David Silver 교수님의 RL Course 강의 내용 정리
Lecture 1: Introduction to Reinforcement Learning
Machine Learning paradigms
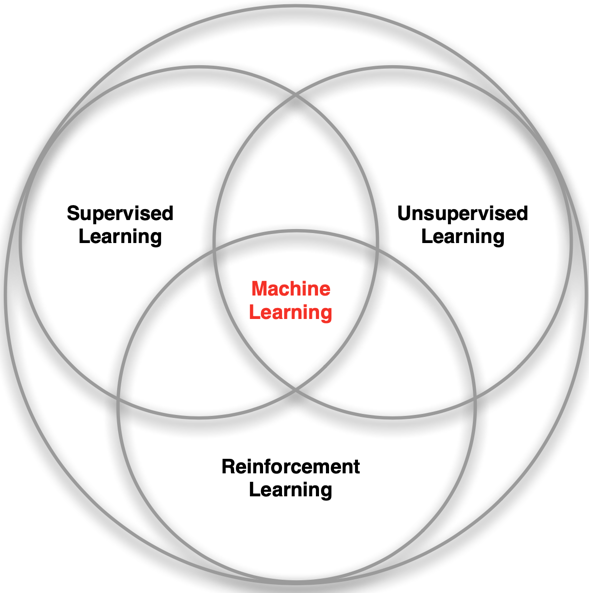
Difference between 'RL' and 'SL, UL'
- No supervisor, only a reward signal
- Feedback is delayed by many steps
- Time really matters (Sequential and non-iid data)
- Agent's actions affect the subsequent data
Example of RL
- Fly stunt manoeuvres in a helicopter
- Defeat the world champion at Backgammon Manage an investment portfolio
- Control a power station
- Make a humanoid robot walk
- Play many different Atari games better than humans
Rewards
- , Scalar feedback signal
- 값 하나 (= 숫자)
- 비교 가능
- Example: Make a humanoid robot walk
- +ve reward for forward motion
- −ve reward for falling over
Reward Hypothesis
Maximization of expected cumulative reward
--> 누적 보상 최대화
Sequential Decision Making
- Goal: select actions to maximize total future reward
- Actions may have long term consequences
- Reward may be delayed
