고려대학교 산업공학과 정태수 교수님 강의 정리
Week7: 마르코브 결정 프로세스-3
개요
Infinite-horizon MDP
- 강화학습의 기본 수학적 모델
- 정상성 과정을 적용
- 최상의 정상 정책이 존재
--> 목적: 가치함수의 값을 바탕으로 최적의 정상정책을 찾아내는 것
벨만최적방정식을 푸는 방식
- Value Iteration
- Policy Iteration
7-1. Value Iteration
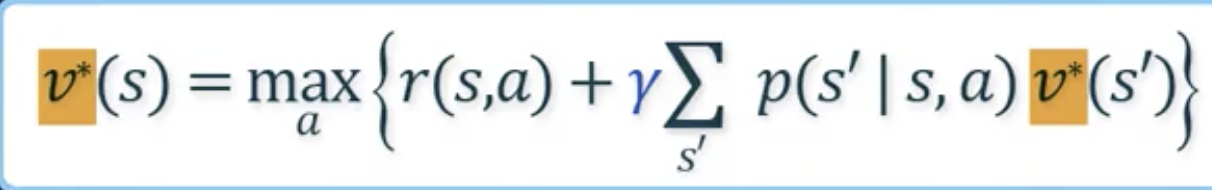
- 알고리즘 아이디어: 와 가 모든 s에 대해서 다 같다면 문제를 조금 더 반복적으로 풀 수 있지 않을까? 하고 제안된 방법론
Infinite-horizon MDP 알고리즘
문제 풀이
- 초기화 for all s
- 계산의 용이성을 위함

- 계산의 용이성을 위함
반복 풀이 ()

