출처: 코리 웨이드.(2022). XGBoost와 사이킷런을 활용한 그레이디언트 부스팅. 서울:한빛미디어
앙상블
개별 모델의 예측을 합치는 머신러닝 모델 -> 개별 모델보다 오차를 줄이고 더 좋은 성능을 도출할 수 있음
분류기 대표적인 방법: 다수결 투표 (Majority vote)
앙상블 방법
- 여러 종류의 머신러닝 모델을 연결하는 방식 (ex. VotingClassifier)
- 하드 보팅 (Hard Voting): 다수의 분류기가 예측한 결과값을 선택
- 소프트 보팅 (Soft Voting): 각 분류기별 레이블 값 결정 확률을 평균 낸 값이 가장 높은 레이블 값을 선정
- 같은 종류의 모델을 여러 개 합치는 방식 (ex. XGBoost, Random Forest)
- 배깅 (Bagging)
- 부스팅 (Boosting)
배깅 (Bagging)
Bagging = Bootstrap Aggregation
부트스트래핑(Bootstraping): 중복을 허용한 샘플링 (= 복원추출)
대표 알고리즘: Random Forest
데이터별 방식 구분
- 분류: Majority Vote
- 회귀: Mean
랜덤 포레스트 (Random Forest)
부트스트래핑을 사용한 결정 트리의 예측을 합친 방법
랜덤 포레스트의 분산을 줄일 수 있는 2가지 이유
- 부트스트래핑 샘플을 사용하므로 다양성이 높아지고, 집계하면 분산이 줄어듦
- 노드를 분할할 때 특성 개수의 제곱근을 사용
하이퍼파라미터
- oob_score (oob = out of bag)
- True로 설정 시, 랜덤 포레스트 모델을 훈련한 후 각 트리에서 사용하지 않은 샘플(=부트스트래핑되지 않은 남은 샘플)을 사용해 개별 트리의 예측 점수를 누적하여 평균을 냄
-> 트리 개수(=n_estimators)가 작을 경우, 수집할 oob 샘플 수가 적음
-> 더 많은 트리는 더 많은 oob 샘플을 의미하며 정확도를 높일 수 있음 - 테스트 점수의 대안으로 사용 가능
- True로 설정 시, 랜덤 포레스트 모델을 훈련한 후 각 트리에서 사용하지 않은 샘플(=부트스트래핑되지 않은 남은 샘플)을 사용해 개별 트리의 예측 점수를 누적하여 평균을 냄
