토이 프로젝트를 진행하면서 발생했던 문제에 대한 본인의 생각과 고민을 기록한 글입니다.
기술한 내용이 공식 문서 내용과 상이할 수 있음을 밝힙니다.
프로젝트의 목표는 최대 2천명의 트래픽에서도 충분히 버틸 수 있는 서버 환경을 구축하는 것이었다.
CI/CD를 구축한 상태에서 외부 톰캣 1대에서 시작해 Nginx로 로드밸런싱을 하여 Scale-out 과정에서 병목이 발생하는 구간과 성능 향상에 초점을 맞추어서 테스트 과정을 기록한다.
서버 스펙
AWS EC2
| Jenkins | Tomcat-1 | Tomcat-2 | SonarQube | Vault |
|---|---|---|---|---|
| t2.small(1vCPU 2GB) | t2.medium(2vCPU 4GB) | t2.small(1vCPU 2GB) | t2.medium(2vCPU 4GB) | t2.micro(1vCPU 1GB) |
Naver Cloud Platform
| nGrinder | Docker | Nginx |
|---|---|---|
| 4vCPU 8GB | 1vCPU 2GB | 1vCPU 2GB |
Jenkins
CI/CD의 중추 역할이다. TravisCI, gitAction 등 대체재가 있었지만, 점유율도 높고 Pipeline을 활용하여 통합, 배포를 제어할 수 있는 툴이자 StackOverflow에서 기술적 가이드가 잘 되어있어 CI/CD 툴로 채택했다.
처음에는 t2.micro를 썼는데 너무 느렸다. jenkins-plugin 설치 및 Credential 설정 등 메모리 사용량을 고려하여 t2.small로 scale-up을 하여 사용하였다. (페이지 전환도 꽤 빨라짐)
Nginx
로드 밸런싱을 하기 위해서는 필수이지 않을까 싶다. 여러 서버에 workload를 분산시켜 웹사이트, 애플리케이션들의 성능과 신뢰성을 향상하기 위한 인프라라고 보면 된다.
트래픽 부하에 따른 서버의 병목이 생기지 않을까 했는데, 결론부터 말하면 2000명까지 1vCPU 2GB로도 충분히 테스트가 가능했었다. (CPU 약 75% 사용)
