
1. Problem: 왜 Elastic Scale이 필요한가?
마이크로서비스/컨테이너 환경에서는 트래픽·이벤트·배치가 시간대/시즌/캠페인에 따라 급격하게 바뀝니다.
고정된 replica 수와 고정 자원만으로 운영하면 보통 다음이 반복됩니다.
- 피크 시간: 과소 프로비저닝 → 지연 증가/장애
- 한가한 시간: 과대 프로비저닝 → 비용 낭비
- 운영자가 매번 판단/조치: 휴먼 오퍼레이션 병목
그래서 목표는 단순합니다. “필요할 때만, 필요한 만큼” 자동으로 늘고 줄어드는 시스템을 만드는 것입니다.
2. Solution Overview: 스케일링의 3가지 방향
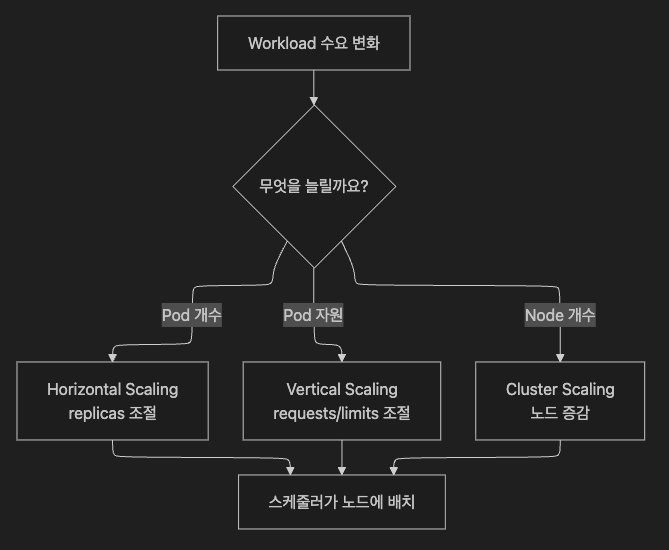
- 수평(Horizontal): Pod 수를 늘려 처리량·가용성을 확보합니다.
- 수직(Vertical): Pod 1개당 자원 요청(requests)과 제한(limits)을 조정해 안정성을 확보합니다.
- 클러스터(Cluster): Pod를 올릴 “자리(노드)” 자체를 늘립니다.
3. 수동 수평 확장: Imperative vs Declarative
책에서는 수동 스케일링을 명령형(Imperative) 과 선언형(Declarative) 로 구분합니다.
3.1 명령형(긴급 대응용)
kubectl scale deploy/random-generator --replicas=103.2 선언형(운영 표준)
Deployment.spec.replicas를 변경하고kubectl apply로 반영합니다.- 같은 맥락에서, HPA도 YAML(리소스)로 선언적으로 생성/관리하는 것이 표준 운영 방식입니다.
- GitOps 환경에서는 선언형이 표준입니다.
클러스터에서만 숫자를 바꾸면 설정 드리프트(Configuration Drift) 가 생기기 쉽습니다.
운영 예시
블랙프라이데이/라이브커머스처럼 “시작 시간이 확실한 이벤트”는
HPA가 있어도 프리워밍(Pre-warming) 으로 미리 replicas를 올려두는 편이 더 안전한 경우가 많습니다.
4. HPA: Horizontal Pod Autoscaler
HPA는 Kubernetes 기본 기능으로, 메트릭 기반으로 replicas를 자동 조절합니다.
다만 기본 HPA만으로는 Scale-to-Zero(0 Pod) 가 불가능합니다(minReplicas >= 1 필수).
4.1 HPA 동작 공식(수식)과 계산 예시
책에서 제시하는 HPA의 핵심은 아래 공식입니다.
desiredReplicas = ceil(currentReplicas × (currentMetricValue / desiredMetricValue))
계산 예시(책 예시 그대로)
- 현재 1개 Pod, CPU가 request 대비 90% 사용
- 목표(desired)가 50% 라면
ceil(1 × 90/50) = ceil(1.8) = 2
→ replicas를 2로 증가시킵니다.

