1. 개념
- Job: “성공적으로 끝나는 것”이 목표인 일회성 작업 컨트롤러
- CronJob: 스케줄에 따라 Job을 반복 생성하는 컨트롤러 (다음 8장에서 다룰 예정)
- 성공 기준은
completions만큼의 성공한 Pod 수이며, 실패·재시도는 컨트롤러가 관리 - 병렬화는 두 갈래
- 고정 개수(Indexed) 분할 → 샤딩에 최적
- Work Queue → 작업 수를 모를 때, 동적 분배에 최적
- 운영의 포인트는 재시도 정책, 리소스/한도, 히스토리/TTL 정리, 동시 실행 제어입니다.
2. Job 생성의 이점
- 완결형 보장:
completions로 끝나는 작업을 선언적으로 관리. - 실패·재시도 내장:
backoffLimit,activeDeadlineSeconds, *podFailurePolicy로 세밀 제어. - 병렬 처리 용이:
parallelism/completions, Indexed(샤딩)·워크큐 패턴 모두 지원. - 자원·부하 조절: 동시성으로 스파이크 완화, Quota/우선순위와 연동.
- 자동 청소:
ttlSecondsAfterFinished로 완료 리소스 정리. - 장애 내성: 노드 드레인 등은 무시하고 대체 파드로 이어서 수행 가능.
- 관측·디버깅 쉬움: 상태/이벤트/로그로 진행·실패 원인 추적.
- 보안·거버넌스/비용 효율: K8s 표준 보안 적용 + 필요할 때만 실행되어 비용 절감.
3. 언제 Batch Job을 쓰나
- 스키마 마이그레이션/데이터 백필/리포트 생성/대량 파일 변환 등 유한하고 멱등 설계가 가능한 작업
- 정확히 N개 파티션만 처리하면 되는 샤딩 배치(Indexed)
- 간헐적·대용량 처리를 안전하게 동시성 제어 하에 진행하고 싶을 때
4. Job
apiVersion: batch/v1
kind: Job
metadata:
name: nginx-indexed-job
spec:
completions: 8 # 1
parallelism: 3 # 2
completionMode: Indexed # 3
backoffLimit: 3 # 4
activeDeadlineSeconds: 1800 # 5
ttlSecondsAfterFinished: 300 # 6
podFailurePolicy: # 7
rules:
- action: FailJob # 7-1
onExitCodes:
containerName: nginx-worker
operator: In
values: [2, 42]
- action: Ignore # 7-2
onPodConditions:
- type: DisruptionTarget
- action: Count # 7-3
onExitCodes:
containerName: nginx-worker
operator: In
values: [137]
template:
metadata:
labels:
app: nginx-batch
spec:
restartPolicy: Never
containers:
- name: nginx-worker
image: nginx:1.27-alpine
env:
- name: JOB_COMPLETION_INDEX
valueFrom:
fieldRef:
fieldPath: metadata.annotations['batch.kubernetes.io/job-completion-index']
- name: TOTAL_SHARDS
value: "8"
command: ["/bin/sh","-c"]
args:
- |
echo "[NGINX Job] shard index=${JOB_COMPLETION_INDEX}/${TOTAL_SHARDS}";
# (데모) 인덱스별 가짜 작업 수행 후 정상 종료
sleep 1
echo "Shard ${JOB_COMPLETION_INDEX} done."
.spec.completions: 총 성공 Pod 수(작업 개수).spec.parallelism: 동시 실행 Pod 수(동시성).spec.completionMode: Indexed→ 각 Pod에 고유 인덱스 부여(샤딩)- NonIndexed (기본값): 파드들이 서로 구분되지 않음.
.spec.completions개수만큼 성공한 파드 수가 채워지면 Job 완료로 간주합니다. 워크 큐 패턴처럼 “같은 일을 하는 파드 여러 개”에 적합 - Indexed: 각 파드가 0 ~ completions-1 인덱스를 부여받아 샤딩 수행. 각 인덱스마다 최소 1개 파드가 성공해야 완료로 간주합니다
- NonIndexed (기본값): 파드들이 서로 구분되지 않음.
