토이 프로젝트를 진행하면서 발생했던 문제에 대한 본인의 생각과 고민을 기록한 글입니다.
기술한 내용이 공식 문서 내용과 상이할 수 있음을 밝힙니다.
새로운 프로젝트가 시작되면서 프로젝트 구상, 아키텍처 및 비즈니스 로직 설계 등으로 바빴다.
진행 상황을 기록하고 싶었지만, 구체화가 되고 개발의 첫 삽을 뜨려다보니 2주가 지나서야 글을 쓴다.
어떤 프로젝트인가?
프로젝트명은 Teemo.gg로 LoL(이하, League Of Legends)을 기반으로 소환사 검색 서비스이다.
정확히는, 게임이 잡히면 10명의 소환사가 챔피언 선택창(이하, 픽창)에 들어가게 되는데 이때 아군(5명)과 적군(5명) 각각 누가 트롤(게임을 의도적으로 망치거나, 게임의 기여도가 매우 낮은 소환사를 의미)인지를 알려주는 트롤 분석기이다.
프로젝트 구상?
기존 프로젝트에서 RDBMS를 활용하여 Full Text Search, General Inverted Index 등 검색의 효과를 높이기 위해 다양한 인덱싱 기법을 사용해보았다.
이번에는 ElasticSearch를 활용해서 단순히 검색만 하는 것이 아니라 여러가지 연산을 할 수 있는 Aggregation 기능을 사용하려고 한다. Kibana에서는 데이터 분석을 신속하고 규모에 맞게 실행하여 관찰, 보안 및 검색을 수행하려고 한다.
이 과정에서 Riot Games에서 제공하는 Riot Developer API를 적극 활용하려고 한다.
소환사명 검색 시 로직이 어떻게 돼?
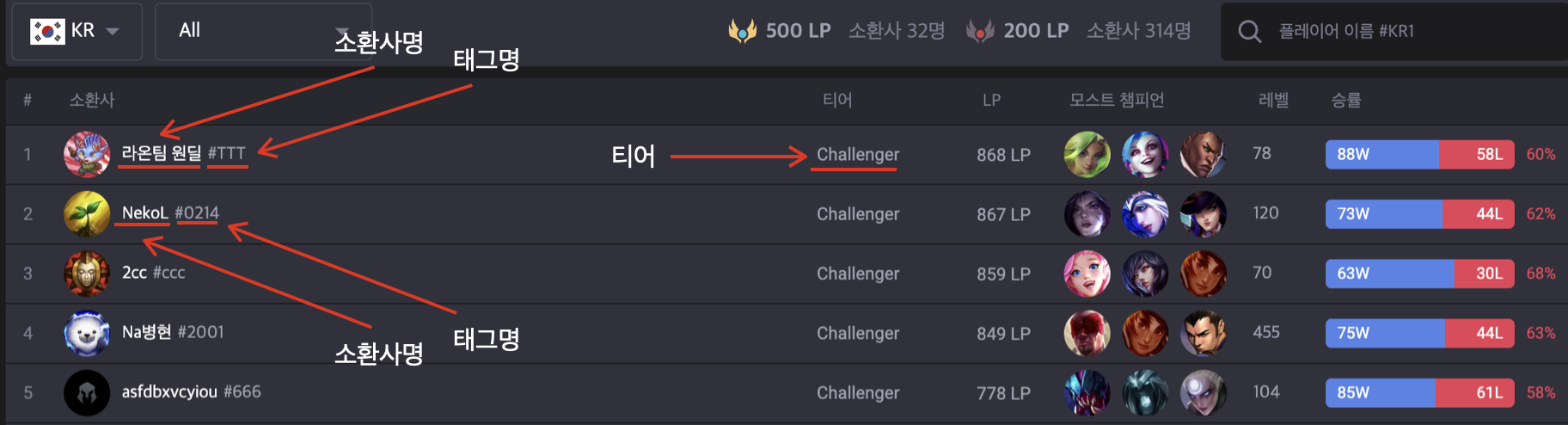
이 사진은 op.gg 사이트의 랭킹 대시보드다. LoL 게임이 사용자명의 중복을 허용하면서 뒤에 태그네임을 통해서 중복 이름의 식별이 가능하다.