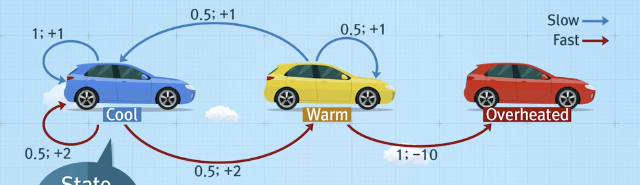
예시

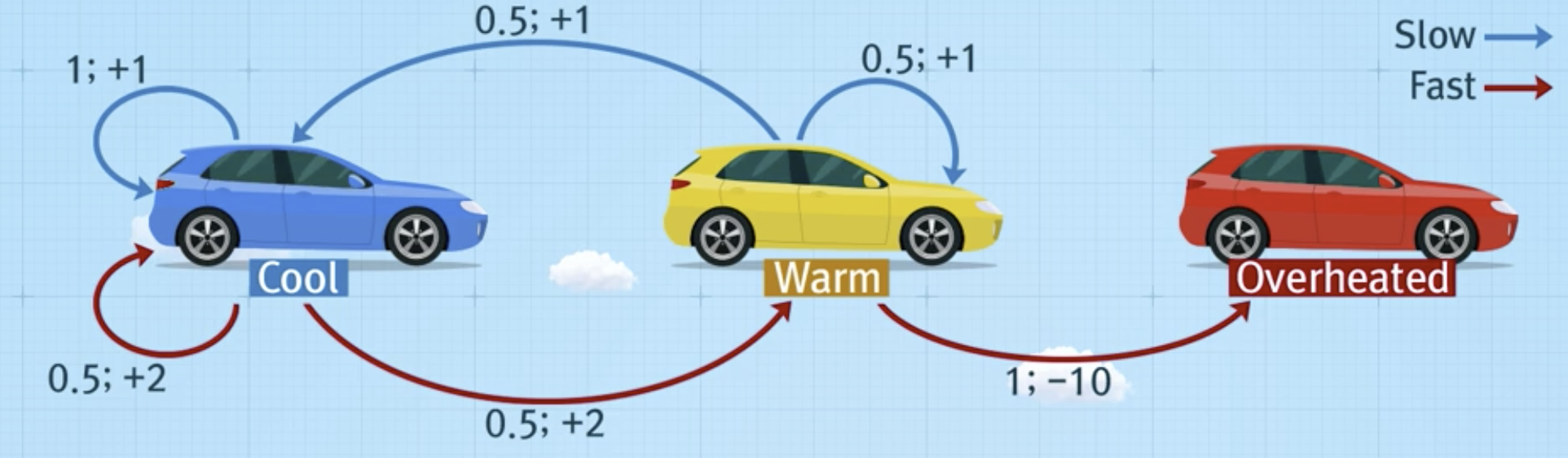
- 가치함수 값 초기화
- 계산:
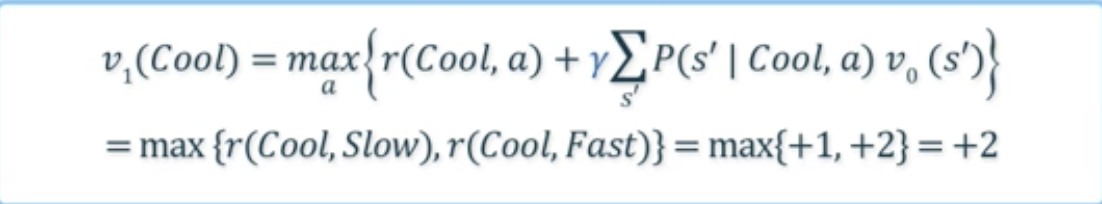
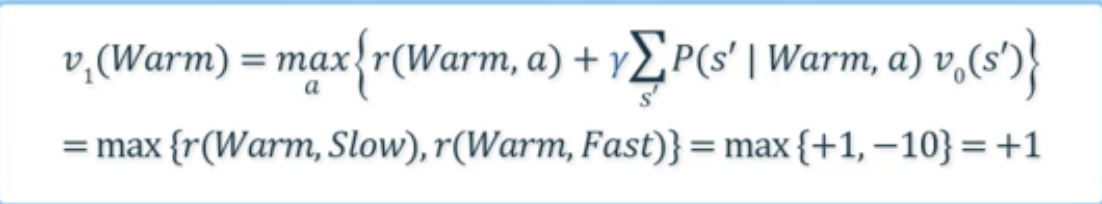

- 가 보다 큰 경우는 다음 iteration 진행
- 계산:




- 계산:

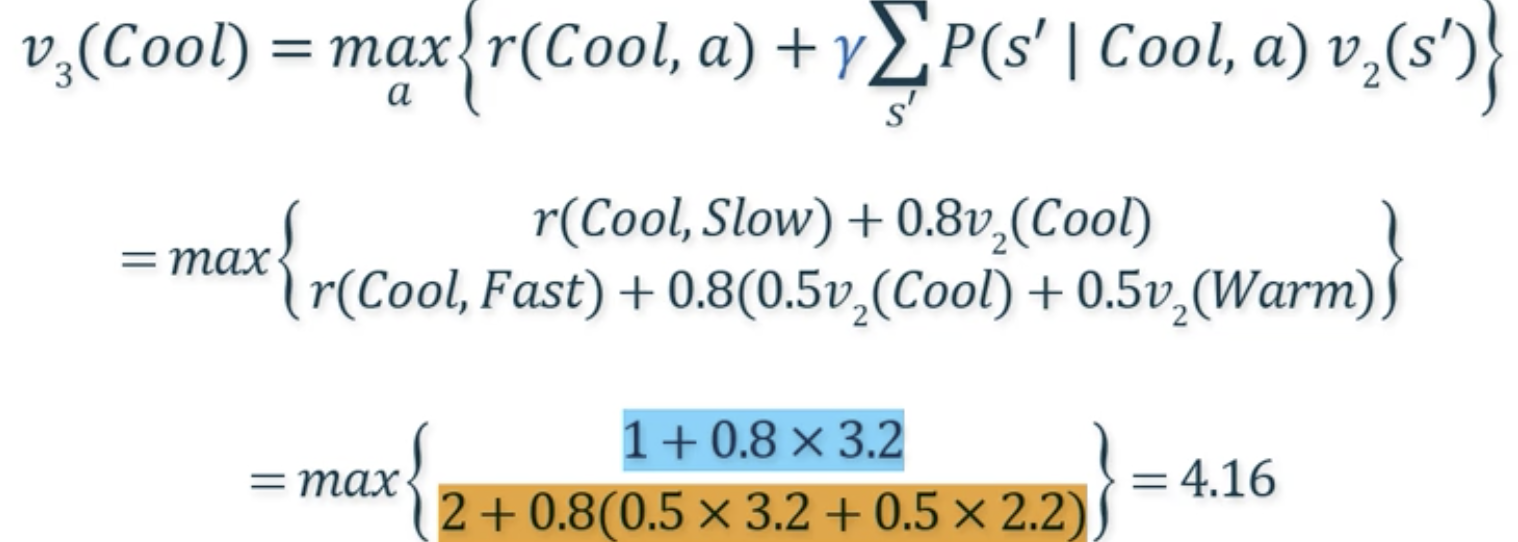
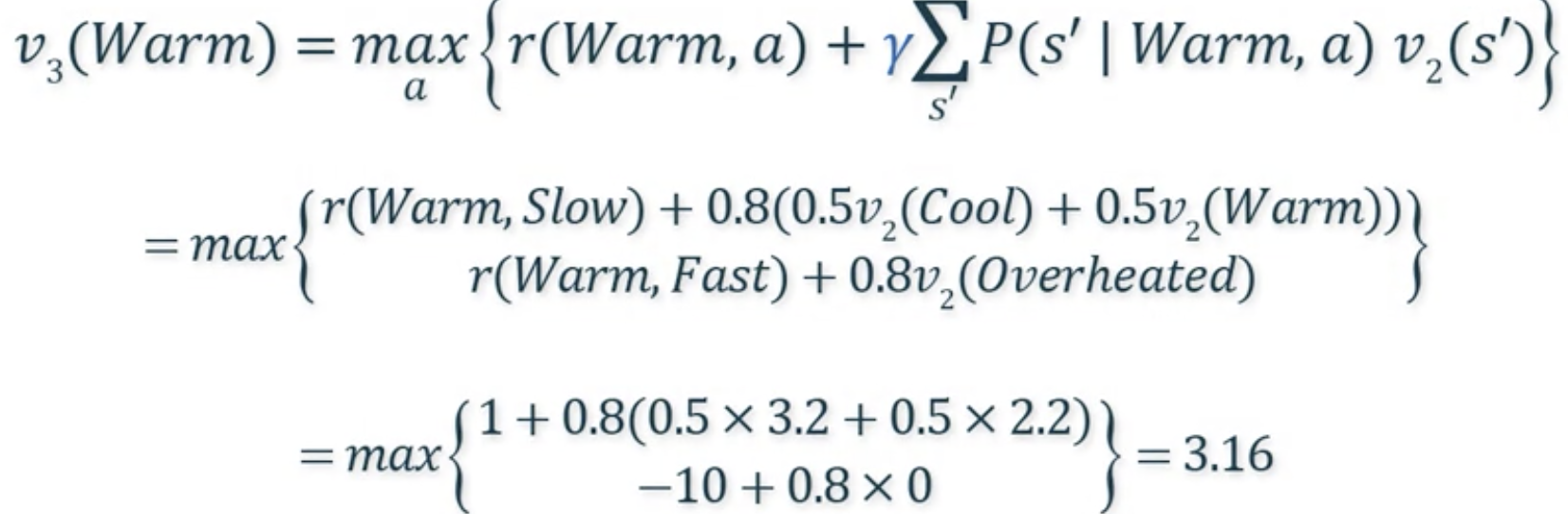