.spec.backoffLimit: Pod가 실패할 때 새 Pod 재시도 횟수.spec.activeDeadlineSeconds: 전체 작업의 최대 허용 시간(초).spec.ttlSecondsAfterFinished: 완료 후 자동 정리(가비지).spec.podFailurePolicy: 종료 코드/조건에 따라 재시도/실패 정책 세밀화- 특정 종료코드(2,42)는 재시도 의미 없음 → 잡 즉시 실패 처리
- 재시도가 의미가 없는 비복구성 오류를 빠르게 멈추고 리소스 낭비를 막고 싶을 때.
- 노드 드레인/중단 등 방해(Disruption)는 실패 카운트에서 제외하고 교체 Pod 생성
- 재시도가 의미가 없는 비복구성 오류(예: 잘못된 입력, 코드 버그, 설정 치명적 오류)를 빠르게 멈추고 리소스 낭비를 막고 싶을 때.
- OOMKilled(보통 137) 같은 경우는 기본 동작대로 실패 카운트 증가(명시적 Count)
- 일시적인 리소스 압박이나 간헐적 실패일 수 있어 재시도 자체는 의미가 있지만, 그래도 backoff 한도(
backoffLimit)를 넘으면 잡을 실패로 보고 싶을 때
- 일시적인 리소스 압박이나 간헐적 실패일 수 있어 재시도 자체는 의미가 있지만, 그래도 backoff 한도(
- 특정 종료코드(2,42)는 재시도 의미 없음 → 잡 즉시 실패 처리
5. Job 종류
.spec.completions / .spec.parallelism 두개의 파라미터를 기준으로 다음 Job으로 구분
1) 단일 파드 잡 (Single Pod Job)
.spec.completions/.spec.parallelism을 생략하거나 기본 값으로 1으로 설정하는 경우- 하나의 파드만 시작하고, 파드가 성공적으로 종료되자마자 완료된다.
2) 고정 완료 횟수 잡 (Fixed completion count Job)
- 1보다 큰 수를
.spec.completions에 지정하면, 많은 파드가 성공해야 한다. .spec.completions설정 값과 같은 수의 파드가 성공적으로 완료되어야 해당 잡이 완료된 것으로 간주한다.
3) 작업 큐 잡
.spec.completions를 생략하고,.spec.parallelism를 1보다 큰 정수로 세팅하면, 병렬 잡에 대한 작업 큐를 가진다.- 최소한 하나의 파드가 성공적으로 종료되고, 또 다른 모든 파드가 종료될 때 완료된 것으로 간주된다.
- 하나의 파드가 여러 작업항목을 처리하므로, 해당 잡 유형은 세분화된 작업 항목에 매우 적절하다.
6. 내용 보강
1) SuccessPolicy (completionMode: Indexed에만 해당)
- Indexed Job에서 “몇개만 성공해도 Job 종료”와 같은 조기 성공 조건을 선언적으로 지정할 수 있다.
- 필드 :
.spec.successPolicy(v1.33에서 GA) → 해당 조전을 만족하면 남은 파드도 모두 종료 됨spec: completions: 8 completionMode: Indexed successPolicy: rules: - succeededIndexes: 0 # 지정된 파드 리더 (0번)이 성공하는 경우 succeededCount: 1succeededIndexes: 해당 인덱스(샤드)들이 성공해야 Job을 성공으로 간주할지를 지정합니다.succeededCount: 지정된 파드의 성공 개수
2) BackoffLimitPerIndex / MaxFailedIndexes (Indexed Job의 실패 한도 세분화)
.spec.backoffLimitPerIndex: 인덱스별 재시도 한도..spec.maxFailedIndexes: 실패 인덱스가 이 값을 넘으면 Job 실패.- v1.33에서 GA로 승격(과거 1.28에 등장). Indexed +
restartPolicy: Never에서만 사용 가능.\spec: completionMode: Indexed backoffLimitPerIndex: 3 maxFailedIndexes: 1 template: spec: restartPolicy: Never
3) PodReplacementPolicy (교체 파드 생성 시점 제어)
.spec.podReplacementPolicy: 파드 완전 종료 후 교체할지, 종료 시작(terminating)만 돼도 교체할지 선택.- 값 예시:
Failed(완전 실패 후 교체),TerminatingOrFailed(기존 동작).
