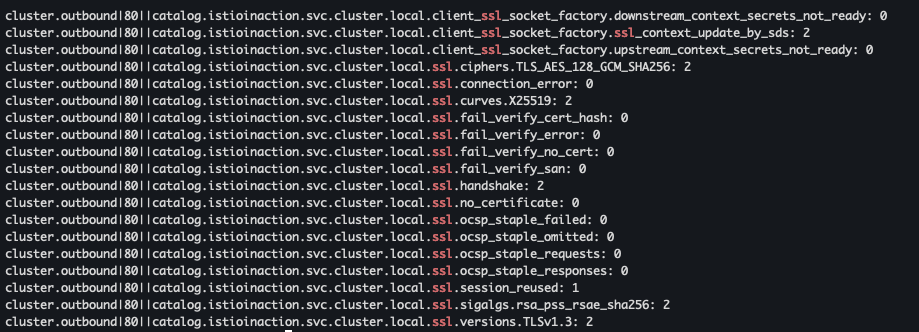
- upstream_cx, upstream_rq : 네트워크에서 일어나는 일에 대한 좀 더 정확한 정보 확인
kubectl exec -it deploy/webapp -c istio-proxy -n istioinaction -- curl localhost:15000/stats | grep catalog | egrep 'local.upstream_cx|local.upstream_rq'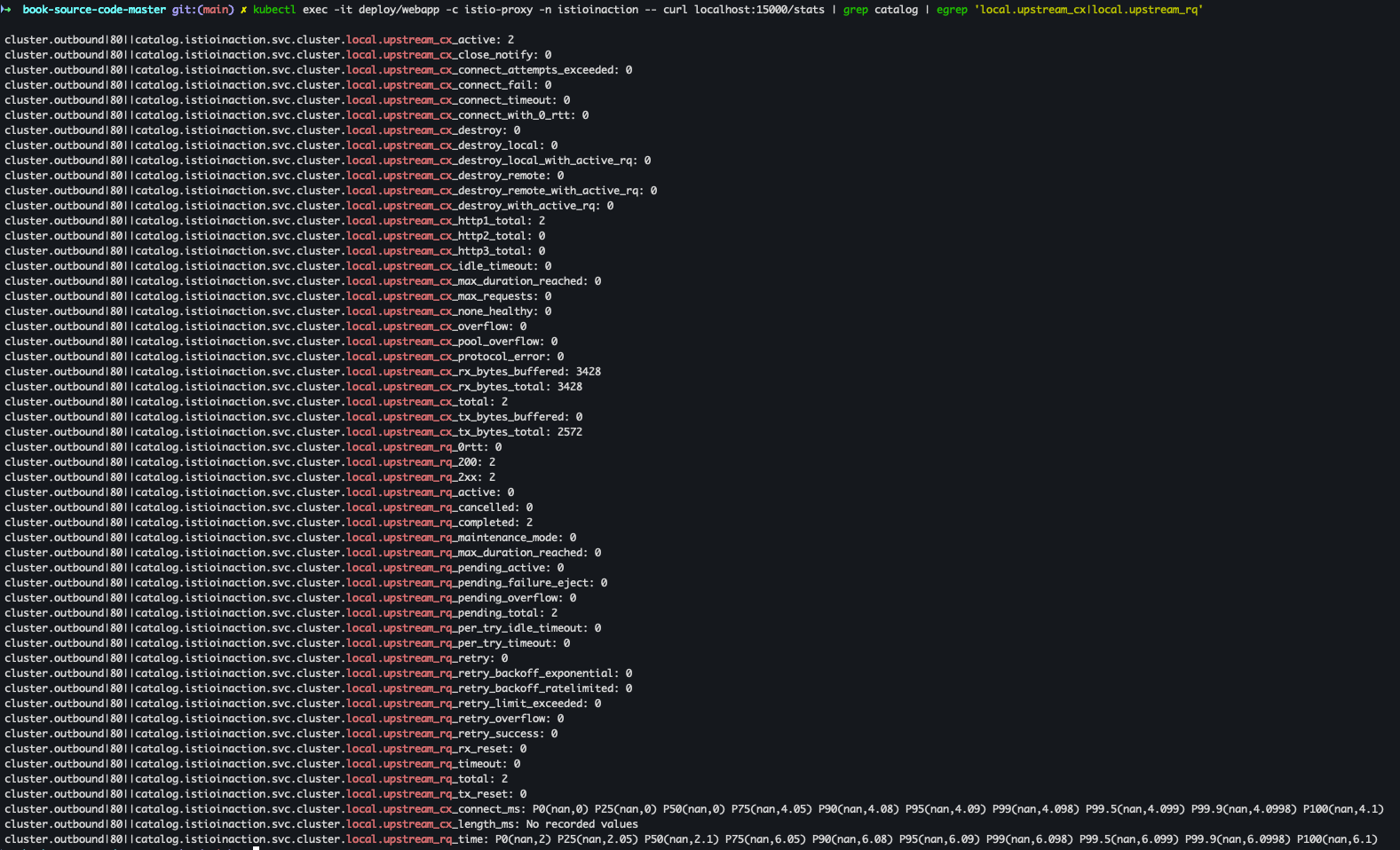
- 기타 메트릭 확인 (LB) - Docs
kubectl exec -it deploy/webapp -c istio-proxy -n istioinaction -- curl localhost:15000/stats | grep catalog | grep lb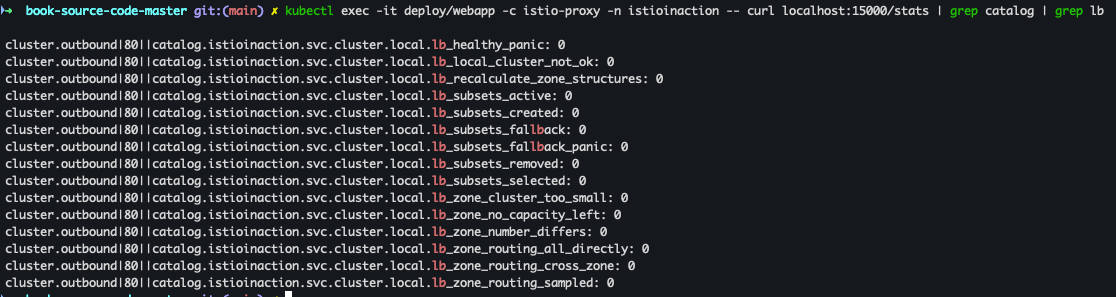
- 백엔드 클러스터, 엔드포인트 나열
kubectl exec -it deploy/webapp -c istio-proxy -n istioinaction -- curl localhost:15000/clusters | grep catalog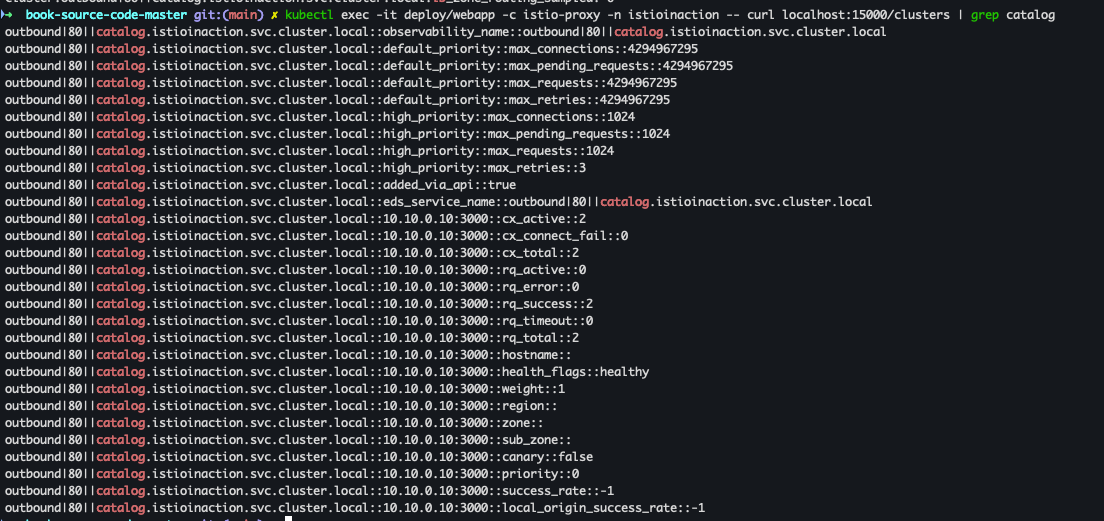
컨트롤 플레인 메트릭
컨트롤 플레인에는 istiod가 어떻게 동작하는지에 대한 정보가 풍부 합니다.
이를테면 데이터 플레인 프록시와 설정을 동기화한 횟수, 설정 동기화에 소요된 시간이나 잘못된 설정, 인증서 발급/로테이션에 대한 정보등을 조회 할수 있습니다.
- istiod 파드에 Listen Port 확인
kubectl exec -it deploy/istiod -n istio-system -- netstat -tnl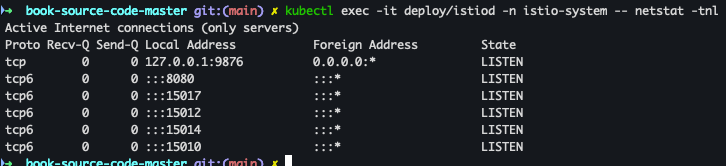
- CSR 정보 조회
kubectl exec -it -n istio-system deploy/istiod -n istio-system -- curl localhost:15014/metricskubectl exec -it -n istio-system deploy/istiod -n istio-system -- curl localhost:15014/metrics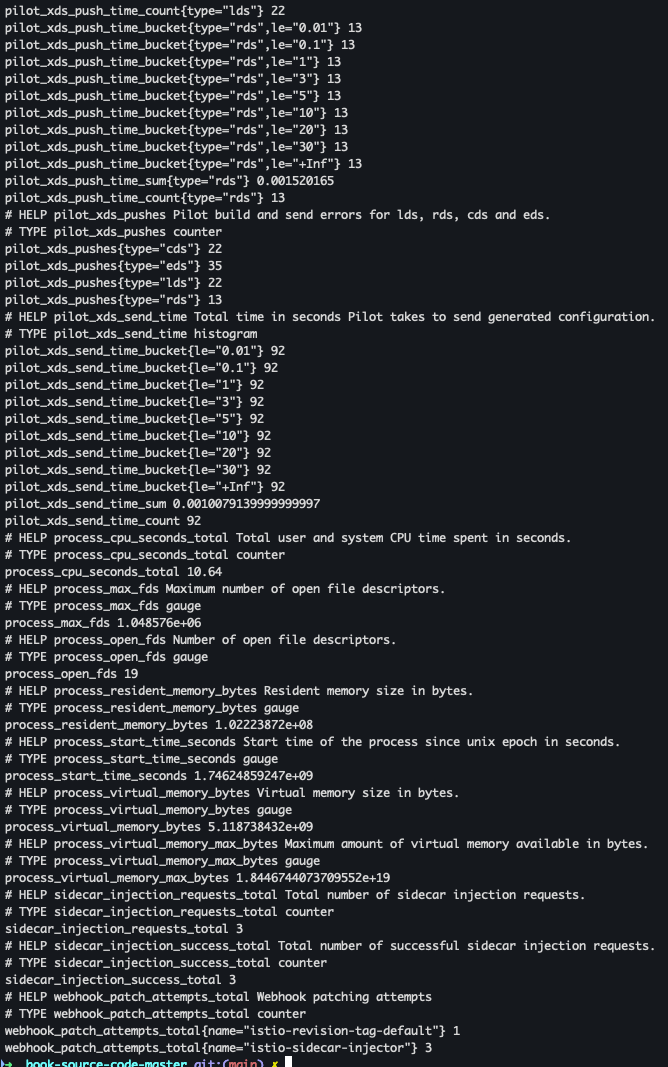
- Citadel (Istio 보안 컴포넌트) 정보 조회
kubectl exec -it -n istio-system deploy/istiod -n istio-system -- curl localhost:15014/metrics | grep citadel
- 컨트롤 플레인 버전에 대한 런타임 정보 확인 : istio 버전정보
kubectl exec -it -n istio-system deploy/istiod -n istio-system -- curl localhost:15014/metrics | grep istio_build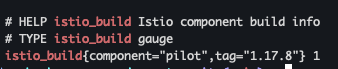
- xDS 리소스의 수렴(convergence) 상태와 관련된 메트릭을 조회
kubectl exec -it -n istio-system deploy/istiod -n istio-system -- curl localhost:15014/metrics | grep convergence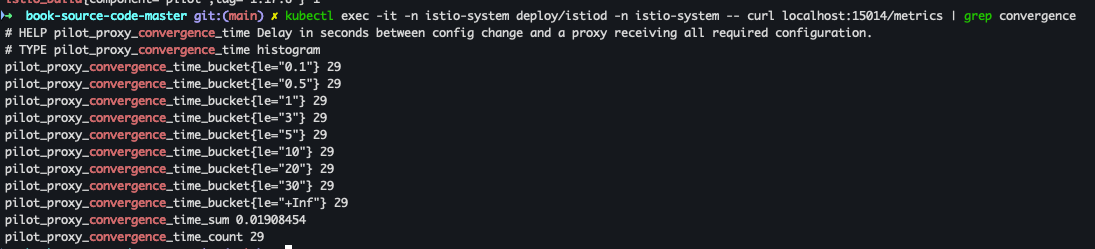
- 컨트롤 플레인에 알려진 서비스 개수, 사용자가 설정한 VirtualService 리소스 개수, 연결된 프록시 개수 조회
kubectl exec -it -n istio-system deploy/istiod -n istio-system -- curl localhost:15014/metrics | grep pilot | egrep 'service|^pilot_xds'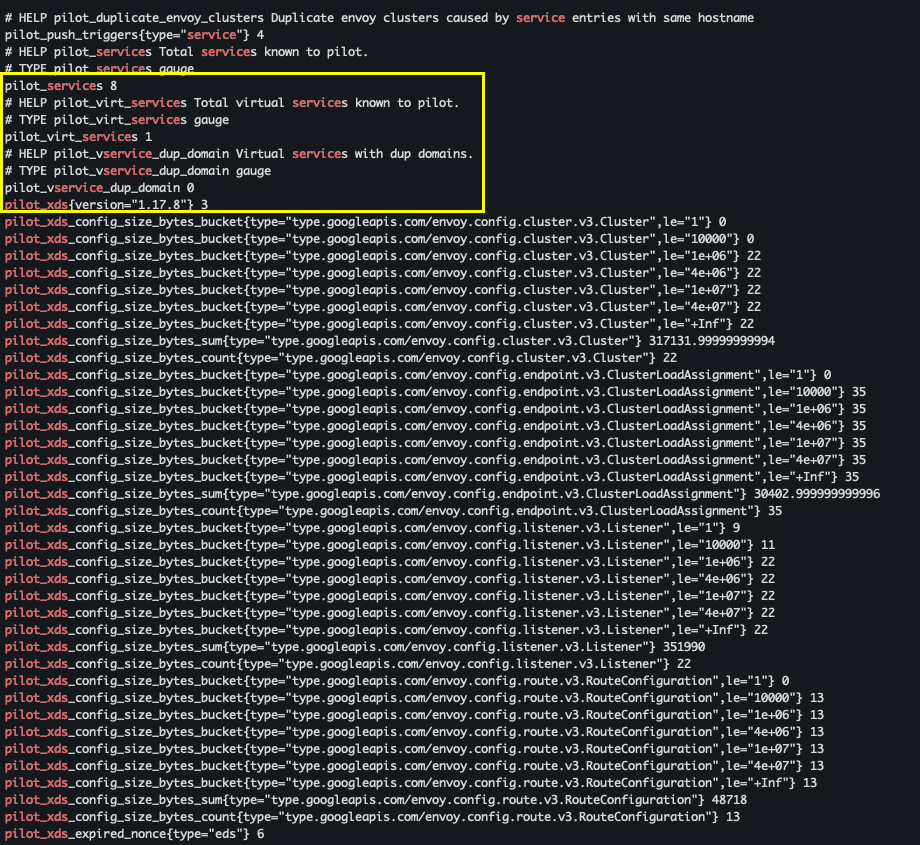
7.3 istio 메트릭 수집 (Prometheus)
들어가며
시스템 운영의 핵심 중 하나는 메트릭(Metric)을 통한 모니터링과 장애 탐지다. 이 분야에서 가장 많이 사용되는 도구가 바로 프로메테우스(Prometheus)다. 프로메테우스는 구글의 내부 시스템인 Borgmon에 영향을 받아 사운드클라우드(SoundCloud)에서 시작된 오픈소스 메트릭 수집 및 모니터링 도구다.
