인프런 권철민님 강의 정리
Sectio4: 분류(Classfication)
분류
- 학습 데이터로 주어진 데이터의 피처와 레이블 값을 학습하여
새로운 데이터 값이 주어졌을 때, 미지의 레이블 값을 예측하는 것
결정 트리
- 쉽고 유연하게 적용될 수 있는 알고리즘
- 데이터 스케일링, 정규화 등의 사전 가공의 영향이 적다.
- 예측 성능을 향상시키기 위해 복잡한 규칙 구조를 가져야 하지만 이로 인해 과적합이 발생할 수도 있다.
- 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내서 트리 기반의 분류 규칙을 만듦 (if-else 기반)
정보 균일도
정보 이득 (Information Gain)
- 엔트로피 개념 기반 지수
- 엔트로피: 데이터 집합의 혼잡도를 의미
- 서로 다른 값이 섞여 있으면 엔트로피가 높고, 같은 값이 섞여 있으면 엔트로피가 낮음
- 엔트로피: 데이터 집합의 혼잡도를 의미
- 정보 이득 지수: 1 - 엔트로피 지수
- 정보 이득이 높은 속성을 기준으로 결정 트리는 분할함
- 정보 이득 높다 = 엔트로피 낮다
지니 계수
- 경제학에서 불평등 지수를 나타낼 때 사용하는 계수
- 0이 가장 평등, 1로 갈수록 불평등
- 지니 계수가 낮을 수록 데이터 균일도가 높은 것으로 판단
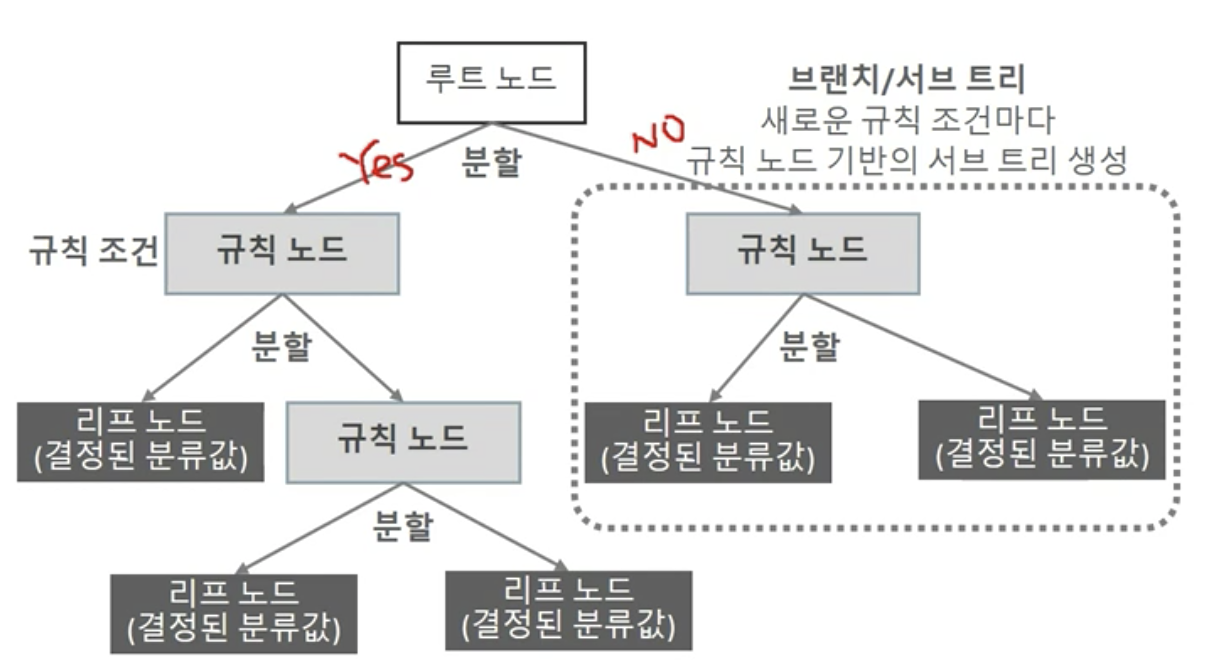
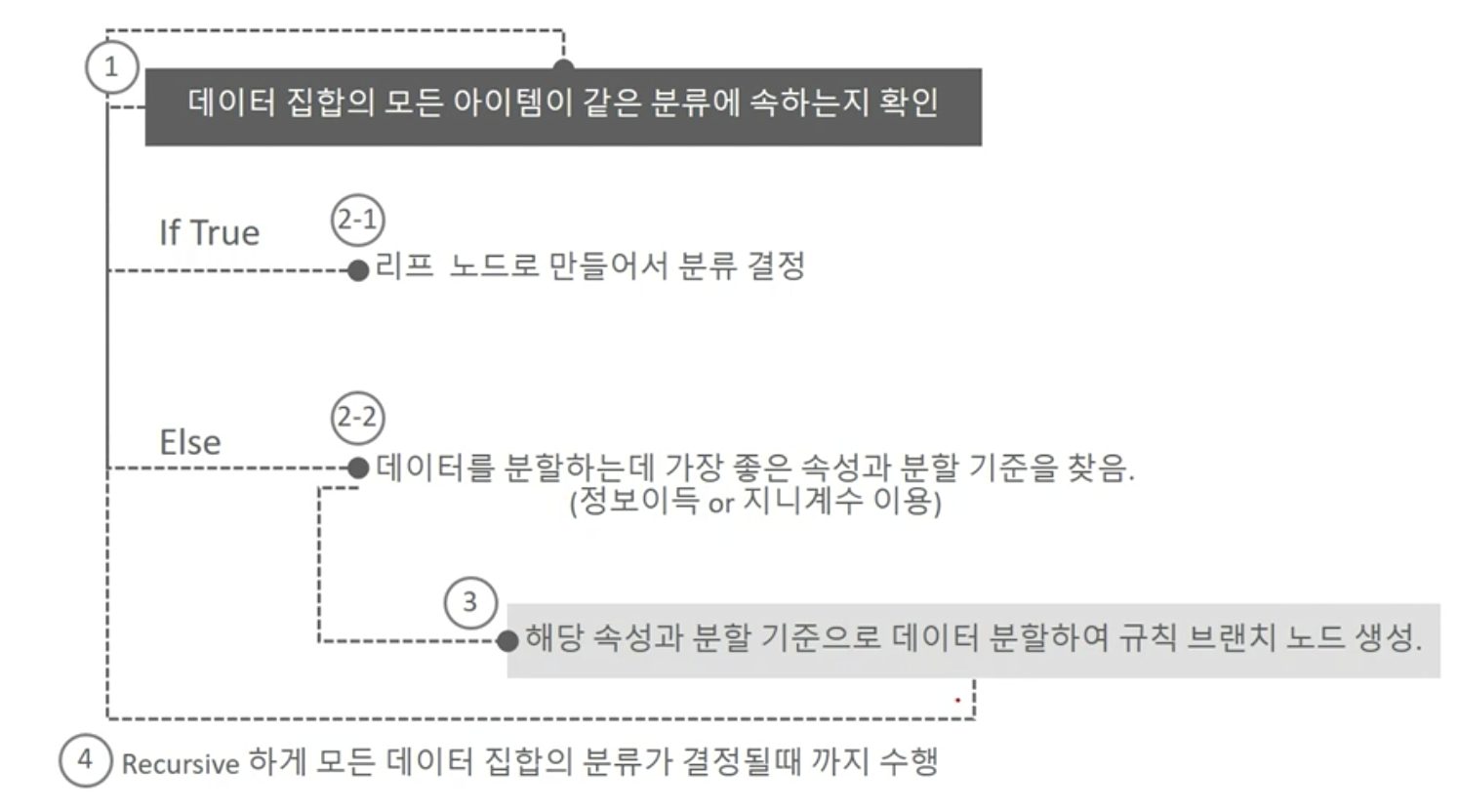
결정 트리의 규칙 노드 생성 프로세스
특징
- 쉽고 직관적이다.
- 피처 스케일링, 정규화 등의 사전 가공 영향도가 적음
- 과적합으로 알고리즘 성능이 떨어진다.