- 값 예시:
- PodFailurePolicy를 설정하면 기본값이
Failed이고 다른 값은 허용되지 않음—겹실행/중복 처리 위험을 줄입니다. - 해당 기능은 Job API 개선 흐름(1.28~)에서 소개, 최근 릴리스 노트에도 명시됩니다. Kubernetes+1
예시:
spec:
podFailurePolicy: { ... }
podReplacementPolicy: Failed # PFP가 있으면 실제로는 Failed만 허용
4) managedBy (외부 컨트롤러가 Job을 관리)
.spec.managedBy로 내장 Job 컨트롤러 대신 외부 컨트롤러(예: Kueue)가 조정하도록 위임 가능.- v1.32에서 베타로 기본 활성화(클러스터에 따라 다름). 값은 도메인 접두 경로 문자열이어야 하며, 내장 컨트롤러 예약어인
kubernetes.io/job-controller는 금지.spec: managedBy: "kueue.x-k8s.io"
7. 실습 코드
0) 준비
-
kube-linter 적용(
.kube-linter.yaml)checks: include: - "unset-cpu-requirements" - "unset-memory-requirements" - "no-anti-affinity" - "minimum-three-replicas" - "mismatching-selector" - "required-annotation-email" - "no-read-only-root-fs" -
쿠버네티스 버전 확인 ⇒ v1.34버전으로 테스트 진행
kubectl version
- 네임 스페이스 생성
# 네임스페이스 생성 kubectl create ns job-lab kubectl get ns
- 실습 코드 생성 (
configmap-worker-scripts.yaml)apiVersion: v1 kind: ConfigMap metadata: name: job-worker-scripts namespace: job-lab data: worker.sh: | #!/bin/sh set -eu idx="${JOB_COMPLETION_INDEX:-0}" mode="${MODE:-ok}" echo "[worker] mode=$mode index=$idx" case "$mode" in ok) echo "OK shard $idx" exit 0 ;; exit42) # FAIL_INDEX와 인덱스가 같으면 42로 즉시 종료(비복구성 에러 시뮬) if [ "${FAIL_INDEX:-3}" = "$idx" ]; then echo "Failing index $idx with exit 42" exit 42 fi echo "OK shard $idx" exit 0 ;; always_fail) # 특정 인덱스는 항상 실패(재시도/백오프/FailIndex 실험용) if [ "${FAIL_INDEX:-5}" = "$idx" ]; then echo "Always failing index $idx" exit 1 fi echo "OK shard $idx" exit 0 ;; *) echo "unknown MODE=$mode" exit 2 ;; esac
- 배포 진행
kubectl apply -f configmap-worker-scripts.yaml
위 스크립트는 세 가지 모드를 지원합니다.
MODE=ok: 성공MODE=exit42+FAIL_INDEX=N: 특정 인덱스에서 exit 42MODE=always_fail+FAIL_INDEX=N: 특정 인덱스 항상 실패
1) Indexed + SuccessPolicy (조기 성공)
[목표]
- 8개 샤드 중 6개만 성공해도 Job 완료. 나머지 파드는 컨트롤러가 정리합니다.