따라서, SummonerName#TagLine 이렇게 검색을 해야한다. (매우 귀찮아짐)
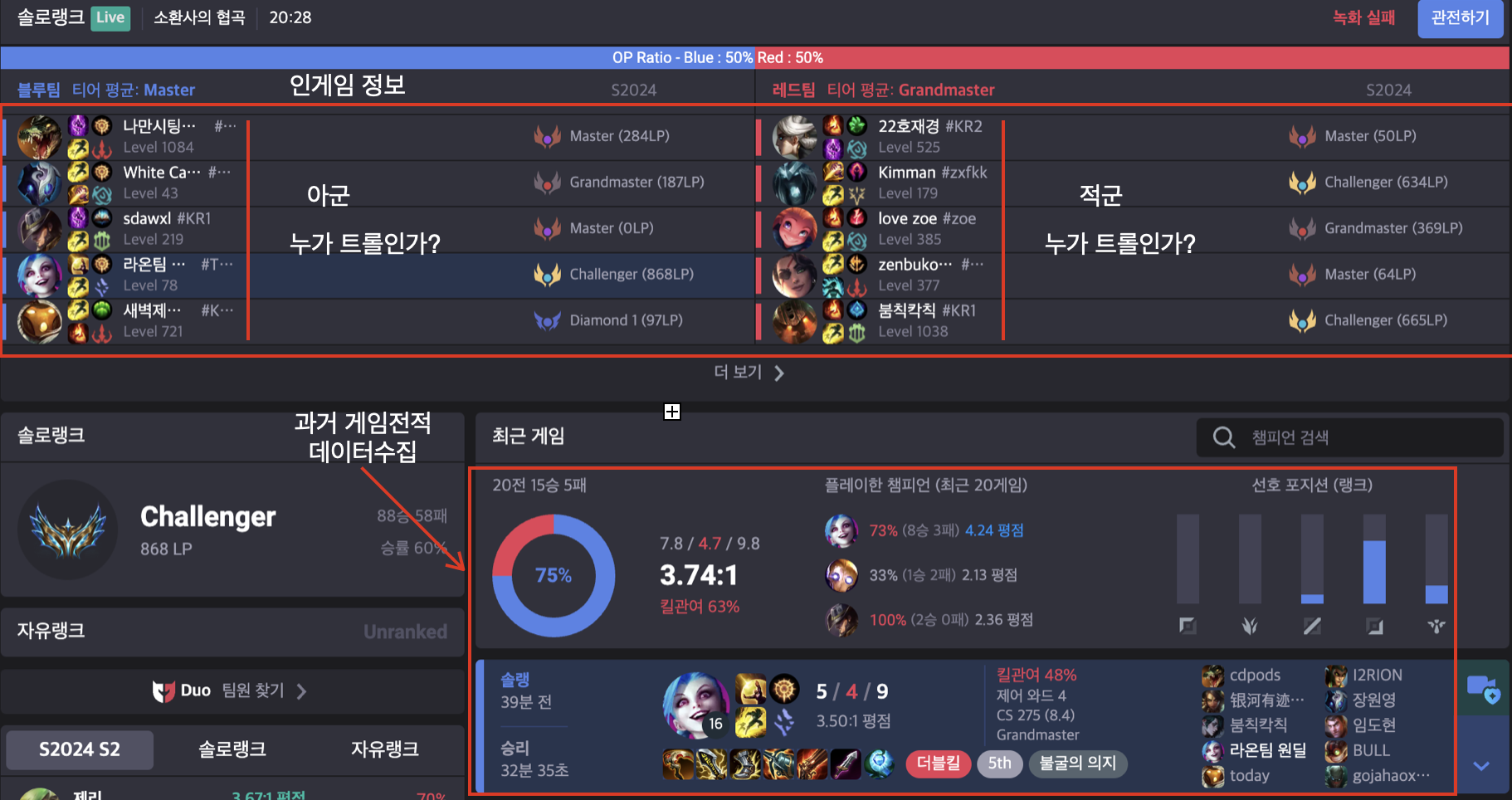
해당 사진은 특정 소환사의 상세정보이다.
이전 기록(과거 대전기록 20개~100개)를 수집하여 트롤 점수 산정 알고리즘을 통해서 트롤점수를 계산할 예정이다.
