
TL;DR
- Operator = CRD(도메인 리소스 정의) + Controller(자동화 로직)
- CRD를 등록하면
kubectl get <custom>으로 도메인 개념을 네이티브 리소스처럼 관리할 수 있음 - Controller(27장)는 기본 리소스를 감시하고, Operator(28장)는 커스텀 리소스의 전체 라이프사이클을 자동화함
- 개발 도구: Kubebuilder(Go 표준) / Operator SDK(+OLM) / Metacontroller(언어 무관)
- v1.35: StorageVersionMigration Beta 기본 활성화, CEL 기반 CRD 검증 안정화
0. Problem: 왜 Operator가 필요한가?
27장에서 기본 리소스의 상태 변화를 감지하고 반응하는 Controller를 배웠습니다.
하지만 실제 운영에서는 이것만으로 부족한 상황이 자주 발생합니다.
예시 — Prometheus 모니터링 통합
Prometheus를 배포하는 것은 어렵지 않지만, 다음과 같은 "운영 작업"이 남습니다.
- 설정(alerting rule, scrape config)을 선언적으로 관리하고 싶음
- 모니터링 대상을 라벨 셀렉터로 지정하고 싶음
kubectl get prometheus처럼 네이티브 리소스로 다루고 싶음
예시 — PostgreSQL HA 클러스터
DBA가 수동으로 하던 페일오버, 백업, 레플리카 동기화를 자동화하고 싶지만,
이런 작업은 Kubernetes 기본 리소스만으로 표현할 수 없는 도메인 지식입니다.
이러한 한계를 극복하기 위해 CRD + Controller 조합, 즉 Operator 패턴이 등장했습니다.
1. Solution: CRD로 도메인 리소스 정의하기
CRD를 만들면 Kubernetes API에 새로운 리소스 타입이 등록됩니다.
etcd에 저장되고, kubectl로 CRUD하며, Watch 스트림도 열 수 있습니다.
Example 28-1. Prometheus CRD 정의
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: prometheuses.monitoring.coreos.com # <복수형>.<그룹>
spec:
group: monitoring.coreos.com # API 그룹
names:
kind: Prometheus # 리소스 Kind
plural: prometheuses # 복수형
scope: Namespaced # 네임스페이스 범위
versions:
- name: v1
storage: true # etcd 저장 버전 (하나만 true)
served: true # REST API 활성화
schema:
openAPIV3Schema: .... # 검증 스키마핵심 필드를 정리하면 다음과 같습니다.
| 필드 | 설명 |
|---|---|
metadata.name | <복수형>.<그룹> 형식 |
spec.group | API 그룹 (kubectl/URL에서 사용) |
names.kind / plural | Kind와 복수형 (kubectl get prometheuses) |
scope | Namespaced 또는 Cluster |
storage / served | etcd 저장 버전(하나만 true)과 API 활성화 여부 |
openAPIV3Schema | 리소스 유효성 검증 스키마 |
운영급 CRD에서는 shortNames(kubectl get cw), categories(kubectl get all 포함), additionalPrinterColumns(커스텀 컬럼 출력) 등을 추가로 설정합니다.
OpenAPI V3 스키마의 중요성
운영급 CRD에서는 스키마가 필수입니다.
스키마가 없으면 잘못된 spec이 API 서버를 통과해 etcd에 저장되고, Operator가 예상치 못한 입력을 받아 오동작할 수 있습니다.
예:
replicas필드에 문자열"three"를 넣어도 스키마가 없다면 통과될 수 있습니다.
운영 중 Operator가 이 값을 파싱하다 panic이 발생할 수 있습니다.
Example 28-2. 커스텀 리소스 인스턴스
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
spec:
serviceMonitorSelector:
matchLabels:
team: frontend
resources:
requests:
memory: 400Mi하지만 커스텀 리소스만으로는 아무런 동작도 하지 않습니다.
리소스의 라이프사이클을 감시하고 행동하는 Controller(= Operator)가 필요합니다.