Tomcat
이전 글에서 Tomcat을 배포하는 방법에 대해서 간단하게 기술하였다. 프리티어 부터 시작을 했었는데 WAR 파일 크기, 배포 시 애플리케이션 실행 메모리, 트래픽 부하를 고려했어야 했다.
이후, 병목이 발생(Read Time-Out)하면서 Scale-up과 Scale-out을 동시에 진행하면서 CPU와 Mem을 올렸다.
Ngrinder
테스트,모니터링 등 성능 지표에 대한 세부적인 테스트로 적합한 테스팅 툴인 것 같다.
처음엔 로컬(MacBook M1)에 설치할까 했지만, 사용자가 늘어남에 따라 테스트 툴 자체도 성능을 올려야 하지 않을까라는 생각에 클라우드로 띄웠다. (4vCPU 8GB정도 해야 2천명 언저리를 버티는거 같다. CPU 사용률이 97% 가까이 된다.)
사용자 테스트
nGrinder Test Script
Scale-Up: WAS 서버 유형 올려가며 점진적 테스트
1. Tomcat-1(1vCPU 1GB)
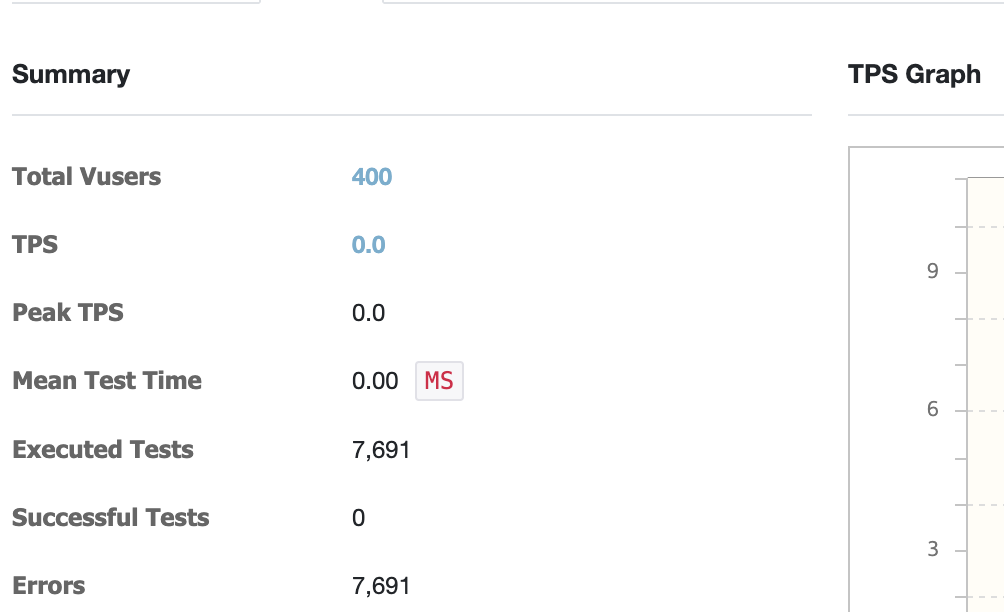
Tomcat-1 하나로 테스트를 진행했을 때 vUsers는 40명이 최대였다. TPS는 약 2배로 측정된다.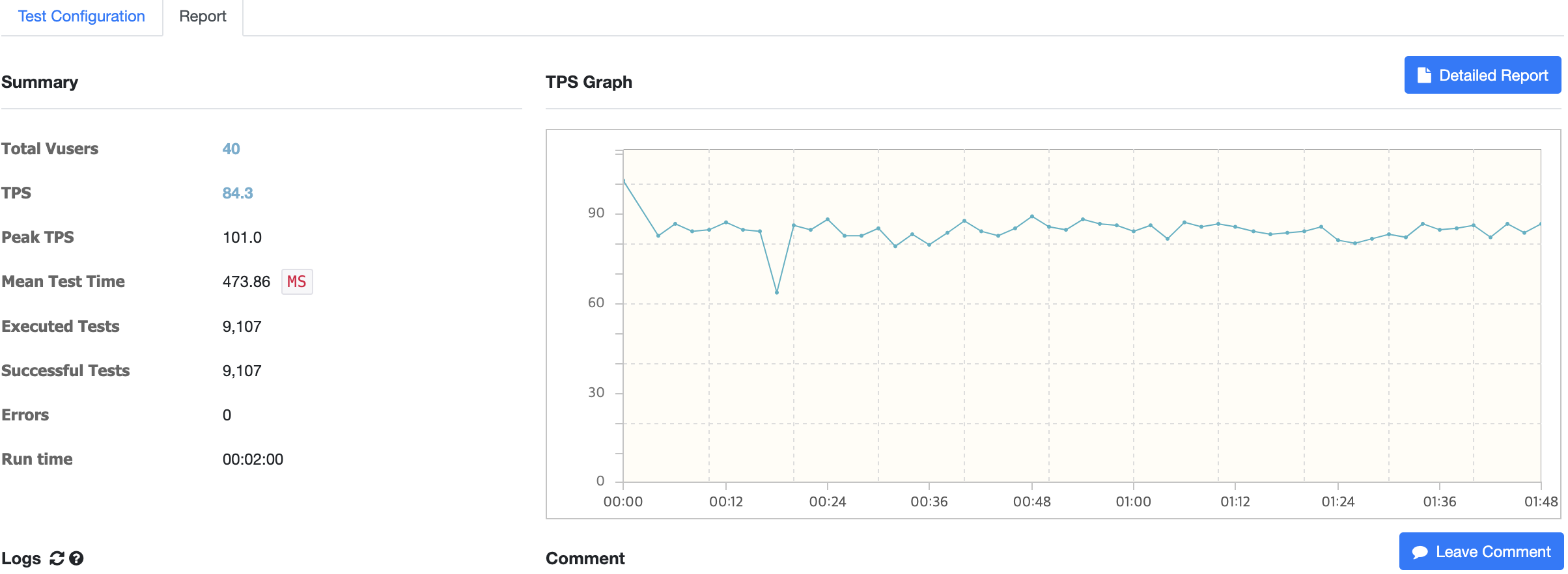 vUsers=400, Read Time Out 발생
vUsers=400, Read Time Out 발생
1-1. nGrinder(2vCPU 4GB)
CPU Usage를 봤을 때, nGrinder가 트래픽을 WAS 서버에 온전히 부하를 걸지 못하고 있는 것으로 보인다.

2. Tomcat-1(1vCPU 2GB)
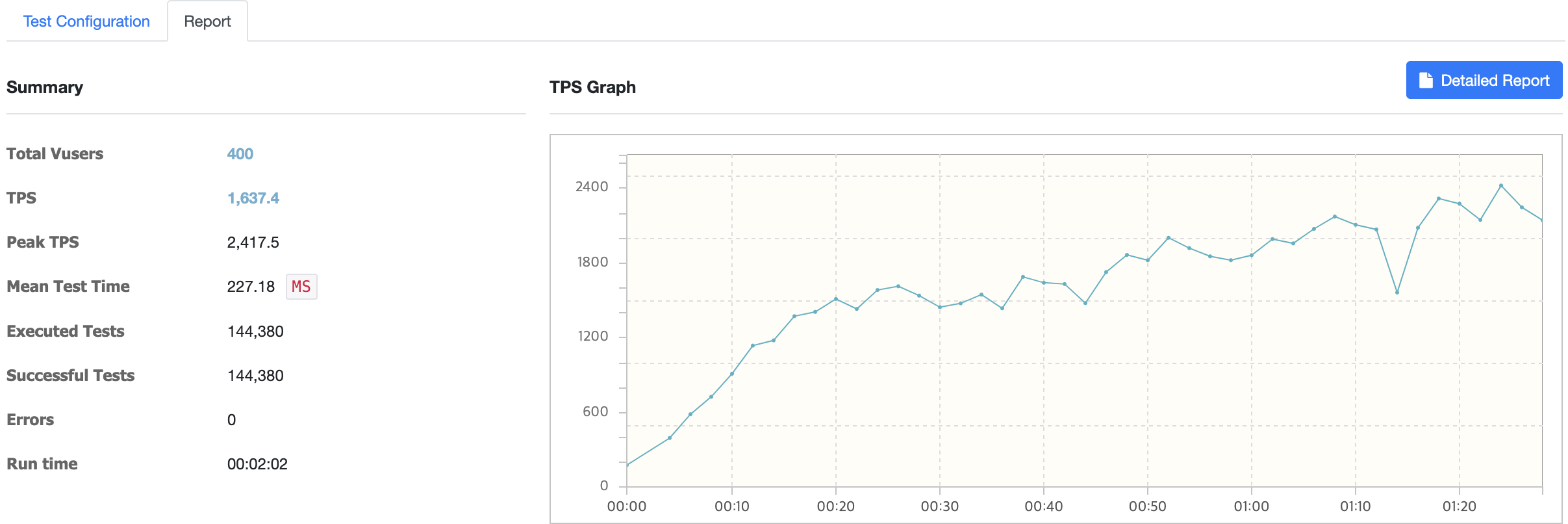 1vCPU 2GB t2.small에서는 redis-caching을 했기 때문에 단일 서버만으로도 vUsers 400에서 TPS가 1600까지 올랐다.
1vCPU 2GB t2.small에서는 redis-caching을 했기 때문에 단일 서버만으로도 vUsers 400에서 TPS가 1600까지 올랐다.