- 사전에 트리 크기를 제한하는 튜닝 필요
결정 트리 주요 하이퍼 파라미터
- max_depth: 트리의 최대 깊이
- max_features: 최적의 분할을 위해 고려할 최대 피처 개수
- min_samples_split: 노드를 분할하기 위한 최소한의 샘플 데이터 수
- min_samples_leaf: 말단 노드가 되기 위한 최소한의 샘플 데이터 수
- max_leaf_nodes: 말단 노드의 최대 개수
예시

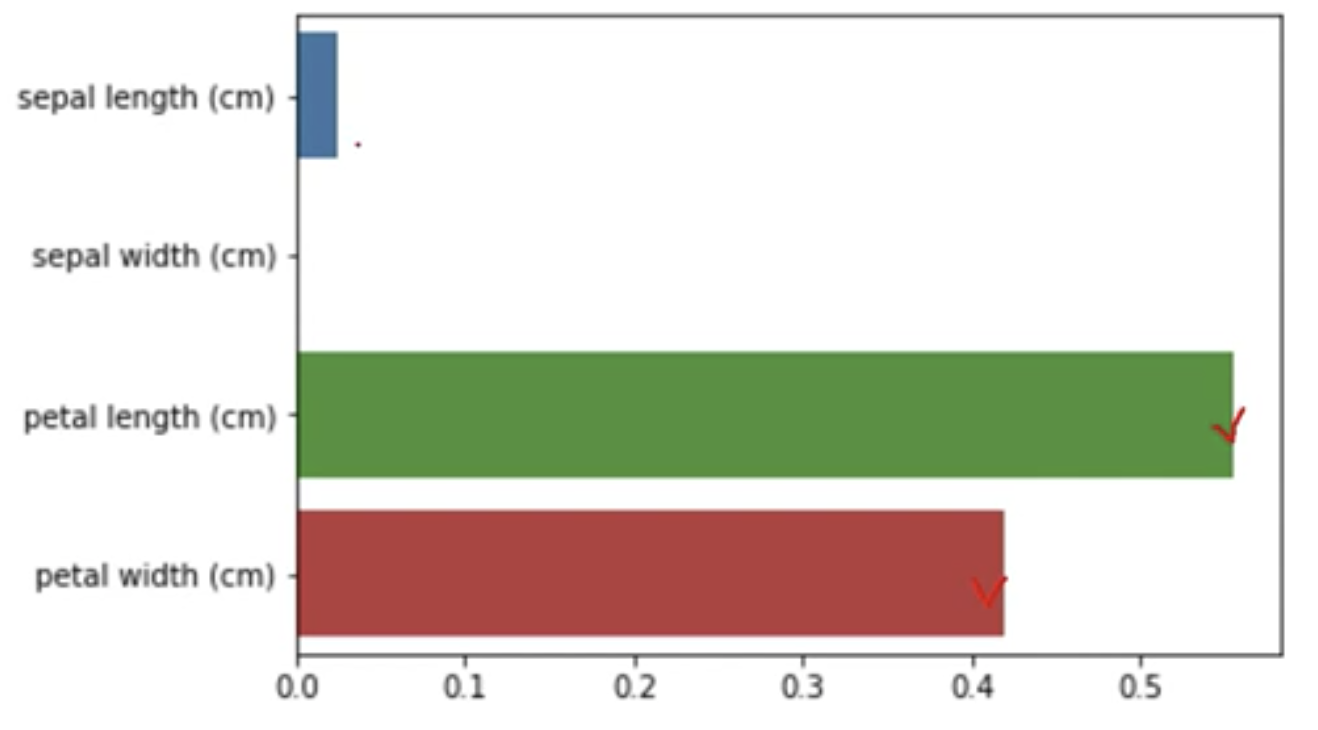
피처 중요도 확인
feature_importances_사용
앙상블
- 약한 학습기(예측 성능이 떨어지는 알고리즘)를 결합해 확률적 보완과 오류가 발생한 부분에 대한 가중치를 업데이트하면서 예측 성능을 향상시키는 기법
- 유형
- 보팅
- 배깅: RandomForest
- 부스팅: AdaBoosting, XGBoost, LightGBM
- 특징
- 단일 모델의 약점을 다수의 모델들을 결합하여 보완
- 서로 다른 모델을 섞는 것이 오히려 전체 성능이 도움이 될 수 있음
- 부스팅 알고리즘들은 모두 결정 트리 알고리즘 기반
- 결정 트리 단점인 과적합을 많은 수의 분류기를 결합하여 보완하고 직관적인 분류 기준은 강화됨