Pull vs Push
프로메테우스는 다른 메트릭 수집 도구와는 달리, 메트릭 데이터를 "밀어넣기(push)"가 아닌 "당겨오기(pull)" 방식으로 수집한다. 일반적으로 다른 모니터링 솔루션들이 메트릭 데이터를 중앙 서버로 전송(push)하는 방식을 취하는 것과 비교해 볼 때, 프로메테우스는 애플리케이션이나 서비스가 메트릭 데이터를 HTTP 엔드포인트로 제공하면 이를 주기적으로 직접 "긁어와(scrape)" 수집하는 방식이다.
이러한 pull 방식은 특정 상황에서 매우 유연하며, 특히 고가용성 설정에 강력한 장점을 가진다. 예를 들어, 여러 프로메테우스 서버가 동일한 메트릭 엔드포인트에서 데이터를 동시에 수집해도 문제가 발생하지 않으며, 이를 통해 간단히 고가용성을 구축할 수 있다.
이스티오(Istio)와 프로메테우스의 결합
이스티오의 서비스 프록시인 엔보이(Envoy)는 모든 서비스 간 통신을 처리하면서 요청에 대한 다양한 메트릭 데이터를 자동으로 수집한다. 엔보이는 이 메트릭 데이터를 프로메테우스가 쉽게 수집할 수 있도록 HTTP 형식의 엔드포인트에 노출한다.
엔보이가 수집하는 주요 메트릭은 다음과 같다:
- 초당 요청 수(RPS)
- 요청 처리 시간(Latency)
- 실패 요청 비율 등 다양한 성능 관련 메트릭
이러한 메트릭 데이터는 curl과 같은 간단한 HTTP 클라이언트 또는 웹 브라우저로 쉽게 확인할 수 있으며, 실제 환경에서 다음과 같이 curl 명령어로 조회할 수 있다.
# webapp의 istio-proxy 컨테이너에서 메트릭 확인하기
kubectl exec -it deploy/webapp -c istio-proxy -n istioinaction -- curl localhost:15090/stats/prometheus
# 이 외에도 다음 명령으로도 메트릭 조회 가능
kubectl exec -it deploy/webapp -c istio-proxy -n istioinaction -- curl localhost:15020/metrics이렇게 노출된 메트릭은 프로메테우스가 주기적으로 긁어가게 되며, 서비스 상태를 더욱 상세하게 파악할 수 있게 된다.
고가용성 프로메테우스 구축
프로메테우스의 pull 방식을 활용하면 손쉽게 고가용성(High Availability)을 구현할 수 있다. 하나의 메트릭 엔드포인트에서 여러 프로메테우스 서버가 동시에 데이터를 수집해도 문제가 없기 때문이다. 이는 운영 환경에서 장애 대응력을 크게 높이는 효과를 가져온다.
프로메테우스, 그라파나 설정
- helm repo update
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm repo update
- prom-values 파일 작성
cat << EOF > prom-values-2.yaml prometheusOperator: tls: enabled: false admissionWebhooks: patch: enabled: false prometheus: service: type: NodePort nodePort: 30001 grafana: service: type: NodePort nodePort: 30002 EOF
- helm 설치
kubectl create ns prometheus helm install prom prometheus-community/kube-prometheus-stack --version 13.13.1 \ -n prometheus -f ch7/prom-values.yaml -f prom-values-2.yaml
- 배포 확인
helm list -n prometheus kubectl get sts,deploy,pod,svc,ep,cm,secret -n prometheus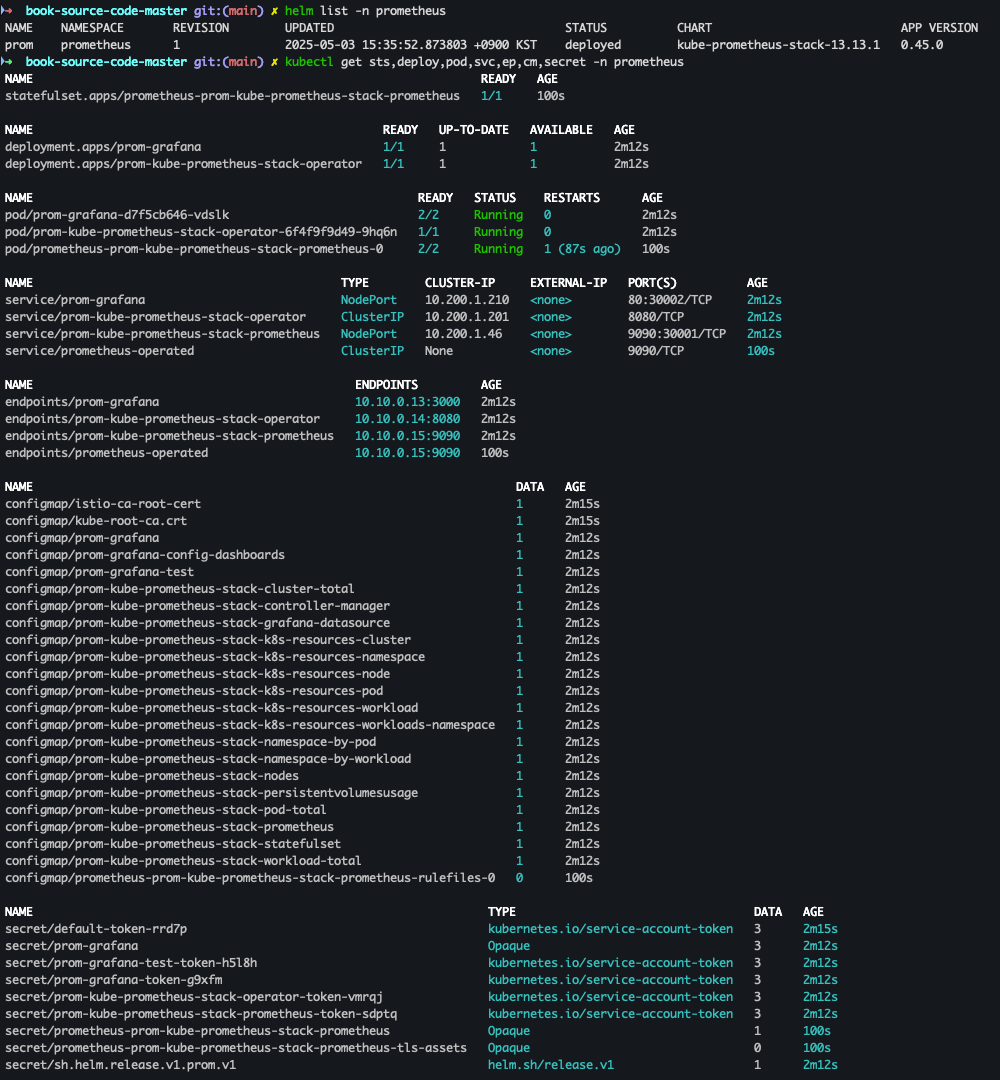
- prometheus, grafana 접속
# prometheus open http://127.0.0.1:30001 # grafana open http://127.0.0.1:30002
프로메테우스 오퍼레이터 설치
프로메테우스가 이스티오 매트릭을 수집하도록 설정하기 위해 프로메테우스 오퍼레이터의 커스텀 리소스 ServiceMonitor, PodMonitor를 사용할 것이다.
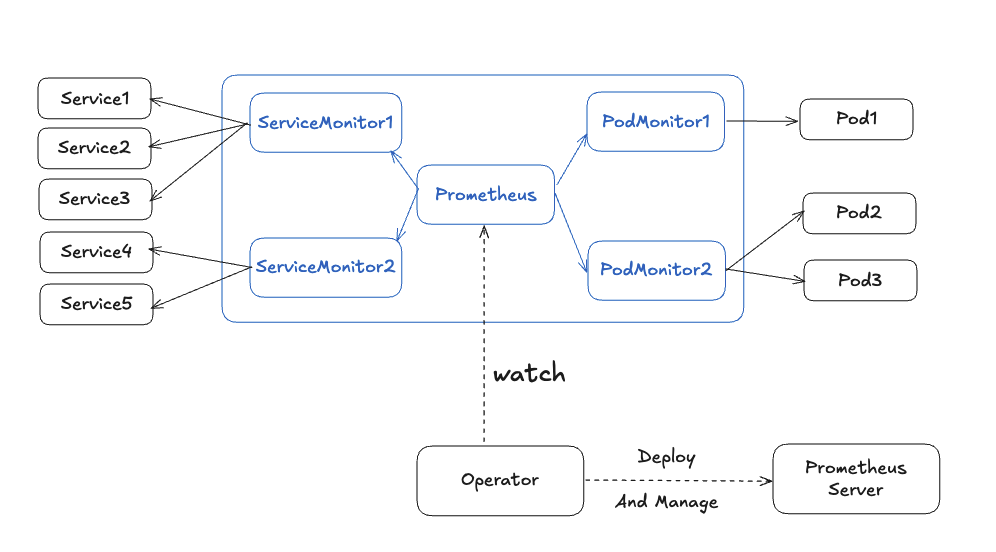
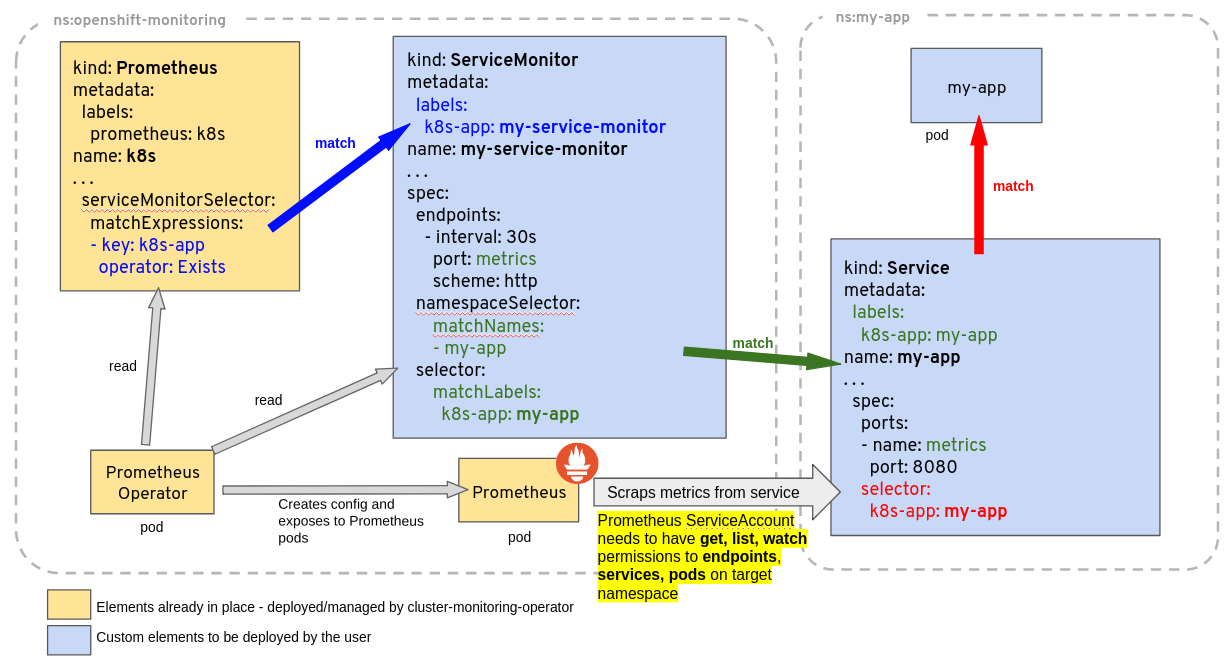
{kind=link}
이스티오 컨트롤 플레인 구성 요소를 수집할 수 있도록 ServiceMonitor리소스를 설정해야 하며.. 방법은 다음과 같습니다.
