토이 프로젝트를 진행하면서 발생했던 문제에 대한 본인의 생각과 고민을 기록한 글입니다.
기술한 내용이 공식 문서 내용과 상이할 수 있음을 밝힙니다.
Mysql 공식문서 참고: https://dev.mysql.com/doc/refman/8.0/en/
Postgre 공식문서 참고: https://www.postgresql.org/docs/
PostgreSQL로 데이터 10만건, 100만건을 생성하여 LIKE, Full Text Search 검색 성능을 비교해보려고 한다.
10만건, 100만건으로 설정한 이유?
일반적으로, LIKE 연산자는 패턴 매칭을 위해 주로 사용되며, 특히 작은 데이터셋에서는 효율적이다. 그러나 데이터의 크기가 클수록 (특히 10만건, 100만건 그 이상) 그 성능은 급격히 저하된다. LIKE는 각 행을 개별적으로 검사해야 하기 때문에, 데이터가 많아질수록 처리 시간이 길어질거라 생각이 들었다.
반면에, Full Text Search는 전문 검색을 위해 설계되었고, 대량의 데이터에 대한 검색을 빠르게 수행할 수 있다. 이는 검색어를 토큰화하고, 이 토큰들을 인덱스화하여 검색을 빠르게 수행하기 때문이다.
추가로, 100, 1000, 10000건을 사전에 테스트 해본 결과 비등하거나, LIKE가 조금 더 빨랐다.
대용량 데이터 생성하기
사실 처음에는 for문으로 10만, 100만, 1000만을 반복해서 객체를 만들면 될거라 생각을 했다. 틀린 방법은 아니지만, 테스트를 위한 데이터 준비 시간이 길었다.
따라서, 벌크 연산을 통해 Batch Size를 나누어 DB에 데이터를 생성해보는 방법을 떠올렸다.
JPA를 사용하여 벌크 연산
JPA는 엔티티의 생명주기를 관리하며, 연관된 객체들을 함께 로딩하고, 변경 감지 등의 작업을 수행한다. 각 엔티티 객체를 개별적으로 관리하므로, 일반적으로 영속성 컨텍스트(Persistence Context)가 1:1로 생성된다.
대량의 데이터를 처리할 때 JPA는 각각의 엔티티에 대해 개별적인 SQL을 발행 이 비용은 상당히 커질 수 있기에 추가적인 메모리 사용과 CPU 사용으로 이어진다.
int batchSize = 100;
for (int i = 0; i < 100_000; i++) {
MenuReview review = new MenuReview(...);
menuReviewRepository.save(review);
if (i % batchSize == 0) { // 100건마다 플러시와 클리어를 수행
entityManager.flush();
entityManager.clear();
}
}JDBC를 사용하여 벌크 연산
벌크 연산을 수행할 때는 영속성 컨텍스트를 우회하여 직접 쿼리를 실행하는 방법이 낫다고 생각했다.
JDBC 템플릿을 이용하면 SQL을 직접 제어할 수 있어, 벌크 연산을 효율적으로 처리하는 데에 더 적합하고 검색의 성능을 비교하기 위함이므로 영속성으로 관리할 필요가 없기에 JDBC를 활용하였다.
JDBC는 적은 수의 SQL 쿼리를 실행하게 되므로, 네트워크 비용을 줄이고 SQL 실행 비용을 최소화하여 전체적인 성능을 향상시킬 수 있을 것이다.
@Configuration
public class SecondConfig {
public static final String ENTITY_MANAGER_BEAN_NAME = "twoDBEntityManager";
private static final String DATASOURCE_BEAN_NAME = "twoDataSource";
{...}
@Bean
public JdbcTemplate postgresJdbcTemplate(@Qualifier(DATASOURCE_BEAN_NAME) DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
}JdbcTemplate 객체를 Spring Bean으로 등록하였다. Mysql과 PostgreSQL 두개의 DB를 사용하고 있어 각각의 PrimaryConfig, SecondConfig로 구성되어 있다.