4.2 메트릭 3유형: Standard / Custom / External
HPA는 크게 3가지 메트릭 소스/유형을 다룹니다.
| 유형 | 대표 예 | 특징 | 보통 필요한 구성 |
|---|---|---|---|
| Standard(Resource Metrics) | CPU/Memory | Kubernetes 기본 메트릭(리소스 사용량) | metrics-server |
| Custom Metrics | http_requests_per_second 같은 애플리케이션 지표 | “클러스터 내부 객체(예: Pod)”와 연결되는 커스텀 지표 | Custom Metrics Adapter(예: Prometheus Adapter) |
| External Metrics | SQS 큐 길이, 외부 시스템의 backlog | “클러스터 바깥 자원” 지표 | External Metrics Provider + (여러 시스템을 쓰면) 집계 레이어(KEDA 등) |
책 포인트: HPA의 리소스 사용률(Utilization) 계산은
limits가 아니라requests(guaranteed resource) 를 기준으로 합니다.
운영 예시
- Custom: “요청/초(RPS)”를 Prometheus로 수집 → HPA가
custom.metrics로 스케일- External: “큐 길이”를 기준으로 워커를 스케일 → KEDA가 특히 잘 맞습니다.
4.3 메트릭 선택의 핵심(왜 Memory는 위험한가?)
HPA 메트릭 선택의 핵심 질문은 이것입니다.
“Pod를 늘리면(metric 분산으로) 그 지표가 내려가나요?”
- 좋은 지표: CPU, RPS, 큐 길이(부하 분산과 상관관계가 큼)
- 위험한 지표: Memory(특히 캐시/힙을 오래 잡는 런타임)
나쁜 예시(메모리 기반 HPA 폭주)
Java 서비스가 캐시를 많이 쥐고 있어 메모리 사용률이 80%로 유지됩니다.
HPA는 메모리를 낮추려고 Pod를 계속 늘리지만, 새 Pod도 캐시가 차면서 지표가 내려가지 않습니다.
결국 maxReplicas까지 계속 증가하며 비용 폭발로 이어질 수 있습니다.
결론
메모리 문제는 HPA로 해결하려고 하기보다, VPA/requests 튜닝/애플리케이션 튜닝으로 접근하는 편이 안정적입니다.
4.4 Thrashing(출렁임) 방지: behavior 튜닝
HPA는 지표가 흔들릴 때 빠르게 올렸다 내렸다(Thrashing) 하면 오히려 장애를 유발합니다.
그래서 autoscaling/v2의 .spec.behavior로 확장/축소 속도를 제한하는 운영이 일반적입니다.
참고: 아래 HPA 예시는 behavior(Example 29-5) 중심으로 책 예시와 동일하게 맞췄고,
min/max/target값은 설명을 위해 다소 확장해 적었습니다(책 Example 29-4는min=1, max=5, target=50).
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: random-generator-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: random-generator
minReplicas: 2
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
behavior:
scaleDown:
stabilizationWindowSeconds: 300 # 5분 안정화(급격한 축소 방지)
policies:
- type: Percent
value: 10
periodSeconds: 60 # 1분당 10%씩만 감소
scaleUp:
policies:
- type: Pods
value: 4
periodSeconds: 15 # 15초당 최대 4개 증가운영 팁
일반적으로 scaleUp은 빠르게, scaleDown은 느리게 잡는 편이 사용자 체감 안정성에 유리합니다.
5. Scale-to-Zero: Knative vs KEDA
기본 HPA의 대표적인 한계는 “트래픽/이벤트가 완전히 없을 때 0 Pod까지 내려가 비용을 0에 가깝게 만들기 어렵다”는 점입니다.
이를 보완하는 대표적인 Kubernetes 애드온이 Knative 와 KEDA 입니다.
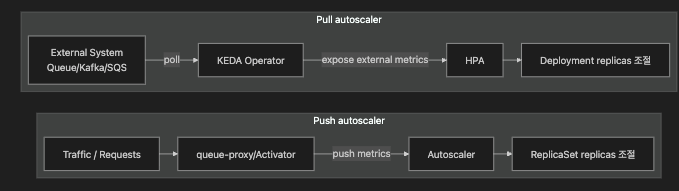
5.1 Push vs Pull 오토스케일러
책의 사이드바 요약을 운영 관점으로 풀면 다음과 같습니다.
