고려대학교 산업공학과 정태수 교수님 강의 정리
Week9: 강화학습 알고리듬 - 1
9-1. 강화학습 Model-free Reinforcement Learning
강화학습
- 강화학습: 환경에 대한 정보를 획득하면서 에이전트가 학습을 함
- 에이전트: 어떤 환경에 어떤 행동이 보상을 최대화 할 수 있는지 학습

Infinite-horizon MDP
모델 구성 요소
- 상태공간
- 에이전트가 관찰할 수 있는 어떤 상태들의 집합
- 행동공간
- 어떤 환경에 따라 취할 수 있는 액션 후보들의 집합
- 상태에 따라 행동들의 집합이 달라질 수 있음
- 상태전이확률
- 어떤 상태에서 어떤 액션을 취하면 다음 상태 예측을 할 수 있는 정보가 주어진 상태
- 보상
- 어떤 보상의 기대값
- 강화학습을 정의하는 환경에 따라 변화

- 감가율
- 누적보상: 어떤 상태에서 어떤 액션을 취해야 유리한지 판단할 수 있는 근거
- 감가율: 누적보상 무한반복 문제 방지를 위한 개념
- 어떤 일정한 값으로 수렴하도록 함
최적 정책
- Final-horizon MDP
- 의사결정규칙: 특정 의사결정 시점에 어떤 상태에서 어떤 액션을 취할지에 대한 함수
- 정책: 의사 결정 규칙들을 다 모아 놓은 것
- Infinite-horizon MDP
- 모든 시간에 따라 독립적이라는 안정성 보유
- 의사결정 규칙이 바로 정책이 되는 상황
- 정책: 상태를 행동에 매핑한 함수
Infinite-horizon MDP의 정책
- 확정적 정책 (Deterministic Policy)
- 정책이 주어져 있음
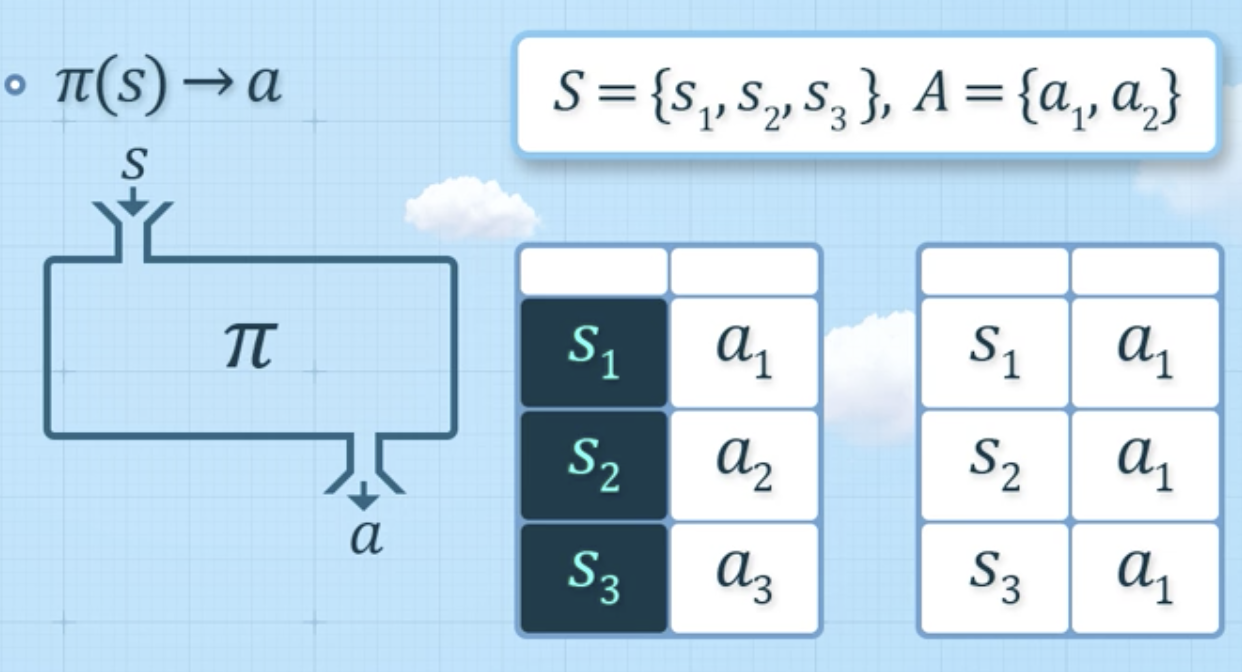
- 정책이 주어져 있음
- 확률적 정책 (Stochastic Policy)
- 확률 분포가 주어져 있음

- 확률 분포가 주어져 있음
Infinite-horizon MDP의 최적 정책
- 감가율이 반영된 누적 보상합의 기대값을 최대화하는 정책을 찾는 것

정책 평가

벨만 기대 방정식

벨만 최적 방정식

가치 반복

정책 반복
- 강화학습에서 prediction 과정이라고 얘기함

Infinite-horizon MDP와 강화학습의 주요 차이점
- 학습 시 모델에 대한 정보 존재 여부
- 강화학습은 모델(환경)에 대한 가정을 모르는 상황에서 학습하는 방법
- 강화학습은 상태전이확률, 보상의 정보가 부재한 경우에 경험을 통해 학습하는 것
강화학습 방법론
Model-based methods
- 수집한 데이터를 바탕으로 모델 추정
- 정보를 수집하고 다양한 방법론을 적용하여 최적 정책 도출
Model-free methods