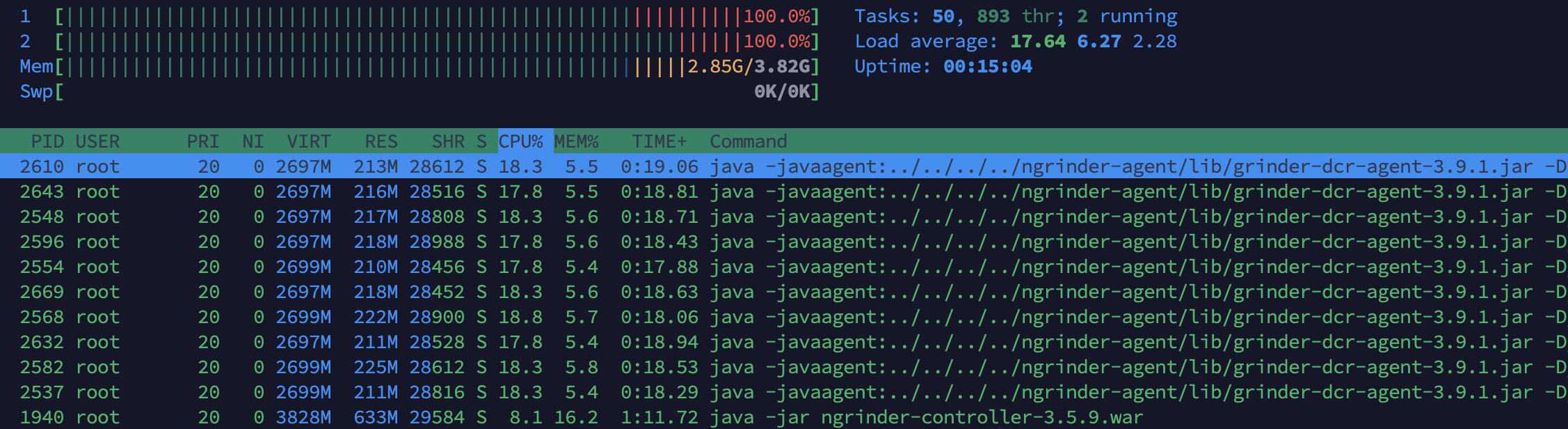 1000명은 테스트가 돌아가지 않았다. (병목현상 발생 후 Time-out)
1000명은 테스트가 돌아가지 않았다. (병목현상 발생 후 Time-out)
nGrinder CPU Usage는 100% / 100%대로 나온다. nGrinder의 서버 사양이 낮아 WAS 서버에 트래픽을 최대로 부하를 걸지 못하는 거 같다.
nGrinder → 4vCPU 8GB 변경
3. Tomcat-1(2vCPU 4GB)
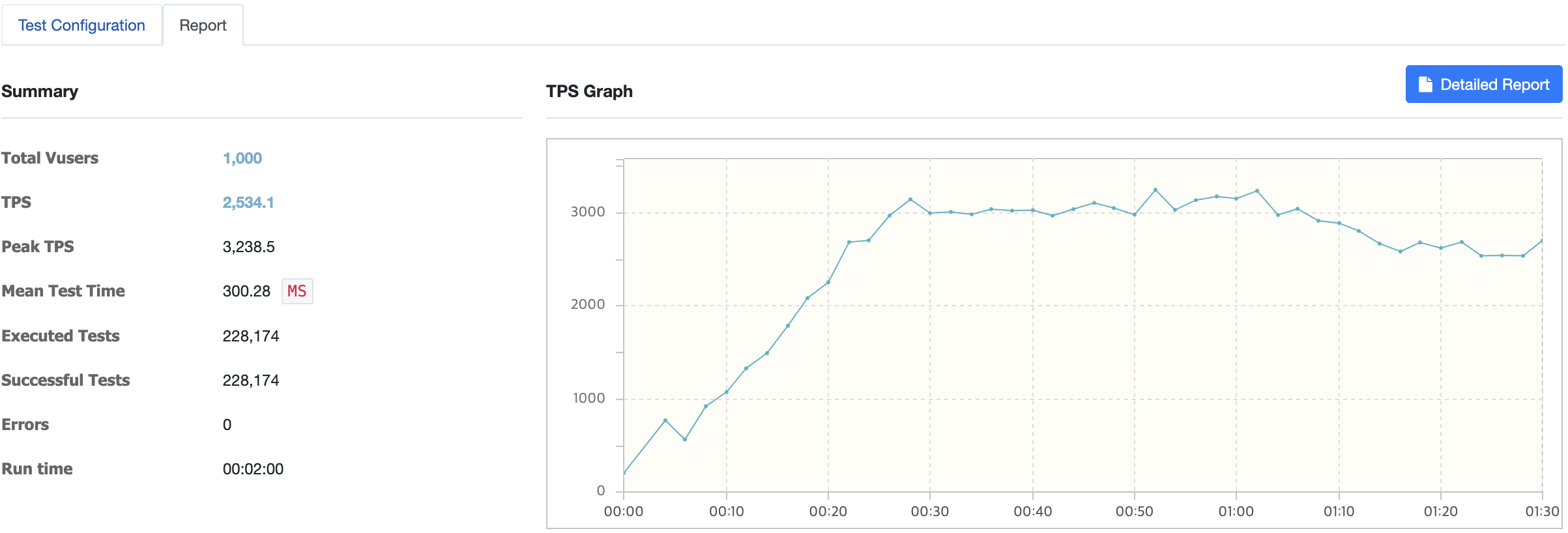 t2.medium으로 Scale-up하여 단일 WAS로 테스트를 진행한 1000명이다. 평균 TPS가 2530, Peak TPS는 약 3300까지 치솟았다. (Caching이 확실히 TPS가 높다.)
t2.medium으로 Scale-up하여 단일 WAS로 테스트를 진행한 1000명이다. 평균 TPS가 2530, Peak TPS는 약 3300까지 치솟았다. (Caching이 확실히 TPS가 높다.)
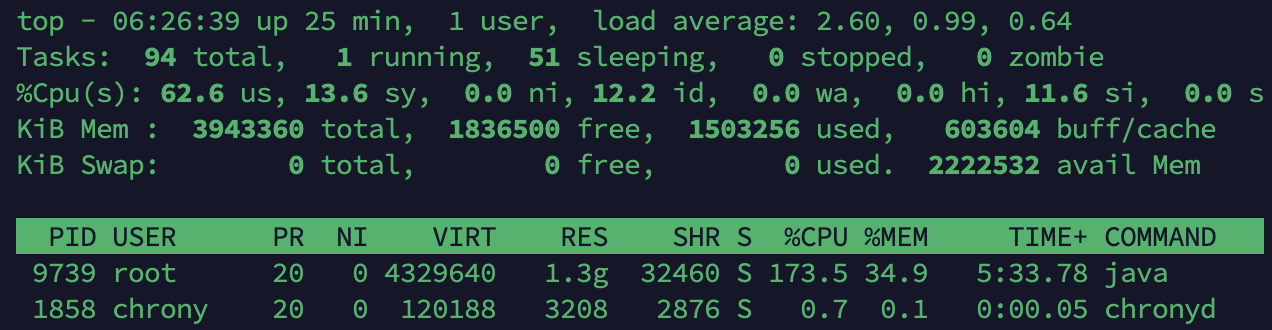 WAS CPU Usage도 약 170%정도로 적절하게 트래픽을 버티고 있다고 판단된다.