- Push autoscaler: 스케일러에 가까운 곳에서 생성된 메트릭을 “밀어 넣어(push)” 스케일 결정을 합니다.
→ Knative가 대표적입니다(Activator/queue-proxy가 concurrency 같은 메트릭을 autoscaler에 전달). - Pull autoscaler: 스케일러가 외부/애플리케이션 메트릭을 “당겨(pull)” 스케일 결정을 합니다.
→ KEDA가 대표적입니다(외부 시스템 큐/이벤트 메트릭을 주기적으로 polling).
5.2 Knative(Serving/Eventing/Functions) + KPA 구조
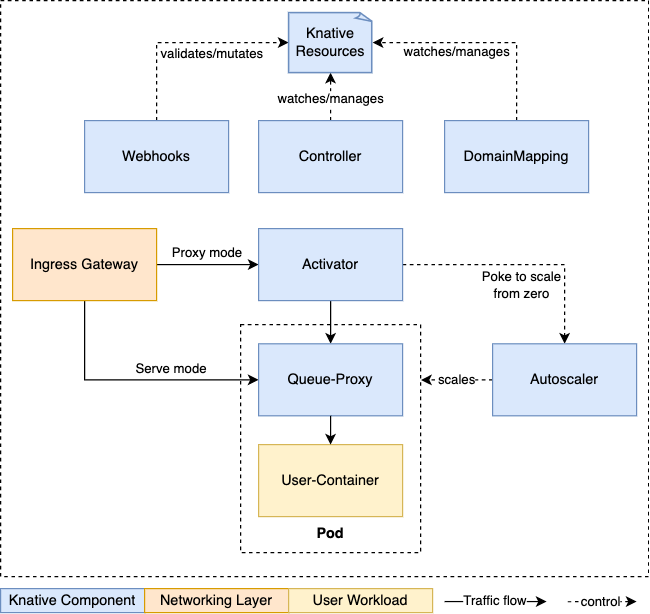
Knative는 보통 다음 3축으로 이해하시면 편합니다.
- Serving: HTTP 기반 서버리스 서비스(요청 트래픽 기반 스케일)
- Eventing: 이벤트 라우팅/메시(Event Mesh) 구성
- Functions: 함수형 개발 경험(프로젝트/배포 레벨에서 Serving에 얹히는 경우가 많습니다)
그리고 Serving의 핵심 오토스케일러가 KPA(Knative Pod Autoscaler) 입니다.
KPA 핵심 컴포넌트(책 Figure 29-2 기반)
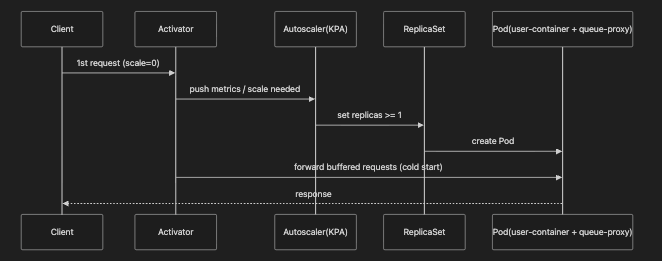
- Activator
scale-to-zero 상태에서도 항상 존재하는 프록시입니다. 첫 요청이 들어오면 요청을 버퍼링하고 Pod를 최소 1개 이상 올린 뒤 전달합니다. (Cold Start 동안 “요청 유실”을 막는 역할) - queue-proxy
애플리케이션 Pod에 사이드카로 주입되어 요청 경로를 가로채고, concurrent requests 같은 오토스케일링 메트릭을 수집합니다. - Autoscaler
Activator/queue-proxy에서 전달된 데이터를 바탕으로 스케일 결정을 하고 ReplicaSet의 replicas를 조정합니다.
참고 이미지(공식 문서)
- Knative Serving Architecture:

(Velog에서는 보통 “이미지 직접 링크”가 필요하니, 게시 전 페이지에서 실제 이미지 URL을 복사해 붙여주시는 것을 권장드립니다.)
5.3 Knative scaling 파라미터(Table 29-1) 정리
책의 Table 29-1을 그대로 옮겨, 운영 시 자주 만지는 옵션만 표로 정리합니다.
