출처: Natural Language Processing with Transformers by Lewis Tunstall, Leandro von Werra, and Thomas Wolf (O’Reilly). Copyright 2022 Lewis Tunstall, Leandro von Werra, and Thomas Wolf
Dataset
- Hugginface Dataset → Apache Arrow 기반
⇒ Apache Arrow?? (columnar database) - Data Load
- csv의 경우 sep 파라미터로 구분자를 지정할 수 있음
- ex.load_dataset("csv", data_files="test.txt", sep=";")

Class Distribution
해결 방식
• Randomly oversample the minority class.
• Randomly undersample the majority class.
• Gather more labeled data from the underrepresented classes.
Tokenization
Character Tokenization
- Character level tokenization
text = "nice to meet you"
tokenized_text = list(text) # ['n', 'i', 'c', 'e', ' ', 't', 'o', ' ', 'm', 'e', 'e', 't', ' ', 'y', 'o', 'u']- numericalization
- mapping from each character in our vocabulary to a unique integer
token2idx = {ch: idx for idx, ch in enumerate(sorted(set(tokenized_text)))}
print(token2idx) # {' ': 0, 'c': 1, 'e': 2, 'i': 3, 'm': 4, 'n': 5, 'o': 6, 't': 7, 'u': 8, 'y': 9}
- token2idx: transform tokenized text to a list of integers
input_ids = [token2idx[token] for token in tokenized_text]
print(input_ids) # [5, 3, 1, 2, 0, 7, 6, 0, 4, 2, 2, 7, 0, 9, 6, 8]- one-hot encoding
df = pd.DataFrame({'station': ['청담역', '강남구청역', '건대입구역'], 'label': [0,1,2]})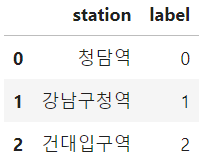
pd.get_dummies(df['station'])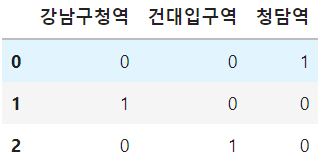
- 특징
- character-level tokenization은 text의 구조를 무시함
- 전체 문자열을 문자 형태로 고려함
- 장점
- 오타, 드물게 사용되는 단어를 처리할 때 유용
- 단점
- 데이터로부터 학습되어야하는 언어적인 구조를 파괴함
- 상당한 계산량, 메모리, 데이터가 필요함
-> 위와 같은 이유로 실제로 잘 사용되지 않음
Word Tokenization
- 가장 단순한 방법: 공백(whitespace)을 기준으로 tokenize =>
text.split() - stemming or lemmatization: 단어의 원형으로 표준화하는 작업
ex. "great", "greater", "greatest" -> "great"- 장점: 사전의 크기를 줄일 수 있음
- 단점: 텍스트에서의 정보를 잃을 수 있음
- 단어 수를 제한하고 드물게 사용되는 단어를 제거하는 방법이 흔하게 사용됨 (=빈도 수 기반 사전 단어 수 제한)
Subword Tokenization
- character tokenization과 word tokenization의 좋은 측면들을 결합한 방식
- 희귀 단어를 작은 단위로 분할하고 싶음 -> 복잡한 단어들과 오타를 모델이 처리할 수 있음
- 자주 사용하는 단어를 단일 개체로 인식하고 싶음 -> 입력 길이를 관리가능한 크기로 유지
- 통계적 규칙과 알고리즘을 혼합한 사전 학습된 corpus를 사용
- Ex. WordPiece (BERT, DistilBERT tokenizer에서 사용)
- BPE(Byte Pair Encoding)의 변형 알고리즘
- 병합했을 때 말뭉치의 우도(likelihood)를 가장 높이는 쌍을 병합
- transformers "AutoTokenizer"
from transformers import AutoTokenizer
model_ckpt = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)- Text encoding
- input_ids: tokenizing 후, token별 index로 변환된 값 (padding 작업이 존재할 경우, 0이나 특정값이 가장 긴 크기의 batch - 내 토큰 수 만큼 추가됨)
- attention_mask: padding으로 추가된 값을 모델이 혼동하지 않기 위한 값 (padding으로 추가된 값은 0, 실제 토큰은 1로 표기함)
text = "Tokenizing text is a task of nlp"
encoded_text = tokenizer(text)
# {'input_ids': [101, 19204, 6026, 3793, 2003, 1037, 4708, 1997, 17953, 2361, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}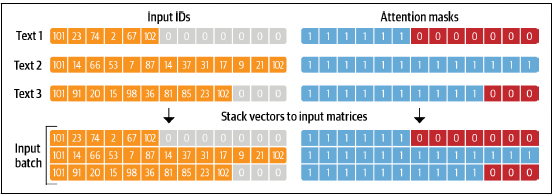
- Convert index to token
- [CLS], [SEP]: sequence의 시작과 끝을 의미 (모델마다 표기법은 다름)
- 토큰은 소문자로 변경되어 저장됨
- 희귀 단어는 토큰이 분리됨 (tokenizing, nlp)
- ##prefix(##izing, ##p)는 앞에 문자가 공백이 아님을 의미함
tokens = tokenizer.convert_ids_to_tokens(encoded_text.input_ids)
# ['[CLS]', 'token', '##izing', 'text', 'is', 'a', 'task', 'of', 'nl', '##p', '[SEP]']- Convert token to string
print(tokenizer.convert_tokens_to_string(tokens))
# [CLS] tokenizing text is a task of nlp [SEP]Reference

Data Scientist, Data Analyst