오렐리앙 제롱, 『Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow』, 박해선, 한빛미디어-OREILLY(2020), p127-156.
Learned
확률적 경사 하강법 (Stochastic Gradient Descent; SGD)
- 매우 큰 데이터셋을 효율적으로 처리하는 장점
- 한 번에 하나씩 훈련 샘플을 독립적으로 처리하기 때문
- 온라인 학습에 잘 맞음
- 결정 함수를 사용하여 각 샘플의 점수를 계산
- 점수가 임곗값보다 크면 샘플을 양성 클래스에 할당, 작으면 음성 클래스에 할당
- 임곗값 = 결정 임곗값 (decision threshold)
분류기 성능 측정 지표
- 불균형한 데이터셋을 다룰 때, 특히 정확도를 선호하지 않음
- 재현율 (recall)
- 분류기가 정확하게 감지한 양성 샘플의 비율
- 민감도 (sensitivity) or 진짜 양성 비율 (True Positive Rate; TPR)로 불림
- F 점수
- > 1 : 재현율 강조
- < 1 : 정밀도 강조
- = 1 : score
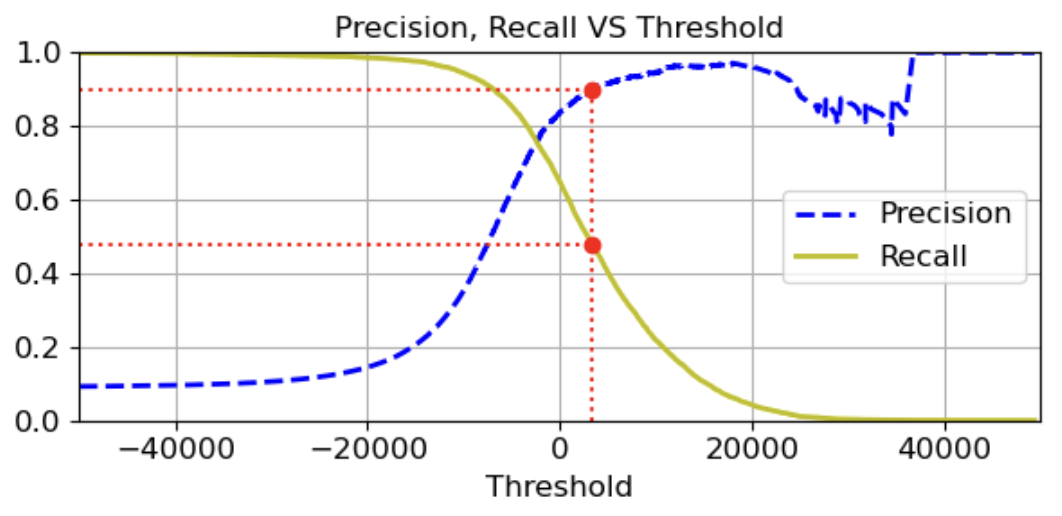
좋은 정밀도/재현율 trade-off를 선택하는 방법
- 임곗값에 따른 정밀도, 재현율 값이 교차하는 지점
- 임곗값이 높을수록 재현율은 낮아지고, 반대로 보통 정밀도는 높아짐
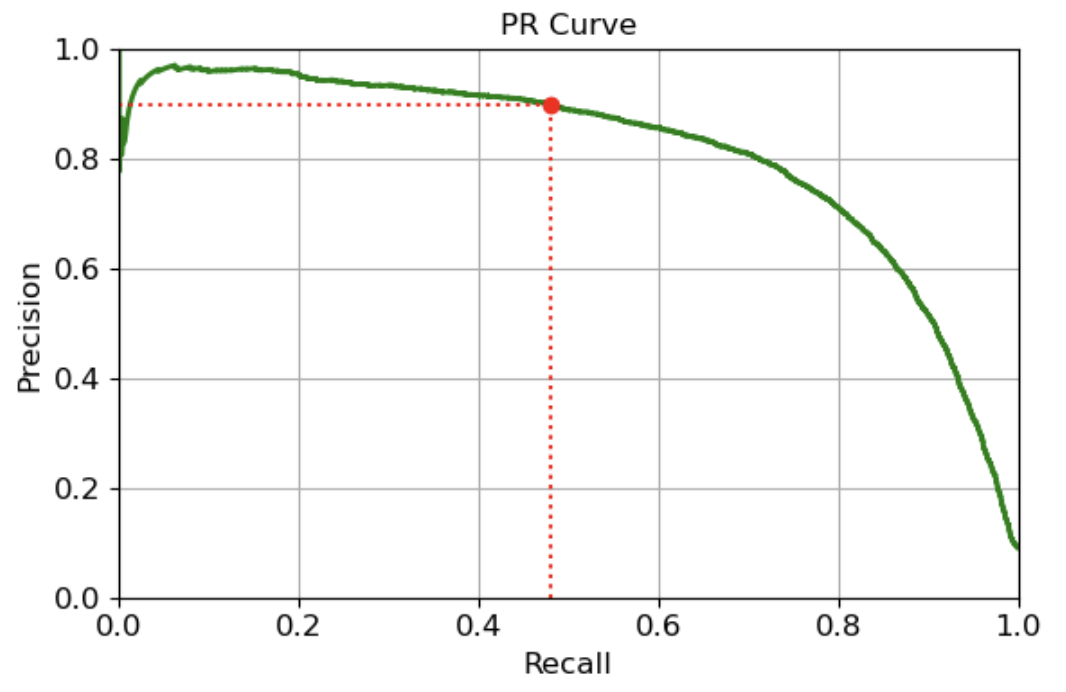
- 정밀도/재현율(PR) 곡선
- 정밀도가 급격하게 하강하는 직전 point를 정밀도/재현율 트레이드 오프로 선택하는 것이 좋음
- 양성 클래스가 드물거나, 거짓 음성보다 거짓 양성이 중요할 때 사용
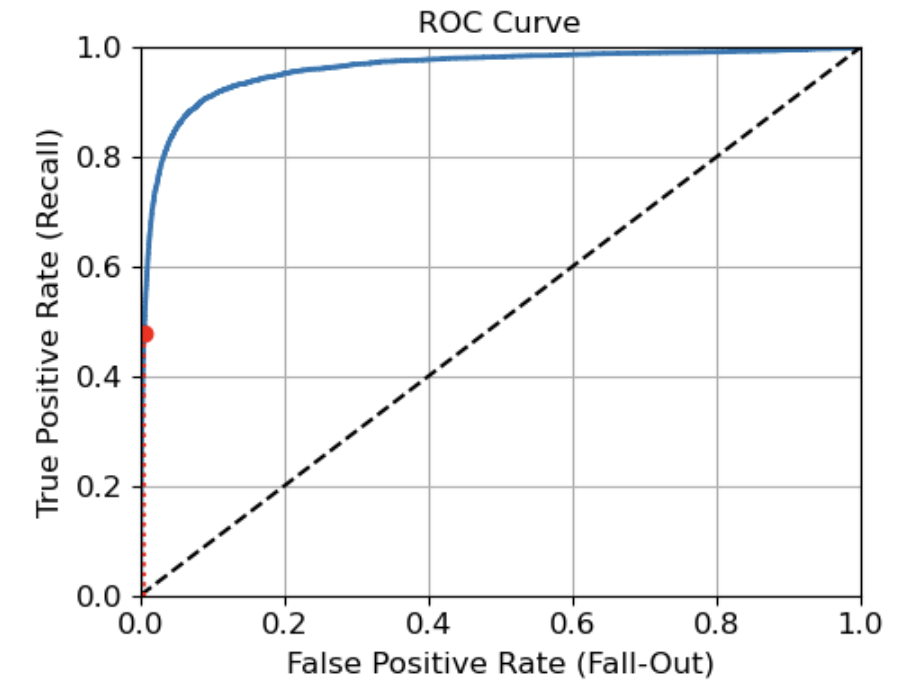
- 수신기 조작 특성 곡선 (Receiver Operating Characteristic Curve; ROC Curve)
- 거짓 양성 비율(FPR)에 대한 진짜 양성 비율(TPR)의 곡선
- FPR = 1 - TNR
- TNR: 진짜 음성 비율, 특이도(specificity)라고 불림
- 민감도에 대한 1-특이도 그래프
- 재현율(TPR)이 높을수록 거짓 양성 비율(FPR)이 늘어남 -> trade-off
- AUC(Area Under the Curve)를 측정하면 분류기들을 비교 가능
- 완벽한 분류기 -> ROC의 AUC = 1
- 완전한 랜덤 분류기 -> ROC의 AUC = 0.5
- 거짓 음성이 거짓 양성보다 중요할 때 사용
- 거짓 양성 비율(FPR)에 대한 진짜 양성 비율(TPR)의 곡선
OvR, OvO