2. CRD 서브리소스(Subresources)
CRD에 두 가지 서브리소스를 추가할 수 있습니다.
Example 28-3. 서브리소스 정의
spec:
subresources:
status: {} # status 서브리소스
scale:
specReplicasPath: .spec.replicas # 원하는 레플리카 수
statusReplicasPath: .status.replicas # 실제 레플리카 수
labelSelectorPath: .status.labelSelector # HPA용 라벨 셀렉터status 서브리소스: spec(원하는 상태)과 status(관측된 상태)를 분리하여 업데이트할 수 있습니다.
사용자는 spec.replicas: 3을 선언하고, Operator는 status.replicas: 2로 "아직 2개만 Ready"임을 보고합니다.
scale 서브리소스: HPA 같은 오토스케일러가 커스텀 리소스를 대상으로 자동 스케일링할 수 있게 해줍니다.
3. Controller와 Operator의 분류
Controller vs Operator — 한눈에 비교
| 비교 항목 | Controller (27장) | Operator (28장) |
|---|---|---|
| 감시 대상 | 기본 리소스 (Pod, ConfigMap 등) | 커스텀 리소스(CRD) + 기본 리소스 |
| 리소스 정의 | 기존 Kubernetes API만 사용 | CRD로 새 리소스 타입 등록 |
| 도메인 표현 | annotation/label에 우회 저장(혹은 ConfigMap 등으로 간접 모델링) | 전용 Kind로 명시적 표현 |
| API 검증 | (기본 리소스는) 이미 정의된 OpenAPI 스키마로 검증됨. 도메인 고유 규칙을 “새 타입”으로 표현하긴 어려움 | CRD 스키마(OpenAPI V3) + (선택) CEL 규칙로 도메인 검증을 타입 수준에서 선언 가능 |
| kubectl | kubectl get cm 등 기본만 | kubectl get <custom> 가능 |
| RBAC | 기본 리소스 단위로 권한 부여 | Kind별(커스텀 리소스 포함) 세분화 가능 |