(공통 prefix autoscaling.knative.dev/는 생략합니다.)
| Annotation | 의미 | 기본값 |
|---|---|---|
target | replica 1개가 처리할 동시 요청 수(soft limit) | 100 |
target-utilization-percentage | concurrency limit의 몇 %에 도달하면 새 replica 생성 시작 | 70 |
min-scale | 최소 replica 수(>0이면 scale-to-zero 불가) | 0 |
max-scale | 최대 replica 수(0이면 무제한) | 0 |
activation-scale | 0에서 올라올 때 초기로 만들 replica 수 | 1 |
scale-down-delay | scale-down 조건이 유지되어야 하는 시간(웜 유지/콜드스타트 완화) | 0s |
window | 스케일 판단에 사용하는 평균 윈도우 | 60s |
운영 예시
- 트래픽이 들쭉날쭉한데 콜드스타트가 부담이면
scale-down-delay를 주고 “웜 유지”를 합니다.- 완전 서버리스(0)로 내리려면
min-scale=0유지가 필수입니다.
5.4 Knative 예시(Example 29-6): Knative Service
책의 Example 29-6을 실습 가능한 형태로 정리했습니다.
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: random
annotations:
autoscaling.knative.dev/target: "80"
autoscaling.knative.dev/window: "120s"
spec:
template:
spec:
containers:
- image: k8spatterns/random- Kubernetes
Service와 이름은 같지만, API 그룹이serving.knative.dev로 다릅니다. target/window는 KPA 오토스케일링 동작을 튜닝하는 대표 파라미터입니다.
5.5 KEDA 구조(0↔1 vs 1↔n) + CRD
이벤트 드리븐 확장(Event-driven scaling)
