
개발자라면 코딩을 하면서 한 번쯤은 HashMap을 써봤을 것이다. 매우 직관적이다. (Key, Value)니까.
HashMap? 어떤 용도로 사용될까
Java에서 HashMap은 매우 중요한 데이터 구조로, 키-값 쌍을 내부적으로 해싱이라는 기법을 사용하여 저장하고 검색한다.
해싱은 특정 객체를 고유한 숫자 값인 해시 코드로 변환하는 과정이다. HashMap에서 이 해시 코드는 해당 객체가 저장되어 있는 버킷이라고 하는 위치를 결정한다.
- 데이터 검색 속도: HashMap은 키-값 쌍을 저장하고 검색할 때 일반적으로 상수 시간 복잡도 (O(1))이다. 즉, 맵의 크기에 관계없이 거의 일정한 시간 안에 데이터를 검색할 수 있다.
- 중복 키 방지: HashMap에서 각 키는 유일해야 한다. 동일한 키로 값을 저장하려고 하면 기존 값이 새 값으로 대체된다.
- Null 허용: HashMap은 null 값을 가진 엔트리와 null 키를 모두 지원한다.
- 객체 연관성: 객체 간의 관계를 나타내기 위해 많이 사용된다. 예를 들어, 사람 이름(키)과 그들의 나이(값) 등을 연결할 수 있다.
HashMap은 순서가 보장되지 않으므로 데이터 입력 순서대로 값을 가져와야 할 경우에는 LinkedHashMap을 사용해야한다. (이거 몰라서 우테코 떨어졌음)
해시 함수(Hash Function)
해시 함수는 임의의 길이를 가진 데이터를 고정된 길이의 데이터로 매핑하는 함수다. HashMap에서는 이 해시 값을 사용하여 키-값 쌍을 저장하거나 검색하는 위치, 버킷을 결정한다.
버킷(Bucket)
버킷은 HashMap에서 키-값 쌍이 실제로 저장되는 공간이다. 해시맵은 내부적으로 버킷 배열을 가지고 있으며, 각 버킷은 유일한 해시 코드에 의해 인덱싱된다. 해시 함수가 어떤 특정 키를 받아 그에 대응하는 해시 코드를 생성하면, 이 해시 코드가 바로 해당 키-값 쌍이 저장될 버킷의 인덱스가 된다.
💡무슨 말인지 이해 안 됨
HashMap은 기본적으로 '상자'들의 배열을 가지고 있다고 생각하자. 이 상자들이 버킷이면 각각의 버킷은 고유한 번호(인덱스)를 가지고 있다.
이제 키-값 쌍을 HashMap에 저장하려 할 때, 해시 함수가 그 키를 받아서 고유한 숫자(해시 코드)를 생성한다. 이 해시 코드는 상자들 중 어느 상자(버킷)에 키-값 쌍을 저장할 것인지를 결정하는 인덱스로 사용된다.
예를 들어, "사과"라는 키로 "빨강"이라는 값을 저장하려 한다면, 해시 함수가 "사과"라는 키를 받아서 예컨대 3이라는 숫자(해시 코드)를 만들어냈다면, 이 HashMap에서 3번째 버킷에 "사과-빨강"이라는 키-값 쌍이 저장된다.
그래서 나중에 "사과"에 해당하는 값을 찾으려 하면, 다시 같은 해시 함수(A라고 가정)가 "사과"라는 키를 받아 3이란 숫자(해시 코드)를 만들어내고, 이 숫자가 가리키는 3번째 버킷에서 원하는 값("빨강")을 찾아낸다.
만약, "사과"에 대한 키 값을 찾으려고 했는데 다른 해시 함수(B)가 "사과"라는 키를 받는다면?
이 경우, 해시 함수 B가 생성하는 해시 코드는 A가 생성한 것과 다르게 될 가능성이 높다. "사과"에 대한 값을 찾으려 할 때 원래의 3번 버킷이 아닌 다른 버킷을 참조하게 되므로, 올바르지 않은 결과나 null 값 등을 반환하게 될 것이다. 이처럼 동일한 객체에 대해서 항상 동일한 해시 코드를 반환해야 한다. (해시 함수의 일관성)
따라서 두 키(저장 / 검색에 사용한 키)가 객체가 equals() 메소드에 의해 동등하다고 판정될 경우, 두 객체의 hashCode() 메소드 역시 반드시 같은 해시 코드를 반환해야 한다.
