인프런 권철민님 강의 정리
Section2: 사이킷런으로 시작하는 머신러닝
Scikit Learn
- 파이썬 머신러닝 라이브러리
- 쉽고 효율적인 API 제공
용어
- 피처: 데이터 세트의 일반 속성
- 레이블/클래스: 분류에 쓰이는 타겟 값
사이킷런 기반 Framework
- sklearn.datasets: 예제 데이터 세트
- sklearn.model_selection: 데이터 분리, 검증, 파라미터 튜닝 (Grid Search)
- sklearn.preprocessing: 데이터 전처리(인코딩, 정규화, 스케일링)
- sklearn.feature_selection: 알고리즘에 큰 영향을 미치는 피처를 우선순위 대로 셀렉트
- sklearn.feature_extraction: 텍스트 데이터나 이미지 데이터의 벡터화된 피처를 추출하는데 사용 (Count Vectorizer, Tf-Idf Vectorizer)
- sklearn.decomposition: 차원 축소(PCA, NMF)
- sklearn.metrics: 평가 지표 (Accuracy, Precision, Recall, ROC-AUC, RMSE)
- sklearn.ensemble: 앙상블 알고리즘 (Random Forest, AdaBoost, GradientBoosting)
- sklearn.linear_model: 선형 모델 (regression, Ridge, Lasso, Logistic regression, SGD)
- sklearn.naive_bayes: 나이브베이즈 알고리즘
- sklearn.neighbors: 최근접 이웃 알고리즘 (KNN)
- sklearn.svm: 서포트 벡터 머신 알고리즘
- sklearn.tree: 의사 결정 트리 알고리즘
- sklearn.cluster: 비지도 클러스터링 알고리즘 (DBSCAN, K-means)
- sklearn.pipeline: 파이프라인 유틸리티 제공
학습 데이터, 테스트 데이터분리
- sklearn.model_selection의
train_test_split()함수- test_size: 테스트 크기 (default 0.25)
- train_size: 훈련 데이터 크기 (잘 안씀)
- shuffle: 데이터를 분리 전에 섞을 것인지 결정 (default True)
- random_state: 동일한 데이터를 생성하기 위한 난수 값
- Numpy ndarray, Pandas DataFrame/Series로 분할 가능
교차검증
- 학습 데이터를 다시 분할하여 학습 데이터와 학습된 모델의 성능을 일차 평가하는 검증데이터로 나눔