KEDA는 외부 이벤트(큐 메시지, lag, 스케줄, DB 변화 등)를 “트리거”로 보고 워크로드를 확장하는 패턴에 최적화되어 있습니다.
KEDA는 “이벤트 기반 워커(큐/스트림 컨슈머)”에 특히 잘 맞습니다.
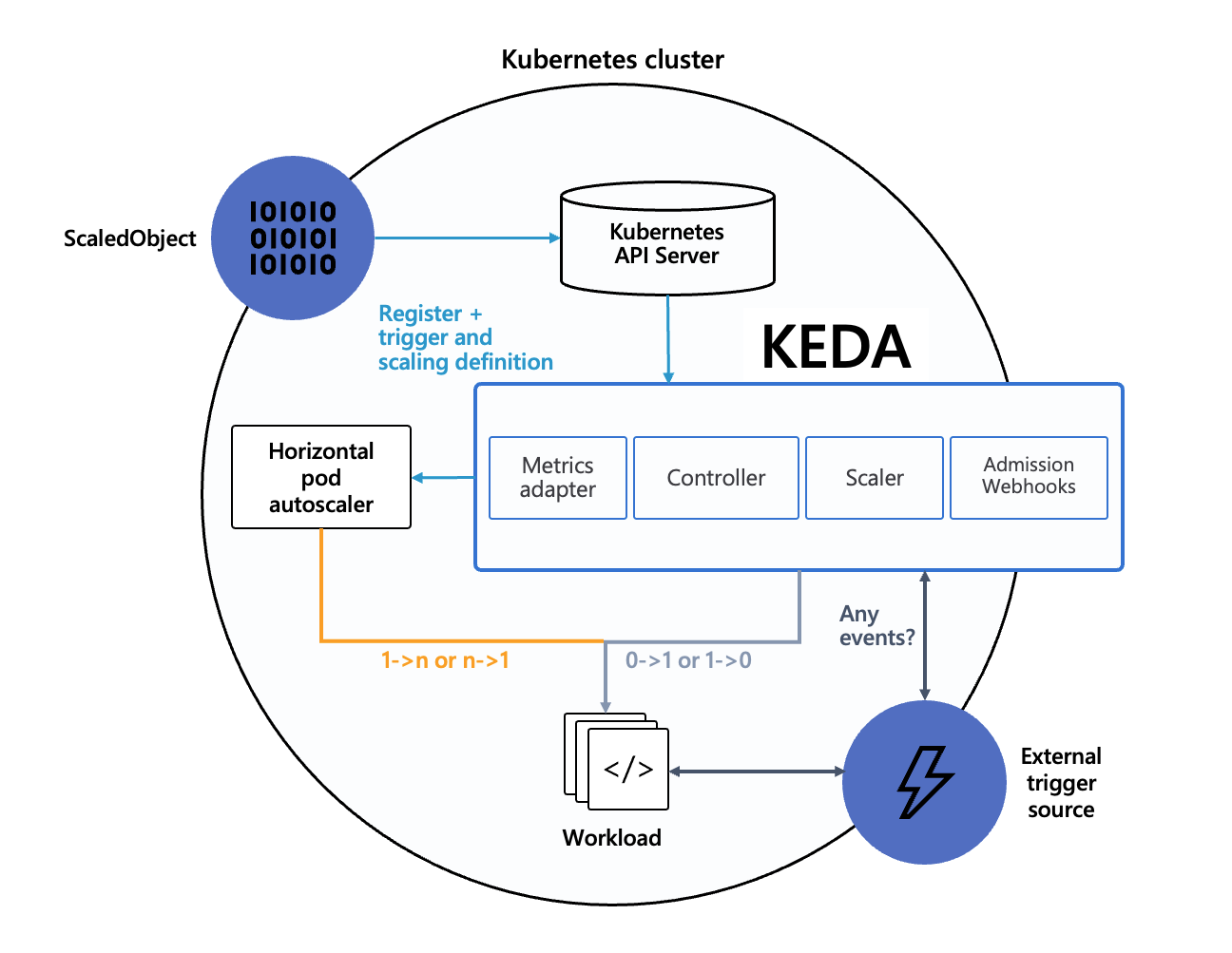
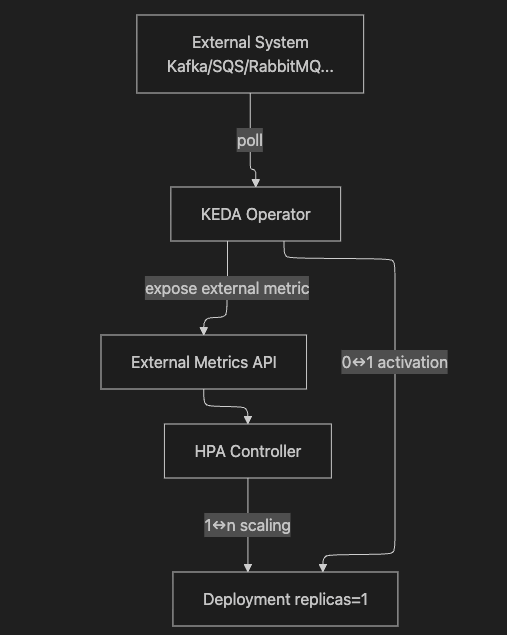
책의 핵심 요약은 다음입니다.
- 0 ↔ 1(Activation): KEDA Operator가 직접 스케일업(0→1) 합니다.
- 1 ↔ n(Active scaling): 워크로드가 활성화된 뒤에는 HPA가 KEDA가 제공하는 external metric을 이용해 스케일합니다.
KEDA 핵심 리소스
- ScaledObject: Deployment/StatefulSet 등 “스케일 대상” + “트리거(외부 메트릭)”를 정의합니다.
- ScaledJob: “replica가 아니라 Job 자체”를 이벤트 양에 맞춰 생성하는 모델입니다(배치/잡에 유리).
5.6 KEDA 예시(Example 29-7): Kafka ScaledObject
책의 Example 29-7을 그대로 가져왔습니다.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: kafka-scaledobject
spec:
scaleTargetRef:
name: kafka-consumer
pollingInterval: 30
triggers:
- type: kafka
metadata:
bootstrapServers: bootstrap.kafka.svc:9092
consumerGroup: my-group
topic: my-topicscaleTargetRef: 스케일 대상(기본은 Deployment)pollingInterval: (특히 0에서 올라올 때) KEDA가 트리거를 확인하는 주기triggers: 어떤 외부 시스템을 볼지(여기서는 Kafka)
운영 예시
“컨슈머 lag가 쌓이면 consumer를 늘린다”는 전형적인 패턴에서,
KEDA는 외부 시스템의 backlog를 직접 지표로 쓰는 것이 강점입니다.