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: istio-component-monitor
namespace: prometheus
labels:
monitoring: istio-components
release: prom
spec:
jobLabel: istio
targetLabels: [app]
selector:
matchExpressions:
- {key: istio, operator: In, values: [pilot]}
namespaceSelector:
any: true
endpoints:
- port: http-monitoring # 15014
interval: 15s- selector 에 istio=pilot 매칭 확인
kubectl describe svc istiod -n istio-system kubectl get pod -n istio-system -l istio=pilot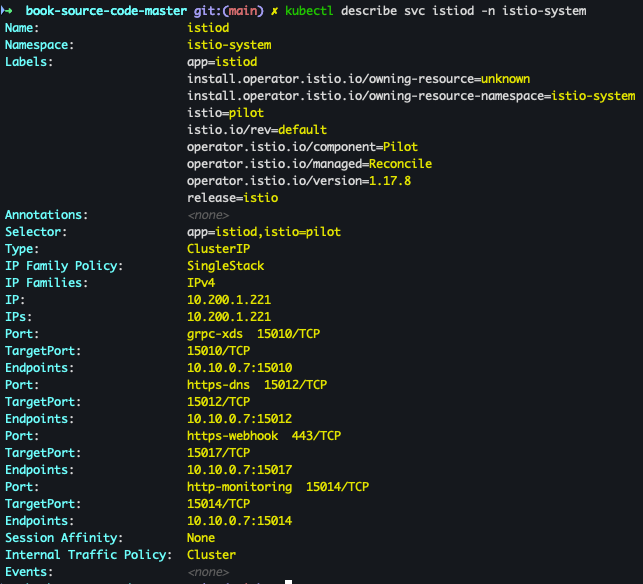

- Service Monitor 적용
kubectl apply -f ch7/service-monitor-cp.yaml -n prometheus
- 적용 확인
kubectl get servicemonitor -n prometheus kubectl get svc,ep istiod -n istio-system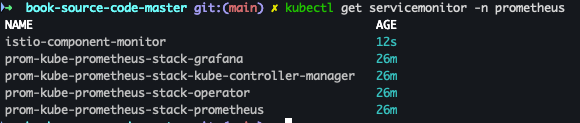

- 데이터 플레인 수집 활성화 - PodMonitor 리소스 사용
cat ch7/pod-monitor-dp.yaml kubectl apply -f ch7/pod-monitor-dp.yaml -n prometheus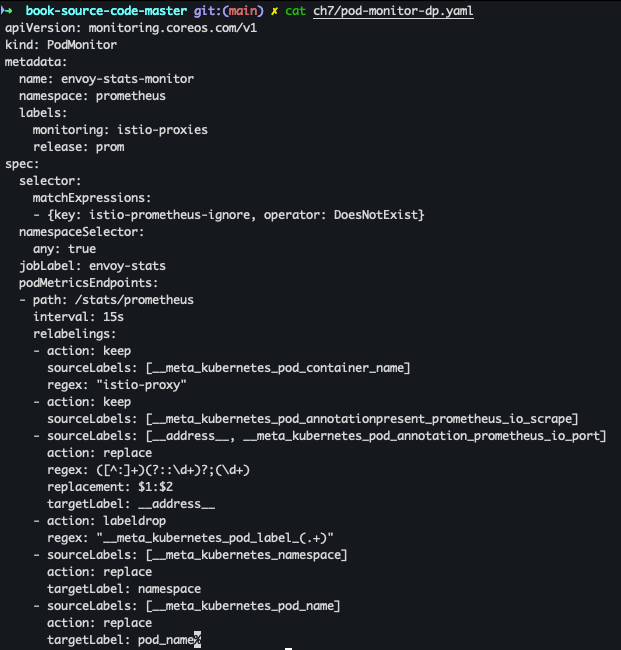
- PodMonitor 배포 확인
kubectl get podmonitor -n prometheus
- metric 확인을 위한 호출 테스트
for in in {1..10}; do curl -s http://webapp.istioinaction.io:30000/ ; sleep 0.5; done for in in {1..10}; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; sleep 0.5; done
- 반복 접속
while true; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done
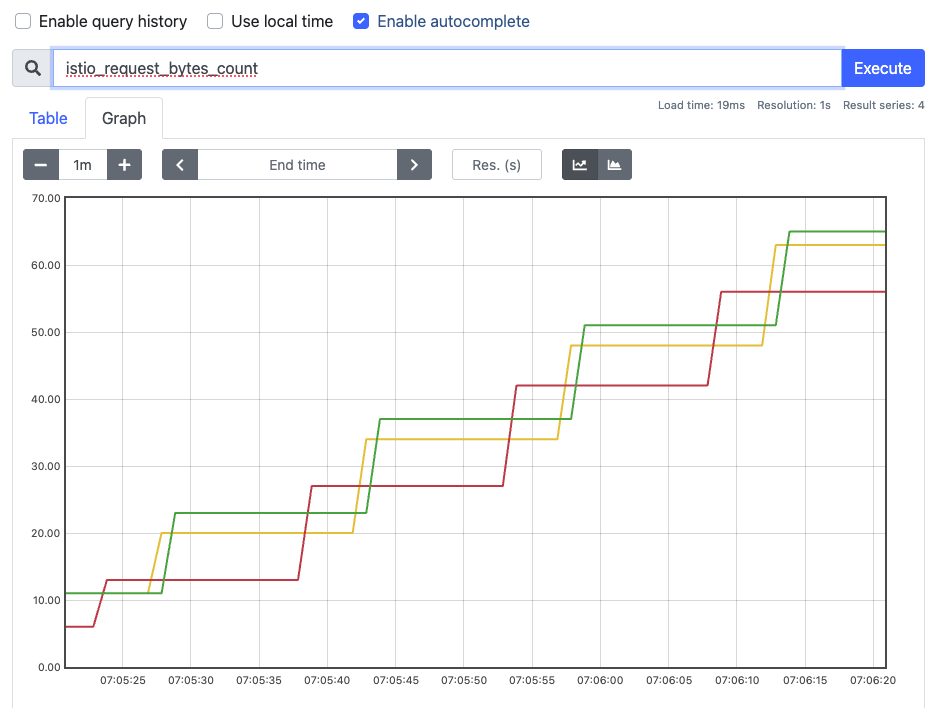
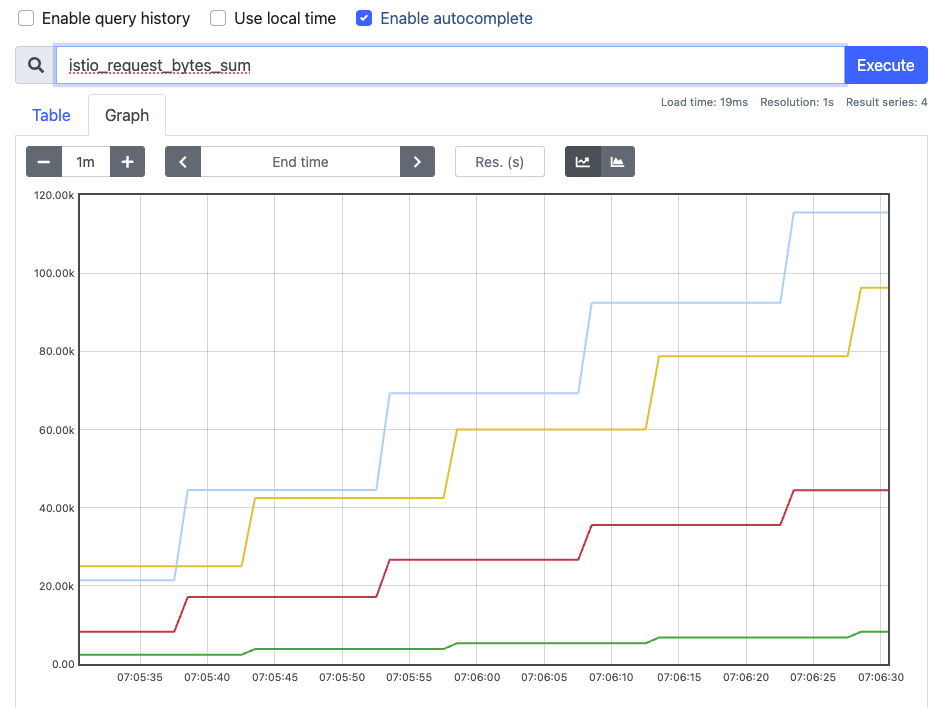
- prometheus →
istio_request_*확인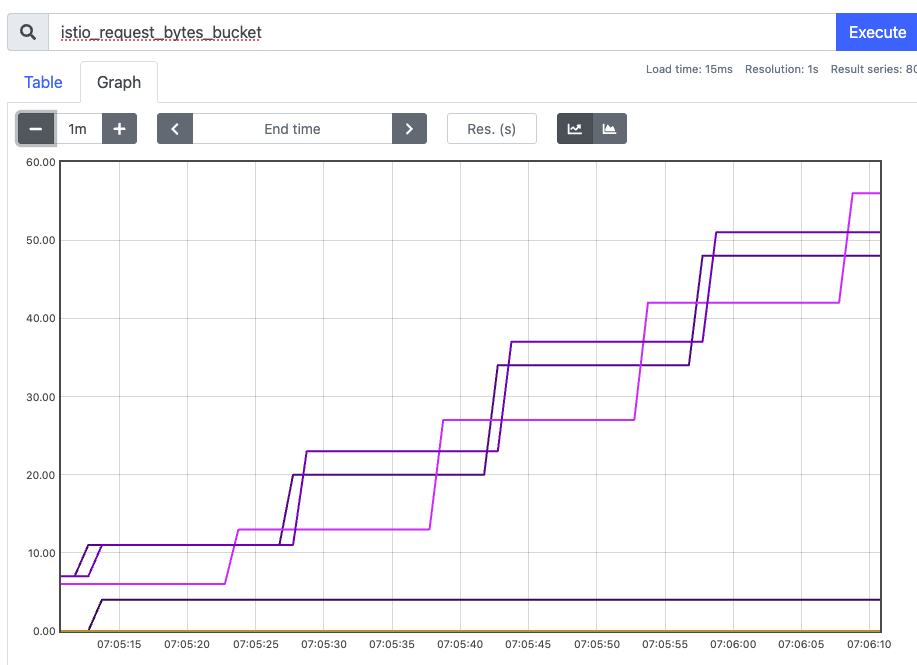
7.4 이스티오 표준 메트릭 커스텀
들어가며
stio는 서비스 메시의 관찰 가능성을 높이는 다양한 기본 메트릭을 제공합니다. 대표적인 표준 메트릭은 다음과 같습니다:
| 메트릭 이름 | 설명 |
|---|---|
| istio_requests_total | 서비스 호출의 총 개수를 카운트 |
| istio_request_duration_milliseconds | 요청 처리 시간의 분포 |
| istio_request_bytes | 요청 바디 크기의 분포 |
| istio_response_bytes | 응답 바디 크기의 분포 |
| istio_request_messages_total | gRPC 메시지 송신 횟수 |
| istio_response_messages_total | gRPC 메시지 수신 횟수 |
이러한 메트릭은 서비스 호출 간의 통신을 분석하고 성능을 평가하는 데 핵심적인 역할을 합니다.
메트릭의 구성요소: 디멘션(Dimension)
메트릭에는 하나 이상의 디멘션이 포함됩니다. 예를 들어, istio_requests_total 메트릭은 여러 디멘션을 통해 세부 정보를 제공합니다:
| 디멘션 이름 | 설명 |
|---|---|
| response_code | 응답 코드 (예: 200, 500) |
| reporter | 메트릭 보고자 (source/destination) |
| source_workload / destination_workload | 요청의 발신 및 수신 워크로드 |
| request_protocol | 요청 프로토콜 (HTTP, gRPC 등) |
| connection_security_policy | 보안 정책 (예: mutual_tls) |
디멘션이 다르면 동일한 메트릭이라도 별도의 항목으로 표시됩니다. 즉, HTTP 200 응답과 HTTP 500 응답은 별개로 집계됩니다.
속성(Attribute)이란?
속성은 디멘션의 값을 정의할 때 사용하는 값으로, Envoy 프록시가 런타임 중에 수집하는 데이터를 말합니다. 대표적인 요청 속성은 다음과 같습니다:
| 속성 이름 | 설명 |
|---|---|
| request.path | URL 경로 |
| request.host | 요청의 호스트 |
| request.method | 요청 메서드(GET, POST 등) |
| request.protocol | 요청 프로토콜 |
| request.useragent | 사용자 에이전트 헤더 |
속성은 요청 속성뿐 아니라 응답 속성, 연결 속성, 업스트림 속성 등 다양한 범주로 나뉩니다. 속성의 전체 목록은 Envoy 공식 문서를 참조할 수 있습니다.
Istio 전용 메타데이터 속성
Istio는 자체 메타데이터 필터(peer-metadata)를 통해 추가적인 속성을 제공합니다:
이 속성들은 메트릭을 좀 더 세부적이고 정교하게 만들 때 유용하며, 메트릭 설정에서 upstream_peer 또는 downstream_peer 접두사를 사용하여 원하는 속성을 쉽게 선택할 수 있습니다.
기존 메트릭 확인
- 메트릭 정보 수정 시 모든 버전의 envoyfilter 에 반영(업데이트)되는지 확인
kubectl get envoyfilter -n istio-system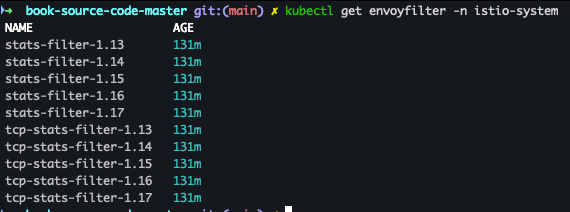
{kind=link}
기존 메트릭에 디멘션 추가
upstream_proxy_version 및 source_mesh_id 디멘션을 추가 한다고 가정합니다.
