출처: Natural Language Processing with Transformers by Lewis Tunstall, Leandro von Werra, and Thomas Wolf (O’Reilly). Copyright 2022 Lewis Tunstall, Leandro von Werra, and Thomas Wolf
Transformer
- The encoder-decoder framework
- Attention mechanisms
- Transfer learning
The Encoder-Decoder Framework
Recurrent architectures
- ex. LSTM, RNN
- NLP tasks, speech preprocessing, time seires에 사용됨
- 정보가 한 단계에서 다른 단계로 전파되도록 하는 네트워크 연결에 feedback loop가 포함되어있음
- RNN은 각 step의 상태에 대한 정보를 시퀀스의 다음 작업으로 전달
- 이전 step으로부터 정보를 계속 추적하게 해줌
- output 예측에 사용
Encoder-Decoder or Sequence-to-Sequence architecture
- input과 output이 모두 임의 길이의 시퀀스인 상황에 적합
- encoder: input 시퀀스의 정보를 last hidden state라고 하는 numerical 표현으로 인코딩하는 것
- 이 상태는 output 시퀀스를 생성하는 decoder로 전달됨
- Ex. “Transformer는 최고다"
→ encoder block(hidden state) → decoder block(hidden state)
→ “Transformer is great”- input 단어들은 encoder를 통해 순차적으로 공급됨 (Transformer는 / 최고다)
- output 단어들은 위에서 아래로 한 번에 하나씩 생성됨 (Transformer/ is / great)
- 장/단점:
- 장점: simplicity
- 단점: encoder의 final hidden state가 정보 병목현상을 발생시킴
- 전체 input sequence를 표현하기 때문
- 특히 긴 문장에서 어려움 → 고정된 표현으로 압축하면서 정보의 손실이 발생 가능
- “Attention” mechanism으로 해결 가능
Attention Mechanisms
- input sequence에 대해 단일 hidden state를 생성하는 대신,
encoder가 각 step에서 decoder가 접근할 수 있는 hidden state를 출력함 - 동시에 모든 state를 사용하는 것은 decoder에게 큰 input을 전달함
→ 사용할 state의 우선 순위를 지정하는 메커니즘이 필요 - decoder가 모든 decoding timestamp에서 각각의 encoder 상태에
다른 양의 가중치 또는 attention을 할당할 수 있음 - 장/단점
- 장점: 좋은 성능의 번역을 할 수 있음
- 단점: 계산이 본질적으로 순차적이고 input 시퀀스에서 병렬화할 수 없음
- Transformer (new modeling)
- 되풀이를 방지
- self-attention 형식에 의존
- self-attention: attention이 신경망의 동일한 레이어에 있는 모든 status에서 작동하도록 허용
- encoder, decoder 각각 self-attention 메커니즘을 갖고 있음
- output은 FF 신경망에 공급됨
- recurrent 모델보다 빠르게 훈련할 수 있음
Transfer Learning
Original task로부터 배운 지식을 신경망에 사용할 수 있음
Supervised learning보다 적을 데이터로 효율적이고 high-quality 모델을 생산할 수 있음
Computer vision 분야에서는 표준이 되어있음
Model을 body와 head로 분리
- body: 가중치는 source domain의 광범위한 feature를 학습하고 새로운 모델을 초기화 하는데 사용됨
- head: task-specific network
Example
- large-scale datasets로 학습 (pretraining) → 데이터의 기본 특징을 학습시키는 것이 목적 (ex. edges or colors in image)
- 사전 학습된 모델을 fine-tuned
- fine-tuned 모델은 일반적으로 같은 양의 라벨 데이터 기준, supervised 모델보다 높은 성능을 보임
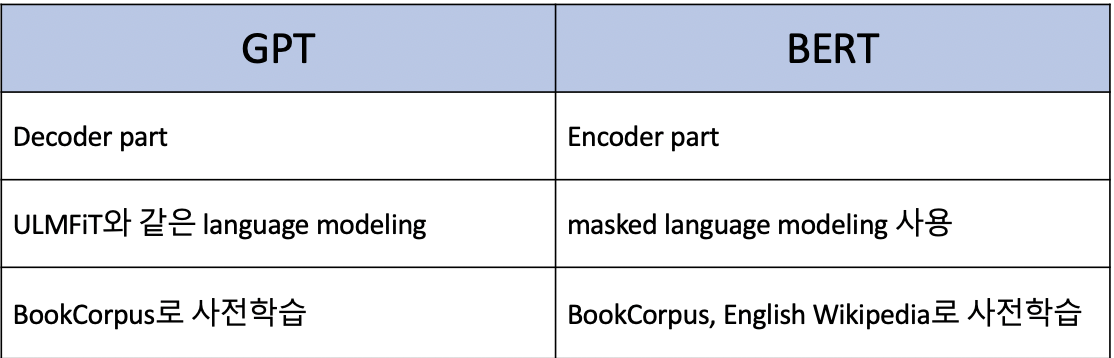
ULMFiT
- pretrained LSTM 모델을 다양한 작업에 적용
- Process
- pretraining
- objective: 이전 단어들을 기반으로 다음 등장 단어 예측 (language modeling)
- 라벨 데이터가 불필요함
- 위키피디아와 같은 large-scale corpus를 사용
- domain adaptation
- 사전 훈련된 모델에 in-domain corpus를 적용
- ex. wikipedia → IMDb corpus (movie review)
- fine-tuning
- classification layer 부착
- pretraining
Self-attention과 전이 학습을 결합한 transformers
Hugging Face
Transformers
최신 ml architecture를 사용하는 것은 복잡하고 어려움
→ Hugging Face의 표준화된 인터페이스로 단순화 (DL framework도 쉽게 switch 가능)
Application
- text classification (sentiment analysis)
- name entity recognition (ner)
- question answering
- summarization
- translation
- text generation
Ecosystem
Family of Library, Hub로 구성됨
- Family of Library: code 제공
- Hub: pretrained model, weights, datasets, 평가 지표 scripts 등 제공
Main Challenges with Transformers
- Language: 희귀 or 적은 resource 언어는 사전 훈련 모델을 찾기 어려움
- Data availability: 인간이 작업을 수행하기 위해 필요한 정보 대비 많음
- Working with long documents: Paragraph 단위는 잘 처리하지만, 전체 문서를 처리하기에는 힘듦
- Opacity: 특정 예측에 대한 이유를 밝히는 것이 어려움
- Bias: 주로 인터넷 텍스트 데이터를 사용하기 때문에, 데이터에 존재하는 편향이 모두 반영됨
- ex. 욕설, 인종차별, 성차별 text 등

Data Scientist, Data Analyst