5.7 HPA vs Knative vs KEDA 비교(Table 29-2 재구성)
책의 Table 29-2를 “운영자가 고르는 기준” 중심으로 다시 구성했습니다.
| 구분 | HPA | Knative | KEDA |
|---|---|---|---|
| 대표 워크로드 | 일반 서비스(특히 CPU 기반) | HTTP 서버리스(웹/API) | 이벤트 워커(큐/스트림) |
| Scale-to-Zero | 불가(minReplicas ≥ 1 필수) | 가능(기본 철학) | 가능 |
| 주요 메트릭 | CPU/메모리/커스텀/외부 | concurrency / RPS(트래픽 중심) | 외부 이벤트/큐/lag |
| 방식 | Pull(메트릭 API 조회) | Push(Activator/queue-proxy) | Pull(외부 polling) |
| Typical use case | 안정적 트래픽 웹 앱, 배치 처리 | 트래픽 없으면 0, 첫 요청 버퍼링 | 큐가 쌓이면 워커를 0→N |
6. VPA: Vertical Pod Autoscaler
VPA는 “Pod 한 개의 사이즈”를 맞추는 오토스케일러입니다.
특히 requests/limits를 잘못 잡아 생기는 문제(OOM, 과도한 낭비) 를 줄이는 데 강점이 있습니다.
6.1 VPA 구성요소 3종(recommender/admission/updater)
책의 Figure 29-4를 말로 풀면, VPA는 다음 3 컴포넌트가 협업합니다.
- Recommender: 실제 사용량을 기반으로 “권장 requests/limits”를 계산합니다.
- Admission Controller(웹훅): 새로 생성되는 Pod에 권장 값을 주입합니다(모드에 따라 활성화).
- Updater: 실행 중 Pod를 evict/reschedule 하는 방식으로 “운영 중 적용”을 수행합니다(모드에 따라 활성화).

6.2 updateMode: Off / Initial / Recreate / Auto
책에서 설명하는 모드를 운영 관점으로 정리하면 다음과 같습니다.
| 모드 | 무엇을 하나요? | 운영 난이도 |
|---|---|---|
| Off | 추천만 계산(Dry-run) | 낮음 (실무 기본 권장) |
| Initial | Pod 생성 시에만 추천값 주입 | 중간 |
| Recreate | 실행 중 Pod도 적용하되, 강제 evict/재생성 방식 | 높음 |
| Auto | 실행 중 Pod도 적용(Updater가 eviction/reschedule) | 높음 |
책 관점(중요): 의도 상
Auto는 재시작 없이(in-place) 자원 조정을 목표로 하지만, 책이 다루는 시점(2023)에서는Recreate와 동일하게 eviction/재시작으로 적용된다고 설명합니다.
실무 팁
처음에는 반드시 Off 로 “추천값을 충분히 모은 뒤” 매니페스트를 사람이 고정하는 방식이 안전합니다.
6.3 resourcePolicy: 컨테이너별 상·하한
VPA는 resourcePolicy로 컨테이너별 하한/상한을 줄 수 있습니다.
실무에서는 “갑자기 추천값이 너무 커지거나 너무 작아지는 것”을 막는 안전장치로 자주 사용합니다.
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: demo-nginx-vpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: demo-nginx
updatePolicy:
updateMode: "Off"
resourcePolicy:
containerPolicies:
- containerName: "*"
minAllowed:
cpu: 50m
memory: 64Mi
maxAllowed:
cpu: 500m
memory: 512Mi6.4 HPA+VPA 동시 사용 시 “Double Scaling” 위험
HPA와 VPA는 같은 축을 동시에 건드리면 예상치 못한 피드백 루프가 생길 수 있습니다.
- HPA는 replicas를 조절합니다.
- VPA는 requests/limits를 조절합니다.
문제는 HPA가 CPU utilization(= 사용량/requests)에 의존하는 경우입니다.
VPA가 requests를 올려버리면 utilization이 낮아져 HPA가 줄이고,
다시 utilization이 오르고… 같은 Double Scaling이 생길 수 있습니다.