@Repository
public class MenuReviewJdbcPostgresRepository implements MenuReviewJdbcRepository {
private final JdbcTemplate jdbcTemplate;
private final int batchSize = 1000;
public MenuReviewJdbcPostgresRepository(@Qualifier("postgresJdbcTemplate") JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
@Transactional("twoDBTransactionManager")
public void saveAll(List<MenuReview> items, Long memberId, Long menuId) throws IOException {
List<MenuReview> subItems = new ArrayList<>();
for (MenuReview item : items) {
subItems.add(item);
if (subItems.size() % batchSize == 0) { ------------> (1)
batchInsert(subItems, memberId, menuId);
subItems.clear();
}
}
if (!subItems.isEmpty()) { ------------> (2)
batchInsert(subItems, memberId, menuId);
}
}
private void batchInsert(List<MenuReview> subItems, Long memberId, Long menuId) {
jdbcTemplate.batchUpdate(
"INSERT INTO menu_review (id, comments, create_at, update_at) VALUES (?, ?, ?, ?)",
subItems,
batchSize,
(ps, argument) -> {
ps.setLong(1, argument.getId());
ps.setString(2, argument.getComments());
ps.setTimestamp(3, Timestamp.from(Instant.now()));
ps.setTimestamp(4, Timestamp.from(Instant.now()));
}
);
}
}JdbcTemplate를 주입받는 부분에서 @Qualifier 어노테이션을 사용하였는데, 이는 같은 타입의 여러 Bean이 존재할 경우 원하는 Bean을 명확히 지정해주기 위해 사용하였다. (이후 MySQL도 Jdbc로 테스트 진행 계획)
MenuReviewJdbcPostgresRepository의 saveAll 메소드에서는 주어진 데이터를 batchSize만큼 분할하여 batchInsert 메소드를 호출하고, batchInsert 메소드에서는 JdbcTemplate의 batchUpdate 메소드를 사용하여 한 번에 여러 개의 데이터를 데이터베이스에 삽입하였다.
(1) 코드: 반복문을 통해 items의 모든 아이템을 subItems에 추가하면서, subItems의 크기가 batchSize와 같아질 때마다 batchInsert를 호출하여 저장한다.
(2) 코드: items의 크기가 batchSize의 배수가 아닐 경우 마지막에 남는 아이템들이 처리되지 않을 수 있으므로, 반복문이 끝난 후에 subItems에 아이템이 남아있는지 확인하고 남아있다면 batchInsert를 한 번 더 호출하여 모든 데이터를 정확하게 저장한다.
PostgreSQL FTS 설정 적용
- to_tsvector: DB에
저장된 텍스트 데이터를 토큰화하고, 이를 검색 가능한 형태로 변환한다. 이 과정에서 불용어를 제거하고, 단어를 어간으로 변환한다. - plainto_tsquery:
사용자가 검색어로 입력한 텍스트를 토큰화하고, 이를 tsvector와 비교 가능한 형태인 tsquery로 변환한다. 이 과정에서도 불용어를 제거하고, 단어를 어간으로 변환한다. - GIN 인덱스: GIN (Generalized Inverted Index)는 각 토큰에 대한 포인터를 저장하므로, 특정 토큰을 가진 데이터를 찾을 때 모든 데이터를 살펴보지 않고도 해당 토큰을 가진 데이터를 빠르게 찾을 수 있다.
포인터? 데이터의 특정 위치를 참조하는 메커니즘을 의미한다. GIN 인덱스는 토큰과 키워드가 포함된 행의 위치 정보를 매핑하여 저장한다. DB Context에서 이 포인터는 인덱스 항목이 실제 데이터 행을 참조하는 방법을 가리킨다.
- @@ 연산자: @@ 연산자는 tsvector와 tsquery 사이의 텍스트 검색 조건을 검사한다.