- It may be better to sacrifice immediate reward to gain more long-term reward
- greedy한 결과보다 장기적인 결과가 중요 (ex. 마시멜로 이야기)
- Examples:
- A financial investment (may take months to mature)
Agent, Environment
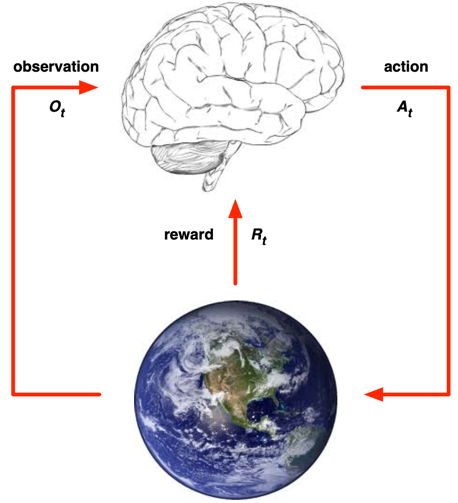
- At each step t
- agent:
- 행동 실행()
- 행동의 결과를 받음()
- Scala 보상을 받음()
- environment:
- 행동을 받음()
- 행동에 따른 다음 스텝의 모습을 보내줌()
- 다음 스텝의 보상을 보내줌()
- agent:
History, State
- history: t까지의 연속적인 관측, 행동, 보상의 sequence
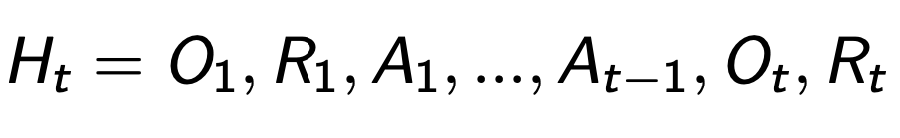
- state: 다음에 어떤 것을 할 것인지 결정하는데 사용하는 정보
- state는 history의 function
Environment State
- 다음 관측/보상을 주기 위해 사용하는 데이터
- ex. 아래 그림에서 게임기 안의 정보
- ex. 주식을 모바일로 매매할 때, 미래에셋 mstock앱의 내부 정보
- agent에게 보통 보이지 않음
- 만약 보인다면, 불필요한 정보까지 포함할 수 있음
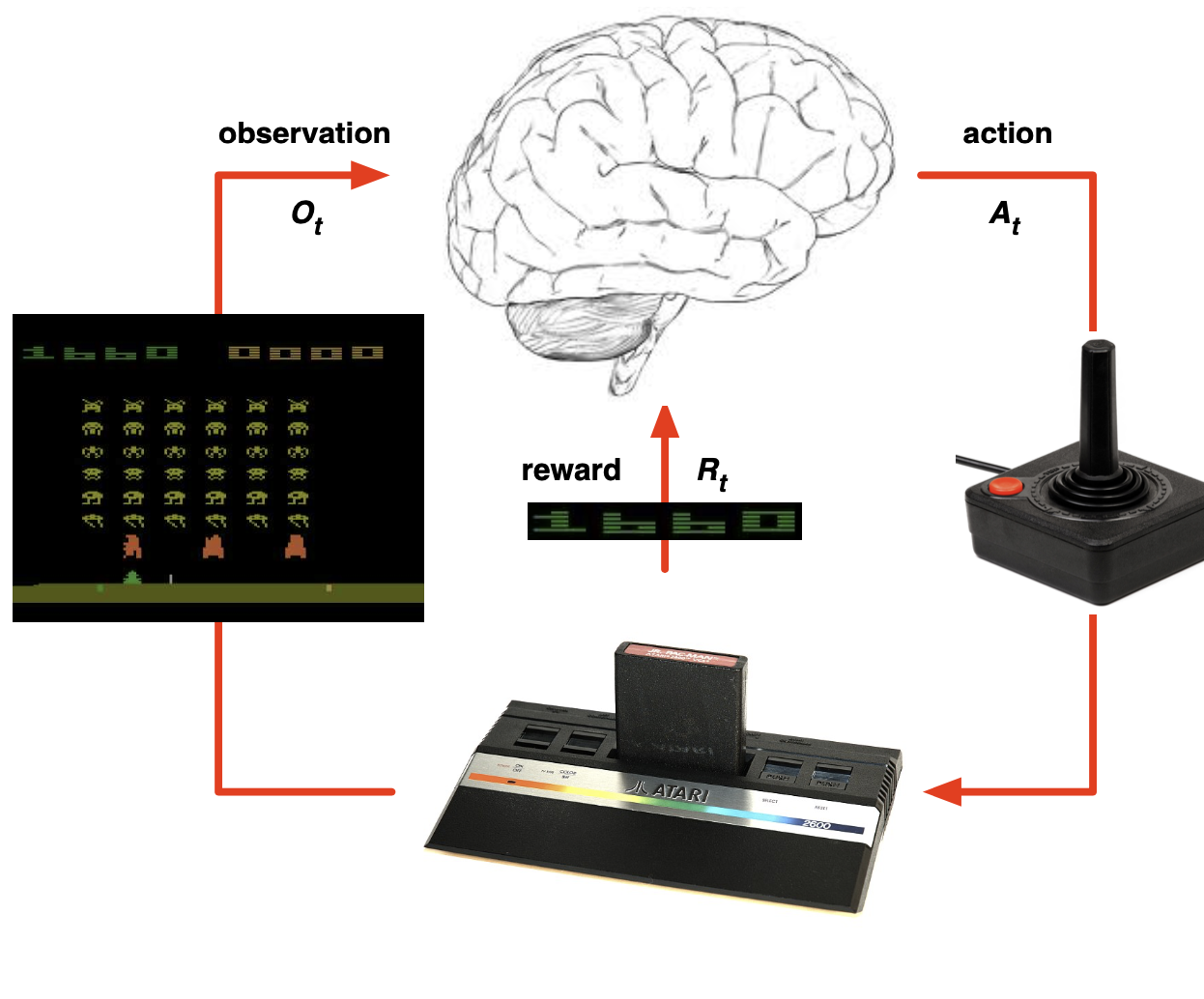
- 만약 보인다면, 불필요한 정보까지 포함할 수 있음
Agent State
- 내가 다음 행동을 하기 위해 쓰이는 정보
- ex. 주식을 매매 할 때 사용하는 정보 (영업이익률, 당기순이익, PER, PBR...)
- 참고 정보라고 생각하면 됨
Information State
- 과거 history의 모든 유용한 정보를 포함하고 있음
- Markov하다: 바로 직전 tick의 결과만 관련이 있다.