- OvR(One versus the Rest): 각 분류기의 결정 점수 중에서 가장 높은 것을 클래스로 선택
- 대부분의 이진 분류 알고리즘에서는 OvR을 선호
- OvO(One versus One): 각 클래스의 조합마다 이진 분류기를 훈련시키는 것
- 클래스가 개 라면 분류기는 개 필요
- 각 분류기의 훈련에 전체 훈련 세트 중에서 구별할 두 클래스에 해당되는 샘플만 필요한 장점이 있음
- SVM과 같은 훈련 세트의 크기에 민감한 알고리즘은 작은 훈련 세트에서 많은 분류기를 훈련시키는 쪽이 빠름
에러 종류 분석
- 모델 성능을 향상시키는 방법
- 분류기의 성능 향상 방안에 대한 통찰을 얻을 수 있음
- 훈련 데이터를 더 모아서 분류기를 학습
- 분류기에 도움 될 만한 특성을 찾아보기
- 분류기의 성능 향상 방안에 대한 통찰을 얻을 수 있음
matplotlib의matshow()함수활용하여 오차 행렬을 시각화
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)- 오차 행렬의 값을 대응되는 클래스 개수로 나누어 에러 비율을 비교
- 에러의 절대 개수로 비교하면 데이터가 많은 클래스가 상대적으로 나쁘게 보임
분류 종류
- 이진 분류기(binary classifier): 두 개의 클래스를 구별
- 다중 분류기(multiclass classifier): 둘 이상의 클래스를 구별
- 다항 분류기(multinomial classifier)로도 불림
- 다중 레이블 분류(multilable classification): 여러 개의 이진 꼬리표를 출력하는 분류 시스템
- ex. 출력 값이 2가지 (짝수 여부, 5이상 여부)
- 다중 출력 분류(multioutput classification): 다중 레이블 분류에서 한 레이블이 다중 클래스가 될 수 있도록 일반화한 것
- 다중 출력 다중 클래스 분류(multioutput-multiclass classification)로 불림
Question
- 정밀도, 재현율이 각각 중요할 때의 사례
- 재현율이 중요: 실제 Positive 데이터를 Negative로 판단하면(FN) 큰 영향이 발생하는 case
- ex. 암 진단, 금융사기 판별
- 정밀도가 중요: 실제 Negative 데이터를 Positive로 판단하면(FP) 큰 영향이 발생하는 case
- ex. 스팸 메일 -> 중요한 메일을 스팸으로 분류
- 재현율이 중요: 실제 Positive 데이터를 Negative로 판단하면(FN) 큰 영향이 발생하는 case
Reference

Data Scientist, Data Analyst