GIN 인덱스 적용
메뉴 리뷰 검색이 목적이므로 menu_review 테이블에 인덱스를 생성한다.
yunni_bucks_traffic=# CREATE INDEX comments_idx ON menu_review USING GIN(to_tsvector('english', comments));
CREATE INDEX
yunni_bucks_traffic=#
SELECT
tablename,
indexname,
indexdef
FROM
pg_indexes
WHERE
tablename = 'menu_review';
tablename | indexname | indexdef
-------------+------------------+---------------------------------------------------------------------------------------------------------
menu_review | comments_idx | CREATE INDEX comments_idx ON public.menu_review USING gin (to_tsvector('english'::regconfig, comments))
menu_review | menu_review_pkey | CREATE UNIQUE INDEX menu_review_pkey ON public.menu_review USING btree (id)설정 조회
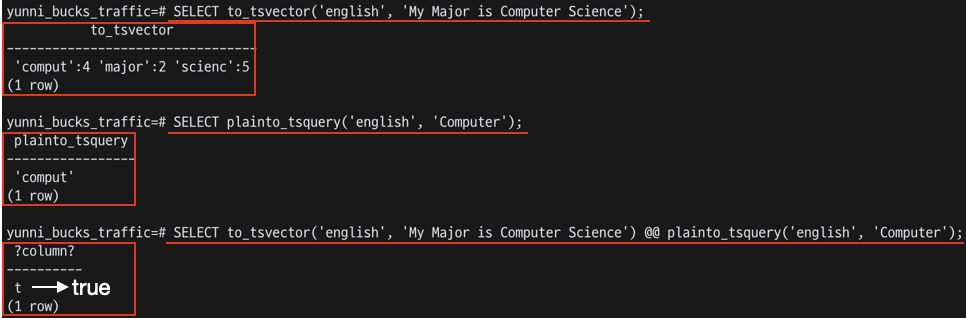
토큰을 나누었는데 My Major is Computer Science가 아니라 comput, major, sciec로 나왔다.
이는 어간 추출로 단어의 끝 부분이 제거되므로, 여러 형태의 단어를 동일하게 취급할 수 있다.
예를 들어, computers, computer, computing 등의 단어는 모두 comput라는 어간을 가지고 있다.
어간 추출을 통해 이러한 단어들을 comput라는 하나의 어간으로 취급하면, 이 단어들이 같은 문맥에서 사용된 것으로 인식할 수 있게 된다.
SELECT to_tsvector('english', 'My Major is Computer Science');쿼리의 결과에서 comput와 scienc라는 표현은 각각 computer와 science라는 단어가 어간 추출을 통해 변환된 결과인 것이다.
결과값의 ':4'와 ':5'는 해당 단어가 원래 문자열에서 몇 번째 위치에 있었는지를 나타낸다.
to_tsvector 함수를 사용할 때 불용어 제거를 자동으로 수행한다.
이 때문에 My Major is Computer Science라는 문장에서 is, My와 같은 불용어가 to_tsvector 함수의 결과에서 제외된 것이다.
Spring JPA Repository Query 적용
public interface JpaPostgresSQLMenuReviewRepository extends JpaRepository<MenuReview, Long> {
@Query(value = "SELECT * FROM menu_review WHERE comments LIKE %:keyword%", nativeQuery = true)
List<MenuReview> findMenuReviewByCommentsContainingWithQuery(@Param("keyword") String keyword);
@Query(value = "SELECT * FROM menu_review WHERE to_tsvector('english', comments) @@ plainto_tsquery('english', ?)", nativeQuery = true)
List<MenuReview> findMenuReviewByCommentsContainingOnFullTextSearchWithQuery(@Param("keyword") String keyword);
}yml에서 spring.datasource.hibernate.dialect:org.hibernate.dialect:PostgreSQLDialect를 설정하여 to_tsvector과 plainto_tsquery를 natvieQuery를 적용하였다.