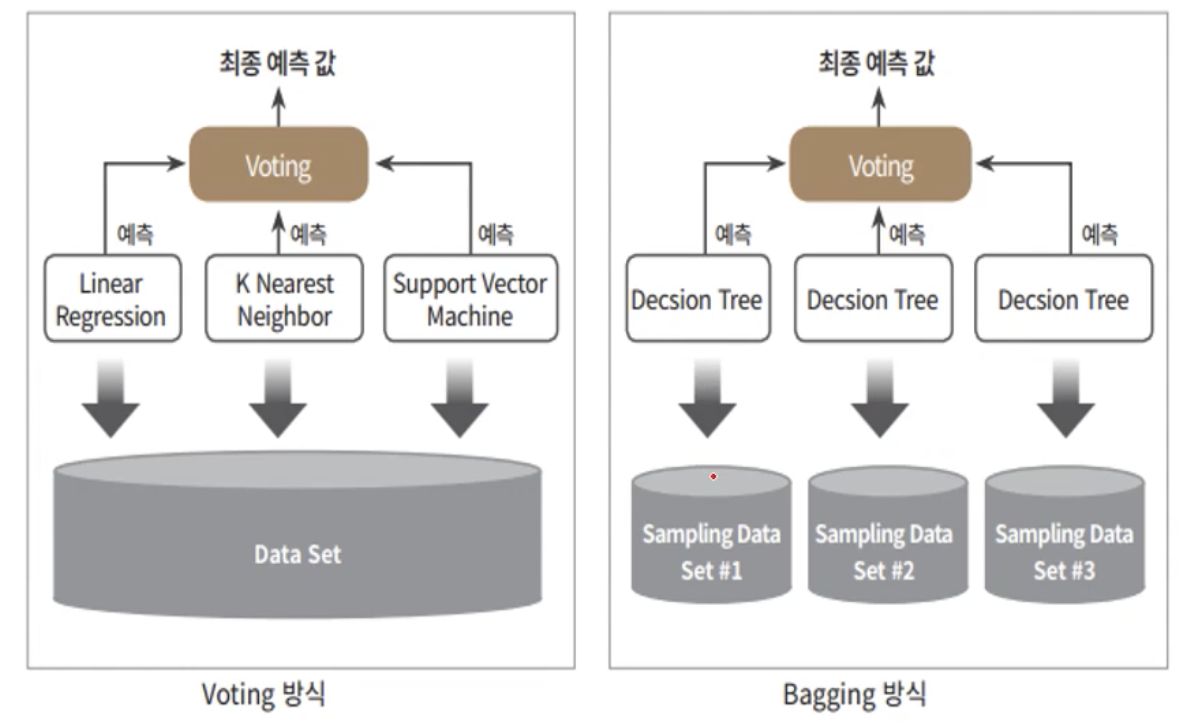
보팅, 배깅
- 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식
- 차이점
- 보팅: 다른 알고리즘 결합
- 배깅: 같은 알고리즘 기반, 서로 다른 샘플 데이터
보팅
- 하드 보팅: 다수결의 원칙
- 소프트 보팅: 클래스별 확률을 평균하여 결정함
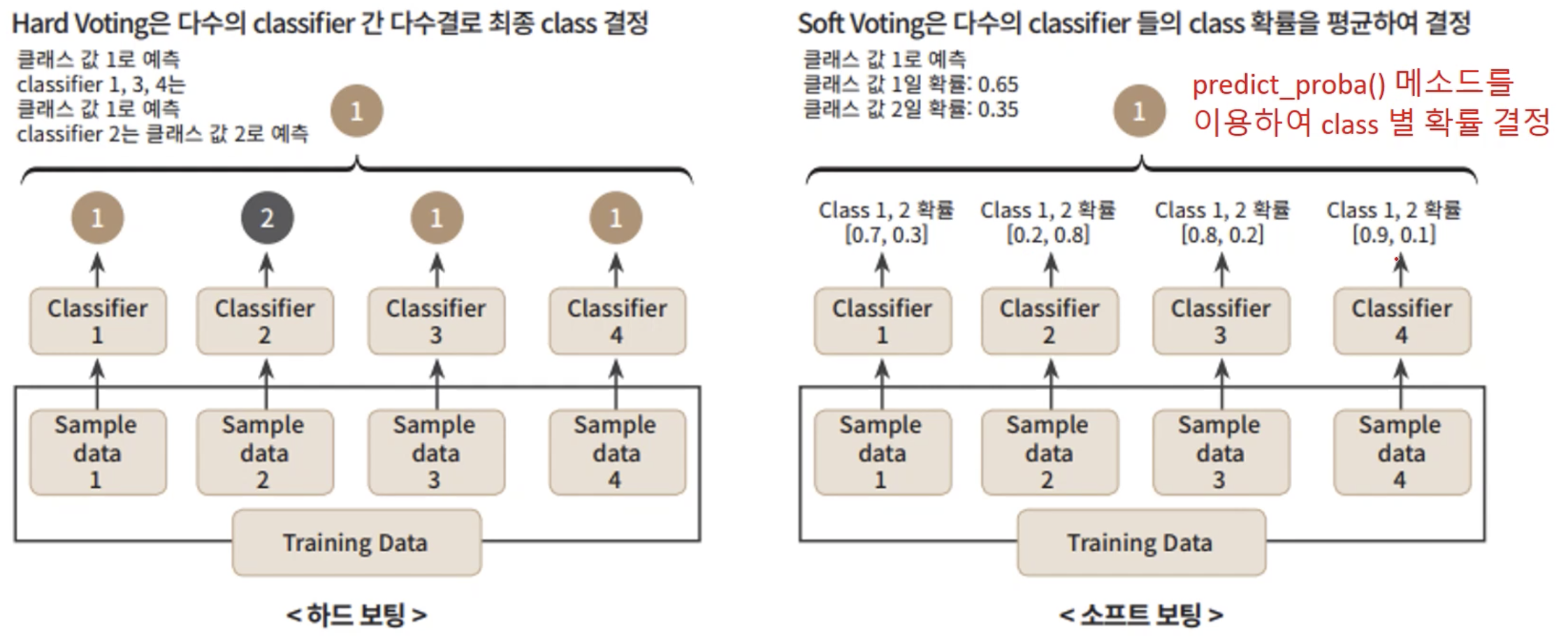
- 일반적으로 소프트 보팅의 성능이 뛰어나서 주로 사용됨
배깅
- 대표적인 알고리즘: Random Forest
- 빠른 수행 속도
- 다양한 영역에서 높은 예측 성능
- 부트스트래핑: 데이터 세트를 중첩되게 분리하는 방식
- Bagging = Bootstrap aggregating
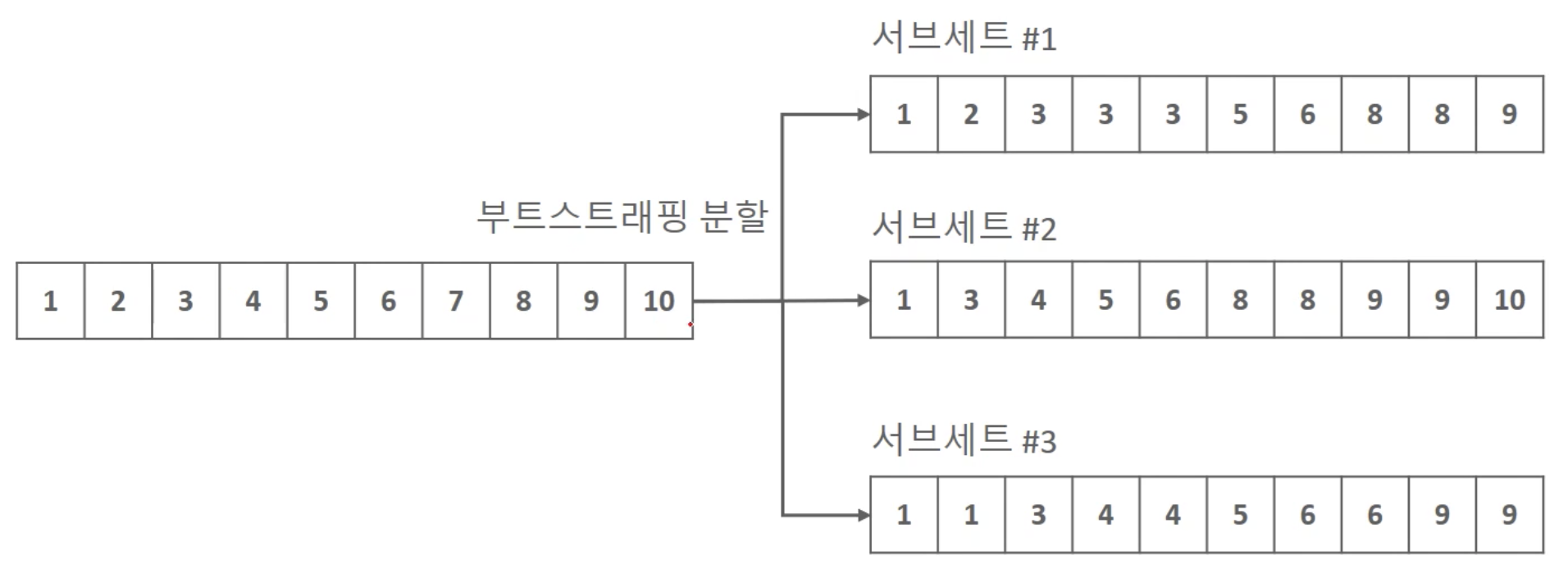
- Bagging = Bootstrap aggregating
부스팅
- 여러 개의 약한 학습기를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식
- 성능은 좋지만, 학습 시간이 너무 오래 걸림 (순차적으로 진행하기 때문)