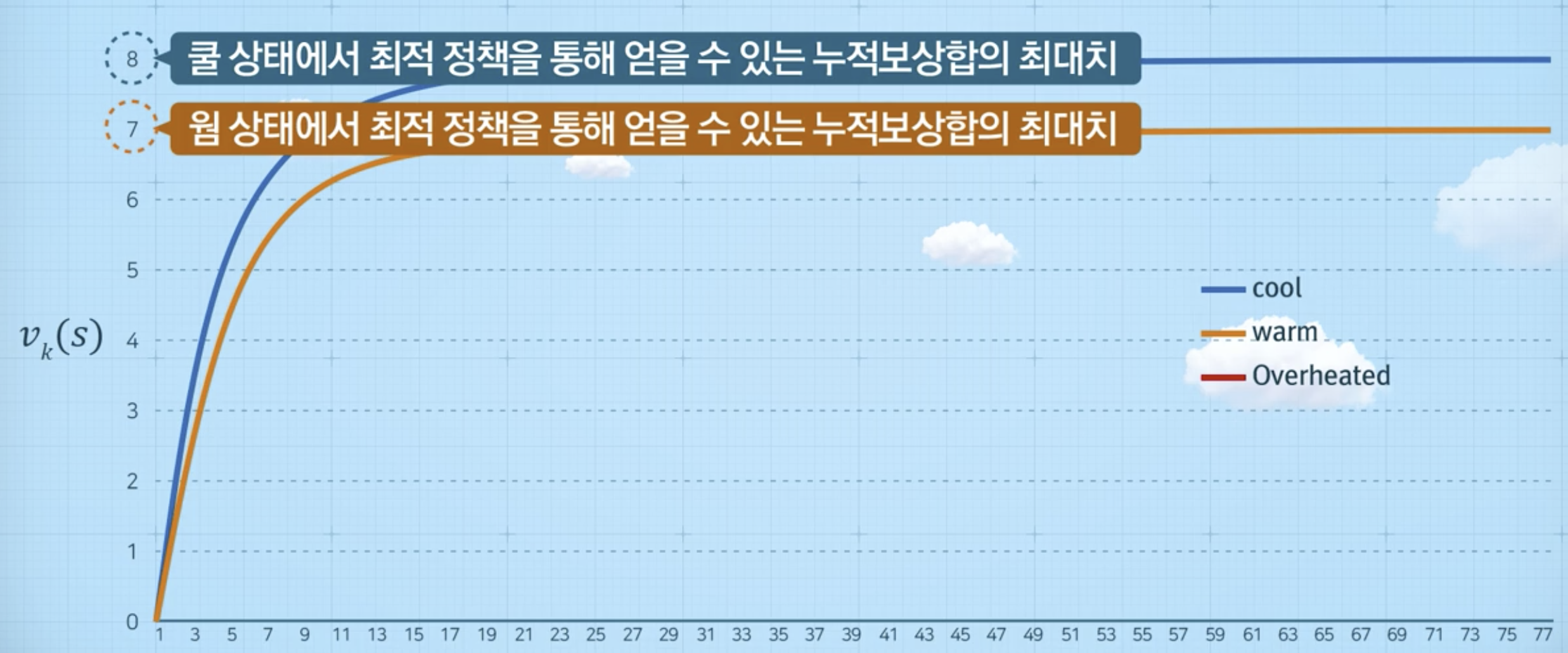
- 수렴할 때까지 위의 과정을 반복
- 결과
최적정책
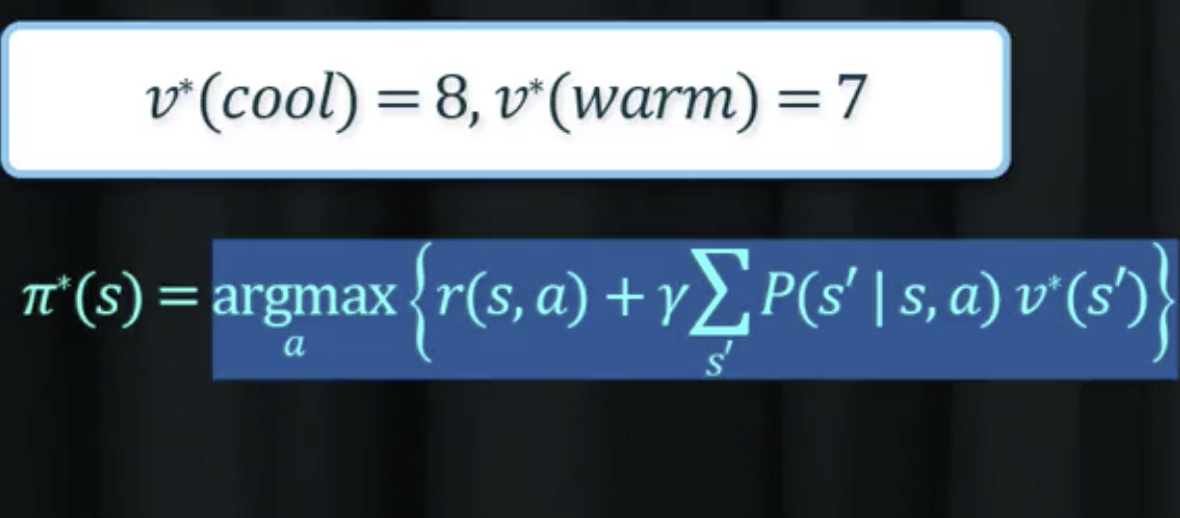