- 가치 기반 방법: 최적 행동-가치 함수 추정
- 정책 기반 방법: 최적 정책 직접적으로 개선
매우 단순한 모델 기반 강화학습
- 데이터로부터 MDP 추정
- 데이터로부터 상태전이확률과 리워드 추정
- 이를 바탕으로 최적 정책 찾기
9-2. 몬테칼로 학습 Monte-Carlo Learning
개요

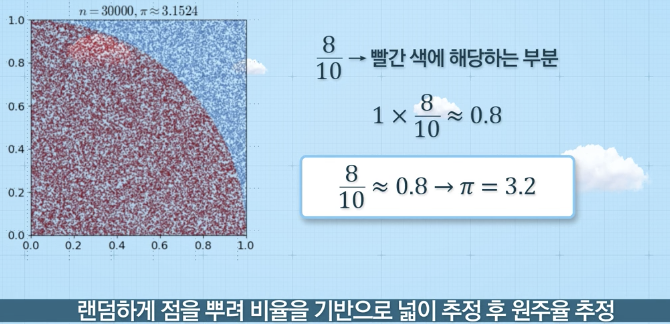
- 랜덤하게 점을 뿌려서 점의 수의 비율로 넓이를 추정하는 방법
- 전체 점 개수 대비 도형 안의 점 개수 비율 추정
- 추정한 비율을 가지고 도형의 넓이 추정 가능
몬테칼로 방법
- 실제 시도하여 얻어진 데이터를 바탕으로 가치함수/행동가치함수 값 추정
- 에이전트가 정책에 따라 환경과 상호작용을 통해 상태, 행동, 보상 획득 (하나의 점)
- 에피소드로부터 직접적으로 가치함수 학습
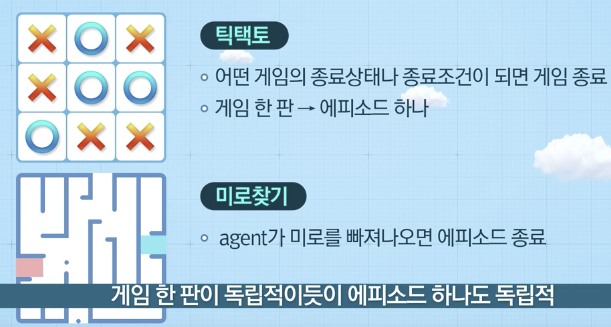
에피소드
- 일련의 상호작용은 에피소드 단위로 구분 가능
- 임의의 종료상태(terminal state)에서 종료함
- 각 에피소드는 독립적
예시 (게임)


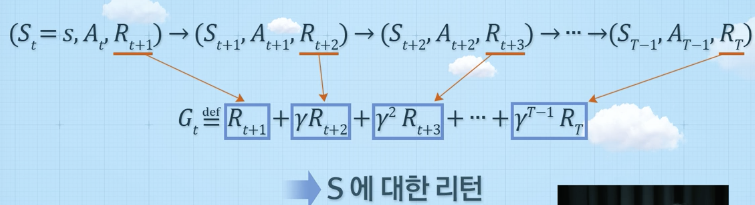
에피소드의 리턴
- 현재시점부터 에피소드 종료시까지의 보상들의 합 --> 누적보상

연속 작업 (Continuing Task)
- 에피소드들로 자연스럽게 분할이 어려운 경우
- 프로세스가 무한 지속
- 예시 (주가변동)
- 오늘 장의 종점이 다음 날의 어떤 장의 시점과 일치 --> 프로세스 무한 지속
- 연속 작업의 리턴
- 보상 합이 무한대로 발산 가능
- 감가율에 대한 도입 필요
몬테칼로 정책 평가
- 강화학습에서 MC를 이용하는 경우, 종결 상태까지 완료된 에피소드에 한정하여 사용
- 연속 작업에서 MC 방법 적용은 가능함
- 일반적으로 종결 상태가 존재하는 에피소드에 한정하여 사용

몬테칼로 정책 평가 방법



예시 (First-visit MC)





예시 (Every-visit MC)

점진적 몬테칼로 정책 평가
- 기존 가치함수를 기반으로 추정값 업데이트
- 최근 가치함수에 대한 추정치만 필요 --> 효율적 관리
- 새로운 에피소드 정보 값으로만 계속 업데이트 가능
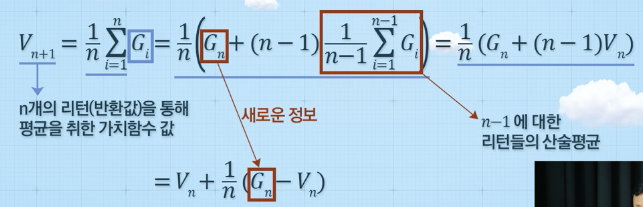

- 처음부터 새로운 에피소드까지 전체로부터 가치함수 추정
- 매 에피소드에 대한 정보 필요 --> 비효율적
몬테칼로 방법에 따른 가치함수 업데이트 방법

몬테칼로 기반 정책 개선
- 가치함수 값 추정만으로는 어려움
- 행동가치함수 필요
- 에피소드의 모든 상태에 대한 리턴 값 산출 가능
- 리턴 값 기준으로 상태에 대한 가치함수 업데이트



참고

Data Scientist, Data Analyst