| 필요 권한 | 보통 네임스페이스 권한으로 가능 | CRD 설치는 클러스터 범위 권한이 필요할 수 있음(운영 모델에 따라 다름) |
| 대표 예시 | ConfigMap 변경 → Pod 재시작 | Prometheus Operator, CloudNativePG |
Controller는 기본 리소스를 감시하고, Operator는 CRD를 통해 도메인 고유 리소스를 정의한 뒤 그 라이프사이클을 자동화합니다.
스펙트럼: 어디부터 Operator인가?
핵심은 CRD를 사용하기 시작하면 Operator 영역으로 진입한다는 것입니다.
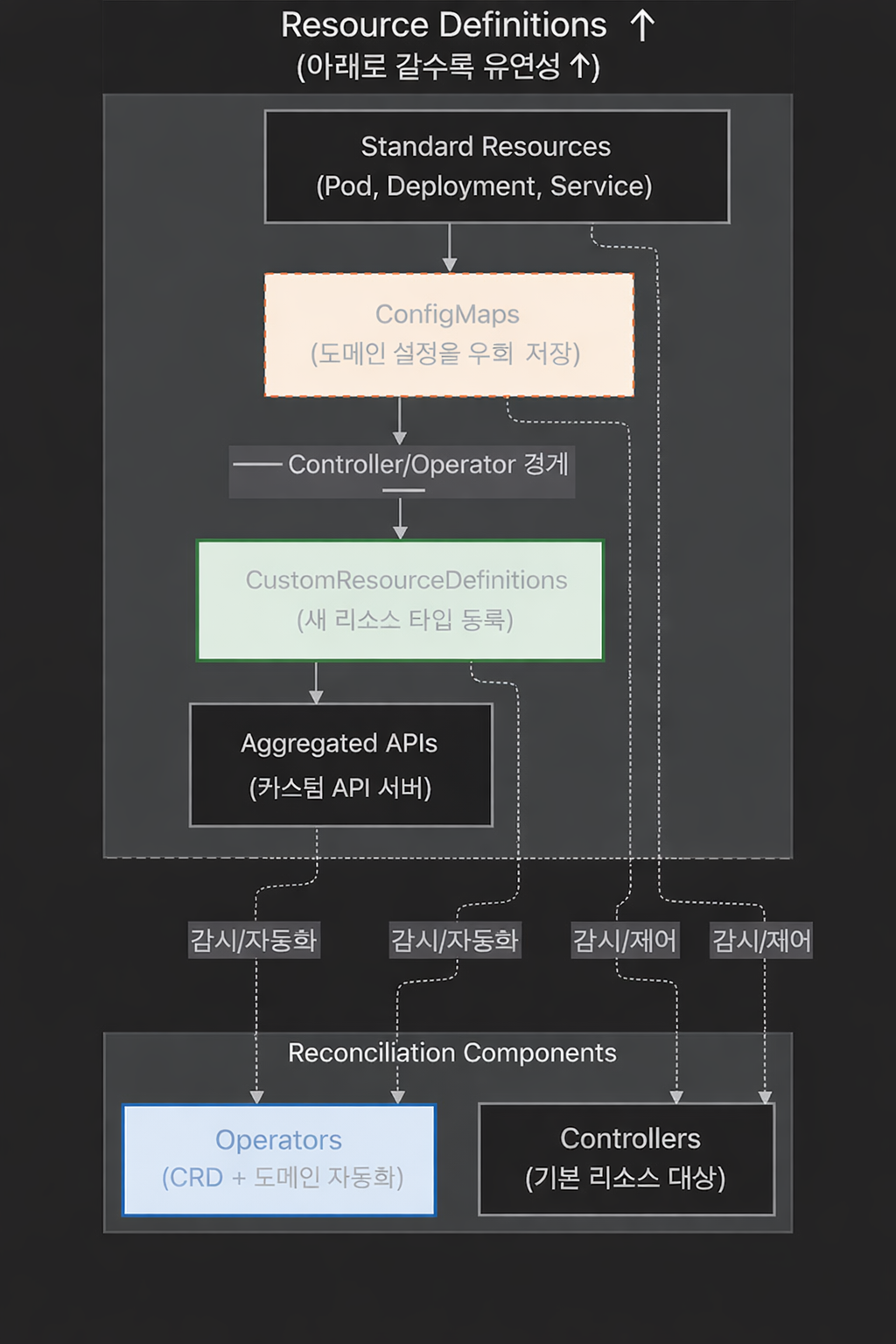
그림 28-1:
Standard Resources → ConfigMaps ──경계── → CRDs → Aggregated APIs순으로 유연성이 증가합니다.
ConfigMaps까지는 Controller, CRDs부터는 Operator입니다.
Operator 개념도

그림 28-2:
kubectl apply→ API Server 검증 → etcd 저장 → Operator가 Watch → Analyze → Act
CRD 분류: Installation vs Application
| 분류 | 설명 | 예시 |
|---|---|---|
| Installation CRD | 애플리케이션 자체를 설치/운영 | Prometheus — Prometheus 서버를 배포 |
| Application CRD | 도메인 고유 개념을 표현 | ServiceMonitor — 모니터링 대상 등록 |
하나의 Operator가 두 종류를 모두 관리할 수 있으며, 경계는 명확하지 않습니다.
ConfigMap vs CRD
CRD 등록이 불가능한 환경(예: cluster-admin 권한이 제한됨)에서는 ConfigMap을 대안으로 사용할 수 있지만, 스키마 기반 검증/권한 세분화/status 분리/버전 관리 등에서 제약이 큽니다.
CRD를 사용할 수 있다면 CRD가 일반적으로 더 유리합니다.
4. API Aggregation — CRD 너머의 확장
CRD가 관리형 확장이라면, API Aggregation은 Kubernetes API 경로 자체를 확장하는 방식입니다.