테스트
1차 테스트(DataFaker로 100만개 벌크연산)
@PostConstruct
public void init() throws IOException {
Faker faker = new Faker();
for (int i = 0; i < 1_000_000; i++) {
String comments = faker.lorem().sentence(); // 랜덤한 문장 생성
MenuReview menuReview = MenuReview.builder()
.id((long) (i + 1))
.comments(comments)
.member(member)
.menu(menu)
.now(now())
.build();
menuReviews.add(menuReview);
}
menuReviewJdbcPostgresRepository.saveAll(menuReviews, member.getId(), menu.getId());
}
@Test
@Rollback(value = false)
void 대용량데이터FullTextSearch로검색MySQL() {
System.out.println("크기: " + menuReviews.size());
String keyword = "%" + "Rice" + "%";
long startTime2 = System.nanoTime();
List<MenuReview> menuReviewList2 = menuReviewRepository.findMenuReviewByCommentsContainingWithQuery("Rice");
long endTime2 = System.nanoTime();
double duration2 = (endTime2 - startTime2) / 1_000_000.0; // 나노초를 밀리초로 변환 후, 밀리초를 초로 변환
System.out.println("%LIKE% 실행 시간: " + duration2 + " ms");
long startTime1 = System.nanoTime();
List<MenuReview> menuReviewList1 = menuReviewRepository.findMenuReviewByCommentsContainingWithFTS("Rice");
long endTime1 = System.nanoTime();
double duration1 = (endTime1 - startTime1) / 1_000_000.0; // 나노초를 밀리초로 변환 후, 밀리초를 초로 변환
System.out.println("Full Text Search 실행 시간: " + duration1 + " ms");
assertThat(menuReviewList1.size()).isGreaterThan(0);
assertThat(menuReviewList2.size()).isGreaterThan(0);
System.out.println("Full Text Search 결과 크기: " + menuReviewList1.size());
System.out.println("%LIKE% 결과 크기: " + menuReviewList2.size());
}이렇게 테스트를 했을 때, 아래와 같은 결과가 나온다.
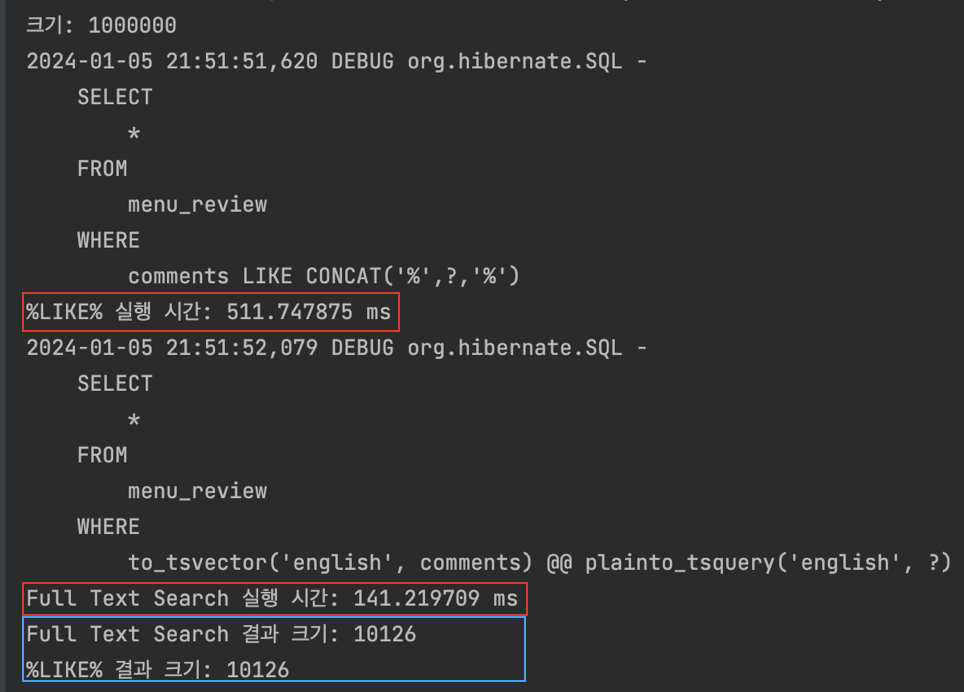 FTS가 약 3.8초 성능이 올라갔다고 볼 수 있지만, Full Text Search가 실행될 때, 데이터베이스는 이미 %LIKE% 검색을 통해 일부 데이터를 캐시에 로드했을 가능성이 있다.
FTS가 약 3.8초 성능이 올라갔다고 볼 수 있지만, Full Text Search가 실행될 때, 데이터베이스는 이미 %LIKE% 검색을 통해 일부 데이터를 캐시에 로드했을 가능성이 있다.