- 배포 파일 확인
cat ch7/metrics/istio-operator-new-dimensions.yaml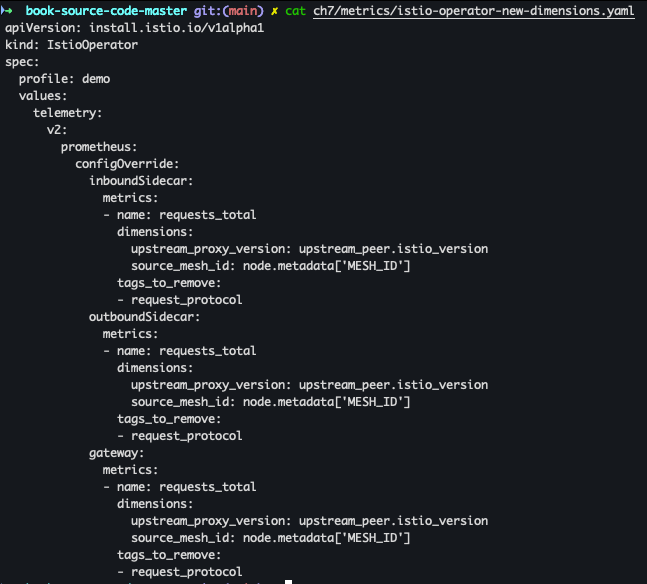
- 기존 설정 확인
kubectl get istiooperator installed-state -n istio-system -o yaml | grep -E "prometheus:|telemetry:" -A2
- 메트릭 확인 (request_protocol 디멘션 존재 여부)
kubectl -n istioinaction exec -it deploy/webapp -c istio-proxy \ -- curl localhost:15000/stats/prometheus | grep istio_requests_total
- 컨테이너 접속
docker exec -it myk8s-control-plane bashdocker exec -it myk8s-control-plane bash
- 파일 작성
cat << EOF > istio-operator-new-dimensions.yaml apiVersion: install.istio.io/v1alpha1 kind: IstioOperator spec: profile: demo values: telemetry: v2: prometheus: configOverride: inboundSidecar: metrics: - name: requests_total dimensions: upstream_proxy_version: upstream_peer.istio_version source_mesh_id: node.metadata['MESH_ID'] tags_to_remove: - request_protocol outboundSidecar: metrics: - name: requests_total dimensions: upstream_proxy_version: upstream_peer.istio_version source_mesh_id: node.metadata['MESH_ID'] tags_to_remove: - request_protocol gateway: metrics: - name: requests_total dimensions: upstream_proxy_version: upstream_peer.istio_version source_mesh_id: node.metadata['MESH_ID'] tags_to_remove: - request_protocol EOF
- 리소스별 적용 결과 출력 및 배포
istioctl verify-install -f istio-operator-new-dimensions.yaml # 리소스별로 적용결과를 출력 istioctl install -f istio-operator-new-dimensions.yaml -y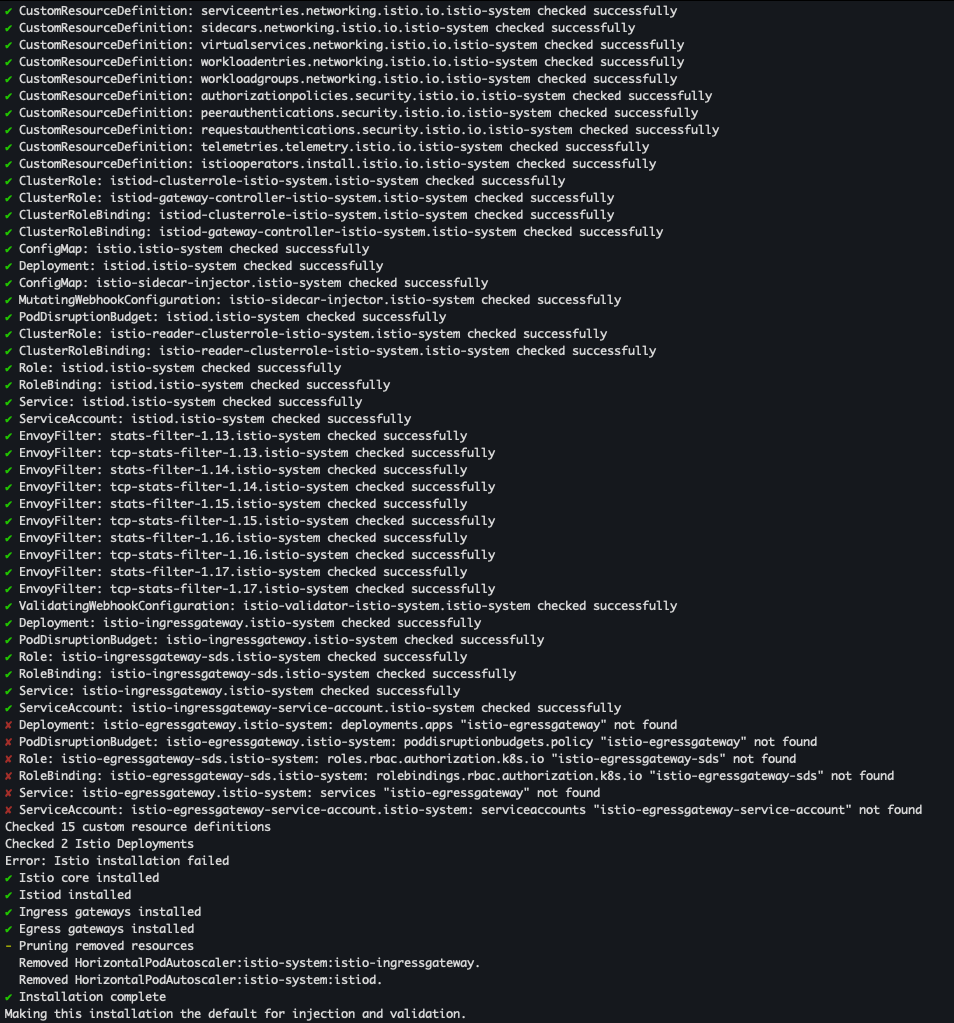
- 변경 설정 확인
kubectl get istiooperator -n istio-system installed-state -o yaml | grep -E "prometheus:" -A9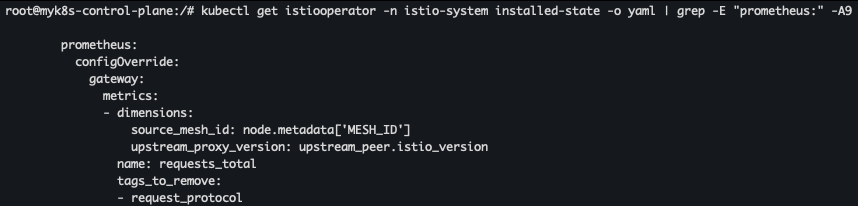
- envoyfilter 확인
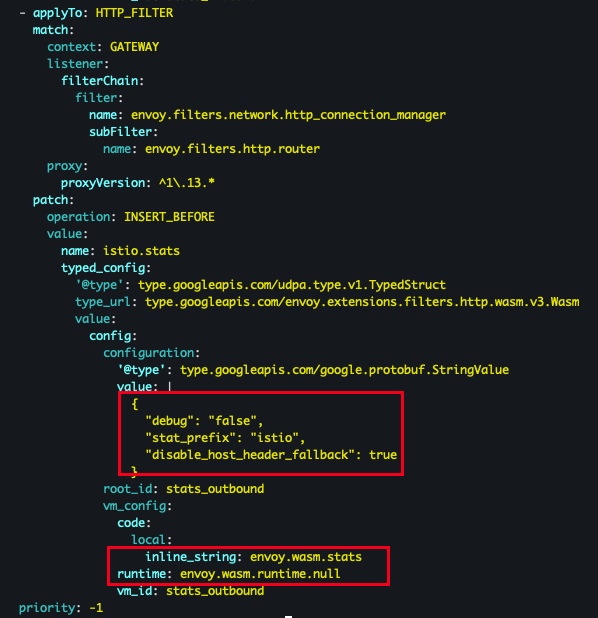
kubectl get envoyfilter stats-filter-1.13 -n istio-system -o yaml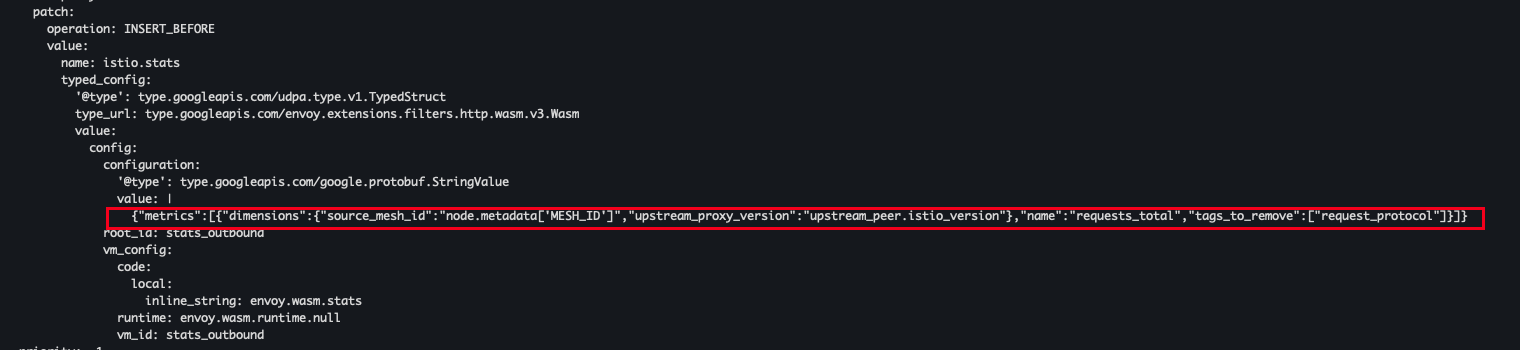
- 파드 어노테이션 설정
cat ch7/metrics/webapp-deployment-extrastats.yaml kubectl apply -n istioinaction -f ch7/metrics/webapp-deployment-extrastats.yaml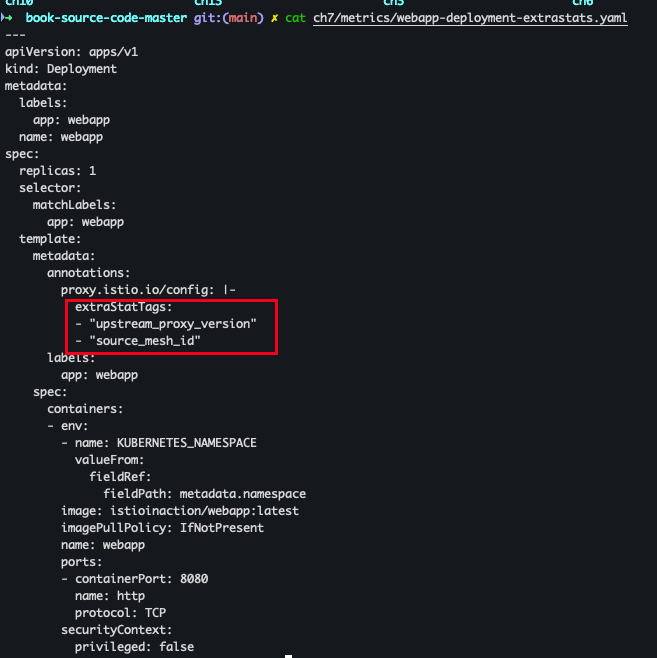
- metric 확인을 위한 호출 테스트 진행
for in in {1..10}; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; sleep 0.5; done while true; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; donefor in in {1..10}; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; sleep 0.5; done while true; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done
- 프로메테우스 UI 에서 확인 :
istio_requests_total- Link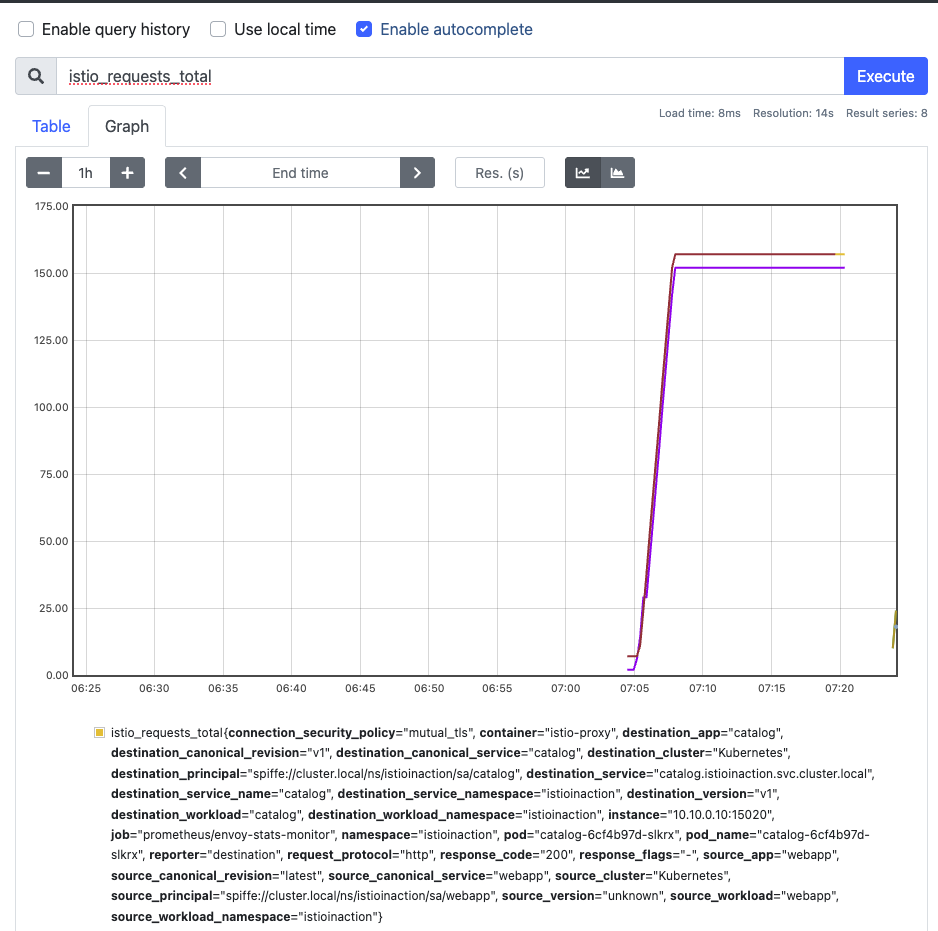
새로운 메트릭 생성
새로운 매트릭을 생성하기 위해선 stats 플러그인에 새 메트릭을 정의하면 됩니다.
- 배포 파일 확인 :
get_calls정의 ( istio_ 접두사는 매트릭 생성시 자동으로 붙는다)cat ch7/metrics/istio-operator-new-metric.yaml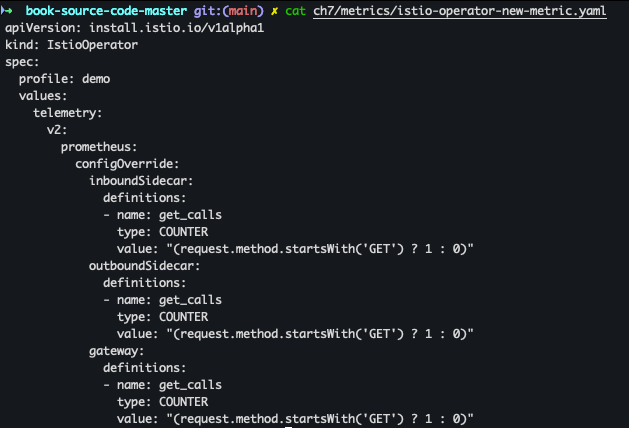
- 매트릭 적용
docker exec -it myk8s-control-plane bash cat << EOF > istio-operator-new-metric.yaml apiVersion: install.istio.io/v1alpha1 kind: IstioOperator spec: profile: demo values: telemetry: v2: prometheus: configOverride: inboundSidecar: definitions: - name: get_calls type: COUNTER value: "(request.method.startsWith('GET') ? 1 : 0)" outboundSidecar: definitions: - name: get_calls type: COUNTER value: "(request.method.startsWith('GET') ? 1 : 0)" gateway: definitions: - name: get_calls type: COUNTER value: "(request.method.startsWith('GET') ? 1 : 0)" EOF istioctl verify-install -f istio-operator-new-metric.yaml # 리소스별로 적용결과를 출력 istioctl install -f istio-operator-new-metric.yaml -y
- 배포 확인
kubectl get istiooperator -n istio-system installed-state -o yaml | grep -A2 get_calls$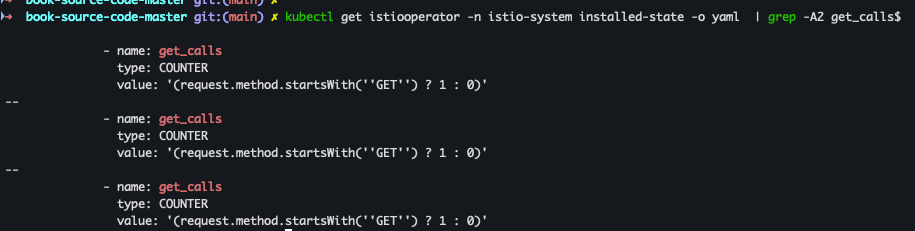
- 배포 확인 2
kubectl get envoyfilter -n istio-system stats-filter-1.13 -o yaml | grep get_calls
- 메트릭을 만들때는 프록시에 노출하라고 이스티오에 적용 필요 → 1.17 버전 부턴 별도로 적용 안해도 됨
cat ch7/metrics/webapp-deployment-new-metric.yaml kubectl -n istioinaction apply -f ch7/metrics/webapp-deployment-new-metric.yaml
- 호출 테스트
for in in {1..10}; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; sleep 0.5; done while true; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done
- 메트릭 확인
kubectl -n istioinaction exec -it deploy/webapp -c istio-proxy -- curl localhost:15000/stats/prometheus | grep istio_get_calls
- 프로메테우스 UI 확인 : istio_get_calls - Link
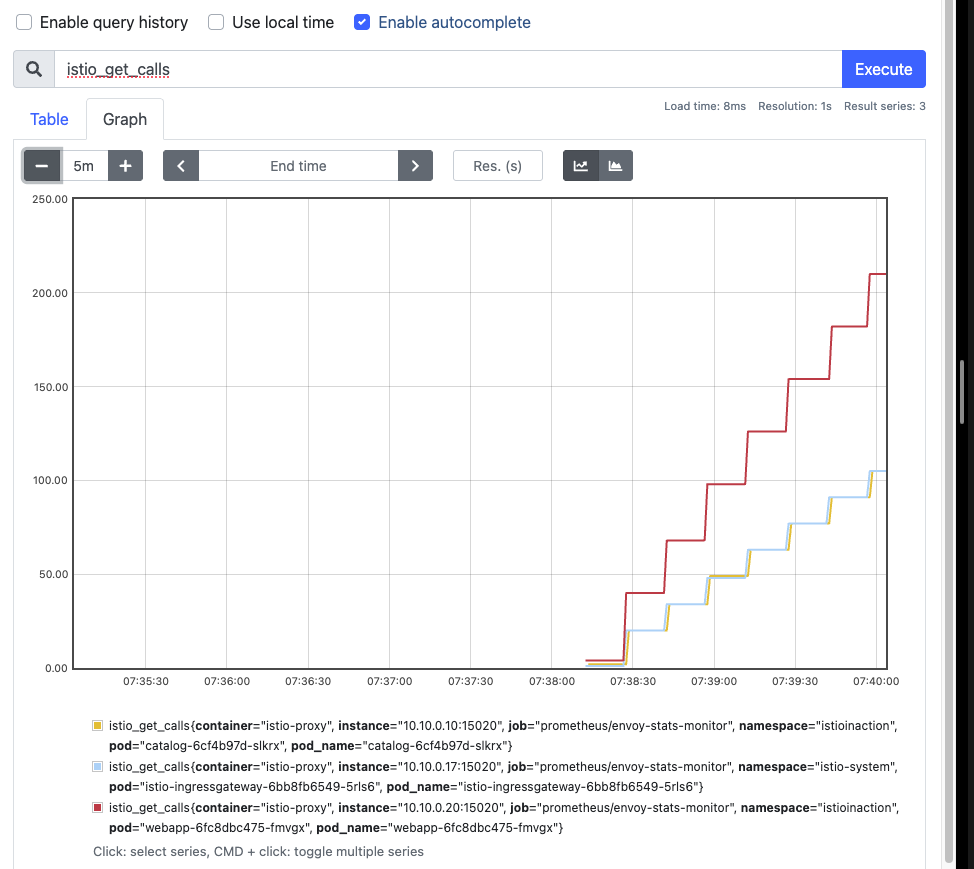
새 속성으로 호출 그룹화 하기
기존 속성을 기반으로 더 세분화하거나, 도메인에 특화해 새 속성을 만들수 있습니다.