1. {사용자명#태그네임}으로 검색
public List<SummonerPerformance> analyzeSummonerPerformance(String gameName, String tagLine) throws Exception {
Account account = getPuuid(gameName, tagLine);
String username = String.format("%s#%s", gameName, tagLine);
List<String> matchIds = getMatchIds(account.puuid());
List<SummonerPerformance> matchDetails = new ArrayList<>();
for (String matchId : matchIds) {
String matchDetail = getMatchDetail(matchId);
matchDetails.add(jsonToPlayerPerformance(matchDetail, username, account.puuid()));
}
}Riot은 소환사 별로 고유의 식별자키인 PK처럼 PUUID를 가지고 있다. 모든 API의 매개변수는 puuid가 필요하기 때문에 반드시 알아내야 한다.
1-1. PUUID 조회 API 호출
private Account getPuuid(String gameName, String tagLine) {
return this.restClient.get()
.uri(uriBuilder -> uriBuilder
.path("/riot/account/v1/accounts/by-riot-id/{gameName}/{tagLine}")
.queryParam("api_key", API_KEYS)
.build(gameName, tagLine))
.retrieve()
.body(Account.class);
}1-2. MatchID 조회 API 호출
PUUID를 알아냈다면 해당 소환사의 과거 전적데이터를 가져와야한다. 롤은 대전별로 고유 matchID가 있다. PageSize를 통해서 원하는 만큼의 대전 기록을 조회할 수 있다. 현재 20개 데이터를 기반으로 집계를 처리할 예정이고, ElasticSearch의 기능이 정상적으로 작동되었을때 100개까지 늘릴 예정이다.
private List<String> getMatchIds(String puuid) {
return this.restClient.get()
.uri(uriBuilder -> uriBuilder
.path("/lol/match/v5/matches/by-puuid/{puuid}/ids")
.queryParam("start", 0)
.queryParam("count", PAGE_SIZE)
.queryParam("api_key", API_KEYS)
.build(puuid))
.retrieve()
.body(new ParameterizedTypeReference<>() {
});
}1-3. 대전 상세정보 조회 API 호출
private String getMatchDetail(String matchId) {
return this.restClient.get()
.uri(uriBuilder -> uriBuilder
.path("/lol/match/v5/matches/{matchId}")
.queryParam("api_key", API_KEYS)
.build(matchId))
.retrieve()
.body(String.class);
}json 값에는 어떤 속성 값들이 들어있을까?
| NAME | DATA TYPE | DESCRIPTION |
|---|---|---|
| 12AssistStreakCount | int | 12연속 어시스트 횟수 |
| abilityUses | int | 사용한 스킬 횟수 |
| acesBefore15Minutes | int | 게임 시작 후 15분 이전에 에이스를 달성한 횟수 |
| alliedJungleMonsterKills | int | 아군 정글 몬스터 처치 수 |
| baronTakedowns | int | 바론 처치 횟수 |
| blastConeOppositeOpponentCount | int | 적과 반대쪽에 있는 폭발성 식물을 사용한 횟수 |
| bountyGold | int | 현상금으로 얻은 골드 |
| buffsStolen | int | 상대 정글에서 훔친 버프 횟수 |
| completeSupportQuestInTime | int | 정해진 시간 내에 서포터 퀘스트를 완료한 횟수 |
| controlWardsPlaced | int | 설치한 제어 와드 수 |
| damagePerMinute | float | 분당 가한 피해량 |
| damageTakenOnTeamPercentage | float | 팀 내에서 받은 피해 비율 |
| dancedWithRiftHerald | int | 협곡의 전령과 춤춘 횟수 |
| deathsByEnemyChamps | int | 적 챔피언에 의해 죽은 횟수 |
| dodgeSkillShotsSmallWindow | int | 작은 시간 창 내에서 회피한 스킬샷 수 |
| doubleAces | int | 더블 에이스 횟수 |
| dragonTakedowns | int | 드래곤 처치 횟수 |
| legendaryItemUsed | List[int] | 사용한 전설 아이템 목록 |
| effectiveHealAndShielding | float | 효과적인 치유 및 보호막량 |
| elderDragonKillsWithOpposingSoul | int | 상대 팀이 드래곤 영혼을 가진 상태에서 처치한 장로 드래곤 수 |
| ... | ... | ... |
진짜 엄청 많다. 도합 300개는 족히 넘는 것 같다.
일단 ElasticSearch에 저장하자.