[실습]
- Job 코드 작성 (
job-indexed-successpolicy.yaml)# filename: job-indexed-successpolicy.yaml apiVersion: batch/v1 kind: Job metadata: name: indexed-successpolicy namespace: job-lab annotations: owner: "신복호" email: "gjrjr4545@gmail.com" # 요구되는 이메일 어노테이션 spec: completions: 8 parallelism: 4 completionMode: Indexed successPolicy: rules: - succeededCount: 6 backoffLimit: 2 activeDeadlineSeconds: 1800 ttlSecondsAfterFinished: 300 template: metadata: labels: app: sp-demo spec: restartPolicy: Never securityContext: seccompProfile: type: RuntimeDefault fsGroup: 1000 fsGroupChangePolicy: "OnRootMismatch" containers: - name: worker image: alpine:3.20 imagePullPolicy: IfNotPresent command: ["/scripts/worker.sh"] env: - name: MODE value: "ok" - name: JOB_COMPLETION_INDEX valueFrom: fieldRef: fieldPath: metadata.annotations['batch.kubernetes.io/job-completion-index'] securityContext: runAsUser: 1000 runAsGroup: 1000 runAsNonRoot: true readOnlyRootFilesystem: true allowPrivilegeEscalation: false capabilities: drop: ["ALL"] resources: requests: cpu: "100m" memory: "128Mi" limits: cpu: "500m" memory: "256Mi" volumeMounts: - name: scripts mountPath: /scripts readOnly: true - name: tmp mountPath: /tmp # RO 루트FS 대비 쓰기 가능한 tmp volumes: - name: scripts configMap: name: job-worker-scripts defaultMode: 0755 - name: tmp emptyDir: {} - Job 배포
kubectl apply -f job-indexed-successpolicy.yaml - 확인
kubectl -n job-lab get job indexed-successpolicy -o wide kubectl -n job-lab get pods -l job-name=indexed-successpolicy -o wide kubectl -n job-lab describe job indexed-successpolicy | sed -n '1,120p' kubectl -n job-lab logs -l job-name=indexed-successpolicy --all-containers --prefix
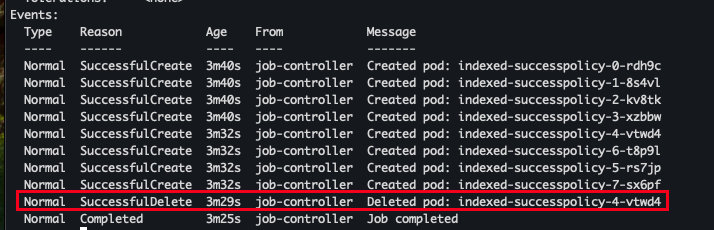
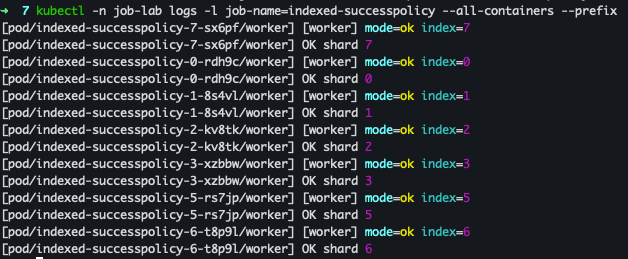
- 확인 결과
- 전체 8개 중 7개 성공, 1개 삭제 (4번 - Job이 성공 조건을 만족했기 때문에 컨트롤러가 불필요한 Pod을 정리한 것)
- 조건에 대해 성공하거나 실패하였을 경우 그 이후로 파드 SuccessfulDelete 진행

2) podFailurePolicy: FailJob (비복구성 코드 즉시 실패)
[목표]
- 특정 인덱스가 exit 42를 내면 잡 전체를 즉시 실패
[실습]
-
실패 Job 코드 작성 (
