출처: 코리 웨이드.(2022). XGBoost와 사이킷런을 활용한 그레이디언트 부스팅. 서울:한빛미디어
부스팅
부스팅: 개별 트리의 실수로부터 학습
- 이전 트리의 오차를 기반으로 새로운 트리를 훈련하는 것
- 잔차(=실제값 - 예측값)를 활용
- 개별 트리가 이전 트리를 기반으로 만들어짐
배깅:
- 새로운 트리가 이전 트리와 관련이 없음
- 새로운 트리는 부트스트래핑을 사용해 처음부터 훈련되고, 최종 모델은 모든 개별 트리의 결과를 합침
에이다부스트 (AdaBoost)
- 인기 있는 초기 부스팅 모델 중 하나
- 새로운 트리가 이전 트리의 오차를 기반으로 가중치를 조정함
- 오류 샘플의 가중치를 높여서 잘못된 예측에 더 많은 주의를 기울임
- 약한 학습기를 강력한 학습기로 만들 수 있음
- 약한 학습기: 우연보다 조금 나은 성능을 내는 ML 모델
- 강한 학습기: 많은 양의 데이터에서 학습하여 잘 수행되는 모델
- 반복 횟수는 n_estimators 파라미터로 설정 가능
약한 학습기로 학습을 시작하는 이유
- 부스팅은 반복적으로 오류를 고치는 것에 초점을 맞춤
- 기반 모델이 너무 강력하면 학습 과정에 제한이 생겨서 부스팅 모델의 전략을 약화시킴
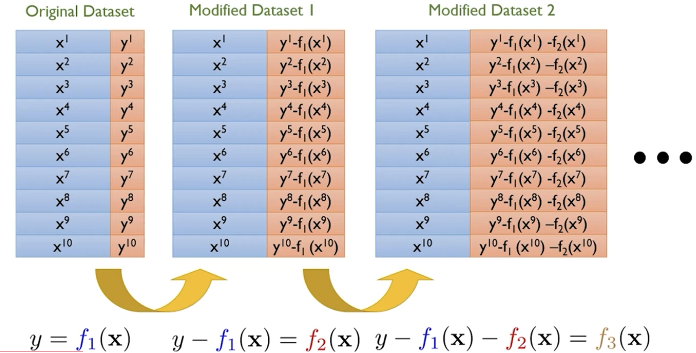
그레이디언트 부스팅 (Gradient Boosting)
- 이전 트리의 예측 오차를 기반으로 완전히 새로운 트리를 훈련함
- 각 트리의 실수를 살펴보고 이런 실수에 대한 완전히 새로운 트리를 만드는 것
- 손실 함수를 정의하고 손실을 최소화하도록 트리를 추가함 -> 손실 함수의 gradient를 계산
- 회귀 모델: 제곱 오차
- 분류 모델: 로지스틱 손실 함수
- 각 트리의 예측 값을 더해서 모델 평가에 사용함
AdaBoost VS Gradient Boosting
두 알고리즘 모두 예측하기 어려운 문제를 관찰에 초점을 맞추어 기본 학습기 (week learner)의 성능을 반복적으로 높이는데 사용됨
- AdaBoost:
- 잘못 분류된 관측값에 가중치를 부여하여 개선
- 각 분류기의 최종 예측에 할당되는 가중치가 다름
- tree는 stump로 자람
- Gradient Boosting:
- 실제값과 예측된 값의 차이인 잔차를 기반으로 개선
- 모든 분류기의 가중치가 동일
- 일반적으로 tree는 8~32개 terminal node를 가지는 깊이로 자람
학습 방법
- 약한 결정 트리로 시작 (스텀프 or max_depth 3이하)
- 모델 학습 (X: 사용할 독립 변수, Y: 종속 변수)
- 잔차 계산 (잔차1)
- 모델 학습 (X: 동일, Y: 잔차1)
- 하이퍼 파라미터가 동일한 gradient boosting 모델을 사용
- 잔차 계산 (잔차2)
- 모델 학습 (X: 동일, Y: 잔차2)
- 모델 학습, 잔차 계산 n회 반복 -> 과정이 반복되면 잔차가 0에 가까워짐
- Test 데이터에 대한 예측 결과를 모두 더함 (y_pred = 잔차1 + 잔차2 + ... + 잔차n)
- 실제값과 예측값(y_pred)의 평가 (ex. MSE)
사이킷런 그레디언트 부스팅
- 초기 잔차를 계산하기 위한 합리적인 모델을 만들어야됨
- init 매개변수에서 초기 모델 지정 가능 (default None)
- 회귀: 타깃의 평균 사용 (GradientBoostingRegressor)
- 분류: 다수의 클래스 레이블 사용 (GradientBoostingClassifier)
- 평가 방식
- GradientBoostingRegressor: 예측값 합산 후 비교
- GradientBoostingClassifier: 클래스별 각 트리의 예측을 합한 후, sigmoid 함수를 적용하여 예측 확률을 계산
학습 과정
from skelarn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error
# 약한 결정 트리로 시작 (스텀프 or max_depth 3이하)
regtree_1 = DecisionTreeRegressor(max_depth=2, random_state=2)
regtree_2 = DecisionTreeRegressor(max_depth=2, random_state=2)
regtree_3 = DecisionTreeRegressor(max_depth=2, random_state=2)
# 1번째 잔차 계산 (초기 잔차 -> 타깃 평균 사용)
residual_1 = y_train - np.mean(y_train)
# 학습 후, 2번째 잔차 계산
regtree_1.fit(X_train, residual_1)
pred_1 = regtree_1.predict(X_train)
residual_2 = y_train - pred_1
# 학습 후, 3번째 잔차 계산
regtree_2.fit(X_train, residual_2)
pred_2 = regtree_2.predict(X_train)
residual_3 = y_train - (pred_1 + pred_2)
# 학습
regtree_3.fit(X_train, residual_3)
# 예측
y_pred = regtree_1.predict(X_text) + regtree_2.predict(X_text) + regtree_3.predict(X_text)
# 평가
mean_squared_error(y_test, y_pred, squared=False)GBM 알고리즘 사용
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
# 모델
gbr = GradientBoostingRegressor(max_depth=2, n_estimators=3,
random_state=2, learning_rate=1.0)
# 학습
gbr.fit(X_train, y_train)
# 예측
y_pred = gbr.predict(X_test)
# 평가
mean_squared_error(y_test, y_pred) ** 0.5매개변수 튜닝
- learning_rate
- 개별 트리의 영향을 제한함 (=기여를 줄임)
- 기본 학습기의 오차를 기반으로 앙상블을 만들 경우, 초기 트리의 영향이 크게 발생함
- 최적의 learning_rate 값은 n_esimators에 따라 다름 -> 같이 튜닝해야됨
- 기본 학습기
- gradient boosting의 기본 학습기는 결정 트리
- 잔차를 타깃으로 훈련하기 때문에 fine tuning의 필요성은 떨어짐
- 정확도 향상을 위해 max_depth와 같은 일부 매개변수를 튜닝할 수는 있음
- subsample
- 기본 학습기에 사용될 샘플의 비율을 지정 (default 1)
ex. 0.8 -> 80% 데이터만 사용하여 트리를 훈련 - subsample이 1보다 작은 경우 Stochastic Gradient Boosting이라고 부름
- 모델에 무작위성이 주입된다는 의미
- OOB 점수를 계산할 수 있음
- 기본 학습기에 사용될 샘플의 비율을 지정 (default 1)
Reference

Data Scientist, Data Analyst