데이터베이스 시스템은 자주 접근하는 데이터를 빠르게 가져오기 위해 캐시를 사용한다. 따라서, 캐시는 메모리에 저장되므로 디스크에서 데이터를 읽는 것보다 훨씬 빠르다. 그래서 처음 %LIKE% 검색을 실행할 때는 디스크에서 데이터를 읽어야 하지만, 그 다음에 Full Text Search를 실행할 때는 캐시에서 데이터를 읽을 수 있으므로 더 빠를 수 있기에 테스트를 분리해서 똑같은 데이터로 다시 테스트 해보았다.
2차 테스트(DataFaker로 100만개 벌크연산)
- 10만개 데이터 (230ms 단축)
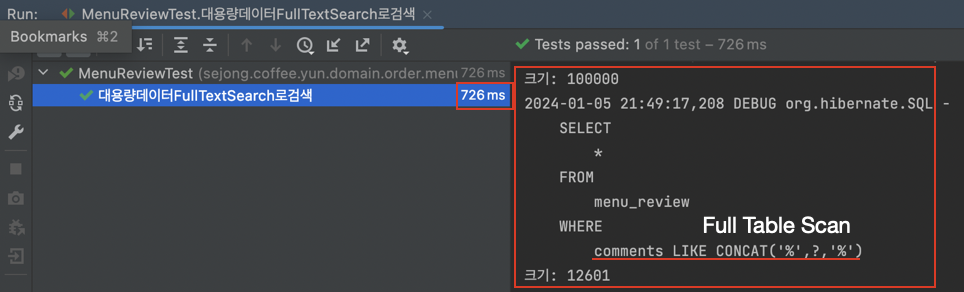
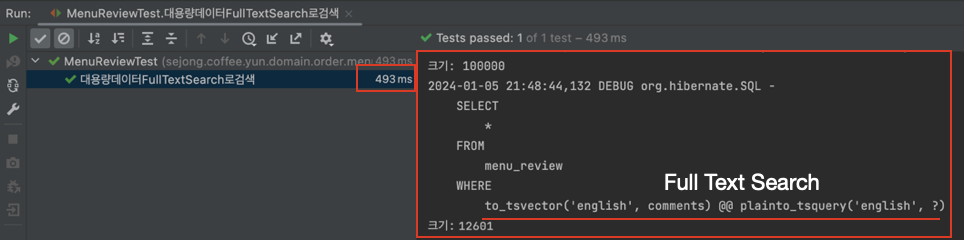
- 100만개 데이터 (7.7s 단축)
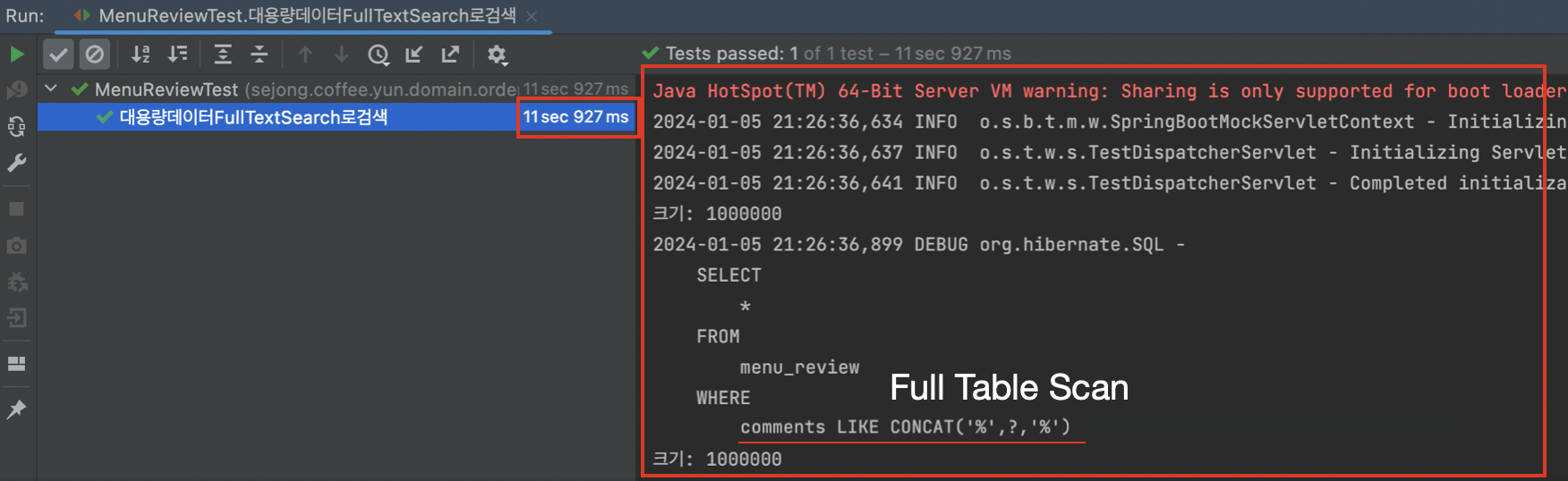
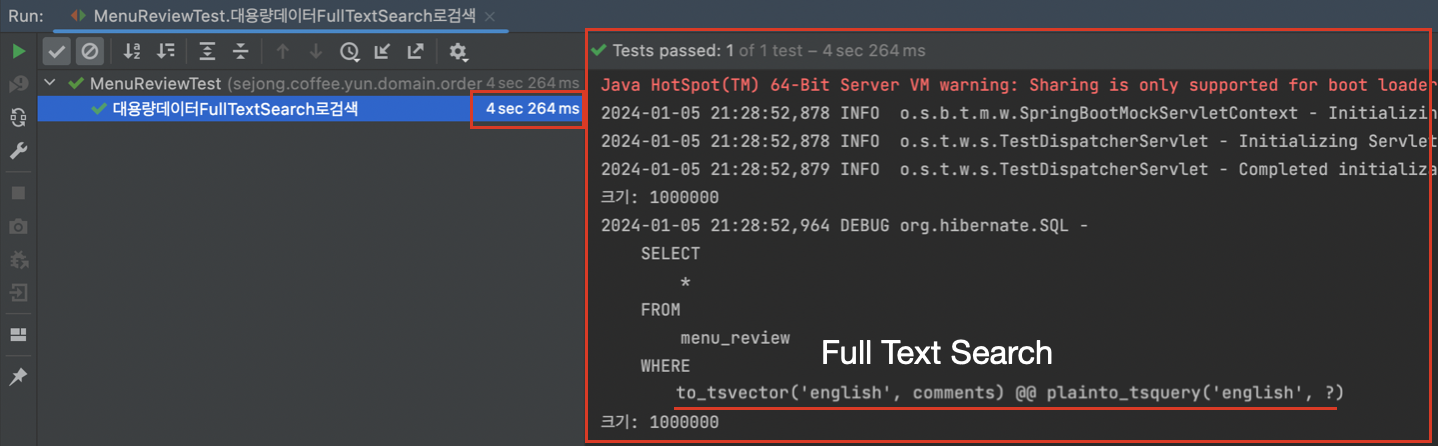
GIN 인덱스가 적용이 되어 전문검색이 된걸까?
postgreSQL에서 인덱스를 적용하긴 했지만 테스트에서 검색쿼리를 실행했을 때 인덱싱검색이 된건지 의문이 들었다. 실행계획으로 인덱싱이 적용된건지 알 수 있다고 한다.