job-pfp-failjob-exit42.yaml)# filename: job-pfp-failjob-exit42.yaml apiVersion: batch/v1 kind: Job metadata: name: pfp-failjob-exit42 namespace: job-lab annotations: owner: "신복호" email: "owner@example.com" # ← 실제 이메일로 교체 spec: completions: 8 parallelism: 3 completionMode: Indexed backoffLimit: 3 activeDeadlineSeconds: 1800 ttlSecondsAfterFinished: 300 # 특정 종료코드(42) → 즉시 Job 실패 podFailurePolicy: rules: - action: FailJob onExitCodes: containerName: worker operator: In values: [42] template: metadata: labels: app: pfp-failjob-exit42 spec: restartPolicy: Never securityContext: seccompProfile: type: RuntimeDefault fsGroup: 1000 fsGroupChangePolicy: "OnRootMismatch" containers: - name: worker image: alpine:3.20 imagePullPolicy: IfNotPresent command: ["/scripts/worker.sh"] env: - name: MODE value: "exit42" - name: FAIL_INDEX value: "3" # 3번 인덱스에서 exit 42 발생 - name: JOB_COMPLETION_INDEX valueFrom: fieldRef: fieldPath: metadata.annotations['batch.kubernetes.io/job-completion-index'] securityContext: runAsUser: 1000 runAsGroup: 1000 runAsNonRoot: true readOnlyRootFilesystem: true allowPrivilegeEscalation: false capabilities: drop: ["ALL"] resources: requests: cpu: "100m" # ← CPU 요청 추가(린트 요구) memory: "128Mi" limits: cpu: "500m" memory: "256Mi" volumeMounts: - name: scripts mountPath: /scripts readOnly: true - name: tmp mountPath: /tmp # RO 루트FS 대비 쓰기 가능한 tmp volumes: - name: scripts configMap: name: job-worker-scripts defaultMode: 0755 - name: tmp emptyDir: {}
- Job 생성
kubectl apply -f job-pfp-failjob-exit42.yaml
- 확인
kubectl -n job-lab describe job pfp-failjob-exit42 | sed -n '1,200p' # Conditions에 Failed, reason=PodFailurePolicy 유사 메시지가 찍힙니다. kubectl -n job-lab get pods -l job-name=pfp-failjob-exit42 kubectl -n job-lab logs -l job-name=pfp-failjob-exit42 --all-containers --prefix
- 확인 결과 : 실행도중 Error가 발생하여.. 이후 프로세스 중단
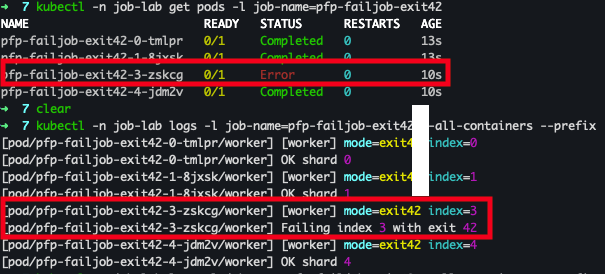
3) Indexed 실패 한도: backoffLimitPerIndex / maxFailedIndexes
[목표]
- 인덱스별 재시도 한도를 3회로, 실패 인덱스 최대 1개까지 허용.
[설정]
restartPolicy: Never+completionMode: Indexed가 전제.
[실습]
-
Job 코드 작성 (