WAS CPU Usage도 약 170%정도로 적절하게 트래픽을 버티고 있다고 판단된다.
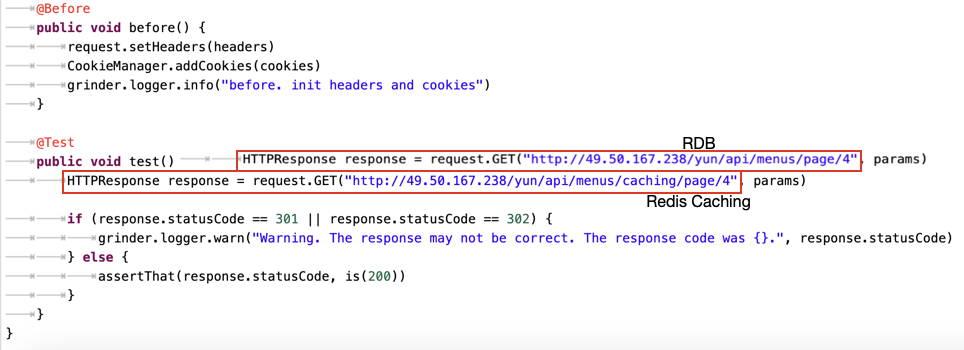
RDB는 어떨까?
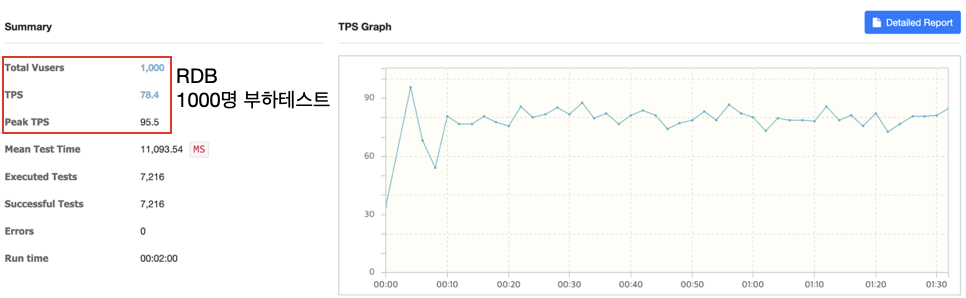 내 눈이 잘못된줄 알았다. 어떻게 이렇게 되지? Controller코드를 살펴보았다.
내 눈이 잘못된줄 알았다. 어떻게 이렇게 되지? Controller코드를 살펴보았다.
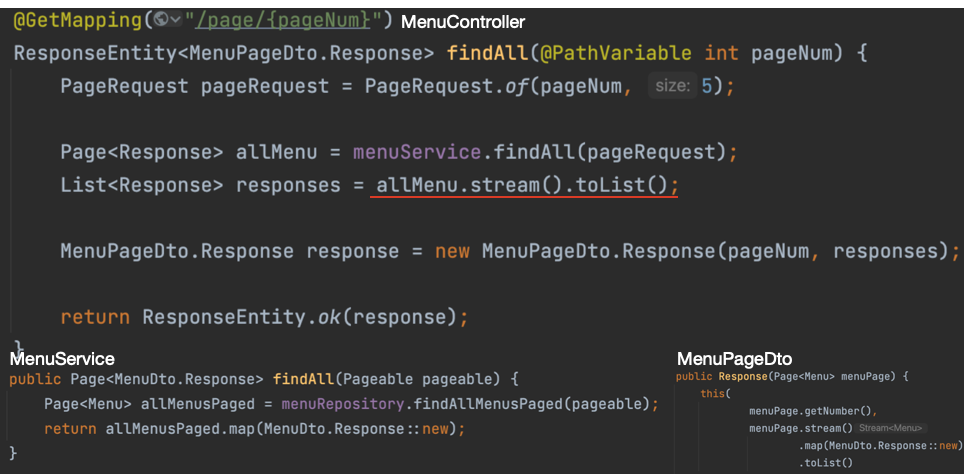
초기 코드에서는 컨트롤러에서 Page 객체를 List로 변환하는 과정에서 스트림 API를 사용했다. Java의 Stream 처리가 내부적으로 일정 부분 오버헤드를 가지고 있기 때문에, 특히 데이터가 많을 경우 성능 저하의 원인이 될 수 있었던 것 같다.
리팩토링 후
RDB로 API 호출 시 TPS는 1000~1100정도로 측정되었다. (MySQL 사용)
변경된 코드에서는 서비스 계층에서 직접 Page 객체를 MenuPageDto.Response 객체로 변환했다.
Page 인터페이스의 map 메서드는 내부적으로 페이징 처리된 데이터의 변환을 효율적으로 처리할 수 있도록 최적화되어 Stream 처리를 최소화하고, Page 인터페이스의 내장 메서드를 이용한 최적화된 변환 로직을 사용하였다.
Scale-Out: WAS 서버 늘려서 점진적 테스트
1000명부터는 본격적으로 Nginx를 통해 WAS 서버에 로드밸런싱을 하도록 서버 구조를 변경하였다.