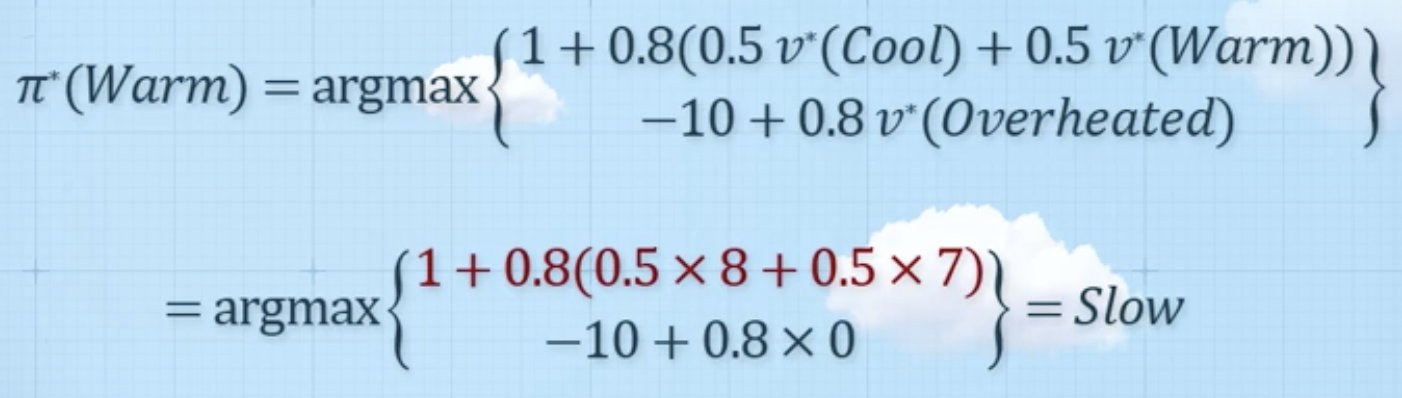
- Cool -> Fast
- Warm -> Slow
Gambler's problem