job-indexed-backoff-per-index.yaml)# filename: job-indexed-backoff-per-index.yaml apiVersion: batch/v1 kind: Job metadata: name: indexed-backoff-per-index namespace: job-lab annotations: owner: "신복호" email: "owner@example.com" # <-- 요구된 이메일 어노테이션 spec: completions: 8 parallelism: 4 completionMode: Indexed backoffLimitPerIndex: 3 maxFailedIndexes: 1 activeDeadlineSeconds: 1800 ttlSecondsAfterFinished: 300 template: metadata: labels: app: indexed-backoff-per-index spec: restartPolicy: Never securityContext: seccompProfile: type: RuntimeDefault fsGroup: 1000 fsGroupChangePolicy: "OnRootMismatch" containers: - name: worker image: alpine:3.20 imagePullPolicy: IfNotPresent command: ["/scripts/worker.sh"] env: - name: MODE value: "always_fail" - name: FAIL_INDEX value: "5" # 5번 인덱스는 늘 실패(3회 재시도 후 실패 인덱스로 집계) - name: JOB_COMPLETION_INDEX valueFrom: fieldRef: fieldPath: metadata.annotations['batch.kubernetes.io/job-completion-index'] securityContext: runAsUser: 1000 runAsGroup: 1000 runAsNonRoot: true readOnlyRootFilesystem: true allowPrivilegeEscalation: false capabilities: drop: ["ALL"] resources: requests: cpu: "100m" memory: "128Mi" limits: cpu: "500m" memory: "256Mi" volumeMounts: - name: scripts mountPath: /scripts # 실행 스크립트 (ConfigMap, read-only) readOnly: true - name: tmp mountPath: /tmp # read-only rootfs 대비 쓰기 가능 tmp volumes: - name: scripts configMap: name: job-worker-scripts defaultMode: 0755 - name: tmp emptyDir: {} # /tmp 쓰기 가능 볼륨 -
배포
kubectl apply -f job-indexed-backoff-per-index.yaml
- 확인
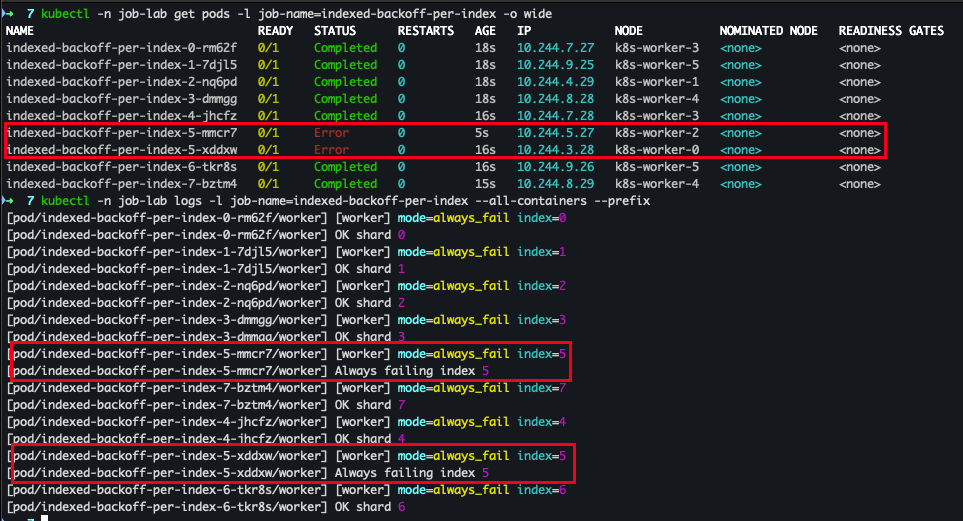
# 인덱스 5는 3회까지 재시도 후 '실패 인덱스'로 집계. # maxFailedIndexes=1을 넘기면 잡이 실패합니다. kubectl -n job-lab describe job indexed-backoff-per-index | sed -n '1,200p' kubectl -n job-lab get pods -l job-name=indexed-backoff-per-index -o wide kubectl -n job-lab logs -l job-name=indexed-backoff-per-index --all-containers --prefix
- 확인 결과 : 5번 파드 2번 실행 → 2번 실패되어 실패 처리 진행
4) podFailurePolicy: Count + OOM(137) 테스트
[목표]
- 컨테이너가 OOMKilled(137) 되면 Count로 실패 카운트를 증가시키고, backoffLimit에 따라 재시도.
- 이미지에 메모리 할당 도구가 있어야 합니다. 여기선
python:3.12-alpine사용 + 메모리 limit을 작게 잡아 OOM을 유도합니다.