1. Tomcat-1(1vCPU 2GB) + Tomcat-2(1vCPU 2GB)
WAS 서버는 둘다 t2.small로 1vCPU 2GB로 가중 라운드 로빈 (Weighted Round Robin)을 하였다. (weight 1:1 기준)
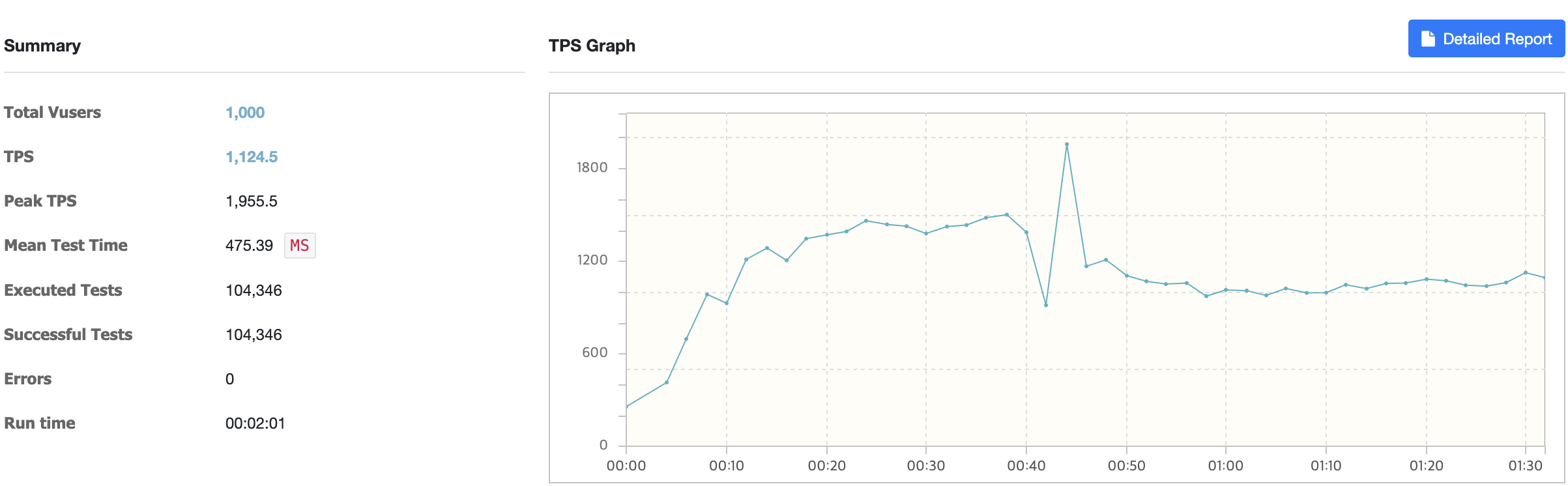
 성능이 단일 WAS 이상으로 나오지 않는다. Nginx가 문제인가?
성능이 단일 WAS 이상으로 나오지 않는다. Nginx가 문제인가? htop을 확인해보자.
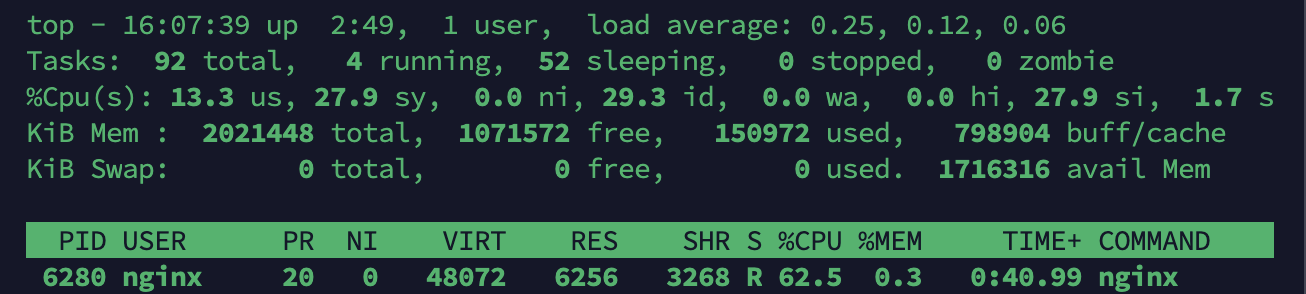 Nginx는 약 62%로 트래픽 분산을 적절히 잘 하고 있는 것 같다. t2.small 2대로 Scale-out시 vUsers 1000명은 무리인 것 같다. (WAS 서버 CPU Usage 90% 가까이 측정)
Nginx는 약 62%로 트래픽 분산을 적절히 잘 하고 있는 것 같다. t2.small 2대로 Scale-out시 vUsers 1000명은 무리인 것 같다. (WAS 서버 CPU Usage 90% 가까이 측정)
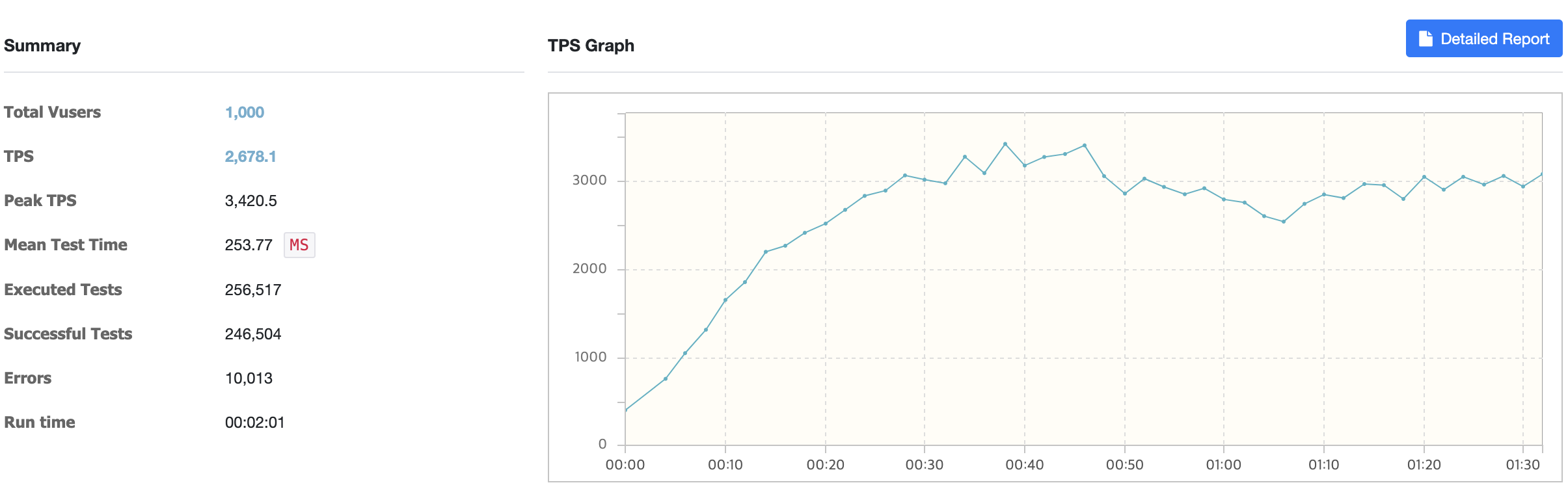