Example 28-4. APIService
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1alpha1.sample-api.k8spatterns.io
spec:
group: sample-api.k8spatterns.io
service:
name: custom-api-server
namespace: default
version: v1alpha1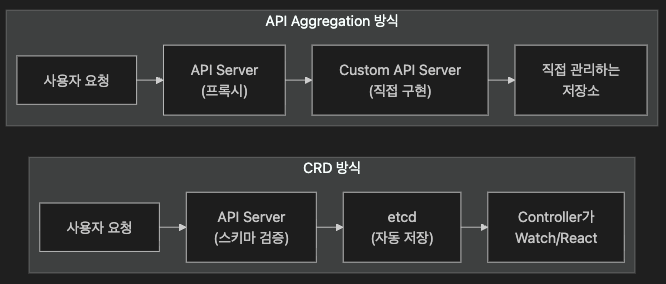
| 비교 | CRD | API Aggregation |
|---|---|---|
| 저장 | etcd 자동 관리 | 직접 구현(스토리지/캐시/백엔드 선택) |
| 복잡도 | 낮음 | 높음 (API 서버 구현/운영) |
| 유연성 | CRUD + Watch 중심 | API 형태에 제약이 상대적으로 적음 |
| 추천 | 대부분의 경우 | Metrics Server 같은 특수 케이스 |
5. Operator 개발/배포 도구 3종
5-1. Kubebuilder
Go 기반 Operator 개발의 사실상 표준입니다.
controller-runtime 위에 스캐폴딩 + 코드 생성 기능을 제공합니다.
5-2. Operator Framework (CNCF)
| 컴포넌트 | 역할 |
|---|---|
| Operator SDK | Kubebuilder 기반 + (선택) Ansible/Helm 플러그인 + 배포/패키징 도구 |
| OLM | Operator의 설치/업데이트/삭제를 관리 ("앱 스토어"와 유사) |
| OperatorHub | 커뮤니티 Operator 카탈로그 |
OLM은 (클러스터 운영자가 허용한 범위 내에서) 일반 사용자가 Operator를 설치/업데이트할 수 있도록 하는 설치/수명주기 관리 계층입니다.
보통 Operator 작성자는 CSV(ClusterServiceVersion)와 번들(bundle)을 패키징해 배포하고, OLM은 이를 읽어 CRD/디플로이먼트 등 필요한 리소스를 설치 전략에 따라 적용합니다.
5-3. Metacontroller
Go 의존성 없이 아무 언어로나 Operator를 만들 수 있습니다.
사용자는 비즈니스 로직만 웹훅(HTTP + JSON)으로 구현하면, Metacontroller가 API 통신/Reconciliation/이벤트 처리를 대행합니다.
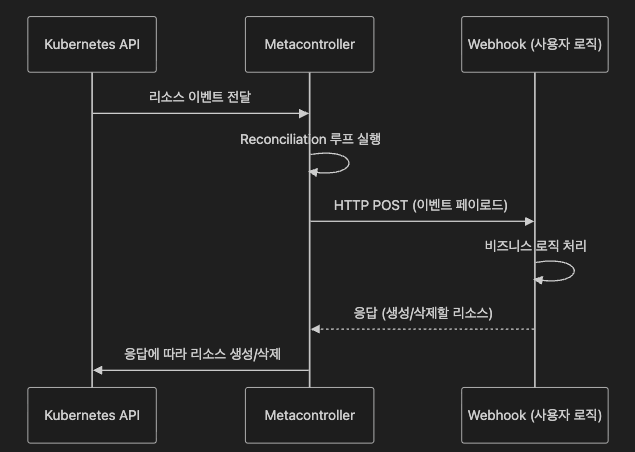
도구 선택 가이드
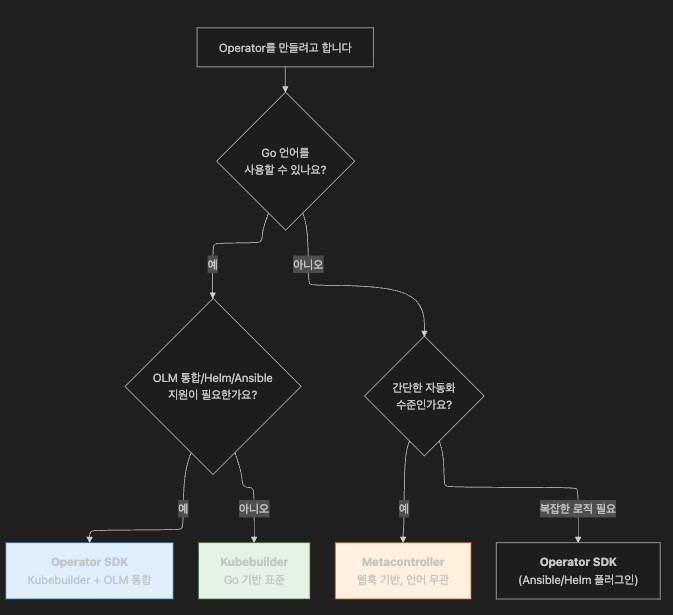
6. 예제: ConfigWatcher Operator
아이디어와 동기
27장에서는 ConfigMap에 annotation을 달아 변경 시 Pod를 재시작했습니다.