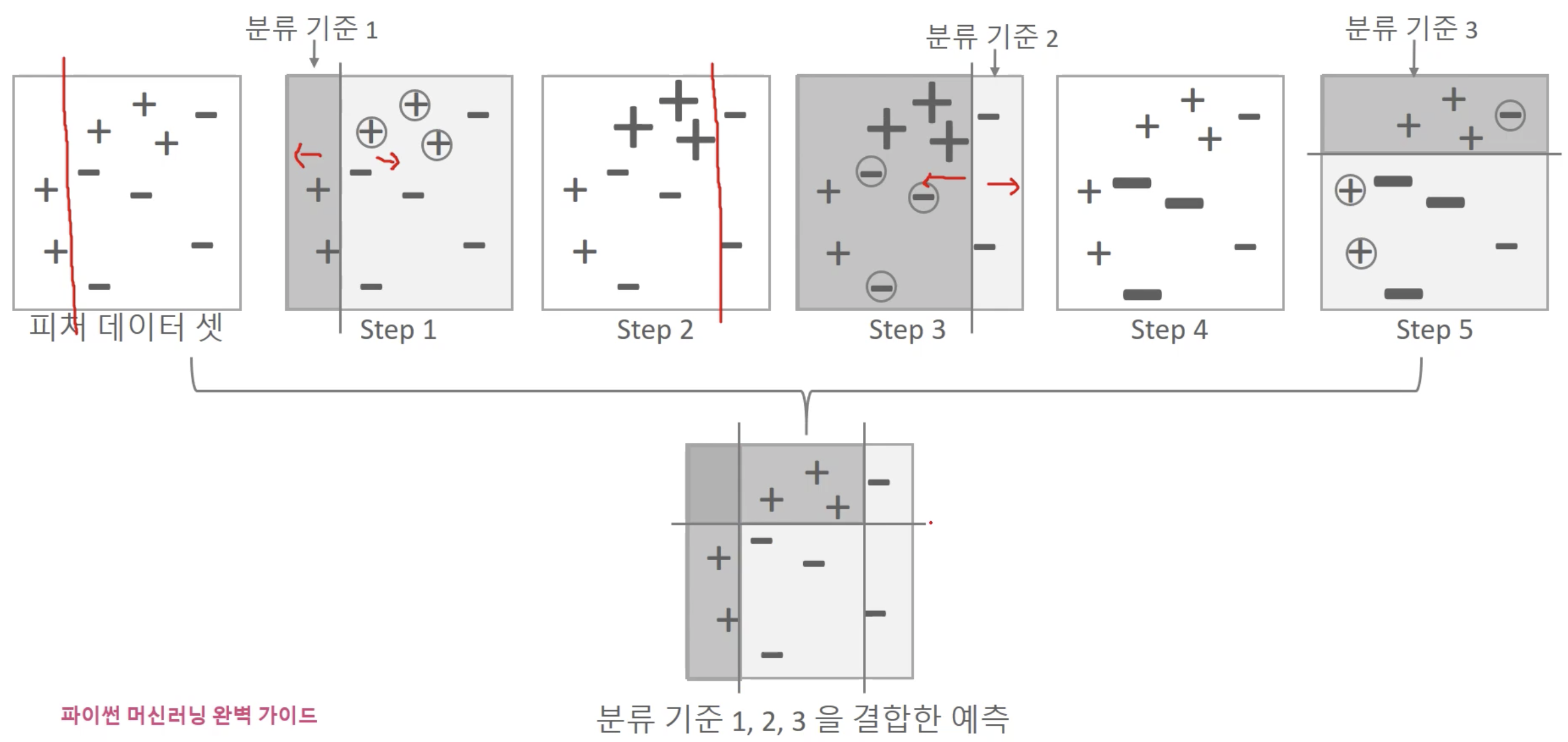
GBM
- Gradient Boost Machine
- 경사하강법을 이용하여 가중치를 업데이트
XGBoost
- eXtra Gradient Boost (극한 변화도(경사도) 부스팅)
- Gradient Boost 알고리즘을 병렬 학습이 지원되도록 구현한 라이브러리
- Regression, Classification 문제를 모두 지원
- 장점
- 뛰어난 예측 성능
- GBM 대비 빠른 수행 시간
- CPU 병렬 처리, GPU 지원
- 다양한 성능 향상 기능
- 규제 기능
- Tree Pruning
- 다양한 편의 기능
- Early Stopping
- 자체 내장된 교차 검증
- 결손값 자체 처리
LightGBM
- XGBoost 대비 빠른 학습, 예측 수행 시간, 더 적은 메모리 사용량
- 카테고리형 피처의 자동 변환과 최적 분할
트리 분할 방식 - 리프 중심
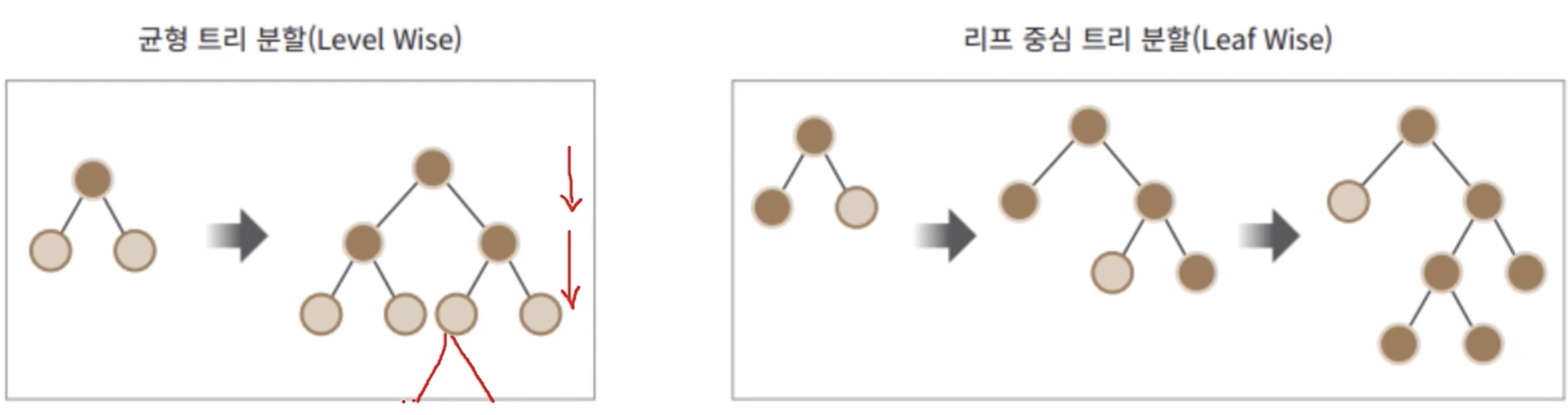
하이퍼 파라미터 튜닝
- 알고리즘이 좋다면, 하이퍼 파라미터 튜닝이 예측 결과를 크게 향상시키지는 않음