2. Tomcat-1(2vCPU 4GB) + Tomcat-2(1vCPU 2GB)
WAS 서버는 각각 t2.medium, t2.small로 가중 라운드 로빈 (Weighted Round Robin)을 하였다. (weight 2:1 기준)
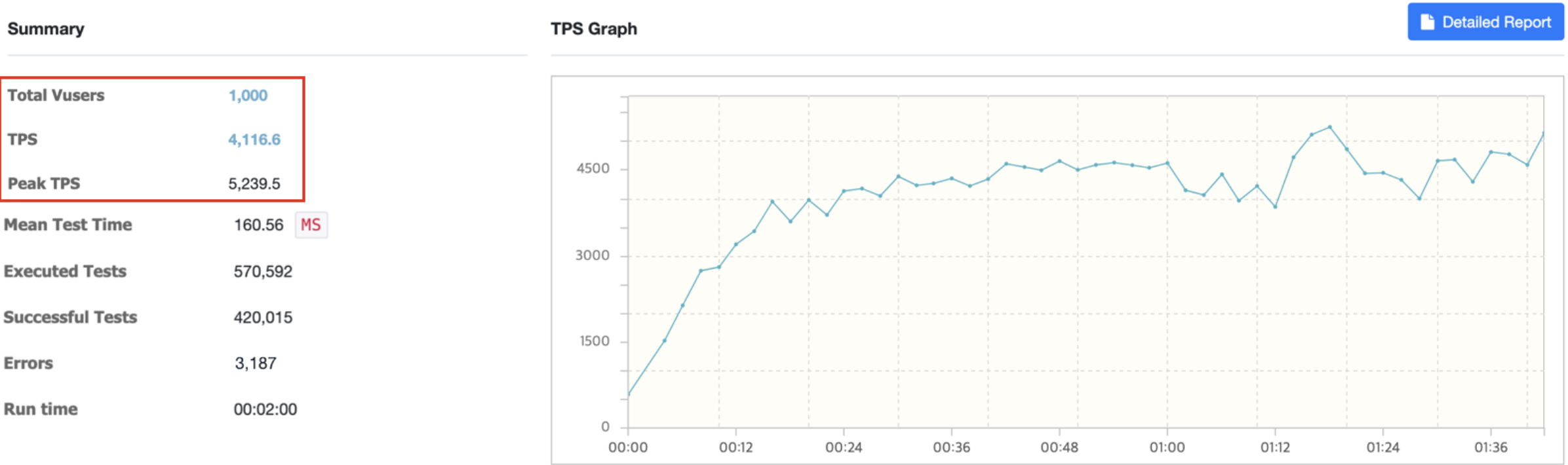 TPS가 약 2600에서 4100으로 기존 테스트 보다 1.7배 가까이 TPS가 상승했다. 응답시간도 250ms에서 160ms로 유의미하게 단축되었다.
TPS가 약 2600에서 4100으로 기존 테스트 보다 1.7배 가까이 TPS가 상승했다. 응답시간도 250ms에서 160ms로 유의미하게 단축되었다.
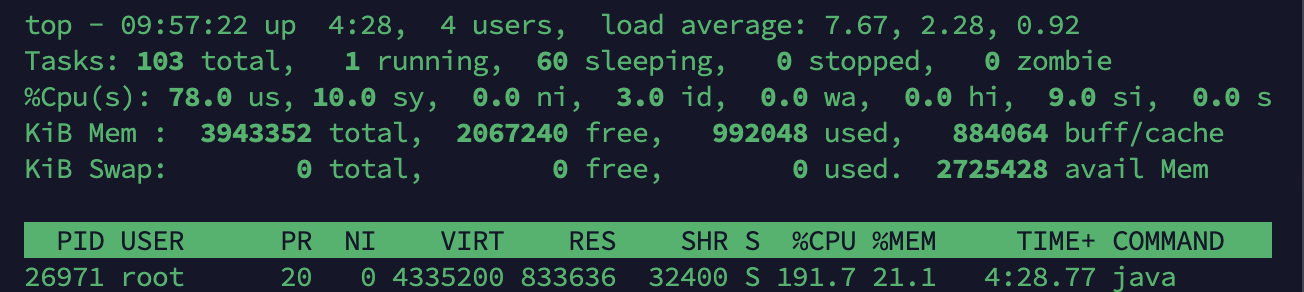
Tomcat-1
 Tomcat-2
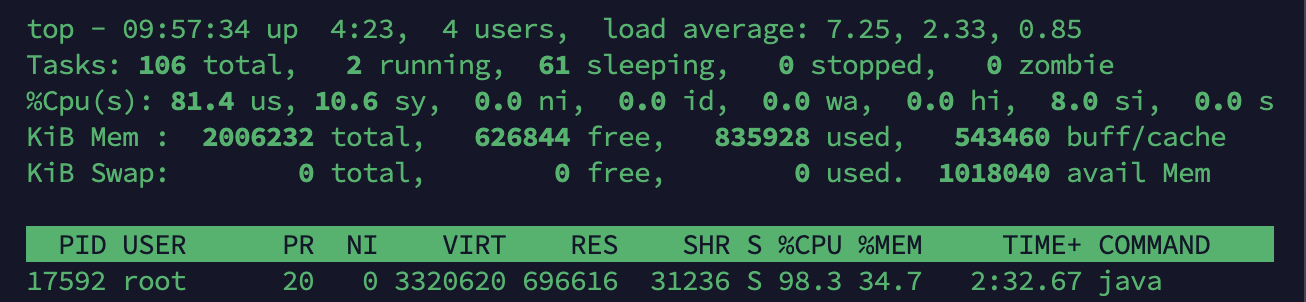
Tomcat-2
 Nginx
Nginx
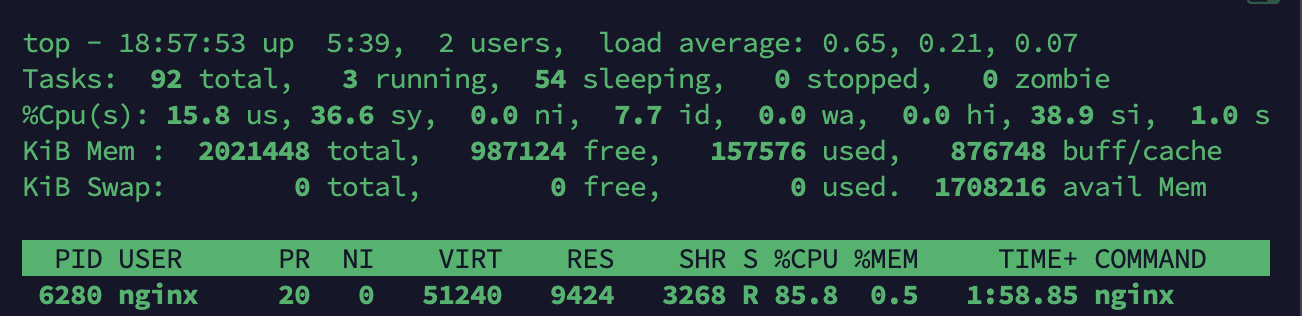 WAS 서버 2대 각각 CPU Usage가 약 190%, 약 98%로 최대 용량을 사용 중이다. Nginx는 약 85%로 사용하고 있다. 사용자 수가 1천명이 서버 스펙에서 최대 사용량일 것 같다.
