출처: Natural Language Processing with Transformers by Lewis Tunstall, Leandro von Werra, and Thomas Wolf (O’Reilly). Copyright 2022 Lewis Tunstall, Leandro von Werra, and Thomas Wolf
Decoder
- 2개의 attention sublayer를 가지고 있음
- Masked multi-head self-attention layer
- Encoder-decoder attention layer
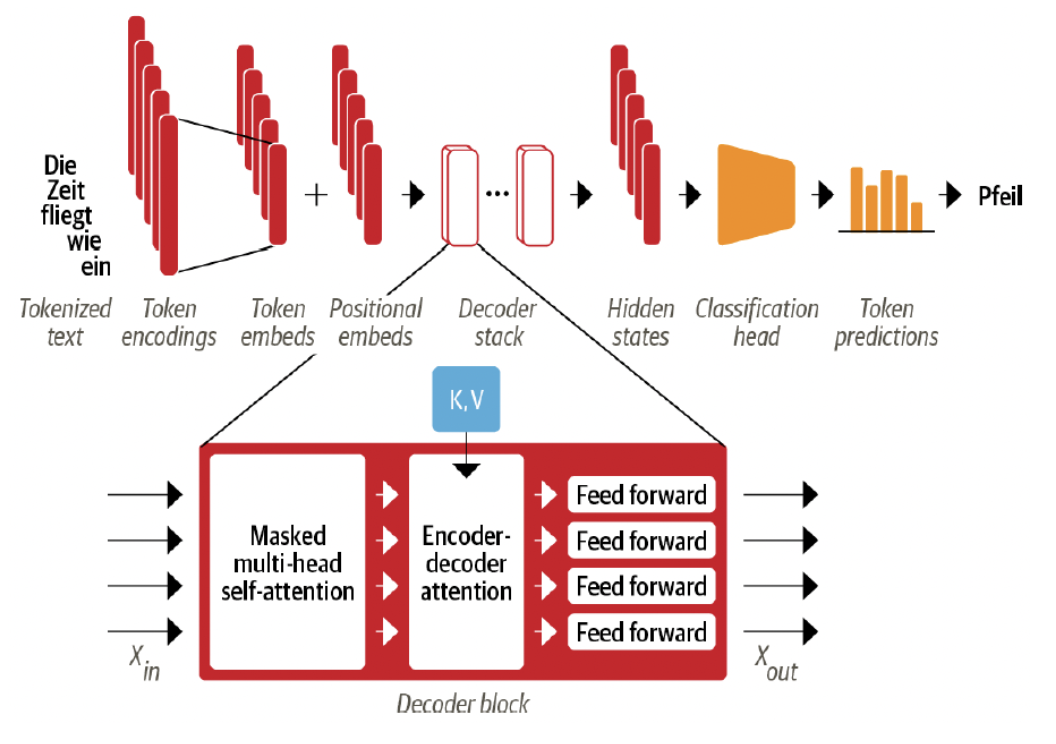
Masked multi-head self-attention layer
- 각 timestep에서 생성하는 token: 과거 출력 + 현재 예측중인 token
- 위 정의가 없으면, decoder는 단순히 target 번역을 복사하여 훈련중에 속임수를 쓸 수 있음
- 입력을 마스킹하면 작업이 어려움
- 마스킹:
Tensor.masked_fill()사용- 상한 값을 음의 무한대(−∞)로 설정
- score에 softmax를 적용하면 attention weights가 0이됨
Encoder-decoder attention layer
- decoder의 중간 표현이 query 역할을 하여 encoder stack의 key, value 출력값에 대해 multi-head attention을 수행함
- 두 개의 다른 sequence에서 token을 연결하는 방법을 배움 (ex. 다른 2가지 언어)
- decoder는 각 block 안에 있는 encoder의 key, value에 접근할 수 있음
Transformers 종류
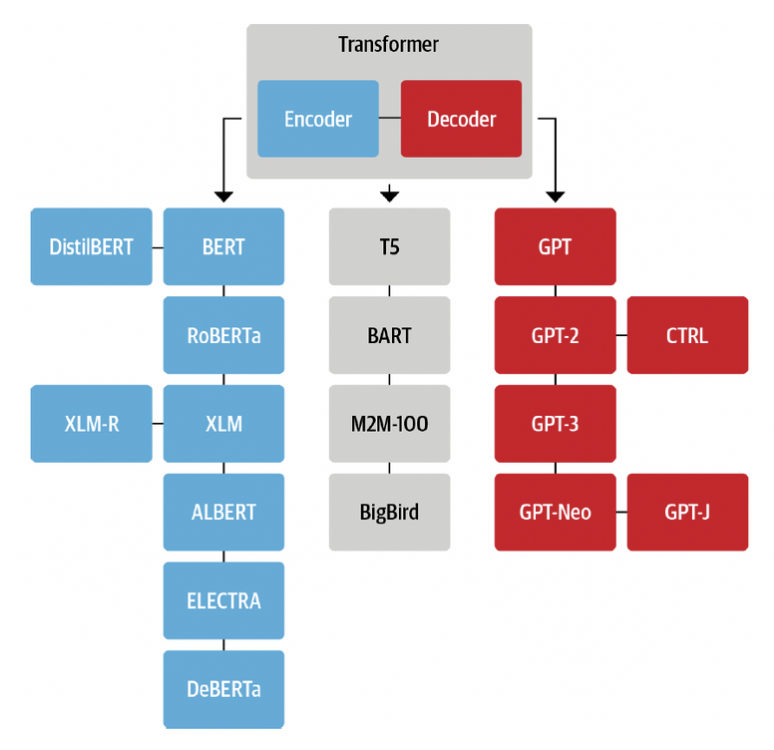
Encoder Branch
- BERT: 2개의 목표로 사전훈련
- masked language modeling(MLM): 텍스트에서 마스킹된 token을 예측
- next sentence prediction(NSP): 한 텍스트 구절이 다른 텍스트 구절을 따를 가능성이 있는지 결정
- DistilBERT
- knowledge distilation 방식 사용
- BERT보다 40% 적은 메모리 사용
- 60% 빠르게 BERT 성능의 97%를 달성
- RoBERTa
- 사전 훈련 방식을 수정하여 BERT 성능을 향상시킴
- 큰 배치(많은 훈련 데이터)에서 더 오래 훈련됨
- NSP 작업을 제외함
- XLM
- 다국어 모델을 구축하기 위한 탐구됨