- 이전 tick의 state는 관련이 없음
- 참고
- environment state는 Markov
- history 도 Markov

Full observability Environments
- agent directly observes environment state
- Markov decision process (MDP)라고 불림
Partial observability Environments
- agent indirectly observes environment
- Now agent state != environment state
- partially observable Markov decision process (POMDP)라고 불림
- Agent는 state 표현형을 구축해야함
- State를 history, RNN과 같이 여러가지로 표현할 수 있다.
RL Agent
Component
- Policy: agent의 행동 함수
- Value function: how good is each state and/or action
- Model: agent의 대표 환경
Policy
- policy: agent의 행동
- state를 넣으면 행동을 알려줌
- 종류
- Deterministic Policy: State를 알려주면 행동을 결정해서 알려줌
- Stochastic Policy: State를 알려주면 각 행동별 확률을 알려줌
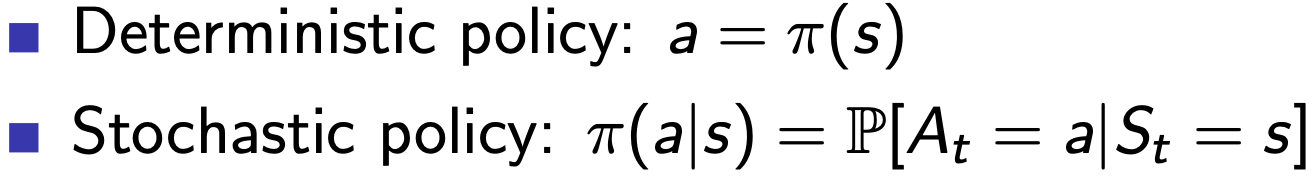
Value function
- 미래 보상들의 기댓값
- 현재 state가 좋은지 안좋은지 평가하는데 사용
- policy가 정해져야 됨
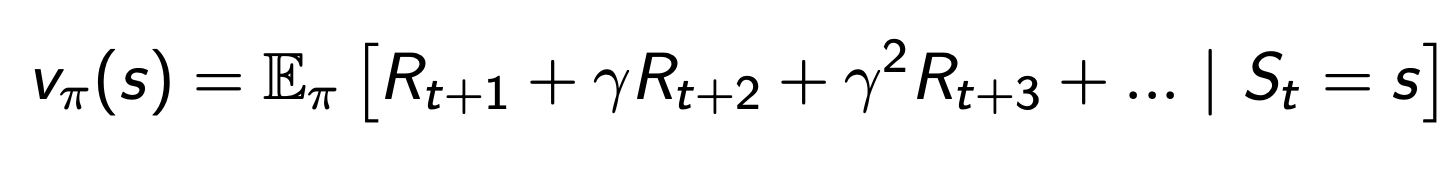
Model
- 환경이 다음에 무엇을 할 것인지 예측
- 다음 상태를 예측
- 다음 보상을 예측
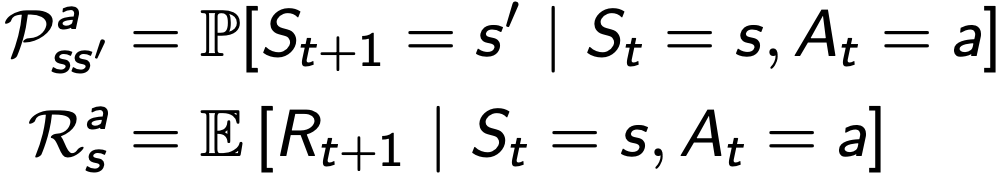
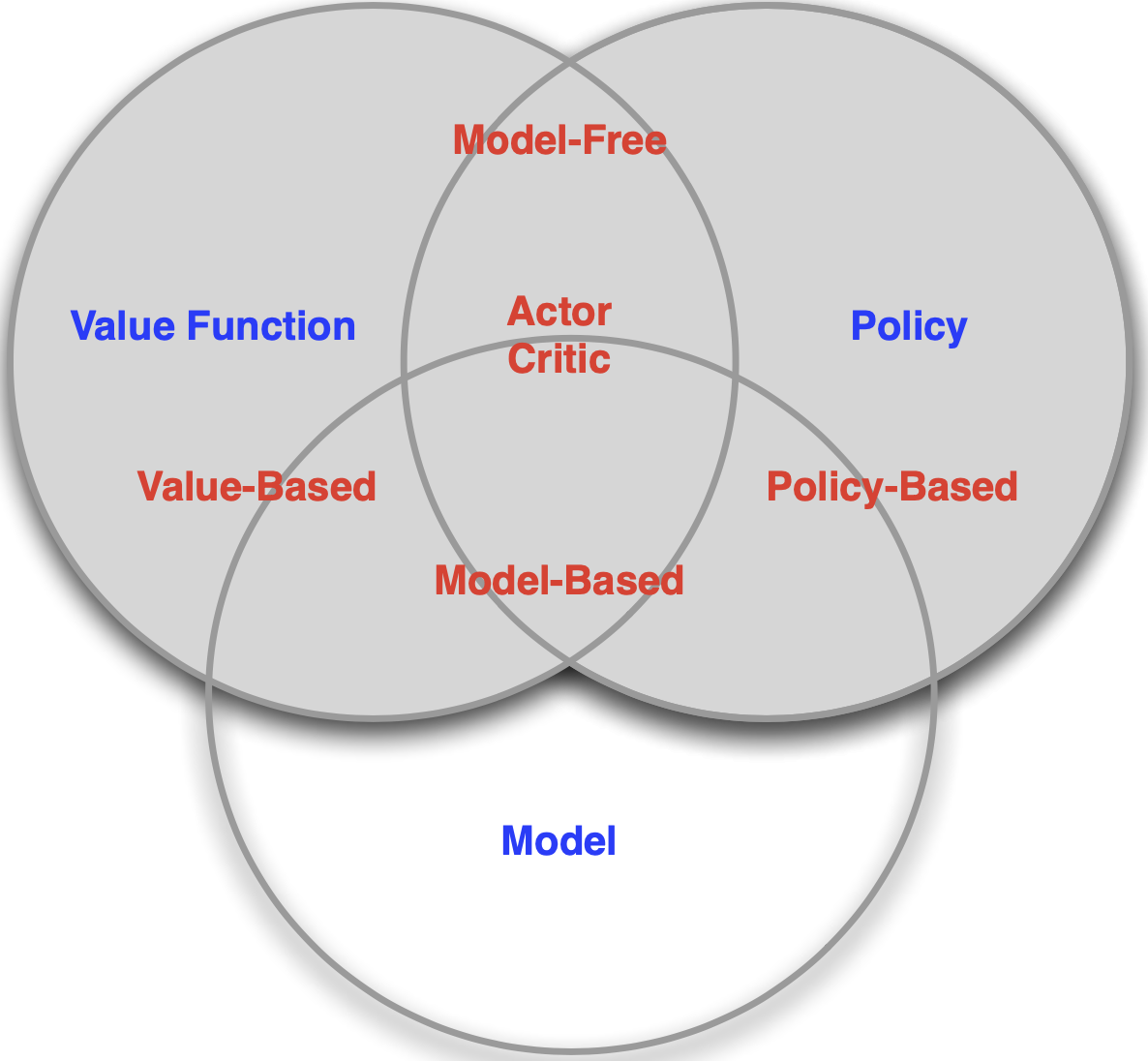
Categorize
