
설명
특정 패턴을 가지는 텍스트를 pandas DataFrame에서 정규표현식을 활용하여 추출하고 싶었다.
python의 re 라이브러리를 활용하지 않고 pandas 내부에서 작동하는 방법이 있을 것이라 생각했다.
Series.str.extract(pat, flags=0, expand=True)
- pat(str): Regular expression pattern with capturing groups.
- flags(int, default 0): Flags from the re module, e.g. re.IGNORECASE, that modify regular expression matching for things like case, spaces, etc. For more details, see re.
- expand(bool, default True): If True, return DataFrame with one column per capture group. If False, return a Series/Index if there is one capture group or DataFrame if there are multiple capture groups.
예시
아래 예시 데이터에서 2가지 작업을 위 방법을 활용해서 진행해보겠다.
1. '00보고서' text 추출
2. '2014.12'와 같은 yyyy.mm 형식 text 추출
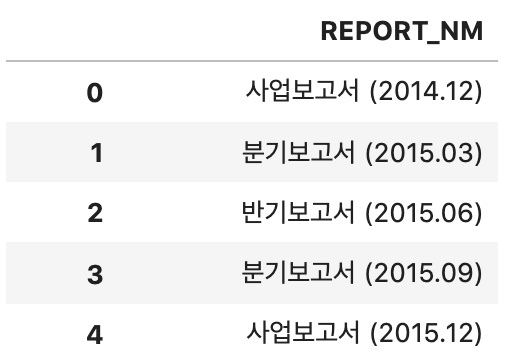
ex1
위에서 '00보고서'는 전부 한글로 표기가 되어있기 때문에 정규표현식 [가-힣]을 사용하면 모두 추출 할 수 있다.
ex_df['REPORT_TYPE'] = ex_df.REPORT_NM.str.extract(pat='([가-힣]+보고서)')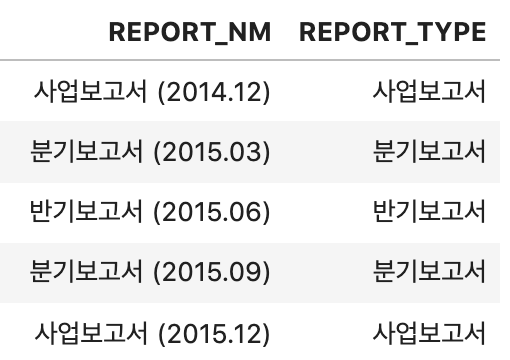
ex2
년월 형식은 연도(yyyy) + '.' + 월(mm) 형식으로 되어있기 때문에
[0-9]+.[0-9]+ 표현식으로 추출할 수 있다.
ex_df['REPORT_YM'] = ex_df.REPORT_NM.str.extract(pat='([0-9]+\.[0-9]+)')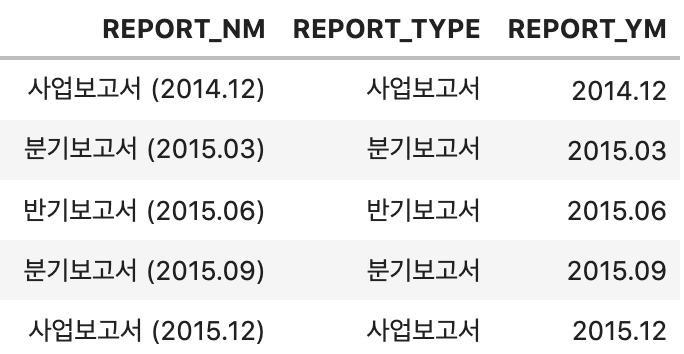
참고

Data Scientist, Data Analyst