예를 들어 quest.path_url 과 request.method 를 조합해 catalog 서비스의 /items API로 가는 GET 호출 개수를 추적하는 istio_operationId를 만들수 있습니다.
이를 위해서 attribute-gen 프록시 플러그인을 사용한다.
- 예시
cat ch7/metrics/attribute-gen.yaml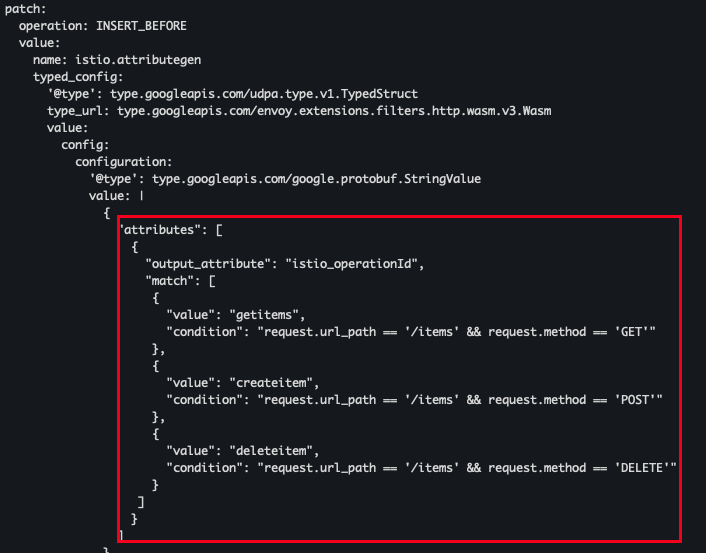
이제 본격적으로 생성을 진행해보자
- istio version 체크
docker exec -it myk8s-control-plane istioctl version
- attribute-gen.yaml proxyVersion 변경
vi ch7/metrics/attribute-gen.yaml ... proxy: proxyVersion: ^1\.17.* # 수정 ...
- envoyfilter 배포 진행
kubectl apply -f ch7/metrics/attribute-gen.yaml -n istioinaction
- upstream_operator 추가
docker exec -it myk8s-control-plane bash ----------------------------------------- cat << EOF > istio-operator-new-attribute.yaml apiVersion: install.istio.io/v1alpha1 kind: IstioOperator spec: profile: demo values: telemetry: v2: prometheus: configOverride: outboundSidecar: metrics: - name: requests_total dimensions: upstream_operation: istio_operationId # 새 디멘션 EOF istioctl verify-install -f istio-operator-new-attribute.yaml # 리소스별로 적용결과를 출력 istioctl install -f istio-operator-new-attribute.yaml -y exit
- 배포 확인 - outboundSidecar 에만 적용 된 것을 확인
kubectl get istiooperator -n istio-system installed-state -o yaml | grep -B2 -A1 istio_operationId$
- 배포 상세 확인
kubectl get envoyfilter -n istio-system stats-filter-1.17 -o yaml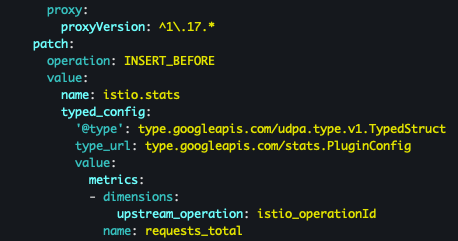
- 호출 테스트
for in in {1..10}; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; sleep 0.5; done while true; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done
- metric 확인
kubectl -n istioinaction exec -it deploy/webapp -c istio-proxy -- curl localhost:15000/stats/prometheus | grep istio_requests_total
- 프로메테우스 UI :
istio_requests_total{upstream_operation!=""}- Link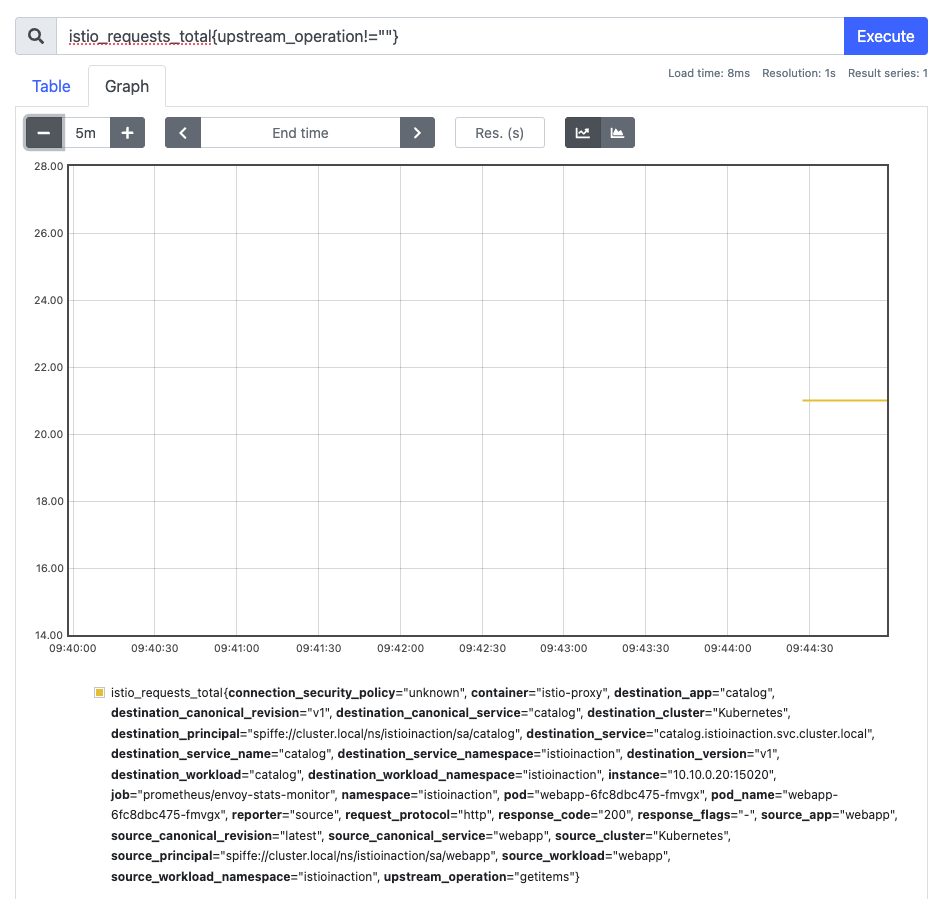
8. 관찰가능성 Observability : Visualizing network behavior with Grafana, Jaeger, and Kiali
8.1 그라파나로 이스티오 서비스와 컨트롤 플레인 메트릭 시각화
이스티오의 그라파나 대시보드 설정하기
- 그라파나 접속 - admin / prom-operator
open http://127.0.0.1:30002/dashboards
- 메트릭 수집을 위한 반복 호출
while true; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done
- 대시보드 추가 설정
cd ch8 kubectl -n prometheus create cm istio-dashboards \ --from-file=pilot-dashboard.json=dashboards/\ pilot-dashboard.json \ --from-file=istio-workload-dashboard.json=dashboards/\ istio-workload-dashboard.json \ --from-file=istio-service-dashboard.json=dashboards/\ istio-service-dashboard.json \ --from-file=istio-performance-dashboard.json=dashboards/\ istio-performance-dashboard.json \ --from-file=istio-mesh-dashboard.json=dashboards/\ istio-mesh-dashboard.json \ --from-file=istio-extension-dashboard.json=dashboards/\ istio-extension-dashboard.json
- 적용 확인
cd .. kubectl describe cm -n prometheus istio-dashboards
- Grafana 가 configmap(istio-dashboards)를 마운트하도록 레이블 지정
kubectl label -n prometheus cm istio-dashboards grafana_dashboard=1
- Grafana 대시보드 확인
컨트롤 플레인 메트릭 보기
- 그라파나 대시보드 → Istio Control Plane Dashboard 선택
- Pilot Push Information → Pilot Pushes 오른쪽 클릭 → Explore 클릭
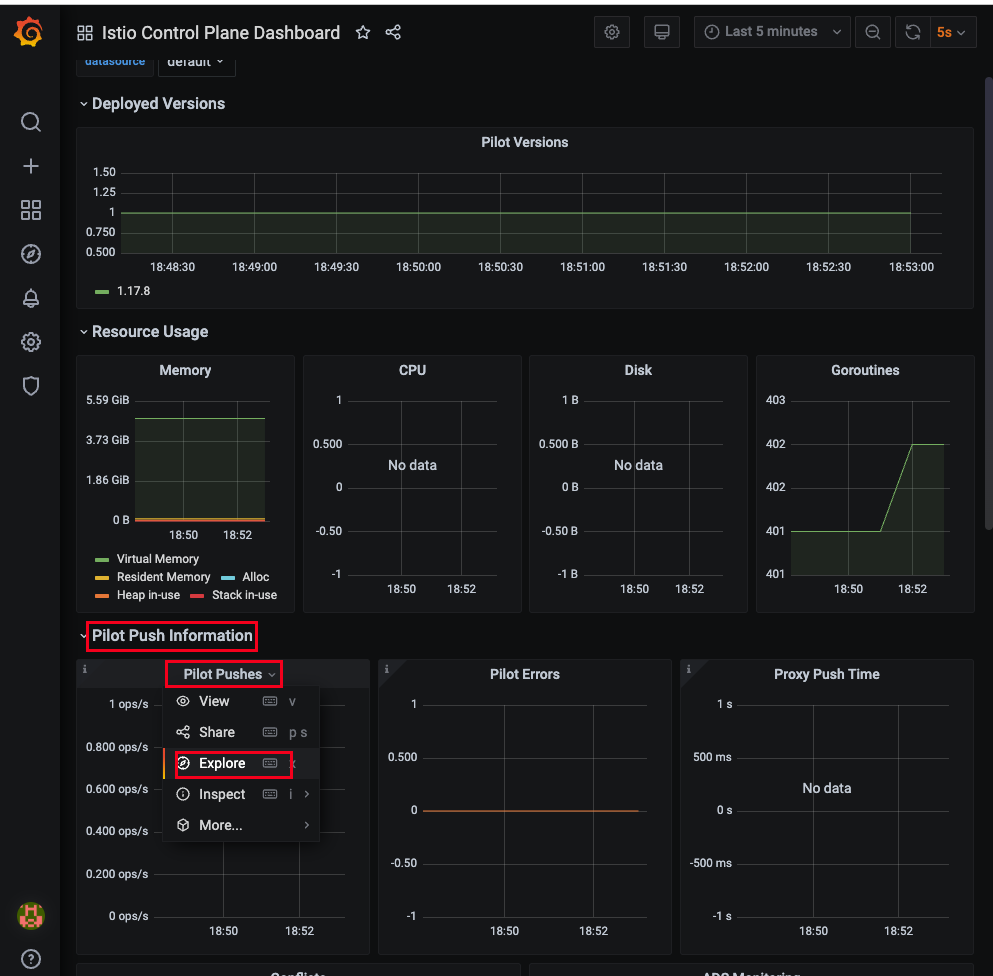
- 해당 코드 복사
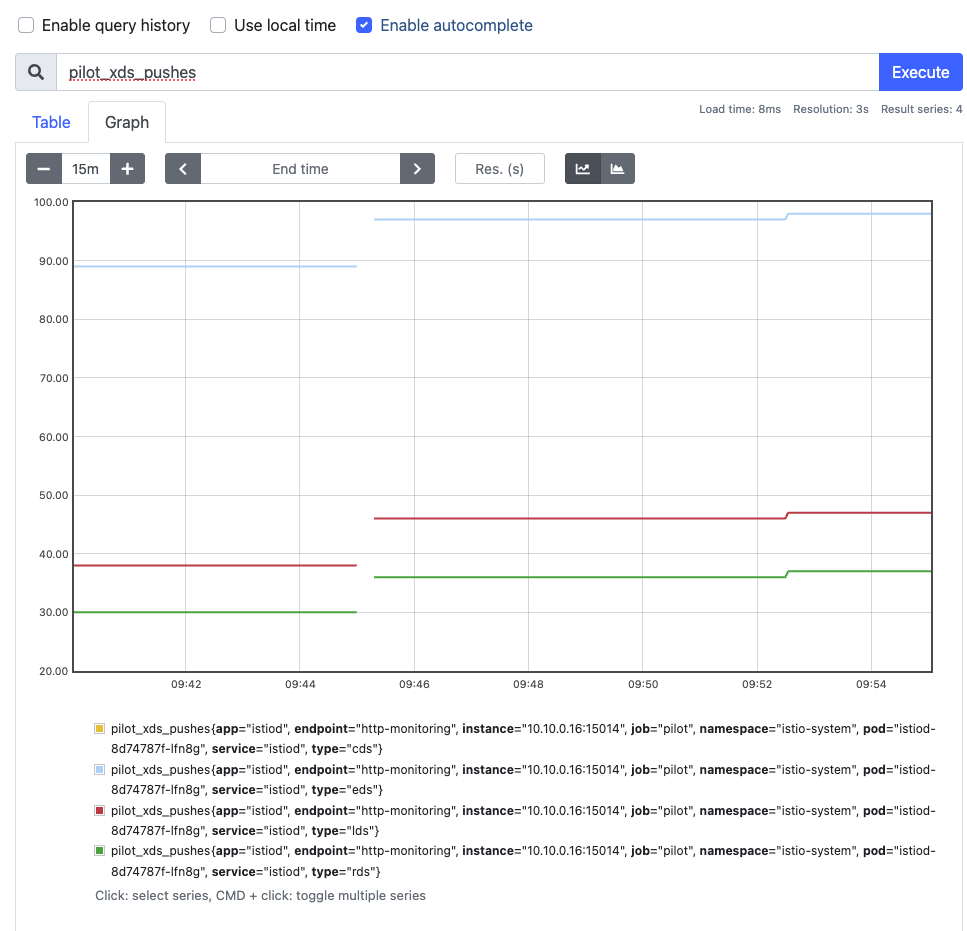