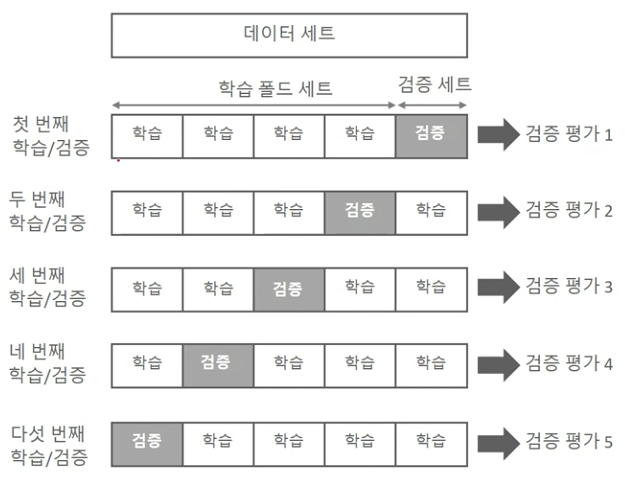
K-Fold 교차 검증
- K개의 데이터 폴드 세트를 만들어서 K번 만큼 학습과 검증을 수행하는 방법
Stratified K-Fold
- 불균형한 분포도를 가진 레이블을 가졌을 때 사용
- 학습데이터와 검증 데이터 세트가 가지는 레이블 분포도가 유사하도록 추출
- Ex. Original(O:700, X:300) --> Train(O:490, X:210), Validation(O:210, X:90)
cross_val_score
- 폴드 세트 추출, 학습/예측, 평가를 한번에 수행
- 내부적으로 StratifiedKFold를 사용함
하이퍼 파라미터 튜닝
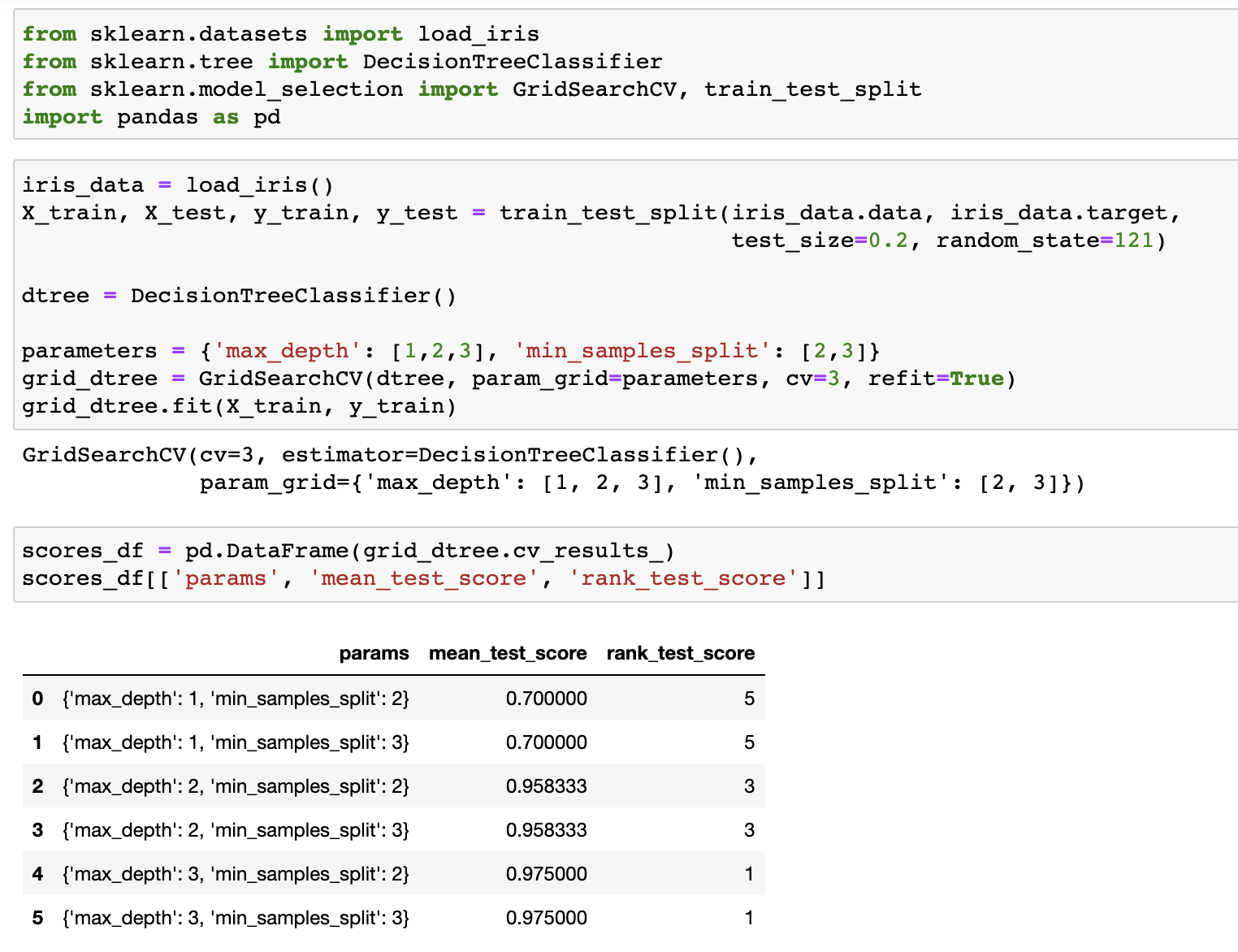
GridSearchCV
- 하이퍼 파라미터를 순차적으로 입력하면서, 최적의 파라미터를 도출할 수 있는 방안을 제공
- 학습/검증 횟수: 파라미터 순차 적용횟수(하이퍼 파라미터 조합 수) * cv 세트 수 (k-fold)
- 파라미터
- estimator: classifier or regressor
- param_grid: 튜닝할 파라미터 딕셔너리
- ex. {'max_depth':[1,2], 'min_samples_split':[2,3]}
- scoring: 예측 성능 평가 지표
- cv: 교차 검증을 위해 분할되는 학습/테스트 세트 개수
- refit: 최적의 하이퍼 파라미터를 찾은 뒤 해당 파라미터로 재학습 시킬 것인지 여부
- 실습