하지만 이 방식은 ConfigMap과 Controller가 강하게 결합되고, 다대다 관계가 복잡해지며, 연결 관계가 명시적이지 않아 장애 추적이 어렵습니다.
Operator 접근법은 ConfigWatcher CRD를 도입하여, ConfigMap과 Pod를 독립적으로 유지하면서 CR이 둘의 연결 관계를 선언적으로 정의합니다.
Example 28-5. ConfigWatcher Custom Resource
apiVersion: k8spatterns.io/v1
kind: ConfigWatcher
metadata:
name: webapp-config-watcher
spec:
configMap: webapp-config # 감시할 ConfigMap
podSelector: # 재시작할 Pod 라벨
app: webappConfigMap 자체에는 아무런 annotation이 필요 없습니다.
하나의 ConfigMap을 여러 앱에, 하나의 앱을 여러 ConfigMap에 자유롭게 연결할 수 있습니다.
Example 28-6. ConfigWatcher CRD
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: configwatchers.k8spatterns.io
spec:
scope: Namespaced
group: k8spatterns.io
names:
kind: ConfigWatcher
singular: configwatcher
plural: configwatchers
versions:
- name: v1
storage: true
served: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
required: ["configMap", "podSelector"]
properties:
configMap:
type: string
podSelector:
type: object
additionalProperties:
type: stringExample 28-7. RBAC Role 정의
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: config-watcher
rules:
- apiGroups: ["k8spatterns.io"]
resources: ["configwatchers", "configwatchers/finalizers"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]finalizers 권한은 CR 삭제 시 외부 리소스 정리(클라우드 리소스 해제, DNS 삭제 등)를 위해 필요합니다.
(단, 이 글의 ConfigWatcher 예제처럼 “외부 리소스가 없는” 경우라면 finalizer가 필수는 아닙니다.)
Example 28-8. Reconciliation 루프 (학습용 쉘 스크립트)
curl -Ns "$base/api/v1/${ns}/configmaps?watch=true" | \
while read -r event; do
type=$(echo "$event" | jq -r '.type')
if [ "$type" = "MODIFIED" ]; then
config_map=$(echo "$event" | jq -r '.object.metadata.name')
# 변경된 ConfigMap을 참조하는 ConfigWatcher를 찾아
# 매칭된 podSelector로 Pod를 삭제 (Deployment가 재생성)
watchers=$(curl -s "$base/apis/k8spatterns.io/v1/${ns}/configwatchers" | \
jq -r ".items[] | select(.spec.configMap == \"$config_map\") | .metadata.name")
for watcher in $watchers; do
delete_pods_with_selector "$(extract_label_selector "$watcher")"
done
fi
done이 쉘 기반 구현은 학습용입니다. 운영급에서는 Go(controller-runtime) 기반 구현을 사용하세요.