sum(irate(pilot_xds_pushes{type="rds"}[1m]))
- 해당 쿼리를 프로메테우스에서 확인 : pilot_xds_pushes - Link
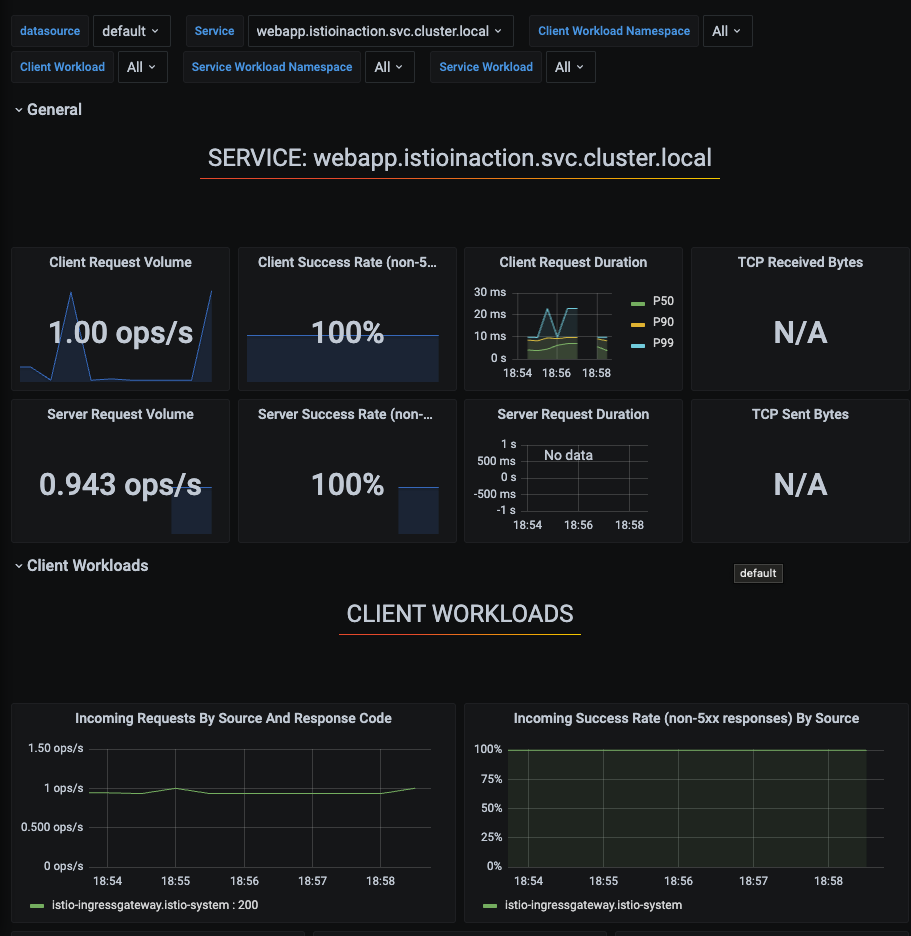
데이터 플레인 메트릭 보기
- 그라파나 대시보드 → Istio Service Dashboard 선택
- Service 선택하여 모니터링 진행 가능
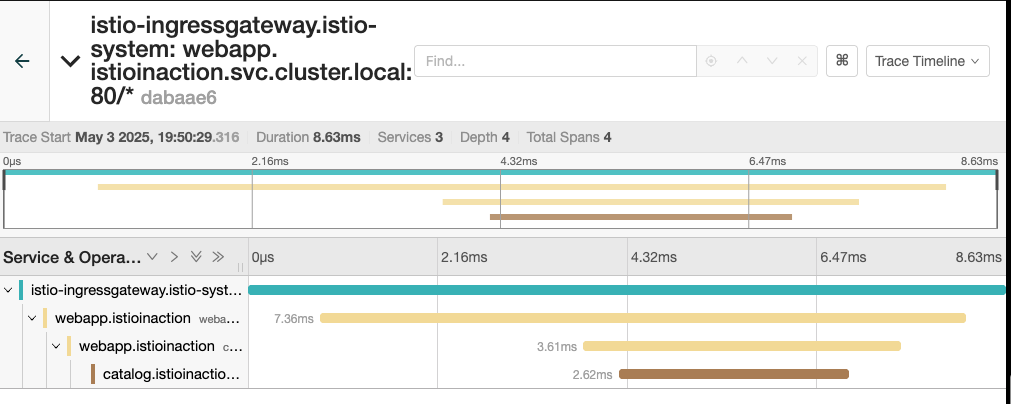
8.2 분산트레이싱
들어가며 - 분산 트레이싱의 필요성
마이크로서비스 환경에서는 장애를 빠르게 진단하는 것이 매우 중요합니다. 특히 분산 트레이싱(Distributed Tracing)은 이러한 진단에 효과적인 방법 중 하나입니다. 마이크로서비스 아키텍처가 확산됨에 따라 서비스 간의 복잡한 네트워크가 형성되고 있으며, 요청 흐름에서 문제가 발생할 경우 이를 정확히 파악하는 능력이 필수적입니다.
기존의 모놀리스(monolith) 환경에서는 런타임 프로파일러나 메모리 분석 도구 등을 활용하여 문제를 신속하게 진단할 수 있었습니다. 그러나 마이크로서비스와 같은 분산 환경에서는 이에 적합한 새로운 도구들이 필요합니다. 분산 트레이싱은 구글의 "대퍼(Dapper)" 논문에서 처음 소개된 개념으로, 서비스 간 이동하는 요청에 고유한 주석을 붙여 추적하는 방식을 사용합니다. 이 주석에는 서비스 간 호출 관계를 나타내는 상관관계 ID(correlation ID) 와 개별 요청 흐름을 추적하는 트레이스 ID(trace ID) 가 포함됩니다.
이러한 메타데이터를 통해 특정 요청이 시스템 내에서 어떻게 처리되고 있는지를 전체적으로 시각화하여 이해할 수 있습니다. 예를 들어, 이스티오(Istio)는 서비스 메시를 통해 데이터 플레인을 지나는 요청에 이러한 ID를 자동으로 추가하고, 외부에서 전달되었거나 인식되지 않는 메타데이터는 제거함으로써 보안을 유지합니다. 대표적으로 x-request-id 헤더를 활용해 트레이스를 관리합니다.
- *오픈텔레메트리(OpenTelemetry)는 분산 트레이싱을 위한 커뮤니티 주도의 표준으로, 메트릭, 로그, 트레이스 데이터를 계측하고 수집하며 분석할 수 있도록 도와주는 도구 모음입니다. 또한, 오픈텔레메트리는 기존의 오픈트레이싱(OpenTracing) 표준을 포함하고 있어 개발자분들께서 분산 트레이싱을 보다 쉽게 도입할 수 있도록 지원합니다.
다만, 분산 트레이싱은 어느 정도 개발자의 개입이 필요한 영역입니다. 특히, 서비스가 요청을 처리하고 다른 시스템으로 요청을 전달할 때에는 트레이스 ID나 상관관계 ID를 추가하는 작업, 즉 코드 계측이 필요합니다.
이스티오와 같은 서비스 메시를 도입하시면 이러한 계측 작업에 대한 개발자의 부담을 줄일 수 있으며, 분산 트레이싱을 자동화하여 서비스 간 통신에서 발생하는 문제를 신속하게 진단하고 해결하실 수 있습니다.
분산 트레이싱은 어떻게 작동하는가?
마이크로서비스 아키텍처가 확산됨에 따라, 하나의 요청이 여러 서비스와 컴포넌트를 거치며 처리되는 구조가 일반화되고 있습니다. 이로 인해 장애가 발생했을 때 원인을 추적하고 진단하는 일이 점점 더 어려워지고 있습니다. 이러한 상황에서 분산 트레이싱은 문제 해결을 위한 강력한 도구로 자리 잡고 있습니다.
분산 트레이싱의 기본 단위: 스팬(Span)
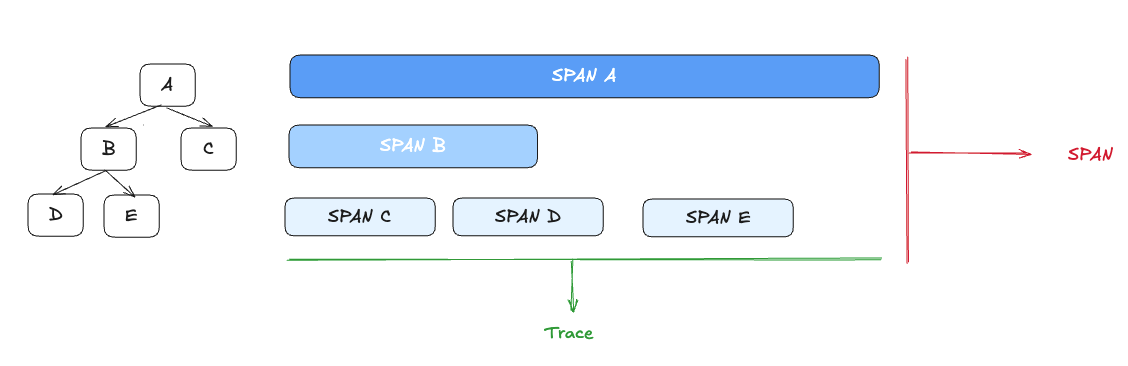
가장 단순한 형태의 오픈트레이싱 기반 분산 트레이싱은 다음 세 가지로 구성됩니다
- 애플리케이션이 스팬(Span)을 생성하고,
- 이를 오픈트레이싱 엔진과 공유하며,
- 이후 호출하는 서비스로 트레이스 콘텍스트(trace context)를 전파합니다.
여기서 스팬이란, 서비스나 구성 요소 내에서 수행되는 작업 단위를 나타내는 데이터 모음이며, 시작 시간, 종료 시간, 작업 이름, 태그, 로그 등의 정보를 포함합니다. 모든 서비스는 자신이 처리한 부분에 대해 새로운 스팬을 생성하고, 이를 트레이싱 엔진에 전달하면서 트레이스 콘텍스트를 다음 서비스로 전달하게 됩니다.
이러한 방식으로 각 서비스의 스팬들이 연결되어 하나의 트레이스(trace)를 구성하게 되며, 이 트레이스는 호출 흐름의 인과관계, 타이밍, 구조를 시각적으로 파악할 수 있도록 도와줍니다.
이스티오와 분산 트레이싱
Istio는 서비스 메시 내부에서 이러한 분산 트레이싱을 자동으로 수행할 수 있도록 지원합니다. 이스티오 프록시는 요청이 들어올 때 자동으로 스팬을 생성하고, Zipkin 트레이싱 헤더를 요청에 추가하여 이후 호출들 간의 상관관계를 유지합니다.
이스티오가 사용하는 주요 트레이싱 헤더는 다음과 같습니다:
x-request-idx-b3-traceidx-b3-spanidx-b3-parentspanidx-b3-sampledx-b3-flagsx-ot-span-context
이러한 헤더들은 서비스 간 요청 흐름을 연결해주는 핵심 정보로, 반드시 모든 애플리케이션이 해당 헤더를 다음 호출에 전파해야 전체 트레이스가 끊기지 않고 유지됩니다.
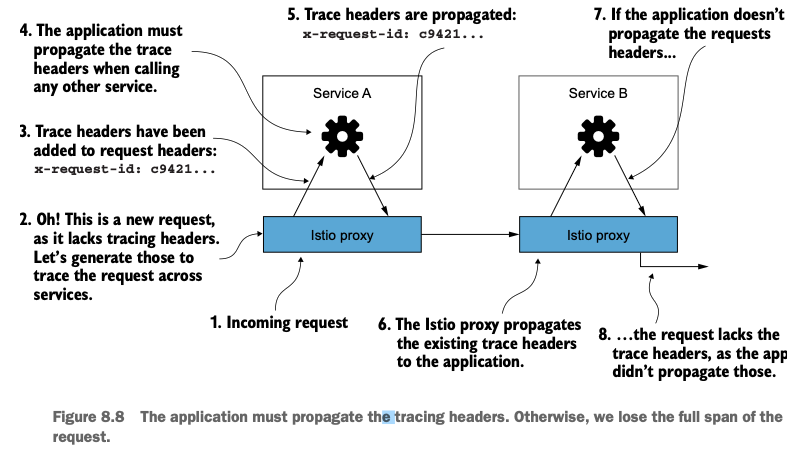
애플리케이션의 역할
이스티오는 자동으로 헤더를 생성하고 전달할 수 있지만, 애플리케이션 자체가 이 헤더들을 전파하는 책임을 반드시 져야 합니다. 예를 들어, 애플리케이션이 HTTP 요청을 보낼 때 위의 트레이싱 헤더를 포함시키지 않으면 트레이스 정보가 단절되며, 호출 그래프를 온전히 파악할 수 없게 됩니다.
다행히도 대부분의 RPC 프레임워크나 HTTP 클라이언트는 오픈트레이싱과의 통합을 지원하며, 이를 통해 헤더 전파를 자동화할 수 있습니다. 그러나 그렇지 않은 경우라면 애플리케이션 개발자가 직접 이를 처리해야 합니다.
대표적인 오픈트레이싱 구현체
현재 널리 사용되는 오픈트레이싱 기반 구현체로는 다음과 같은 시스템들이 있습니다:
- Jaeger
- Zipkin
- Lightstep
- Instana
이 중 이스티오는 주로 Jaeger 또는 Zipkin과 연동하여 분산 트레이싱 기능을 수행합니다.
분산 트레이싱 시스템 설치하기
예거 설치는 DB가 별도로 필요합니다.
이러한 이유로 이 책에서는 예거의 일체형 배포 샘플을 그대로 사용합니다.