@Repository
@Primary
public interface SummonerPerformanceRepository extends ElasticsearchRepository<SummonerPerformance, String> {}
public void storeToElasticsearch(List<SummonerPerformance> performances) {
summonerPerformanceRepository.saveAll(performances);
}2. ElasticSearch를 활용하여 데이터 Aggregation 집계
상세 데이터 가공 및 처리는 다음 글에서 자세히 기록하겠다. 이번 글에서는 개괄적인 내용만 서술한다.
2.1 소환사 20게임 데이터 통계
게임별 KDA, kills, assists, deaths 등 데이터들이 기록되어 있다.
총 20게임의 aggregation을 통해 평균 데이터를 산출한다.
2.2 현재 게임 내 선택한 챔피언의 전체 전적 기록
본인을 포함한 총 10명의 소환사가 선택한 챔피언이 이전에도 트롤이었는지에 대한 정보를 championId를 통해서 데이터를 집계하여 렌더링한다.
2.3 포지션 별 트롤 점수 산정 알고리즘 적용
롤이라는 게임은 TOP, JUG, MID, ADC, SPT 총 5개로 포지션을 배정받아 게임한다.
각 포지션 마다 해야 하는 역할과 게임의 기여도가 다르기 때문에 각기 다른 방식으로 점수를 산정해야 한다.
Top Laner
기본 점수 계산:
KDA 점수 = (킬 + 어시스트) / (데스 + 1)
킬 관여율 점수 = 킬 관여율 * 100추가 점수 계산:
건축물 피해 점수 = 건축물에 가한 피해 / 1000
챔피언 피해 점수 = 챔피언에게 가한 피해(AD + AP) / 1000
teleportTakedowns: 로밍을 통한 킬이나 어시스트로 환산한 점수
soloKills: 솔로킬
Jungler
기본 점수 계산:
KDA 점수
킬 관여율 점수추가 점수 계산:
드래곤과 바론 처치 점수: 드래곤과 바론에 대한 기여도를 점수로 환산
게임당 스캔 와드 사용 수: 스캔 와드를 사용하여 적 와드를 제거한 횟수를 점수로 환산
Mid Laner
기본 점수 계산:
KDA 점수
킬 관여율 점수추가 점수 계산:
챔피언 피해 점수
teleportTakedowns: 로밍을 통한 킬이나 어시스트로 환산한 점수
soloKills: 솔로킬
AD Carry
기본 점수 계산:
KDA 점수
킬 관여율 점수추가 점수 계산:
챔피언 피해 점수
게임당 미니언 처치 수
Supporter
기본 점수 계산:
KDA 점수
킬 관여율 점수시야 점수 계산 (서포터 포지션 전용):
게임당 평균 와드 설치 수 = (핑와 설치 수 + 일반 와드 설치 수) / 게임 수
게임당 평균 와드 제거 수 = 와드 제거 횟수 / 게임 수시야 점수 = (게임당 평균 와드 설치 수 0.5) + (게임당 평균 와드 제거 수 0.5)
와드 설치와 와드 제거에 동일한 가중치를 부여했지만, 필요에 따라 조정 가능
knockEnemyIntoTeamAndKill: 그랩류 등으로 아군쪽으로 그랩해 킬관여
3. Kibana로 데이터 시각화
LOL에 가입되어 있는 소환사 총 계정은 약 280만개이다. 1게임 당 10명의 사용자가 잡히고, 모든 사용자가 게임을 했을 경우 28 * 10^6 / 10 즉, 28만개의 게임이 이루어진다.
사용자 1명이 트롤 검색 API를 요청했을 때, 총 1 + 1 + 20 = 22 번의 요청이 이루어지고, 이후 ElasticSearch의 데이터 전처리 과정이 진행될 때, 최대 50만번의 요청이 동시에 일어나면서 ES가 Aggregation 작업을 수행해야 한다.
대용량 로그를 처리하고 트래픽 병목이 발생하는 엔드 포인트를 빠르게 파악하고 처리하기 위해서는 Kibana를 활용해야 한다고 판단하였다.
추가로, ElasticSearch의 노드 수를 늘려서 분산으로 처리할 수 있지 않을까도 고민해봄직하다.
다음 글은, 어떻게 내가 SpringBoot와 ElasticSearch를 사용하여 데이터 집계처리를 했는지에 대해 알아보겠다.
