출처: Natural Language Processing with Transformers by Lewis Tunstall, Leandro von Werra, and Thomas Wolf (O’Reilly). Copyright 2022 Lewis Tunstall, Leandro von Werra, and Thomas Wolf
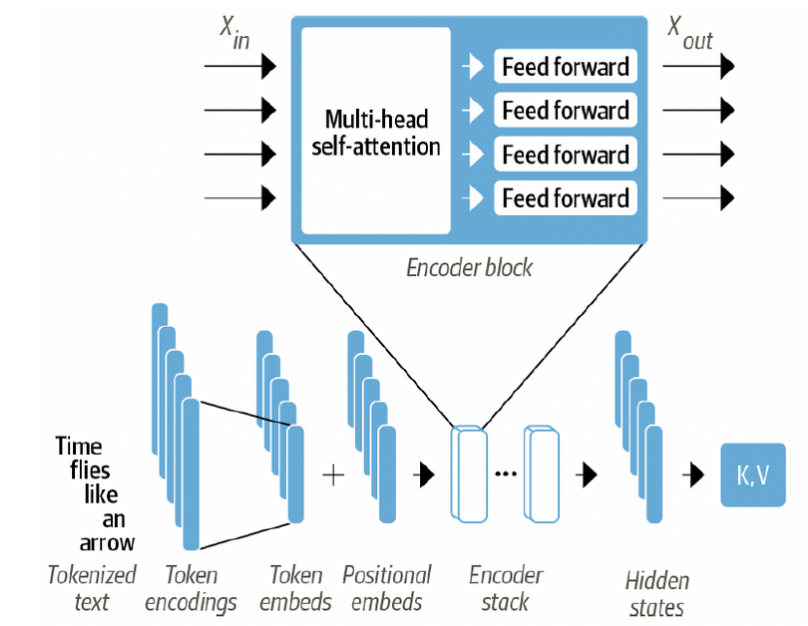
Encoder
- 많은 encoder layer로 쌓여있음 (=encoder stack)
- Input embedding을 update (Sequence의 문맥 정보를 생성하기 위함)
- Sequence of embedding을 받아서 sublayer에 전달
- sublayer 종류
- multi-head self-attention
- (Fully connected) Feed forward layer
- sublayer들은 skip connection과 layer normalization을 사용
- DNN을 효과적으로 훈련하기 위한 표준 방법이라고함
- sublayer 종류
- Output은 Input과 동일한 크기
Self-Attention
- self-attention: 동일한 집합의 모든 hidden states에 weights가 계산됨
- attention: sequence의 각 요소에 서로 다른 weight or attention을 신경망에 할당
- 요소(element): token embeddings
- 순환 모델의 attention mechanism과 대조적임
- 각각의 embedding의 가중 평균을 계산하기 위해 전체 sequence를 사용
- : (normalized) attention weights
- 왜 token embedding을 평균하는 방법을 쓸까?
-
sequence의 문맥에 더 가까운 표현을 가진 token embedding에 큰 가중치를 할당하여 결합하기 위함
→ Contextualized embeddings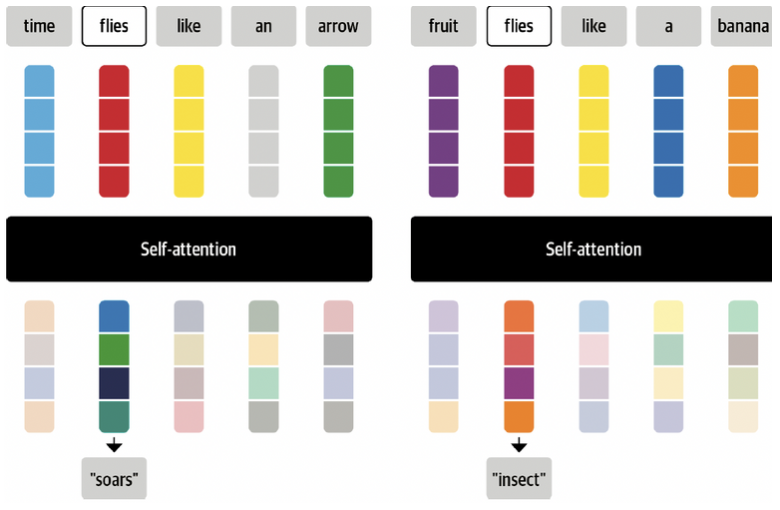
-
- attention: sequence의 각 요소에 서로 다른 weight or attention을 신경망에 할당
Scaled dot-product attention
-
self-attention layer를 개선하기 위한 방법
-
mechanism을 시행하기 위한 4가지 step이 있음

- 각각의 token embedding을 query, key, value라는 세 가지 벡터로 투영