- 교차 언어 모델
- MLM을 다중 언어 입력으로 확장한 번역 언어 모델링(TLM)을 도입
- XLM-RoBERTa
- 훈련데이터를 대규모로 업스케일링하여 다국어 사전 훈련을 발전시킴
- Common Crawl corpus를 사용 → 2.5TB 데이터 세트를 만듦
- MLM으로 encoder를 훈련
- 번역이 없는 데이터만 포함 → TLM 목표는 제외
- 데이터가 적은 언어에서 잘 동작
- ALBERT
- token embedding의 차원을 hidden 차원에서 분리
- 어휘가 커질 때, 매개변수를 절약
- 모든 layer들이 동일한 매개변수를 공유함
- 효과적인 매개변수의 수가 훨씬 감소함
- NSP의 목표는 문장 순서 예측으로 대체됨
- 연속된 두 문장의 순서가 바뀌었는지 여부를 예측
- 더 적은 매개변수로 큰 모델을 훈련 가능
- token embedding의 차원을 hidden 차원에서 분리
- ELECTRA
- 표준 MLM 사전 훈련 목표의 limitation
-
마스킹된 token의 표현만 업데이트, 다른 입력 token은 업데이트 되지 않음
→ 2가지 모델을 사용
- 표준 MLM 모델처럼 작동, 마스킹된 token 예측
- discriminator → 첫 번째 모델의 출력 token 중, 원래 마스킹된 token을 예측
- 모든 token에 대해 이진 분류를 수행
- 훈련이 30배 효율적
-
- 표준 MLM 사전 훈련 목표의 limitation
- DeBERTa
- 각 token은 2개의 벡터로 표시됨
- 콘텐츠용, 상대 위치용
- token의 콘텐츠를 상대적인 위치에서 분리하는 것으로 self-attention layer는 인접한 token 쌍의 종속성을 잘 모델링 할 수 있음
- 단어의 절대적 위치는 decoding에 중요
→ decoding head의 softmax 계층 앞에 절대 위치 embedding이 추가됨
- 각 token은 2개의 벡터로 표시됨
Decoder Branch
- GPT
- 새로운 transformer decoder 아키텍처와 전이학습을 결합
- 이전 단어를 기반으로 다음 단어를 예측하는 것으로 사전 학습됨
- BookCorpus로 학습됨
- 분류와 같은 downstream task에서 잘 동작
- GPT-2
- 사전 훈련 접근 방식에 영감을 받아서 모델과 훈련 세트가 upscale됨
- 일관된 텍스트의 긴 sequence를 생성할 수 있음
- CTRL(Conditional Transformer Language)
- 사용자는 생성된 sequence의 스타일을 거의 제어할 수 없음