데이터 전처리
- 데이터 클린징
- 결손값 처리(Null/NaN)
- 데이터 인코딩 (레이블, 원-핫)
- 데이터 스케일링
- 이상치 제거
- Feature 선택/추출/가공
레이블 인코딩
- 카테고리 피처를 코드형 숫자값으로 변환하는 것
- 변환된 코드가 숫자이다 보니, 원치 않게 비교가 된다.

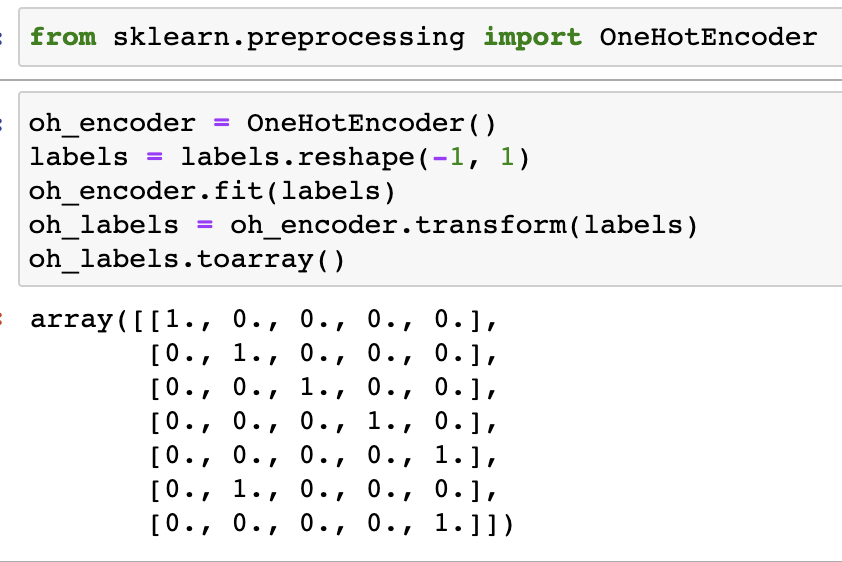
One-hot 인코딩
- 해당되는 피처의 칼럼만 1 나머지는 0으로 표시
- 피처의 개수 만큼 칼럼이 생김
- pd.get_dummies(DataFrame)

피처 스케일링
표준화
- 데이터의 피처가 평균이 0, 분산이 1인 정규분포를 가진 값으로 변환
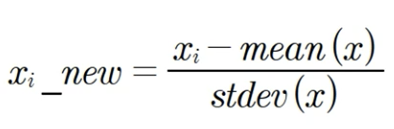
정규화
- 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 개념
- 0~1로 값을 변환
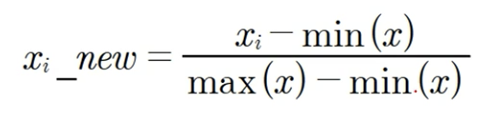

Data Scientist, Data Analyst