- query, key, value 개념이해
- 만약 요리 레시피가 있다고 했을 때,
- 필요한 재료: query
- 슈퍼마켓에서 발견한 label: keys
- 재료와 label이 일치하는지 확인: similarity function
- 일치하면 item을 가져감: value
- 만약 요리 레시피가 있다고 했을 때,
- query, key, value 개념이해
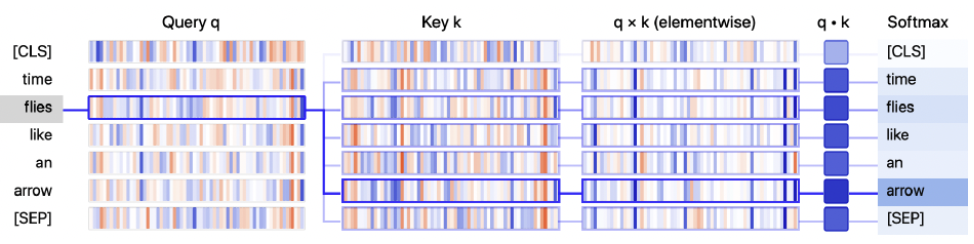
- Compute attention score
- query, key 벡터의 관련성을 확인하기 위하 similarity function을 사용함
- similarity function: 내적(dot product)를 이용
- input token 개수 만큼 attention score의 결과가 생성됨
- input token (n) → attention score matrix (n n)
- query, key 벡터의 관련성을 확인하기 위하 similarity function을 사용함
- Compute attention weights
- 내적값은 큰 숫자가 발생 가능 (큰 값은 훈련 과정을 불안정하게 할 수 있음)
→ scaling 필요 - 분산을 표준화하기 위해 scaling factor를 곱함
- softmax를 활용 → 가중치 합계 1
- 내적값은 큰 숫자가 발생 가능 (큰 값은 훈련 과정을 불안정하게 할 수 있음)
- Update token embeddings
- 각각의 token embedding을 query, key, value라는 세 가지 벡터로 투영
-
BertViz library로 query, key 벡터가 결합되어 최종 가중치가 생성되는 과정을 볼수 있음
Multi-headed attention
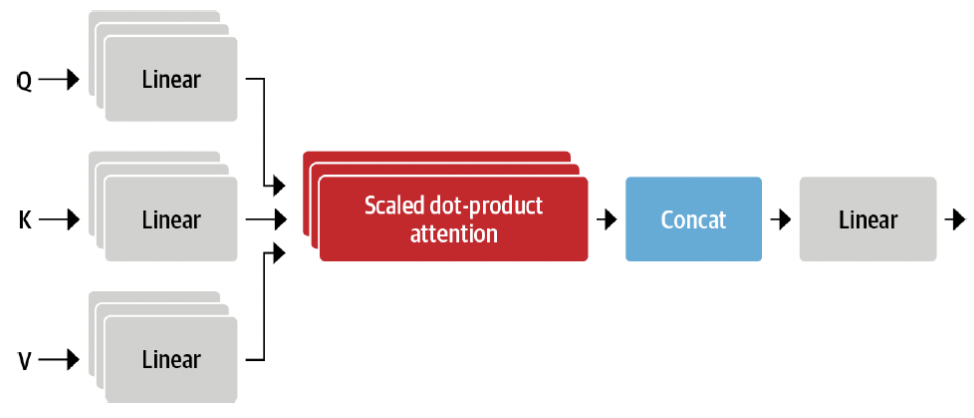
- self-attention layer는 query, key, value 벡터를 생성하기 위해 각 embedding에 독립적인 선형 변환을 적용함
- 독립적인 선형 변환은 embedding을 투영하고 각 투영은 자체 학습 가능한 매개변수 세트를 전달함
→ self-attention layer가 sequence의 다른 의미론적 측면에 집중할 수 있음
- attention head: 선형 투영 세트
- multiple attention head가 유용하다고 함
- 왜 여러 개의 attention head를 필요로 할까?