WAS 서버 2대 각각 CPU Usage가 약 190%, 약 98%로 최대 용량을 사용 중이다. Nginx는 약 85%로 사용하고 있다. 사용자 수가 1천명이 서버 스펙에서 최대 사용량일 것 같다.
사용자를 2천명으로 늘릴 경우 WAS 서버의 병목 현상이 재발현될 것 같고 또한 Nginx 역시 부하가 발생할 것으로 짐작된다.
2-1. VisualVM으로 WAS 서버 JVM 측정
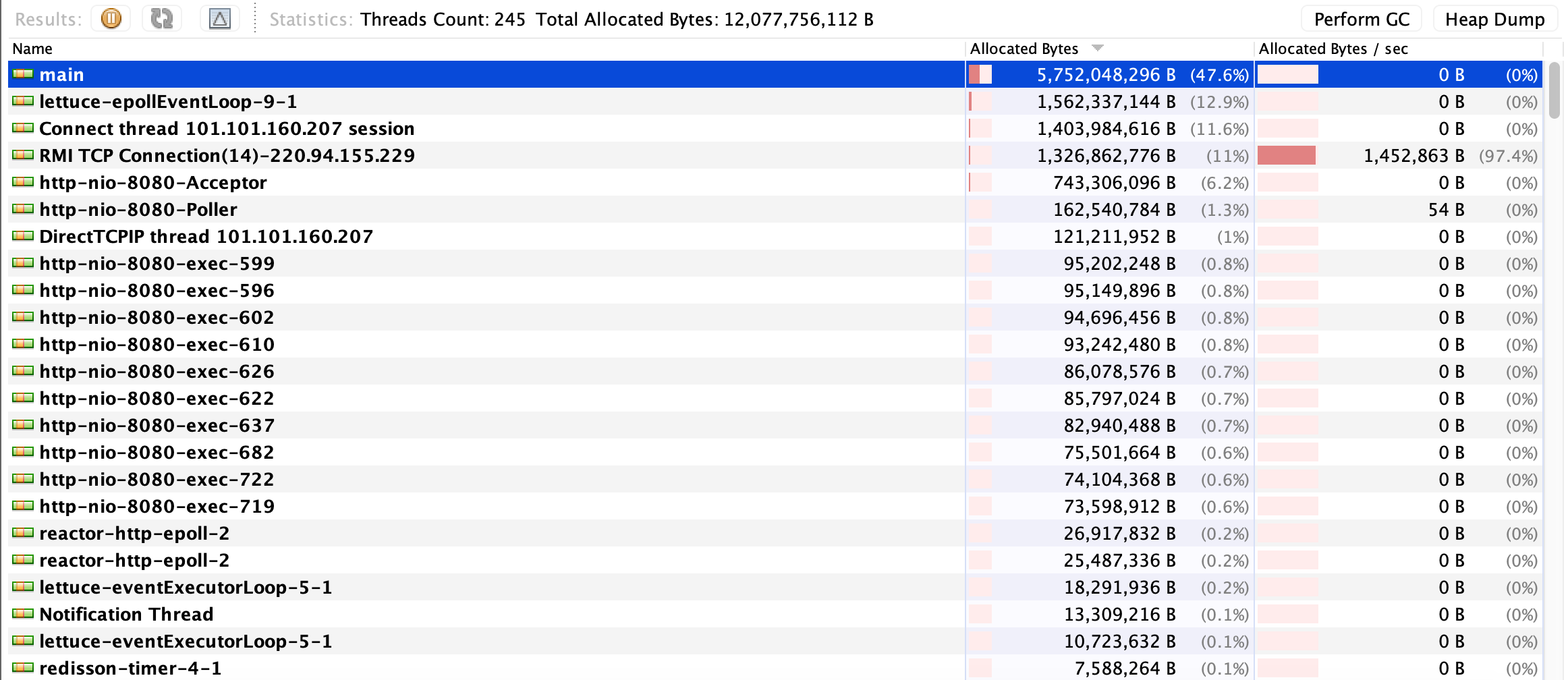 main 쓰레드가 점유율이 50%, lettuce-epollEventLoop가 13%인 것은, main 쓰레드에서 수행하는 작업이 프로그램의 대부분을 차지하고 있으며, lettuce-epollEventLoop는 Redis와의 통신 등 비동기 이벤트 처리에 상당한 리소스를 할당받고 있는 것 같다.