충돌(Collision)
충돌은 두 개 이상의 다른 키가 같은 해시 코드를 가질 때 발생한다. 즉, 서로 다른 키들이 같은 버킷에 매핑되는 경우다. 충돌 자체는 어쩔 수 없이 발생하는 현상인데, 그 이유는 입력되는 키의 수는 잠정적으로 무한하지만, 사용 가능한 버킷(생성 가능한 유일한 해시 코드)의 수는 한정적이기 때문이다.
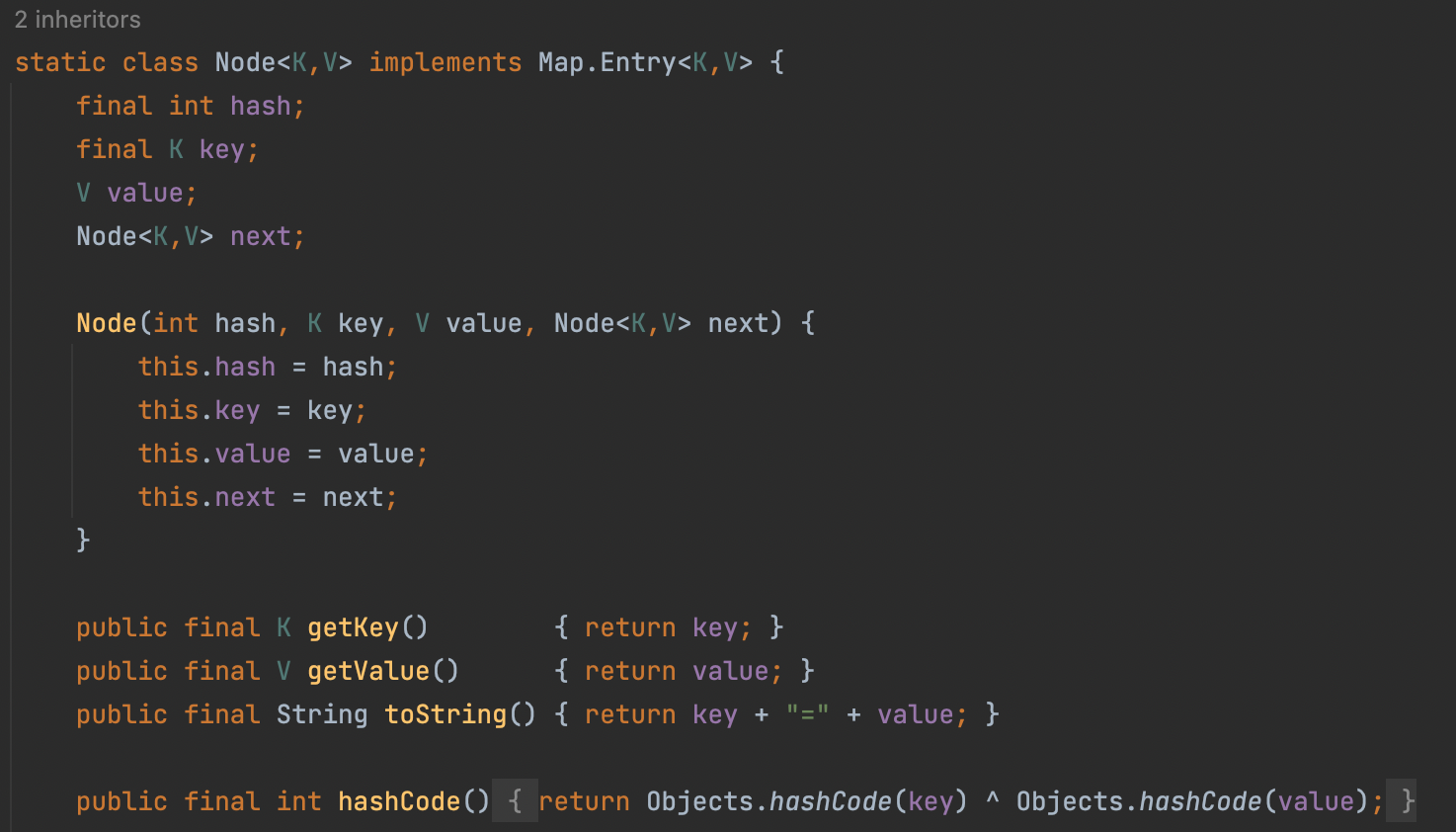
HashMap에서 충돌을 처리하는 기본 방식은 체이닝(chaining)이다. 체인 방식에서 각 버킷은 연결 리스트로 구현되며, 충돌 시 리스트에 새 요소(새로운 키-값 쌍)가 추가된다.(뒤에 새 노드가 연결)
따라서 동일한 버킷 인덱스(3)에 여러 개의 엔트리(서로 다른 키-값 쌍)가 함께 저장될 수 있다.