- Value Based (value function)
- Policy Based (policy)
- Actor Critic (policy + value function)
- Model Free (policy and/or value function)
- Model Based (policy and/or value function + Model)
Learning, Planning
- Reinforcement Learning
- environment를 모름
- agent는 환경과 상호작용을 하면서 정책을 개선시킴
- trial-and-error learning
- ex. 보물찾기를 할 때, 보물 위치를 모르고 현재 위치도 모르기 때문에, 이리로 저리로 다 가보면서 확인해야됨 (= 지도와 나침반이 없는 것)
- Planning
- environment를 알고 있음
- reward, state 뭘 받을 것인지 아는 것
- 실제로 환경에서 무엇을 안해도, 내부적으로 계산해서 값을 알 수 있음
- ex. 몬테카를로 서치
- ex. 보물찾기를 할 때, 보물 위치와 현재 위치를 알기 때문에, 계획을 세워서 행동해볼 수 있음 (= 지도와 나침반이 있는 것)
- environment를 알고 있음
Exploration, Exploitation
- exploration: 환경에 대한 더 많은 정보를 찾는 것
- exploitation: 모은 정보를 바탕으로 보상을 최대화하는 것
- exploration, exploitation: trade off 관계
- 예시 (식당 선택)
- exploration: 새로운 식당에 도전해보는 것
- exploitation: 내가 좋아하는 식당에 가는 것
Prediction, Control
- prediction: 미래를 평가하는 것
- given a policy
- value function을 학습시키는 것
- control: 미래를 최적화하는 것
- find the best policy

Data Scientist, Data Analyst