상태 정의

행동 정의

상태전이확률 정의

보상 정의

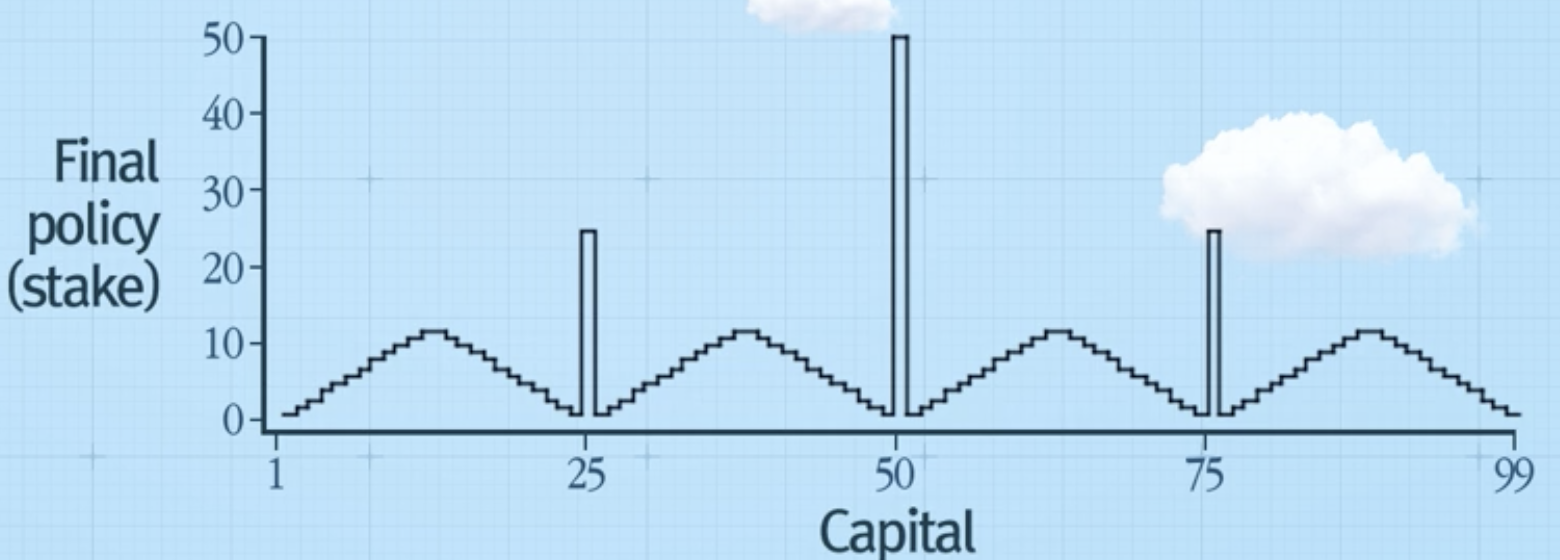
Value iteration 결과

수렴한 정책의 결과
- 자산에 따른 게임에 낼 금액 표현
7-2. Policy Iteration
- 임의의 정책을 바탕으로 정책을 업데이트
- 초기화
- value iteration: 계산의 용이성을 위해 임의의 값 0으로 초기화
- policy iteration: 임의의 정책 초기화
- 정책의 값이 변화가 없을 때까지 반복
반복 단계
-
정책 평가 (Policy evaluation)


-
정책 개선 (Policy improvement)

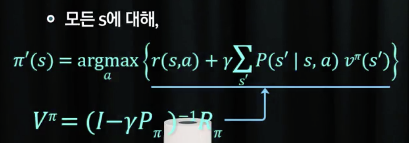

- 반복: 정책 평가 -> 정책 개선 -> 정책 업데이트
- 정책의 변화가 없을 때까지 반복
- 수렴의 보장
- 정책 업데이트 시 가치 함수 값이 항상 커짐

- 정책 업데이트 시 가치 함수 값이 항상 커짐
과정

예시
1. 모든 정책 나열 후 정책 평가
2. 최적 정책 (가장 높은 가치함수 값) 선택
가능한 정책 나열

- 정책 계산

--> State, Action이 작을 경우, 모든 정책을 나열해서 평가
반복(1)
정책 평가



정책 개선


반복(2)
정책 평가

정책 개선


정책 업데이트
- 정책 평가와 개선을 통해 얻어진 정책 간 차이가 없음
--> 동일한 결과값을 얻음
--> 최적의 정책
Jack's car rental
문제

상태 정의
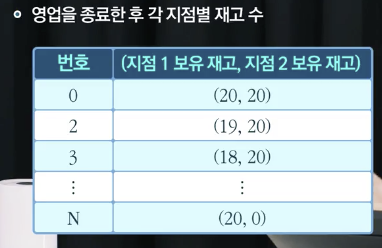
행동 정의

예시

Policy iteration 결과

Infinite-horizon MDP 문제 풀이 방법
Value iteration
- 반복 70~80회 진행
- 반복 시간이 정책 반복보다 작음
Policy iteration
- 반복 2회 진행
- 일반적으로 반복 횟수가 적음
- 반복 시간이 가치 반복보다 큼

Data Scientist, Data Analyst