충돌이 발생하면 기존 버킷 위치 앞/뒤에 새로운 Entry 객체가 생성돼 연결리스트로 연결하는지 Java 11 라이브러리를 확인해보았다. (진짜네)
💡무슨 말인지 이해 안 됨
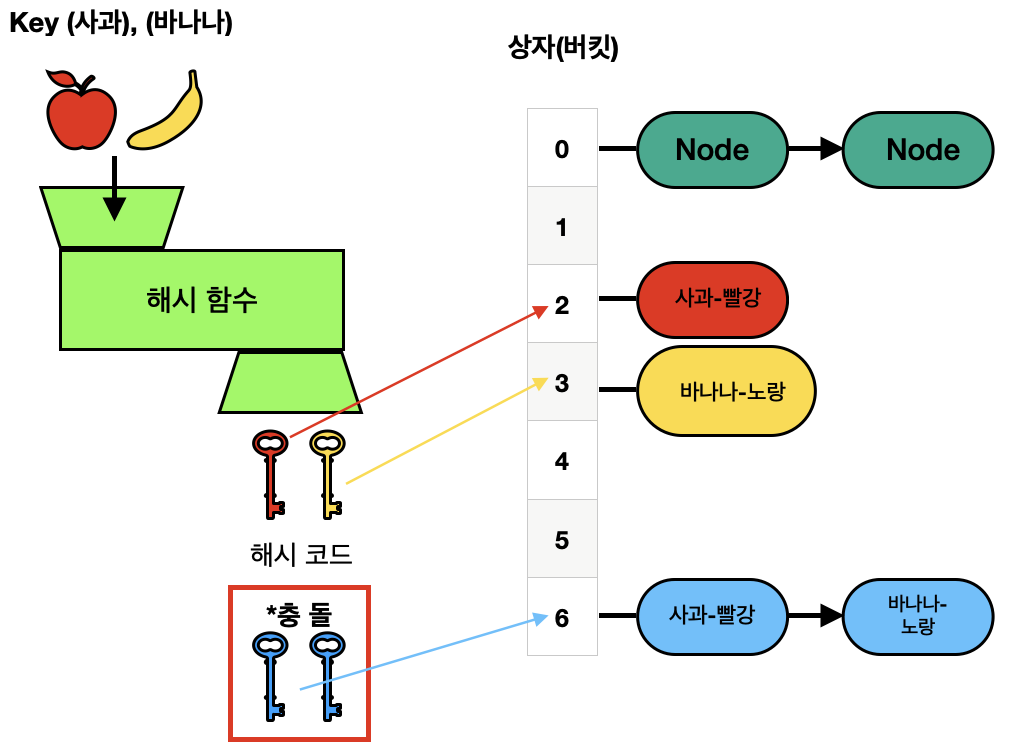
예를 들어, "사과"라는 키와 "바나나"라는 키가 모두 3이라는 해시 코드를 가지게 되다고 가정하자.
둘 다 3번째 상자(버킷)에 저장되어야 한다. 충돌이 발생한 것이다!
이때 사용되는 방법이 체이닝이다. 체인 방식에서 각 상자(버킷 = 3번)는 사실상 한 줄의 연결된 공간인 연결 리스트로 생각할 수 있다.
따라서 "사과-빨강" 데이터를 먼저 3번째 상자에 넣었다면, 그 다음으로 "바나나-노랑" 데이터도 같은 3번째 상자에 넣을 수 있는 것이다. 그리고 나중에 값을 찾을 때는 해당 버킷의 연결 리스트를 따라가며 원하는 키("사과" 혹은 "바나나")와 일치하는 엔트리를 찾는다.
Treeify
Java 8부터 HashMap 구현체에서는 체인 방식과 병합하여 Treeify 방식도 도입했다. 연결 리스트 안에 너무 많은 요소들 (기본적으로 8개 이상)이 들어갔을 때 연결 리스트 대신 Balanced Binary Tree를 사용하게 된다. 이는 해시 충돌에 따른 성능 저하를 최소화한다. (바이너리 트리는 각 노드가 최대 두 개의 자식을 가지는 트리 형태의 데이터 구조로 자료가 균등하게 분포되어 있다면 검색, 삽입, 삭제 등의 연산을 O(log n)의 시간 복잡도(n은 트리에 저장된 노드 수) 내에 처리할 수 있다.
내용이 길어져 2편에서 충돌 관리, 재해싱, 동기화에 대해 자세히 설명하겠다.