- warm_start
- 랜덤 포레스트의 트리 개수를 결정하는데 도움이 됨
- True로 지정 시, 이전 모델에 이어서 트리를 앙상블에 추가할 수 있음
ex. n_estimators를 50개, 100개로 훈련할 때 100개 트리는 50개만 추가적으로 훈련하기 때문에 시간이 단축됨 - 아래 그림에서 oob_score 기준, n_estimators의 적정값은 300임을 알 수 있음
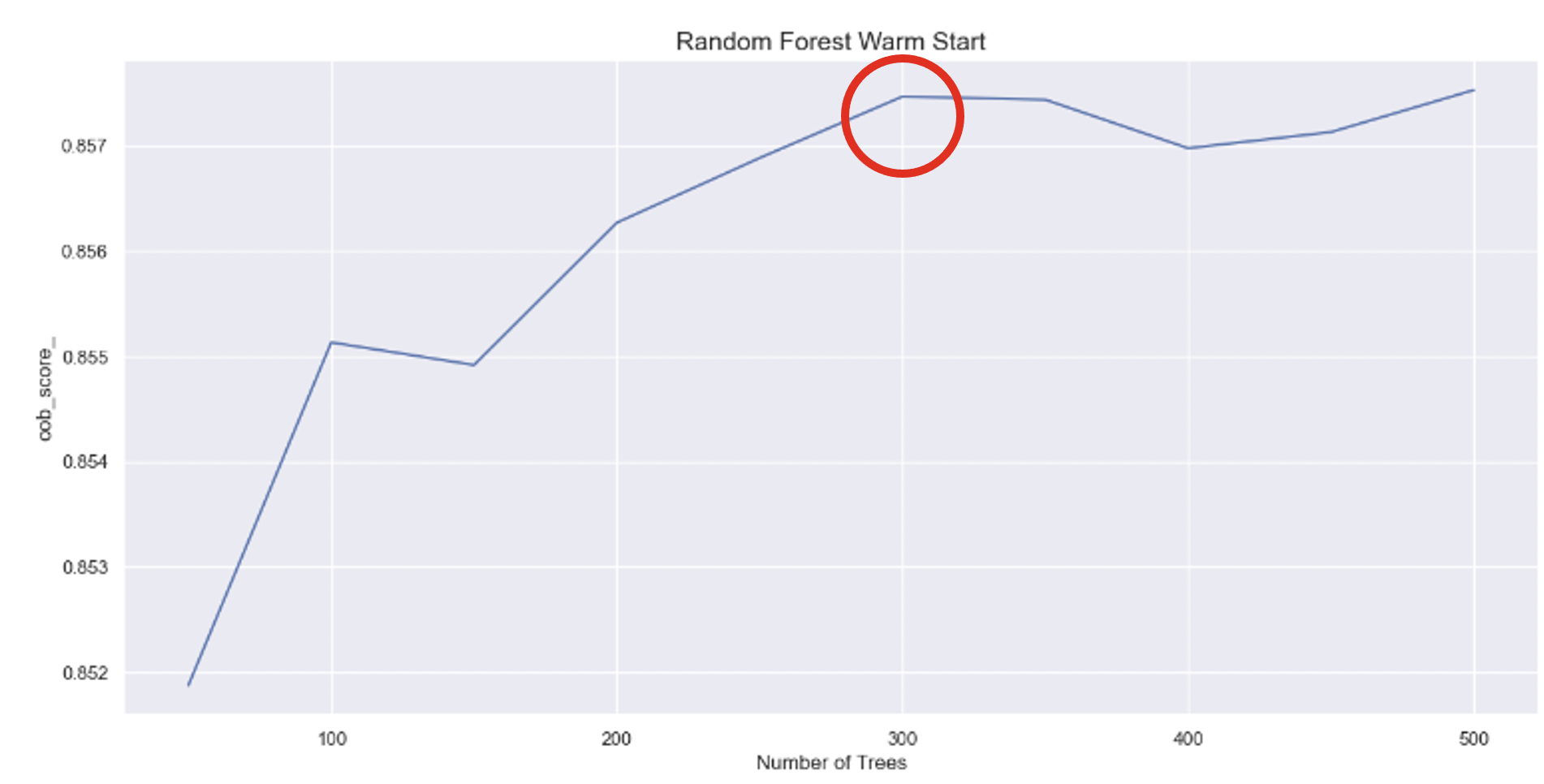
- bootstrap: 과소적합이 일어나는 경우에 False로 지정하여 사용할 때도 있음
- verbose: 모델 구축 동안의 정보를 표시, default 0
- verbose=0 : 출력 안함
- verbose=1 : 자세한 정보를 출력함
- verbose=2 : 함축적인 정보만 출력함
- max_samples: 개별 트리를 훈련하는데 사용할 훈련 세트 크기를 지정, default None
- 샘플 개수를 정수로 or 0~1 사이의 실수로 원본 훈련 세트 크기의 비율로 지정 가능
성능 높이기
- 적정 트리 개수 확인
- warm_start=True
- n_estimators를 높이면서 oob_score확인
- 하이퍼파라미터 튜닝 (Random Search)
- 초기 설정 범위로 실행
- 탐색 범위를 좁혀보기 (하이퍼파라미터 수 감소)
- 탐색 횟수(runs)를 늘려보기
- n_estimators를 증가 시켜보기
- 학습 데이터를 shuffle해보기
장단점
장점
- 회귀, 분류 문제에 모두 사용 가능
- 성능이 뛰어남 (매개변수 튜닝이 없어도 잘 작동함)
- 대용량 데이터 처리에 효과적
- 데이터 스케일에 자유로움 (정규화, 표준화 필요없음)
단점
- 개별 트리에 제약이됨
-> 모든 트리가 동일한 실수 발생 시, 랜덤 포레스트도 실수를 함 - 많은 메모리 사용으로 인해 훈련 및 예측 시간이 오래걸림
- 차원이 높고 희소한 데이터에서는 잘 작동하지 않음
- 생성하는 모든 트리 모델을 다 해석하기 어려움
- 특성의 일부만 사용하여 결정 트리보다 깊어지는 경우가 있음
참고

Data Scientist, Data Analyst