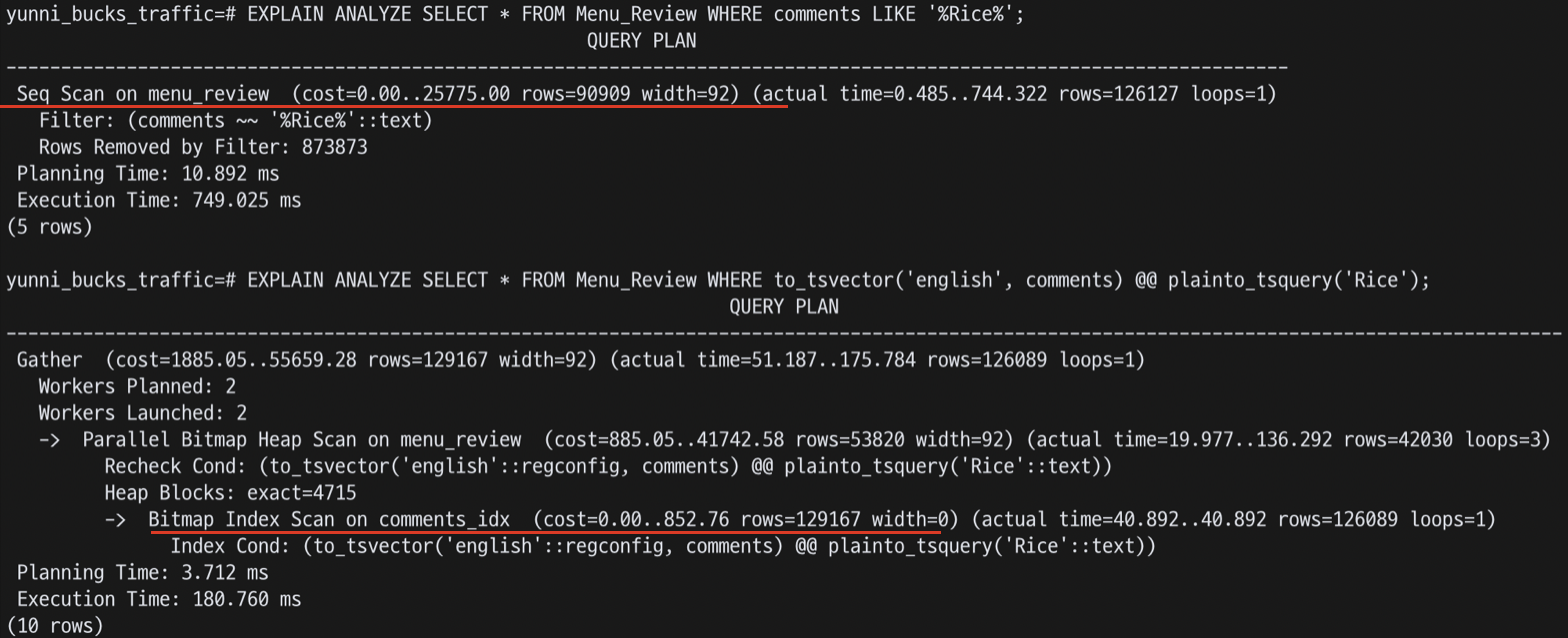 두 실행 계획의 주요 차이점은 Seq Scan과 Parallel Bitmap Heap Scan이 사용되었다는 점이다.
두 실행 계획의 주요 차이점은 Seq Scan과 Parallel Bitmap Heap Scan이 사용되었다는 점이다.
Seq Scan: LIKE 쿼리가 인덱스를 사용하지 않고 테이블의 모든 행을 순차적으로 스캔한다.
Bitmap Index Scan on comments_idx: comments_idx 인덱스를 사용하여 검색하는 작업이다. 인덱스 조건(Index Cond)은 사용된 전문 검색 조건이며, 이 작업은 actual time=40.892...40동안 수행했다는 의미라고 한다.
해결하지 못한 점
PostgreSQL를 사용한 이유는 아래와 같다.
1. 텍스트 검색 기능: tsvector와 tsquery 데이터 타입, 다양한 언어 지원, boolean 검색 연산자 포함
2. 성능: GIN, Gist 인덱스 등 다중값 컨테이너에 대한 검색을 효율적으로 지원한다. GIN 인덱스는 각 토큰에 대한 포인터를 저장하므로, 특정 토큰이 포함된 모든 행을 빠르게 찾을 수 있다.
이를 검색전용DB로 활용하여 Master-Slave구조로 이용하려 했다. 하지만, 서로 다른 시스템 간에 직접적인 Master-Slave 구조를 구성하는 것은 일반적으로 지원되지 않는다고 한다.
방법으로는 CDC, ETL 등 솔루션이 있다고는 하지만, 추가적인 복잡성과 오버헤드를 초래하며, 실시간 동기화를 보장하지 않을 수 있다고 한다.
따라서, MySQL을 하나 더 증설해서 검색 전용DB로 다시 한 번 구현해볼 예정이다.