- 이스티오 sample 디렉터리에서 예거 일체형 배포를 설치
# myk8s-control-plane 진입 후 설치 진행 docker exec -it myk8s-control-plane bash ----------------------------------- # 설치 파일 확인 ls istio-$ISTIOV/samples/addons cat istio-$ISTIOV/samples/addons/jaeger.yaml # 설치 kubectl apply -f istio-$ISTIOV/samples/addons/jaeger.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: jaeger
namespace: istio-system
labels:
app: jaeger
spec:
selector:
matchLabels:
app: jaeger
template:
metadata:
labels:
app: jaeger
sidecar.istio.io/inject: "false"
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "14269"
spec:
containers:
- name: jaeger
image: "docker.io/jaegertracing/all-in-one:1.35"
env:
- name: BADGER_EPHEMERAL
value: "false"
- name: SPAN_STORAGE_TYPE
value: "badger"
- name: BADGER_DIRECTORY_VALUE
value: "/badger/data"
- name: BADGER_DIRECTORY_KEY
value: "/badger/key"
- name: COLLECTOR_ZIPKIN_HOST_PORT
value: ":9411"
- name: MEMORY_MAX_TRACES
value: "50000"
- name: QUERY_BASE_PATH
value: /jaeger
livenessProbe:
httpGet:
path: /
port: 14269
readinessProbe:
httpGet:
path: /
port: 14269
volumeMounts:
- name: data
mountPath: /badger
resources:
requests:
cpu: 10m
volumes:
- name: data
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
name: tracing
namespace: istio-system
labels:
app: jaeger
spec:
type: ClusterIP
ports:
- name: http-query
port: 80
protocol: TCP
targetPort: 16686
# Note: Change port name if you add '--query.grpc.tls.enabled=true'
- name: grpc-query
port: 16685
protocol: TCP
targetPort: 16685
selector:
app: jaeger
---
# Jaeger implements the Zipkin API. To support swapping out the tracing backend, we use a Service named Zipkin.
apiVersion: v1
kind: Service
metadata:
labels:
name: zipkin
name: zipkin
namespace: istio-system
spec:
ports:
- port: 9411
targetPort: 9411
name: http-query
selector:
app: jaeger
---
apiVersion: v1
kind: Service
metadata:
name: jaeger-collector
namespace: istio-system
labels:
app: jaeger
spec:
type: ClusterIP
ports:
- name: jaeger-collector-http
port: 14268
targetPort: 14268
protocol: TCP
- name: jaeger-collector-grpc
port: 14250
targetPort: 14250
protocol: TCP
- port: 9411
targetPort: 9411
name: http-zipkin
selector:
app: jaeger- 설치 확인
kubectl get deploy,pod,svc,ep -n istio-system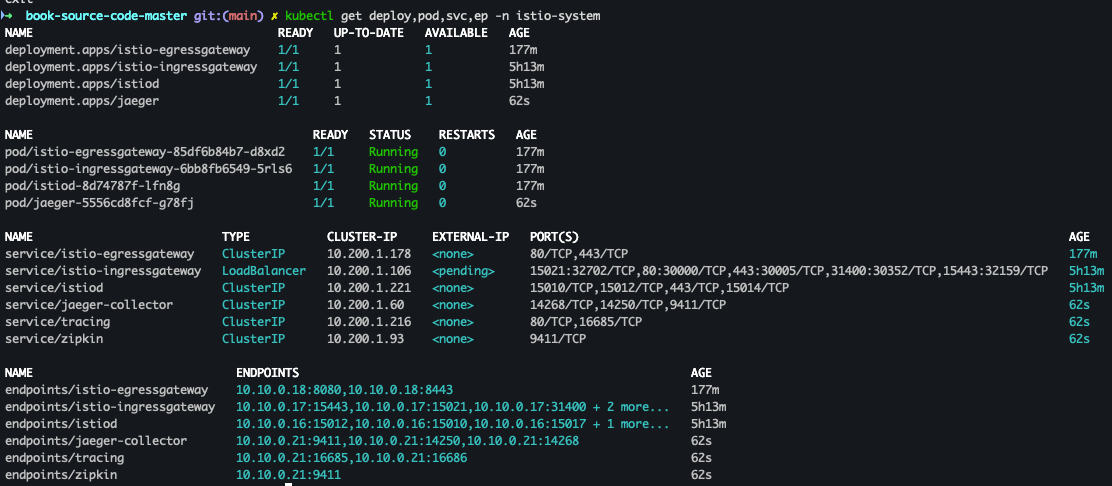
- Service 확인
kubectl describe svc -n istio-system tracing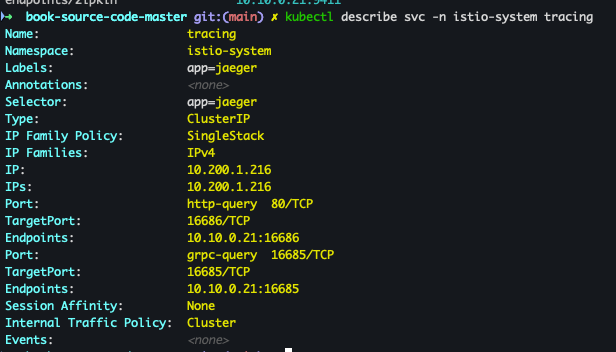
- NodePort 설정
kubectl patch svc -n istio-system tracing -p '{"spec": {"type": "NodePort", "ports": [{"port": 80, "targetPort": 16686, "nodePort": 30004}]}}'
- 예거 트레이싱 대시보드 확인
open http://127.0.0.1:30004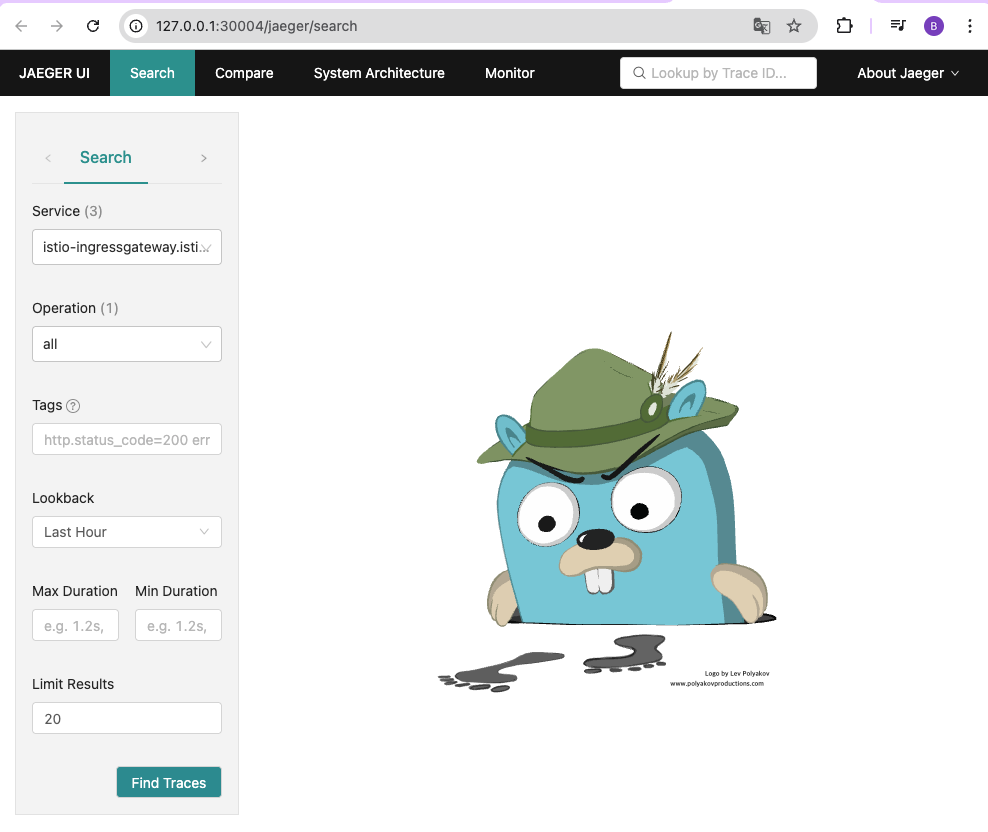
분산 트레이싱을 수행하도록 이스티오 설정
- control-plane 접근
docker exec -it myk8s-control-plane bash
- install-istio-tracing-zipkin.yaml 생성
cat << EOF > install-istio-tracing-zipkin.yaml apiVersion: install.istio.io/v1alpha1 kind: IstioOperator metadata: namespace: istio-system spec: meshConfig: defaultConfig: tracing: sampling: 100 zipkin: address: zipkin.istio-system:9411 EOF
- 배포
istioctl install -y -f install-istio-tracing-zipkin.yaml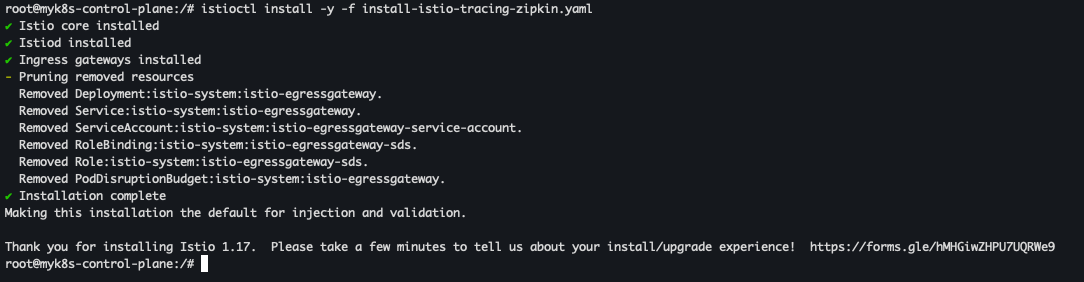
- 컨테이너 나가기
exit
- 배포 확인
kubectl describe cm -n istio-system istio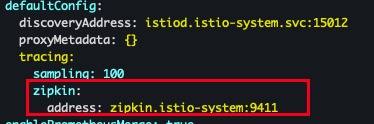
분산 트레이싱 데이터 보기
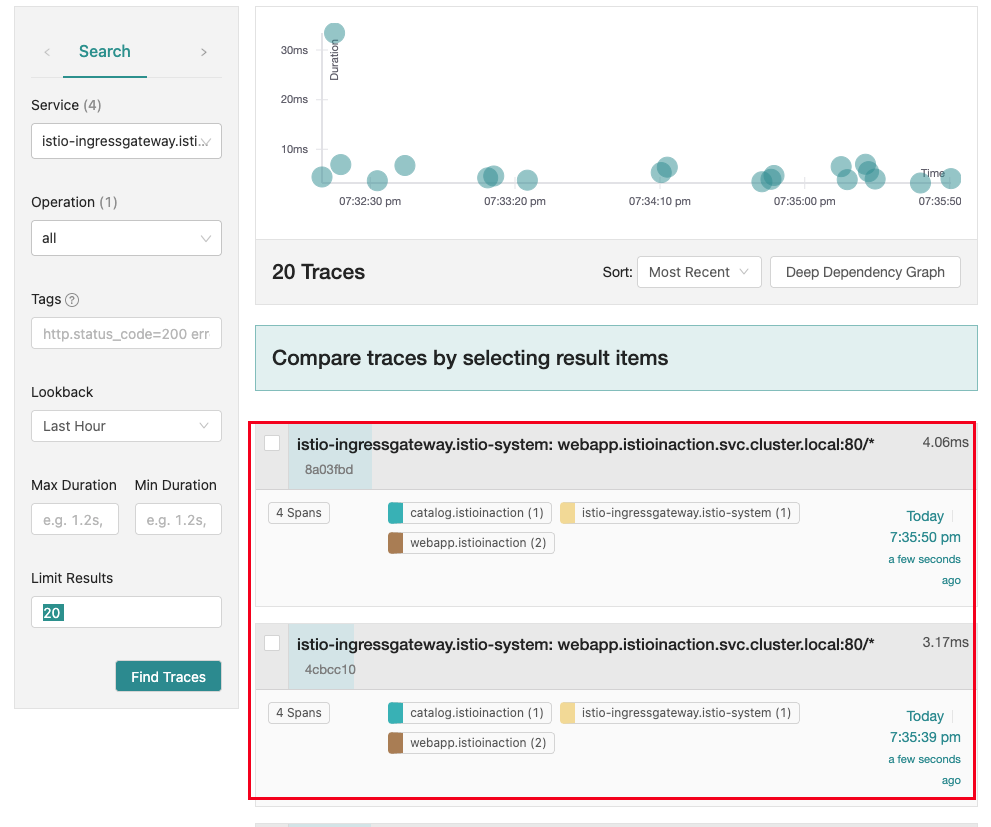
- 기본 검색
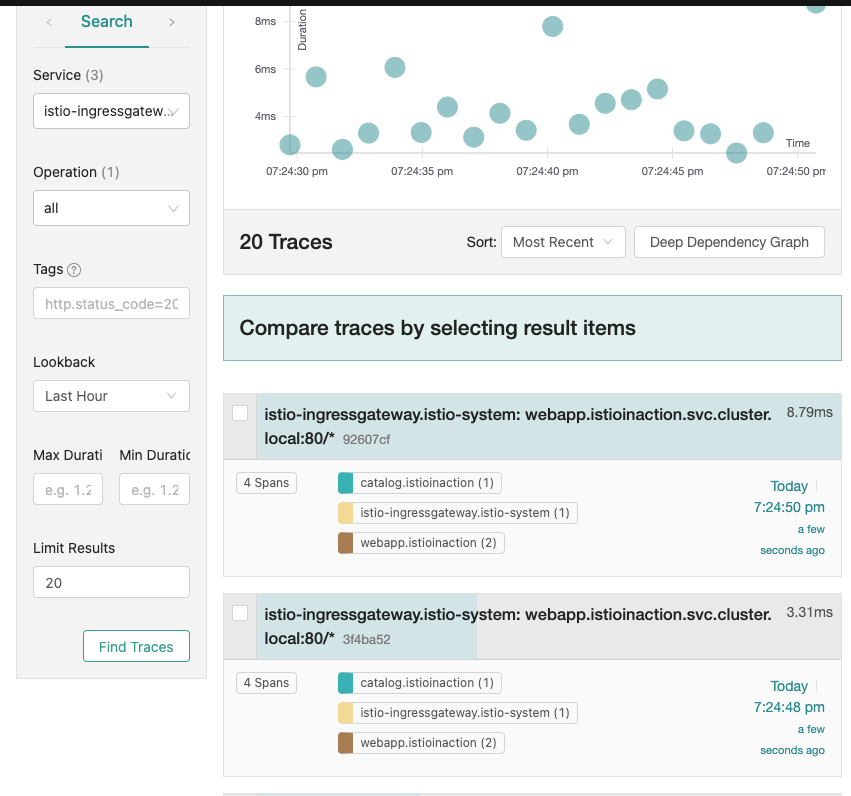
- 상세 분석
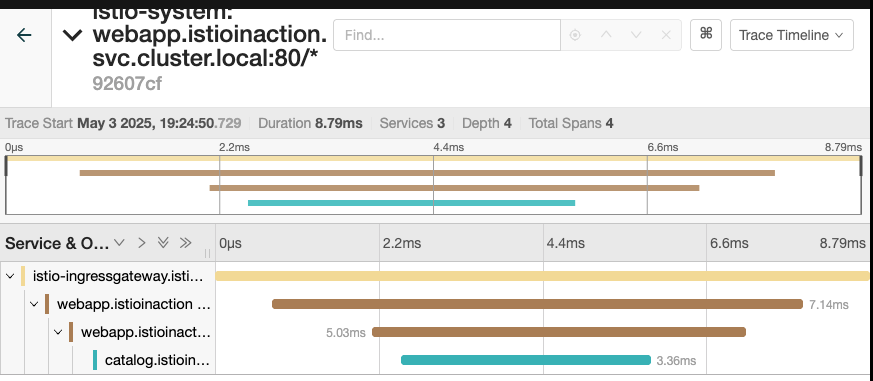
트레이스 샘플링, 강제 트레이스, 커스텀 테그
메시의 트레이스 샘플링 비율 조정하기
istio-system 네임스페이스에 있는 istio configmap 의 MeshConfig 를 수정
- 100 → 10 으로 수정
KUBE_EDITOR="vi" kubectl edit -n istio-system cm istio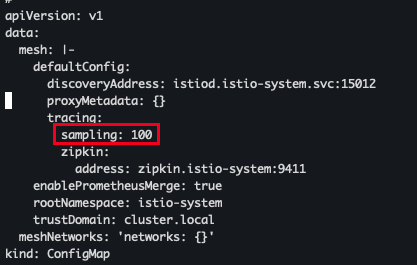
- 샘플링 적용
kubectl rollout restart deploy -n istio-system istio-ingressgateway
전역 설정 대신 애노테이션으로 워크로드별로 설정 가능
cat ch8/webapp-deployment-zipkin.yaml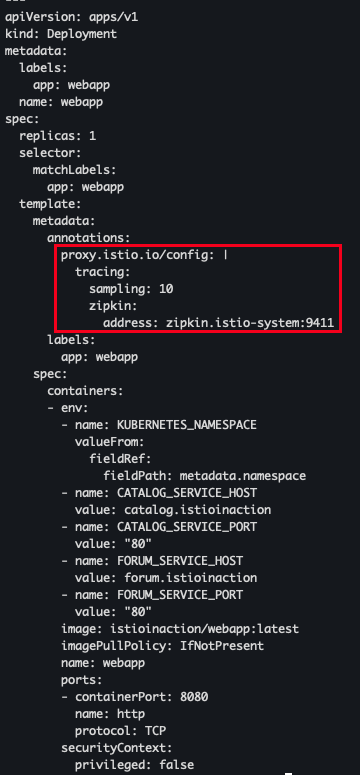
- 호출 적용
kubectl apply -f ch8/webapp-deployment-zipkin.yaml -n istioinaction
- 테스트 진행
curl -s http://webapp.istioinaction.io:30000/api/catalog | jq curl -s http://webapp.istioinaction.io:30000/api/catalog | jq curl -s http://webapp.istioinaction.io:30000/api/catalog | jq
- 예거 확인
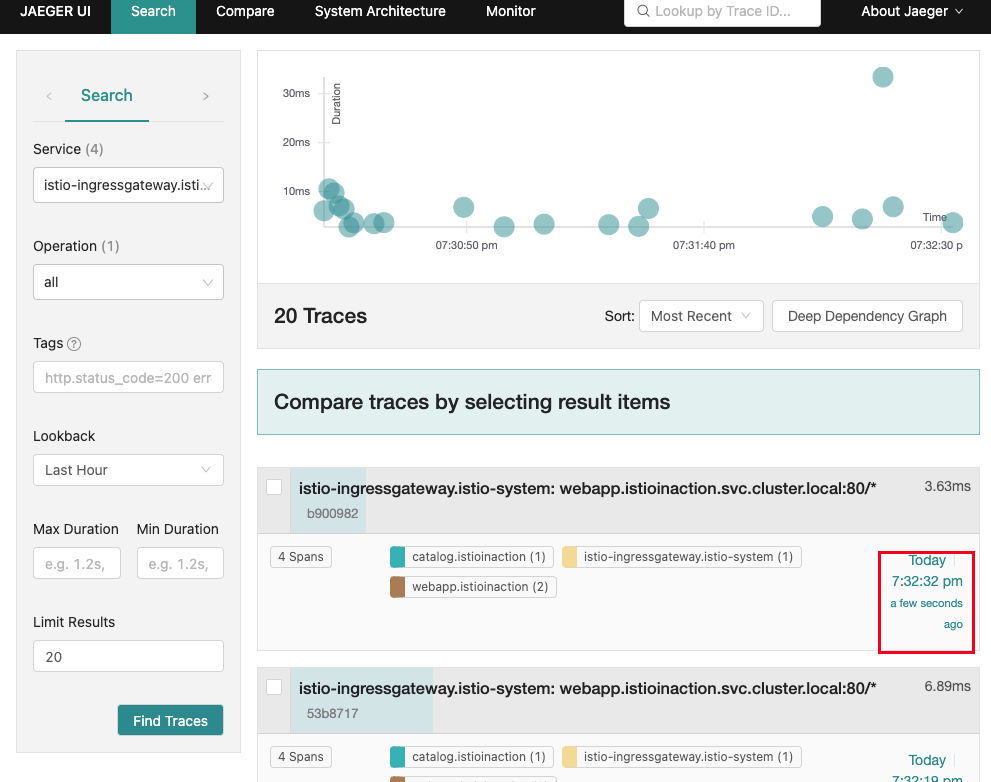
클라이언트에서 트레이싱 강제하기
운영 환경에서는 트레이스의 샘플링 비율을 최소한으로 설정한 후 문제가 있을때만 특정 로드에 대해 활성화하는 것이 이치에 맞다.