7. Discussion: Operator를 써야 할 때, 쓰지 말아야 할 때
적합한 경우: kubectl 통합이 필요할 때, Kubernetes 네이티브로 설계할 때, 선언적 모델에 맞는 도메인일 때, Watch/RBAC/라벨 셀렉터가 필요할 때
적합하지 않은 경우: 선언적이지 않은 워크플로우, 리소스 모델에 안 맞는 데이터, 플랫폼 통합이 불필요할 때, 단순 Controller로 충분할 때
"단순 Controller로 해결 가능한가?"를 먼저 검토하세요.
Controller는 보통 cluster-admin이 불필요하고 CRD 오버헤드도 없습니다.
실제 Operator가 자동화하는 작업
| Operator | 사람이 하던 작업 | Operator가 자동화한 내용 |
|---|---|---|
| Prometheus | 설정 파일 수정 → 서버 재시작 → 대상 수동 등록 | ServiceMonitor CR로 자동 반영 |
| Strimzi (Kafka) | 브로커 추가 → 설정 복제 → 파티션 리밸런싱 | Kafka CR에서 replicas 변경만으로 완료 |
| CloudNativePG | 수동 페일오버 → 레플리카 재설정 → WAL 관리 | 자동 페일오버 + 선언적 WAL 아카이브 |
확장 방식 의사결정 트리
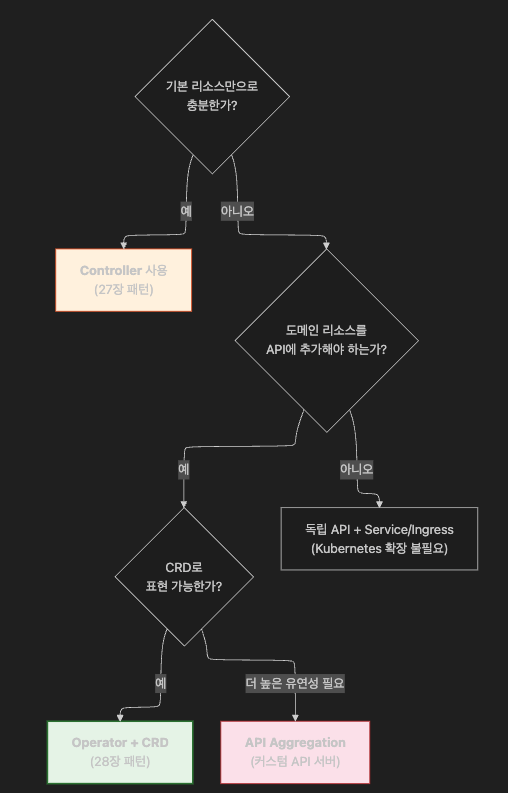
기본 리소스로 충분 → Controller / CRD로 표현 가능 → Operator + CRD / 더 높은 유연성 필요 → API Aggregation
8. Kubernetes v1.35 운영 보강
8-1. Storage Version Migration (Beta 기본 활성화)
CRD를 v1에서 v2로 업그레이드할 때, etcd의 v1 객체를 마이그레이션해야 합니다.
기존에는 수동 read-write 루프(kubectl get | kubectl replace)가 필요했지만, v1.35부터 StorageVersionMigration API가 Beta로 승격되어 코어 컨트롤 플레인에서 직접 마이그레이션을 실행합니다.
(v1.35 Release Blog)
apiVersion: storagemigration.k8s.io/v1beta1
kind: StorageVersionMigration
metadata:
name: migrate-mycrd-to-v2
spec:
resource:
group: mygroup.io
version: v2
resource: mycrds8-2. CEL 기반 CRD 검증
v1.29에서 GA된 CRD Validation Rules는 CEL로 복잡한 검증을 CRD 내에 직접 정의합니다.