권장 패턴(충돌 방지)
- HPA는 “replicas”만 책임지게 하되,
- VPA는 “Off/Initial”로 requests 튜닝에만 제한적으로 사용하고,
- 가능하면 HPA는 CPU utilization 대신 RPS/큐 길이 같은 지표로 역할 분담을 하시는 편이 안전합니다.
7. CA: Cluster Autoscaler
HPA/VPA가 “클러스터 내부에서 Pod를 조절”하는 이야기라면,
CA(Cluster Autoscaler)는 리소스 부족으로 Pod가 스케줄링되지 못해 Pending(Unschedulable) 상태가 발생했을 때 새 노드를 추가하는 방식으로, 노드 자체를 늘리고 줄여 클러스터 용량을 탄력화합니다.
7.1 Scale-up: Node Group 선택과 Expander 전략
책에서는 CA가 scale-up 시 node group을 확장하는데, 이때 “어떤 node group을 늘릴지”를 고르는 전략으로 expander를 소개합니다.
- least cost: 비용이 가장 낮은 그룹 우선
- least waste: 자원 낭비가 가장 적은 그룹 우선
- most pods: 가장 많은 Pending Pod를 수용할 수 있는 그룹 우선
- random: 임의 선택
운영 예시
CPU 노드그룹과 GPU 노드그룹이 함께 있을 때, expander가 없거나 설정이 부적절하면
“GPU 노드를 불필요하게 늘리는” 비용 사고가 날 수 있습니다.
7.2 Scale-down: 4가지 조건(책 기준)과 운영 함정
책에서 CA scale-down을 “안전하게” 수행하기 위한 4가지 조건을 명시합니다.
- 노드의 절반 이상이 유휴(Pod들의 요청 합이 node allocatable의 50% 미만)
- 그 노드의 이동 가능한 Pod들이 다른 노드에 배치 가능(CA가 스케줄링 시뮬레이션으로 검증)
- 노드 삭제를 막는 추가 방해 요인이 없음(예: scale-down 제외 annotation)
- 이동 불가능한 Pod가 없음
- PDB로 인해 이동 불가
- 로컬 스토리지 사용
- eviction 방지 annotation
- controller 없이 단독 생성된 Pod
- 일부 시스템 Pod 등
운영 함정(자주 겪는 장애)
“노드가 텅 비어 보이는데도” scale-down이 안 되는 이유는 대개 4번입니다.
특히 PDB / local PV / DaemonSet / eviction 방지 annotation 을 먼저 의심하시면 해결이 빨라집니다.
8. Scaling Levels 4단계(책 Figure 29-6)
책은 “어디부터 손대야 하는가?”를 더 명확하게 하기 위해 스케일링 레벨을 4단계로 정리합니다.
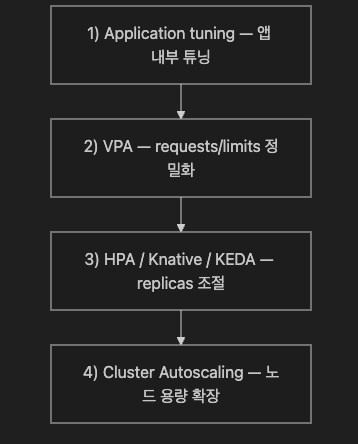
8.1 Application tuning(가장 미세한 레벨)
Kubernetes 밖의 이야기지만, “컨테이너 안 앱이 자원을 잘 쓰게” 만드는 단계입니다.
예시(자주 겪는 케이스)
- Java 힙을 너무 크게 잡으면 GC/메모리 압박으로 성능이 떨어지고 OOM이 나기도 합니다.
- 스레드풀/커넥션풀을 CPU shares에 맞춰 조정하지 않으면 CPU가 남아도 처리량이 안 나옵니다.
팁
이 단계가 제대로 되지 않으면, 그 위에서 HPA/VPA/CA를 아무리 잘 붙여도 “비효율이 커진 채로” 확장만 하게 됩니다.
부록 A. 실습: HPA + (선택) Knative/KEDA + (선택) VPA 추천값 확인
이 부록은 책 내용을 이해하기 위한 실습 가이드(책 밖 보충) 입니다. 운영 환경에 그대로 적용하기보다는, 개념 검증용으로 사용해 주세요.