단 특정 요청에 대해서만 트레이싱을 강제하도록 설정할 수 있다.
예를 들어 애플리케이션 요청에 x-envoy-force-trace 헤더를 추가하여, 요청이 만드는 호출 그래프의 스팬과 트레이스를 이스티오가 포착하도록 만들 수 있다.
- 테스트 진행
curl -s -H "x-envoy-force-trace: true" http://webapp.istioinaction.io:30000/api/catalog -v curl -s -H "x-envoy-force-trace: true" http://webapp.istioinaction.io:30000/api/catalog -v curl -s -H "x-envoy-force-trace: true" http://webapp.istioinaction.io:30000/api/catalog -v
- 예거 확인
트레이스의 태그 커스터마이징 하기
책 기준으론 세 가지 유형의 커스텀 태그를 설정할수 있다.
- 명시적으로 값 지정하기
- 환경 변수에서 값 가져오기
- 요청 헤더에서 값 가져오기
예를 들어 webapp 서비스의 스팬에 커스텀 태그를 추가하려면, 해당 워크로드의 Deployment 리소스에 다음과 같이 애노테이션을 추가 할수 있다.
- 코드 확인
cat ch8/webapp-deployment-zipkin-tag.yaml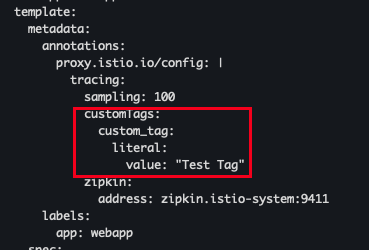
- webapp 에 커스텀 태그 적용
kubectl apply -n istioinaction -f ch8/webapp-deployment-zipkin-tag.yaml
- 호출 테스트
for in in {1..10}; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; sleep 0.5; done for in in {1..10}; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; sleep 0.5; done
- 예거 확인
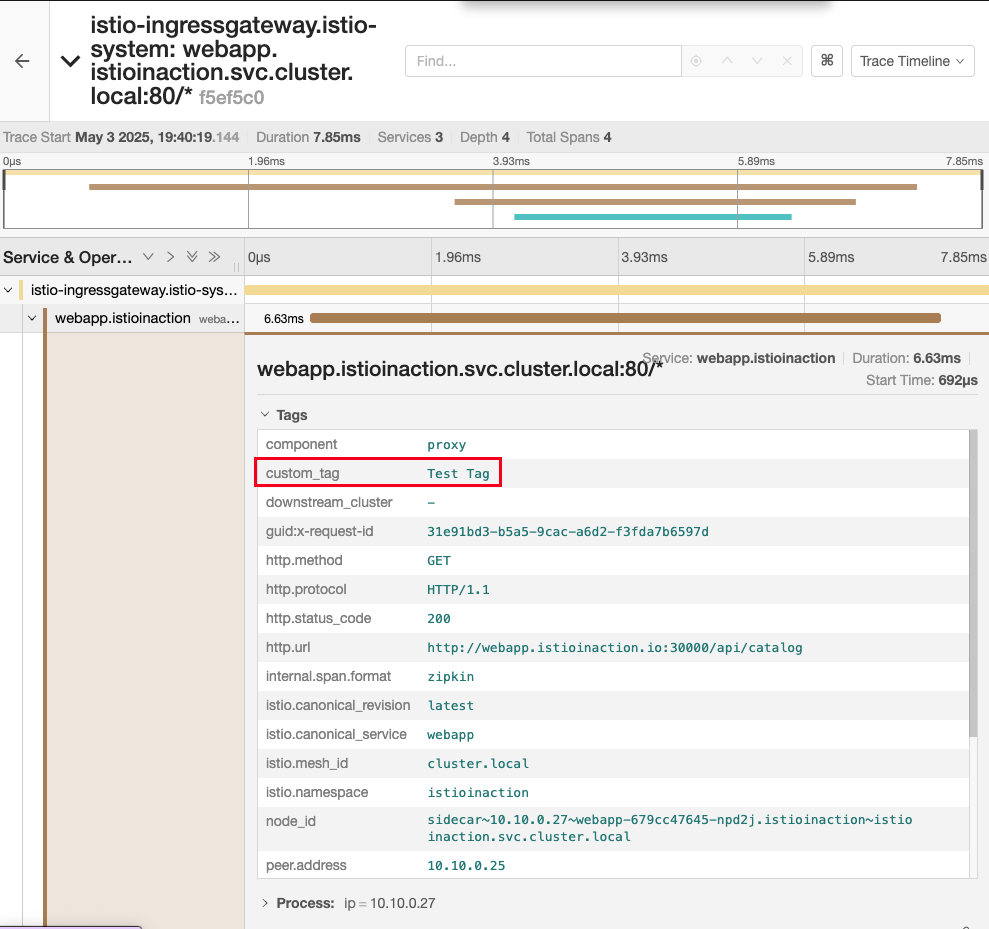
백엔드 분산 트레이싱 엔진 커스터마이징하기
-
기본 설정 확인
docker exec -it myk8s-control-plane bash # deploy/webapp 트레이싱 설정 조회 : 현재 기본 설정 istioctl pc bootstrap -n istioinaction deploy/webapp -o json | jq .bootstrap.tracing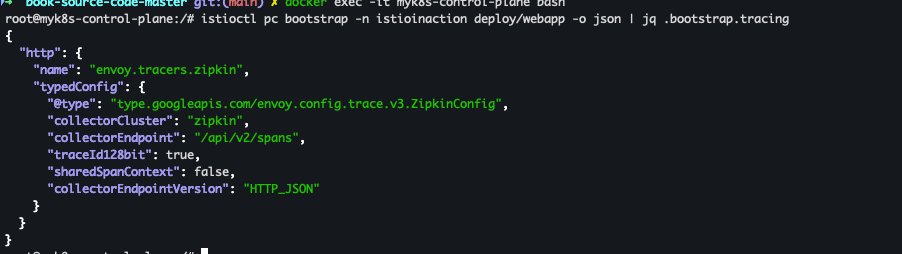
- 현재 기본 설정
- tracing enging 은 Zipkin-based
- Span 은 /api/v2/spans 로 전달
- JSON 엔드포인트로 처리
- 현재 기본 설정
기본 설정은 커스텀 부트스트랩 설정으로 변경 할 수 있습니다.
이를 위해 configmap 에서 튜닝하고자 하는 설정 스니펫을 지정합니다.
cat ch8/istio-custom-bootstrap.yaml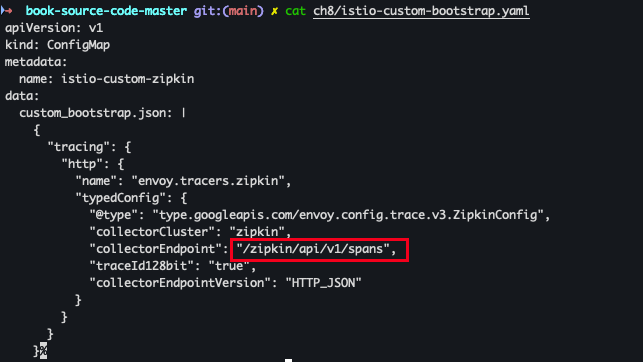
- 이 부트스트랩 설정을 덮어 쓰려는 워크로드가 있는 네임스페이스에 configmap 을 적용
kubectl apply -n istioinaction -f ch8/istio-custom-bootstrap.yaml
- 배포 확인
kubectl get cm -n istioinaction
- 해당 configmap 을 참조하는 Deployment 리소스의 파드 템플릿에 애노테이션을 추가
cat ch8/webapp-deployment-custom-boot.yaml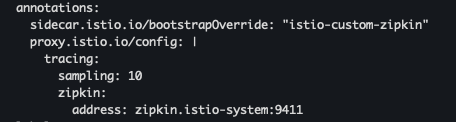
- 변경된 설정으로 webapp 재배포
kubectl apply -n istioinaction -f ch8/webapp-deployment-custom-boot.yaml
- deploy/webapp 트레이싱 설정 조회
docker exec -it myk8s-control-plane bash ----------------------------------------- istioctl pc bootstrap -n istioinaction deploy/webapp -o json | jq .bootstrap.tracing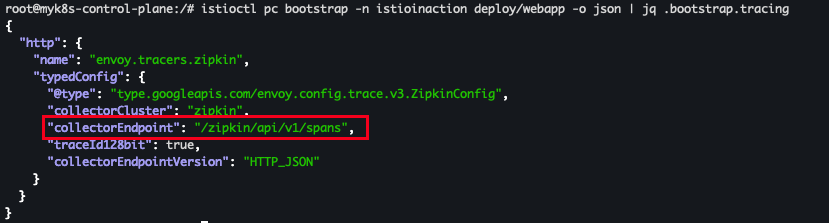
- 호출 테스트
for in in {1..10}; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; sleep 0.5; done for in in {1..10}; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; sleep 0.5; done
- 예거 확인 : webapp 추적 시 collectorEndpoint 에 잘못된 경로 설정으로
webapp Span이 출력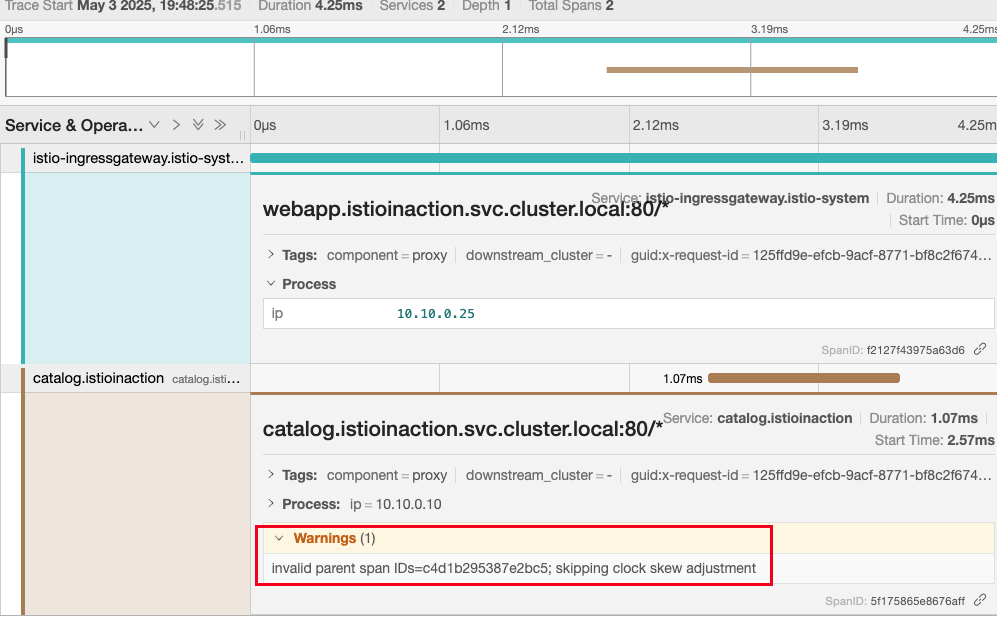
- 다음 실습을 위해서 원복
kubectl apply -n istioinaction -f services/webapp/kubernetes/webapp.yaml
- 원복 확인 테스트 진행
for in in {1..10}; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; sleep 0.5; done for in in {1..10}; do curl -s http://webapp.istioinaction.io:30000/api/catalog ; sleep 0.5; done