main 쓰레드가 점유율이 50%, lettuce-epollEventLoop가 13%인 것은, main 쓰레드에서 수행하는 작업이 프로그램의 대부분을 차지하고 있으며, lettuce-epollEventLoop는 Redis와의 통신 등 비동기 이벤트 처리에 상당한 리소스를 할당받고 있는 것 같다. 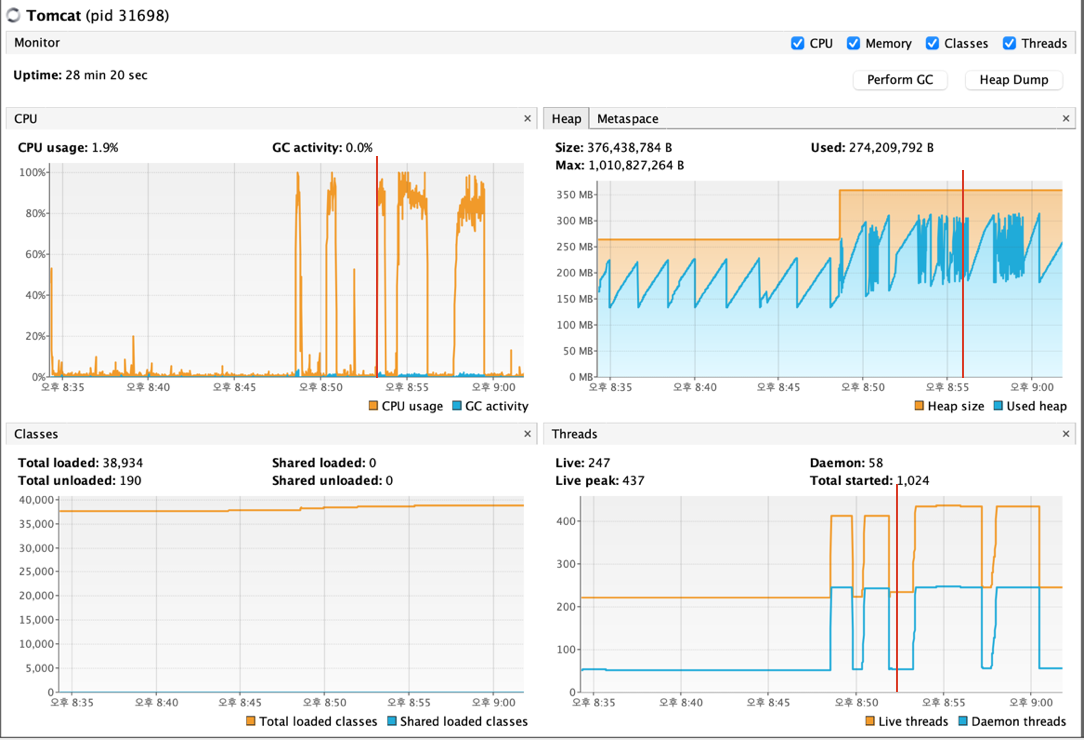 빨간색으로 선을 그어 놓은 부분부터 Scale-Out으로 서버 구조를 변경 후 테스트를 한 시점이다. CPU 최대 사용률의 지속 시간이 길어졌으며, 쓰레드 사용량도 CPU 2코어인만큼 WAS(Tomcat)의 최대 쓰레드 활성화 갯수도 200 * 2로 적절히 사용 중으로 판단된다.
빨간색으로 선을 그어 놓은 부분부터 Scale-Out으로 서버 구조를 변경 후 테스트를 한 시점이다. CPU 최대 사용률의 지속 시간이 길어졌으며, 쓰레드 사용량도 CPU 2코어인만큼 WAS(Tomcat)의 최대 쓰레드 활성화 갯수도 200 * 2로 적절히 사용 중으로 판단된다.
마지막으로 목표치인 2천명을 해보자.
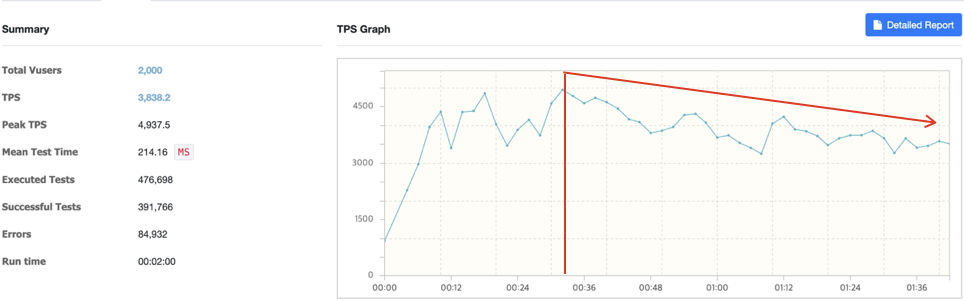 Read Time-out이 발생하지는 않고 테스트가 완료되었다. 하지만 기존 테스트 대비 Error의 점유율이 상당 비율 차지했다. TPS도 기대했던 3배이상인 6000 이상 나오지 않았다.
Read Time-out이 발생하지는 않고 테스트가 완료되었다. 하지만 기존 테스트 대비 Error의 점유율이 상당 비율 차지했다. TPS도 기대했던 3배이상인 6000 이상 나오지 않았다.
30초부터 TPS가 점진적으로 하락하는 이유?
- WAS의 병목현상: 서버 자원(CPU, 메모리 등)의 과도한 사용, GC로 인한 지연, 또는 비효율적인 애플리케이션 로직으로 인해 발생을 의심할 수 있다.
- 데이터베이스 병목현상: 데이터베이스 쿼리 성능 저하, 커넥션 풀의 부족, 락 경합 등 데이터베이스 관련 문제를 의심해 볼 수 있다.
- 네트워크 병목현상: WAS와 데이터베이스 사이, 또는 WAS와 클라이언트 사이의 네트워크 지연이 TPS 하락의 원인일 수 있다. → 데이터가 100만건 넘지 않는다. CPU Usage 10% 언저리 측정
- Nginx 병목현상: Nginx 설정(예: worker 프로세스의 수, 커넥션 제한 등)의 최적화, Nginx 스펙으로 인해 병목현상이 발생할 수 있다.
목표 달성?
결론부터 말하면 실패다. 목표 달성은 할 수 있겠지만, 서버 운영 비용 측면에서 여기서 멈추었다. (금전적 문제)
첫번째로 WAS, Nginx, nGrinder 서버를 Scale-Up을 하여 사용자 수를 늘림으로써 TPS가 증가되었다. 두번째로 Nginx를 두어 WAS 서버를 Scale-Out하면서 TPS가 증가되었다.
서버 자원(CPU, Memory 등)모니터링, 서버 구조(또는 스펙)를 변경을 병행하면서 점진적으로 부하를 높여 테스트를 해보았다.
이번 테스트는 Scale에 초점을 두었지만, 애플리케이션 로직, DB 쿼리 최적화 등 다른 부분에서도 성능을 개선할 수 있지 않을까 싶다.
마지막 CI/CD 글로는, Nginx 로드밸런싱 설정, SonarQube 연동으로 찾아뵙겠다.