목표: “부하를 만들고 → HPA가 replicas를 늘리고 → VPA 추천값을 확인”하는 흐름을 체험합니다.
Knative/KEDA는 환경이 갖춰졌다면 선택적으로 따라가시면 됩니다.
A.1 (필수) metrics-server 설치(없으면 HPA가 동작하지 않습니다)
kubectl apply -f <https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml>
kubectl -n kube-system rollout status deploy/metrics-serverA.2 테스트용 Deployment + Service
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-nginx
spec:
replicas: 2
selector:
matchLabels:
app: demo-nginx
template:
metadata:
labels:
app: demo-nginx
spec:
containers:
- name: nginx
image: nginx:1.27
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
memory: 128Mi
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: demo-nginx
spec:
selector:
app: demo-nginx
ports:
- port: 80
targetPort: 80kubectl apply -f demo.yamlA.3 HPA 적용 및 관찰
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: demo-nginx-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: demo-nginx
minReplicas: 2
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 10
periodSeconds: 60
scaleUp:
policies:
- type: Pods
value: 4
periodSeconds: 15kubectl apply -f hpa.yaml
kubectl get hpa -wA.4 부하 발생
kubectl run -it --rm loadgen --image=busybox:1.36 --restart=Never -- sh -c \\
'while true; do wget -q -O- <http://demo-nginx>; done'다른 터미널에서 관찰합니다.
kubectl get deploy,pod,hpa -w
kubectl top podA.5 (선택) VPA 추천값 확인
VPA는 클러스터에 따라 별도 설치가 필요합니다(설치 방법은 환경별로 상이하므로 공식 가이드를 참고해 주세요). 설치가 되어 있다면, 아래처럼 Off(추천만) 모드로 먼저 사용하시는 것을 권장드립니다.
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: demo-nginx-vpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: demo-nginx
updatePolicy:
updateMode: "Off"kubectl apply -f vpa.yaml
kubectl describe vpa demo-nginx-vpa9. Discussion: “Antifragile” 관점
책의 결론을 한 문장으로 요약하면, Elastic Scale은 단지 “늘리고 줄이는 자동화”가 아니라,
외부 스트레스(트래픽/부하)가 커질수록 시스템이 더 커지고 더 강해지는, 즉 “antifragile”에 가까운 특성을 제공한다
는 관점입니다.
장애를 “그냥 버티는(resilient)” 수준을 넘어, 부하가 올 때 더 유연하게 적응하며 강해지는 방향이 탄력적 확장의 목표입니다.
부록 B. Kubernetes v1.35 운영 보충(책 밖 내용)
이 부록은 책(2nd Edition, 2023) 이후의 Kubernetes 변화를 운영 관점에서 덧붙인 내용입니다.
- HPA tolerance 필드(Beta, 기본 활성화): 목표값 주변의 작은 변동에는 스케일링을 하지 않도록 하는 “민감도”를
tolerance로 조정할 수 있습니다.
짧은 스파이크가 잦은 서비스에서 불필요한 스케일링을 줄이는 데 도움이 됩니다. (공식 문서 참고)- In-Place Pod Resize(Stable/GA): Pod를 재생성하지 않고도 자원(requests/limits) 변경을 적용할 수 있는 방향으로 기능이 성숙하고 있습니다.
장기적으로는 “VPA 적용 시 eviction 부담”을 줄이는 기반이 될 수 있습니다.
실무 팁
기능의 활성화 여부/제약은 클러스터 설정과 런타임, 정책(Quota/LimitRange) 등에 따라 달라질 수 있으니, 적용 전에는 스테이징에서 반드시 검증하시는 것을 권장드립니다.
출처
- Bilgin Ibryam, Roland Huß, Kubernetes Patterns (2nd Edition), O’Reilly, 2023. Chapter 29: Elastic Scale
- Kubernetes 공식 문서: Horizontal Pod Autoscaling
- Kubernetes 공식 문서: HPA Walkthrough(External metrics 포함)
- Knative 공식 문서: Serving Architecture
- Knative 공식 문서: Configuring scale bounds(min/max/initial scale)
- KEDA 공식 문서: ScaledObject spec
- (선택) Kubernetes v1.35 참고: In-Place Pod Resize GA, v1.35 Release Notes(운영 보충 시 활용)