- 1 head의 softmax는 유사성의 한 측면에 초점을 맞추는 경향이 있기 때문
- 여러개의 head를 사용하면 모델이 한 번에 여러 측면에 집중할 수 있도록 함
- ex. 1 head (주어-동사 상호작용), 2 head (+ 동사-형용사 상호작용)
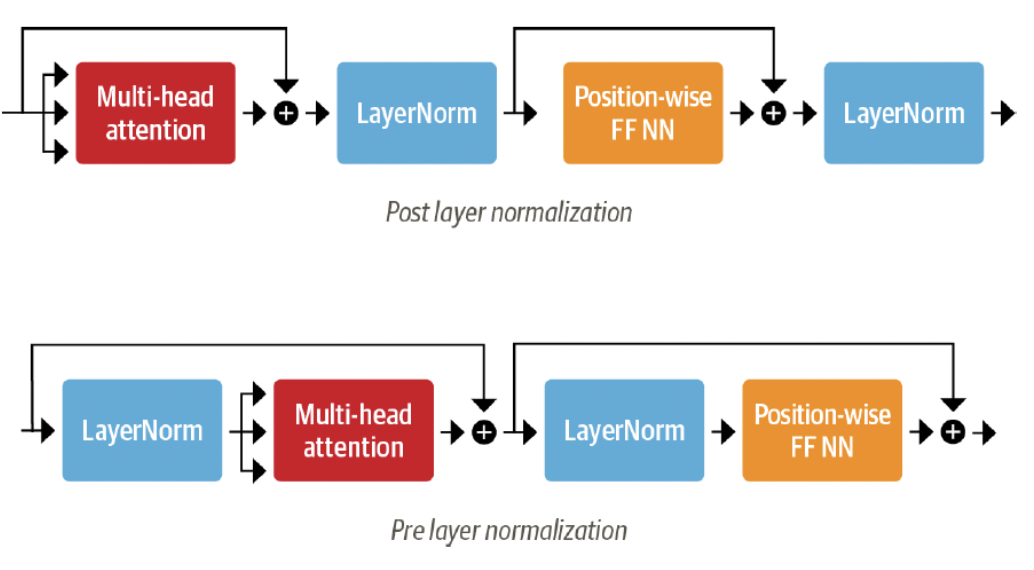
Layer normalization
- skip connections: 텐서를 처리 없이 모델의 다음 layer로 전달하고 처리된 텐서에 추가함
- layer normalization: 배치의 각 입력을 평균 0, 단일 분산을 갖도록 표준화
- Post layer normalization
- transformer 논문에 사용됨
- skip connection 사이에 layer normalization을 배치
- gradient가 발산할 수 있음 → 처음부터 훈련하기 까다로움
→ learning rate warm-up 활용
- learning rate warm-up: 학습률을 작은 값에서 최대값으로 점진적으로 증가시키는 방법
- Pre layer normalization
- skip connection 연결 범위 내에 배치
- 훈련 중에 안정적인 경향 → learning rate warm-up이 필요없음
- Post layer normalization
Positional Embeddings
- 벡터에 배열된 값의 위치 종속 패턴으로 token embedding을 증강
- 각 위치의 특징인 패턴으로 attention head와 feed forward layer는 위치 정보를 transformation에 통합할 수 있음
- learnable pattern 사용
- 사전 학습 데이터가 충분히 클 때 사용
- token embedding과 동일한 방식
- 다른점: input에 position index를 사용
- 사전 훈련 중에 token의 위치를 encoding하는 효율적인 방식
- learnable pattern 대안
- Absolute positional representations
- token의 위치를 encoding하기 위해, 조절된 sine / cosine로 구성된 정적 패턴을 사용
- 많은 양의 데이터가 없을 때, 특히 잘 작동함
- Relative positional representations
- embedding을 계산할 때, 주변의 token이 중요할 수도 있음
- token의 상대적 위치를 encoding함
- 주목하는 sequence의 위치에 따라 각 token의 상대적 embedding이 변경됨
→ relative embedding layer를 처음에 도입하는 것만으로 설정이 불가능
→ token 간 상대적 위치를 고려하는 추가적인 용어로 수정됨
- 주목하는 sequence의 위치에 따라 각 token의 상대적 embedding이 변경됨
- ex. DeBERTa
- Absolute positional representations
Classification Head
- text classifier를 build하려면 classification head를 부착해야됨
- 보통 모델의 첫 번째 token은 예측을 위해 사용되고, dropout 및 분류 예측을 위해 linear layer을 부착함
- 모델을 initialize하기 전, 몇개의 class를 예측할 것인지 설정 필요
Reference

Data Scientist, Data Analyst