- 시퀀스 시작 부분에 제어 token을 추가하여 해결
- 생성된 텍스트의 스타일을 제어 가능 → 다양한 생성이 가능
- GPT-3
- 계산, 데이터 및 모델 크기, 언어 성능 간의 관계에 간단한 멱급수 법칙이 있다는 것이 밝혀짐
- GPT-2 100배 확장 → 1,750억 개 매개변수
- 현실적인 텍스트 구절을 생성 가능
- few-shot learning으로 텍스트를 코드로 번역할 수 있음
- GPT-Neo/GPT-J-6B
- EleutherAI이라는 연구원 집단에서 학습한 모델
- GPT-3 스케일 모델을 재생성 및 출시하는 것을 목표
- 13억, 27억 및 60억 매개변수
- EleutherAI이라는 연구원 집단에서 학습한 모델
Encoder-Decoder Branch
- T5
- NLU 및 NLG 작업을 text-to-text 작업으로 변환하여 통합
- 모든 작업은 sequence-to-sequence 작업으로 구성됨
- original Transformer 아키텍처를 사용
- 크롤링된 대규모 C4 데이터 세트를 사용
- SuperGLUE 작업과 마스킹된 언어 모델링으로 사전 훈련
- SuperGLUE: 모든 것을 텍스트에서 텍스트로 변환
- BART
- BERT와 GPT의 사전 훈련 절차를 결합
- input 변환이 발생
- ex. 간단한 마스킹, sentence permutation, token 삭제, document rotation
- 수정된 input은 encoder를 통해 전달, decoder는 원본 텍스트를 재구성함
- M2M-100
- 일반적으로 번역 모델은 하나의 언어 쌍과 번역 방향에 대해 구축됨
- 100개 언어 중 하나를 번역할 수 있는 최초의 번역 모델
- 희귀 언어와 잘 알려지지 않은 언어 간의 고품질 번역이 가능
- 소스 및 target 언어를 나타내기 위해 접두사 토큰([CLS] token과 유사)을 사용
- BigBird
- transformer 모델의 제한 사항: maximum context size
-
attention 메커니즘의 quadratic memory 요구 사항 때문
→ 선형적으로 확장되는 sparse 형태의 attention을 활용하여 해결
-
- context를 대폭 확장 가능
- BERT(512) → BigBird(4,096)
- 텍스트 요약과 같이 긴 종속성을 보존해야 하는 경우에 특히 유용함
- transformer 모델의 제한 사항: maximum context size
Reference

Data Scientist, Data Analyst