- 피처 엔지니어링을 좋게 하는 것이 오히려 결과가 좋은 경우가 많았음
피처 엔지니어링
Log 변환
- 왜곡된(Skewed) 분포도를 가진 데이터를 정규 분포에 가깝게 변환해줄 수 있음
IQR
- Inter Quantile Range
- 4분위 수를 가지고 이상치를 제거하는 방법
- 이상치 판별 기준
- Value > Q3 + 1.5 * (Q3-Q1)
- Value < Q1 - 1.5 * (Q3-Q1)

언더 샘플링, 오버 샘플링
- 레이블이 불균형한 분포를 가진 데이터를 학습 시, 이상 레이블을 가지는 데이터 건수가 너무 적어서 학습이 어려움
- 또한 정상 레이블 건수만 많기에 치우친 학습을 하게됨

SMOTE
- Synthetic Minority Over-Sampling Technique

스태킹
기반 모델들이 예측한 값들을 Stacking 형태로 만들어서 메타 모델이 이를 학습하고 예측하는 모델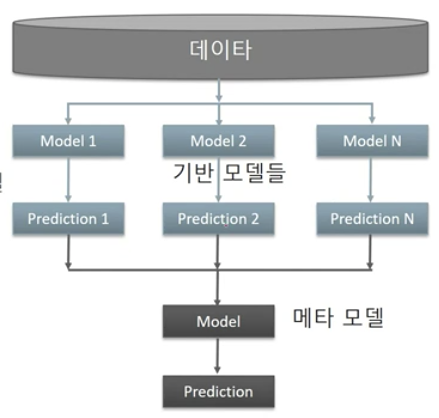

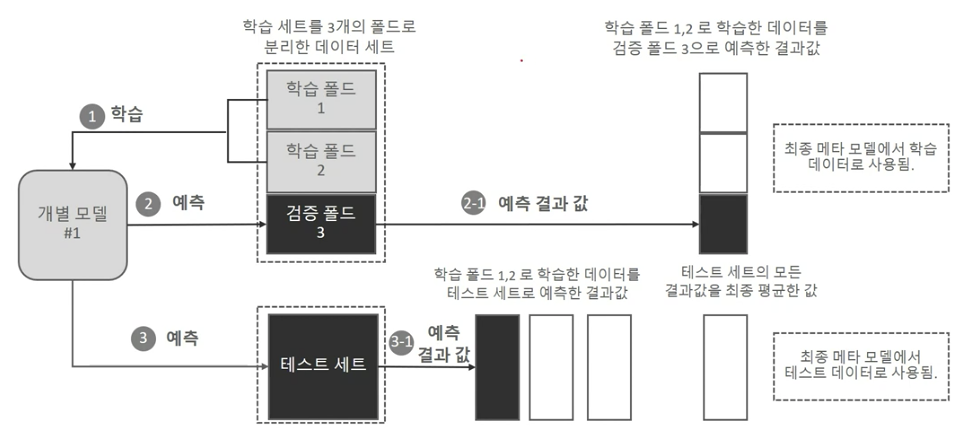
교차 검증 세트 기반의 스태킹
- 과적합을 개선하기 위해 최종 메타 모델을 위한 데이터 세트를 만들 때 사용
- 수행
