인프런 권철민님 강의 정리
Section1: 파이썬 기반의 머신러닝과 생태계 이해
머신러닝의 개념
머신러닝, 왜 필요한가?
- 복잡한 문제를 데이터를 기반으로 숨겨진 패턴을 인지해 해결한다.
- 더 빠른 결정 및 의사결정이 가능
- 데이터에 감춰진 인사이트를 발굴해 이익으로 연결됨
머신러닝 분류
- 지도학습: 분류, 회귀, 시각/음성 감지/인지
- 비지도학습: 군집화/차원축소
- 강화학습
머신러닝의 단점
- 데이터에 의존적이다 (Garbage in, Garbage out)
- 단순히 편향된 많은 데이터가 아닌, 다양한 데이터가 필요함
- 과적합 문제
- 블랙박스
- 데이터만 넣는다고 자동으로 최적된 결과를 주지 않음
- 데이터 특성 파악 및 최적 알고리즘과 파라미터를 구성할 수 있는 능력 필요
Numpy (기초 내용 pass)
인덱싱 유형

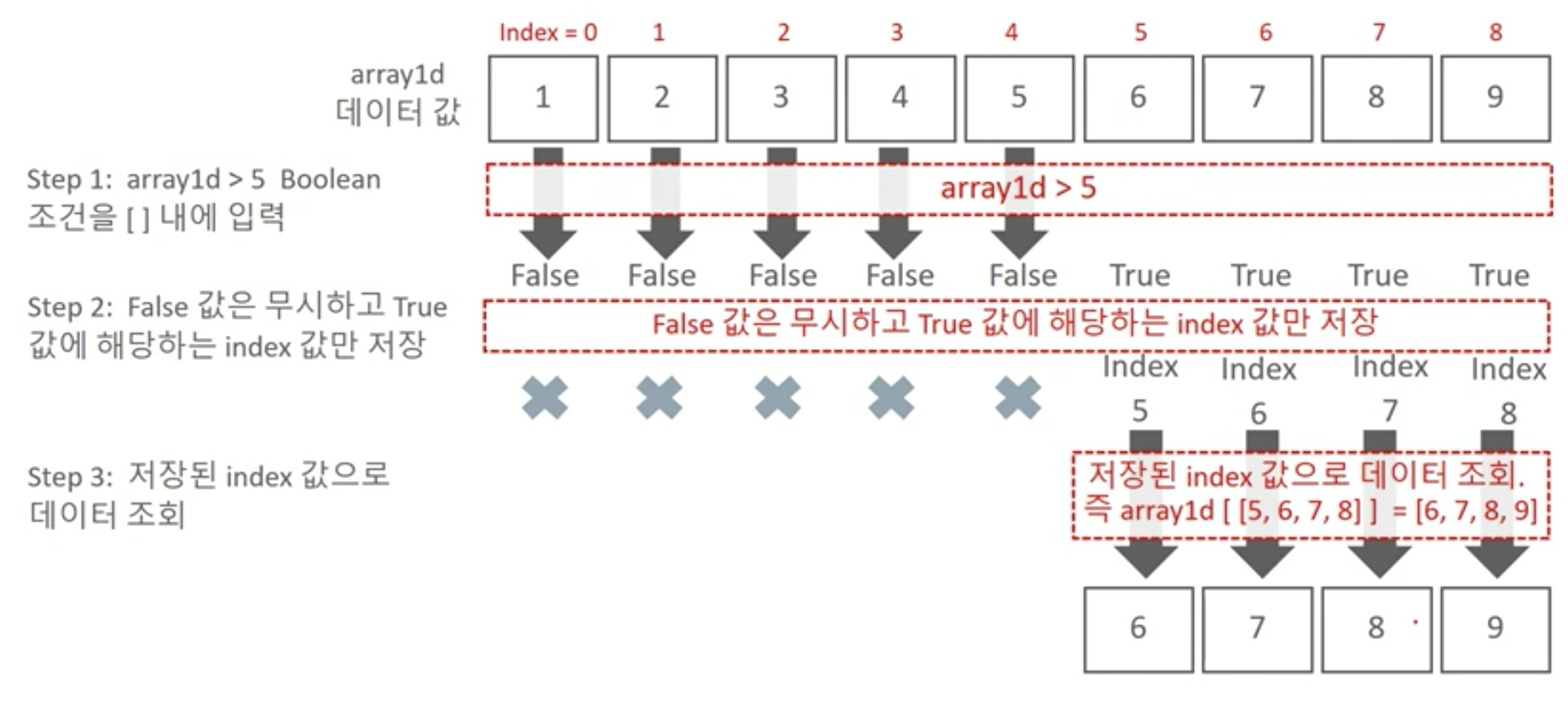
불린 인덱싱의 메커니즘
정렬
- np.sort: 원행렬은 유지한 채, 정렬된 행렬을 반환 (= sorted)
- ndarray.sort: 원행렬이 정렬된 형태의 index를 반환
Pandas (기초 내용 pass)
- index: DB의 PK와 비슷하지만, 식별용으로만 쓰임
Missing data
- isna(): NaN인지 파악 후 True/False 반환
- fillna(): 주어진 값으로 대체

Data Scientist, Data Analyst