Admission Webhook 없이 x-kubernetes-validations만으로 필드 검증이 가능합니다.
x-kubernetes-validations:
- rule: "has(self.configMap)"
message: "configMap은 반드시 지정해야 합니다"
- rule: "size(self.podSelector) > 0"
message: "podSelector에 최소 하나의 라벨이 필요합니다"| 비교 | Admission Webhook | CEL Validation |
|---|---|---|
| 배포 | 별도 Pod/Service | CRD에 내장 |
| 장애점 | 웹훅 다운 시 API 요청이 실패할 수 있음(설정에 따라 Fail/Open 차이) | 웹훅 의존성이 없음 |
| 지연 | 네트워크 호출 | 인라인 평가 |
| 안전성 | 구현에 따라 무한루프/과부하 위험 | 비-튜링 완전(표현력 제한) |
8-3. API 버전 디프리케이션 주의
클러스터 업그레이드 시 Operator 매니페스트의 API 버전을 반드시 확인하세요.
apiextensions.k8s.io/v1beta1, apiregistration.k8s.io/v1beta1 등은 v1.22에서 제거되었습니다.
CI/CD에 pluto(FairwindsOps)를 추가하면 디프리케이션을 자동 감지할 수 있습니다.
8-4. resourceVersion 비교 가능성 개선
v1.35에서 resourceVersion을 비교 가능한 형태로 정리하는 개선이 도입되어, Watch 스트림에서 이벤트 유실 감지와 데이터 일관성 확인에 도움을 줍니다.
9. 운영급 Operator 체크리스트
9-1. Finalizer 설계
Operator가 관리하는 외부 리소스(클라우드 DB, DNS 등)가 있다면, CR 삭제 시 외부 자원을 먼저 정리한 뒤 삭제가 완료되도록 Finalizer를 설계해야 합니다.
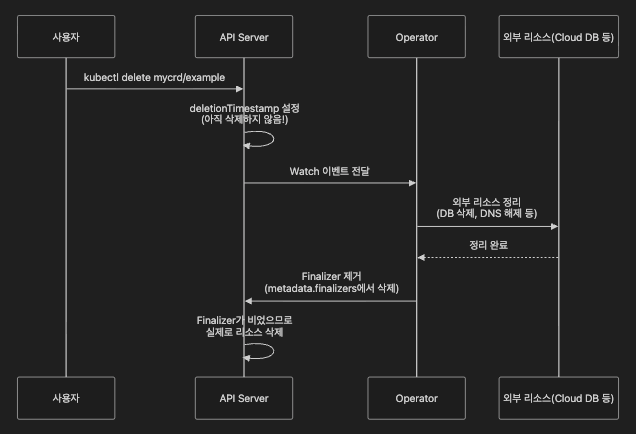
| 주의사항 | 설명 |
|---|---|
| Finalizer 미제거 | 리소스가 Terminating에서 영원히 멈춤 |
| 정리 실패 시 | 재시도 로직 필수, 아니면 무한 대기 |
| 강제 삭제 | kubectl patch -p '{"metadata":{"finalizers":[]}}' --type=merge |
9-2. status 서브리소스 활용
관측값은 반드시 status에만 기록하세요.
phase, conditions, observedGeneration 등을 포함합니다.
9-3. 멱등성(Idempotency)
Reconcile 함수는 동일 입력 반복 호출에도 동일 결과를 내야 합니다.
매번 Pod를 삭제하는 대신, ConfigMap 해시가 이미 반영되었는지 확인 후 미반영된 경우에만 동작하세요.
9-4. Rate Limit / Backoff
장애 시 즉시 재시도하면 API 서버에 부하를 가중합니다.
controller-runtime의 지수 백오프를 활용하세요.
9-5. RBAC 최소 권한
- 네임스페이스 범위 제한
*사용 금지- 읽기 전용 리소스에 write 권한 미부여
9-6. 관측성
- Events:
kubectl describe로 확인 가능한 이벤트 - Metrics:
/metrics로 reconcile 횟수/지연/에러율 노출 - Logs: 구조화된 로그로 "어떤 CR에 어떤 조치를 했는지" 기록
출처
도서
- Kubernetes Patterns (O'Reilly, 2nd Edition) — Chapter 28: Operator
Kubernetes 공식 문서
CRD 검증 (CEL)
Operator 개발 도구
Operator 예제