- Step1: 각 모델별로 원본 학습/테스트 데이터를 예측한 결과 값을 기반으로 메타 모델을 위한 학습/테스트 데이터를 생성
- Step2: Step1에서 개별 모델들이 생성한 학습/테스트용 데이터를 모두 스태킹 형태로 합쳐서 메타 모델이 학습할 최종 학습/테스트 데이터를 생성. 메타 모델은 최종 학습 데이터 기반으로 학습한 후, 최종 테스트 데이터를 예측하고 원본 테스트 데이터의 레이블 데이터를 기반으로 평가함
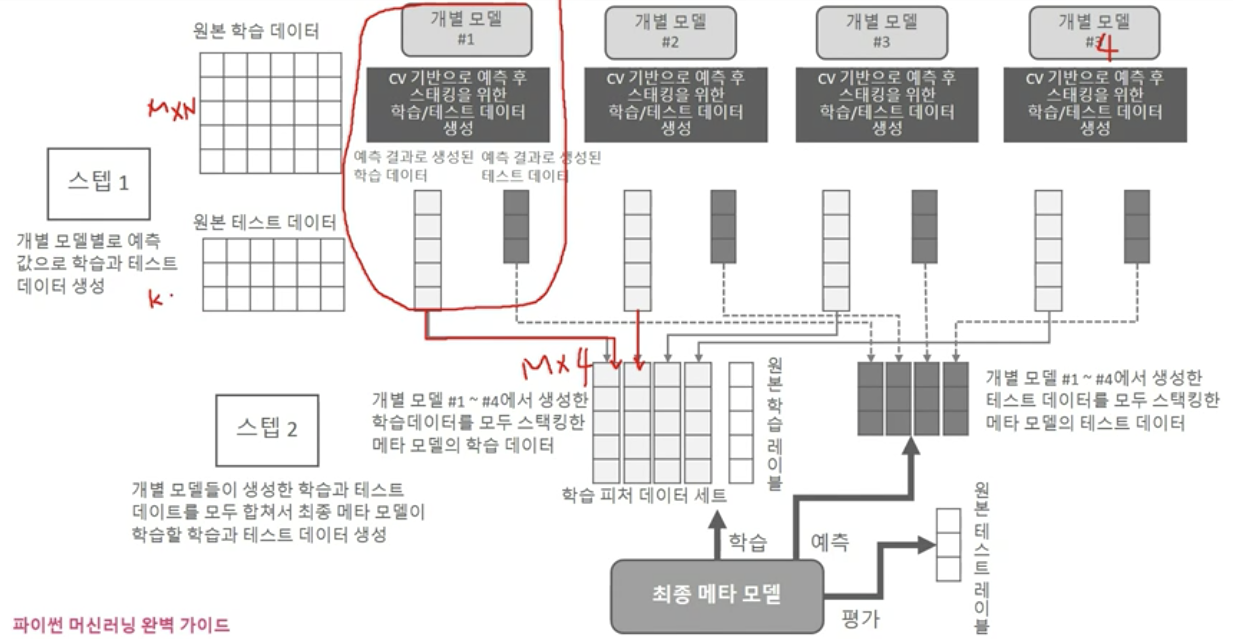
개별 모델 스태킹 모델 만들기
최종 스태킹 모델
Feature Selection
- 모델을 구성하는 주요 피처들을 선택
- 불필요한 다수의 피처들로 인한 모델 성능 저하 방지
- 설명 가능한 모델이 될 수 있도록 피처 선별
- 피처값의 분포, Null, 피처간의 높은 상관도, 결정값과의 독립성 등을 고려
사이킷런 모듈
- RFE (Recursive Feature Elimination)
- 모델 최초 학습 후, 피처 중요도 선정
- 피처 중요도가 낮은 속성들을 차례로 제거해가면서 반복적으로 학습/평가를 수행하여 최적의 피처 추출
- 수행시간이 오래걸리고, 낮은 속성들을 제거해 나가는 메커니즘이 정확한 피처 선정을 하는 목표에 부합하지 않을 수 있음
- SelectFromModel
- 모델 최초 학습 후, 선정된 피처 중요도에 따라 평균/중앙값의 특정 비율 이상인 피저들을 선택
Permutation importance
- 특정 피처들의 값을 완전히 변조했을 떄, 모델 성능이 얼마나 저하되는지를 기준으로 해당 피처의 중요도를 산정
- 학습 데이터를 제거하거나 변조하면 재학습을 해야되므로 수행 시간이 오래 걸림
- 일반적으로 테스트 데이터에 특정 피처들을 반복적으로 변조한 뒤 해당 피처의 중요도를 평균적으로 산정함

feature importance가 feature selection의 절대적인 기준이 될 수 없는 이유
- Feature importance는 최적 tree 구조를 만들기 위한 피처들의 불순도가 중요, 결정 값과 관련이 없어도 피처 중요도가 높아질 수 있음
- Feature importance는 학습 데이터를 기반으로 생성되기에 테스트 데이터에서는 달라질 수 있음
- Feature importance는 number형의 높은 cardinality feature에 편향되어 있음
참고

Data Scientist, Data Analyst