ndarray를 저장하는 방법 중에 npz라는 파일 포맷이 있었다.
numpy에서 지원하는 방법이며, ndarray를 저장할 때 pickle보다 여러 장점이 있다고 해서 찾아보게 되었다.
결론부터 말하면
ndarray를 저장하려고 한다면, npy/npz를 사용하는 것이 pickle보다 좋다고 생각한다. 추가적으로 npz compressed는 load 속도와 memory의 효율성은 있었지만 save 시간이 너무 오래걸렸다.
pickle? npz?
- pickle
- 파이썬 객체 자체를 바이너리 파일로 저장하는 것이다
- dictionary, list, tuple과 같은 형태로 필요한 부분을 저장
- 안전하지 않다는 단점이 있다고 한다 (RCE 공격을 받을 수 있다고 함)
- npz
- numpy 배열을 파일로 저장하는 방식 (numpy 배열에 특화됨)
- ndarray 여러 개를 압축해서 저장하기 위한 바이너리 포맷
(ndarray 하나일 경우 npy)
저장
- pickle
def write_pickle(samples, path):
with open(path, 'wb') as f:
pickle.dump(samples, f)- npy/npz
def write_npz(samples, path):
if samples.ndim == 1:
np.save(path, samples)
else:
np.savez(path, **{str(key): value for key, value in enumerate(samples)}) # 배열 크기만큼 ['0', '1', '2' . ..]로 key값이 저장됨- compressed npz
def write_compressed_npz(samples, path):
if samples.ndim == 1:
np.savez_compressed(path, **{'0': samples})
else:
np.savez_compressed(path, **{str(key): value for key, value in enumerate(samples)})읽기
- pickle
with open(path + 'data.pickle', 'rb') as f:
x = pickle.load(f)- npy/npz
x = np.load(path + 'data.npy')
x = np.load(path + 'data.npz')- compressed npz
x = np.load(path + 'data_compressed.npz')성능 속도
def make_samples(size, count):
if count == 1:
samples = np.random.random_sample((size, ))
else:
samples = np.random.random_sample((count, size))
return samples
samples = make_samples(size, count) # size, count는 알아서 지정여기서는 배열의 길이를 엄청 길게 설정(3억개)하여 테스트 해보았다.
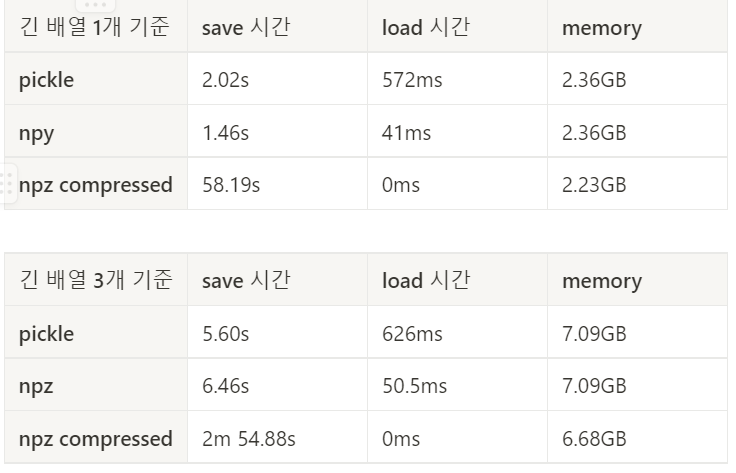
참고

Data Scientist, Data Analyst