[실습]
-
코드 작성 (
job-pfp-count-oom.yaml)# filename: job-pfp-count-oom.yaml apiVersion: batch/v1 kind: Job metadata: name: pfp-count-oom namespace: job-lab annotations: owner: "신복호" email: "gjrjr4545@gmail.com" # ← 실제 이메일로 교체 spec: completions: 4 parallelism: 2 completionMode: Indexed backoffLimit: 2 activeDeadlineSeconds: 900 ttlSecondsAfterFinished: 300 # OOMKilled(137) → 실패 카운트 증가(Count) 후 backoff 전략 적용 podFailurePolicy: rules: - action: Count onExitCodes: containerName: py operator: In values: [137] template: metadata: labels: app: pfp-count-oom spec: restartPolicy: Never securityContext: seccompProfile: type: RuntimeDefault fsGroup: 1000 fsGroupChangePolicy: "OnRootMismatch" containers: - name: py image: python:3.12-alpine imagePullPolicy: IfNotPresent command: ["python","-c"] args: - | a=[] # 일부러 메모리 사용을 늘려 OOMKilled 유도 while True: a.append(bytearray(64*1024*1024)) env: - name: JOB_COMPLETION_INDEX valueFrom: fieldRef: fieldPath: metadata.annotations['batch.kubernetes.io/job-completion-index'] securityContext: runAsUser: 1000 runAsGroup: 1000 runAsNonRoot: true readOnlyRootFilesystem: true allowPrivilegeEscalation: false capabilities: drop: ["ALL"] resources: requests: cpu: "100m" # ← CPU 요청 추가(린트 요구) memory: "64Mi" limits: cpu: "500m" memory: "128Mi" volumeMounts: - name: tmp mountPath: /tmp # RO 루트FS 대비 쓰기 가능한 tmp volumes: - name: tmp emptyDir: {}
- 배포
kubectl apply -f job-pfp-count-oom.yaml
- 확인
kubectl describe job pfp-count-oom -n job-lab | sed -n '1,200p' kubectl get pods -n job-lab -l job-name=pfp-count-oom -o wide kubectl describe pods pfp-count-oom-0-f6v59 -n job-lab
- 확인 결과

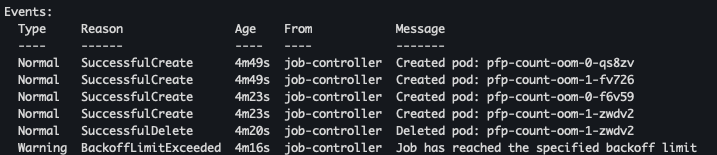
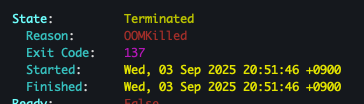
기타 관측/디버깅에 유용한 명령 모음
- 코드
# 잡 진행 상태 실시간 확인 watch -n 2 kubectl -n job-lab get job,pod -o wide # 잡 이벤트/컨디션 확인 kubectl -n job-lab describe job <JOB_NAME> # 인덱스별 Pod와 어노테이션(인덱스) 확인 kubectl -n job-lab get pod -l job-name=<JOB_NAME> -o jsonpath='{range .items[*]}{.metadata.name}{" index="}{.metadata.annotations.batch\.kubernetes\.io/job-completion-index}{"\n"}{end}' # 모든 파드 로그 보기 kubectl -n job-lab logs -l job-name=<JOB_NAME> --all-containers --prefix --tail=-1
6) 정리(클린업)
kubectl delete ns job-lab8) 주요 출처(Official & Authoritative)
- Jobs 개념/동작/백오프 기본값
- Pod Failure Policy (GA v1.31)
- Work Queue 예제(세밀/대략 분할)
- Backoff Limit Per Index / Pod Replacement Policy (도입 설명)
- Backoff Limit Per Index (GA v1.33)
- SuccessPolicy (GA v1.33)
- Pod Replacement Policy 추가 언급
- Indexed 인덱스 주입 설명(참고)
- API 레퍼런스(ManagedBy 포함)
- 공식 예제 YAML (BackoffLimitPerIndex)

DevOps Engineer
안녕하세요. 글 잘 읽었습니다.
podReplacementPolicy가 TerminatingOrFailed 로 설정하면, pod가 terminating인 경우에도 새로운 pod를 생성하고, 이것이 기본동작인 것으로 이해했습니다.
job이 성공한 pod 개수를 확인할 수 있어야 할 텐데, pod가 terminating 상태여도 pod의 성공/실패 여부를 확인할 수 있는지 궁금합니다.