일반적으로 get() 및 put() 연산은 평균적으로 O(1)의 시간 복잡도를 갖는다.(Key 값을 알고 있으면 바로 인덱스로 접근 가능) 하지만 최악의 경우(모든 키가 같은 버킷 인덱스로 매핑되는 경우), 연결 리스트나 균형 이진 트리에서 선형 탐색이 필요하므로 O(n)까지 증가할 수 있다.
충돌 관리는 어떻게?
- HashMap의 전체 크기(size)가 threshold (capacity * load factor, 기본적으로 초기 용량 16에 로드 팩터 0.75를 곱한 값인 12) 값을 초과할 경우, HashMap은 배열 크기를 두 배로 확장하고 모든 엔트리들을 새 배열에 재배치하는 재해싱 과정을 거친다. 기존 배열 크기 16에서 32가 되고, threshold도 2배인 24가 된다.
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
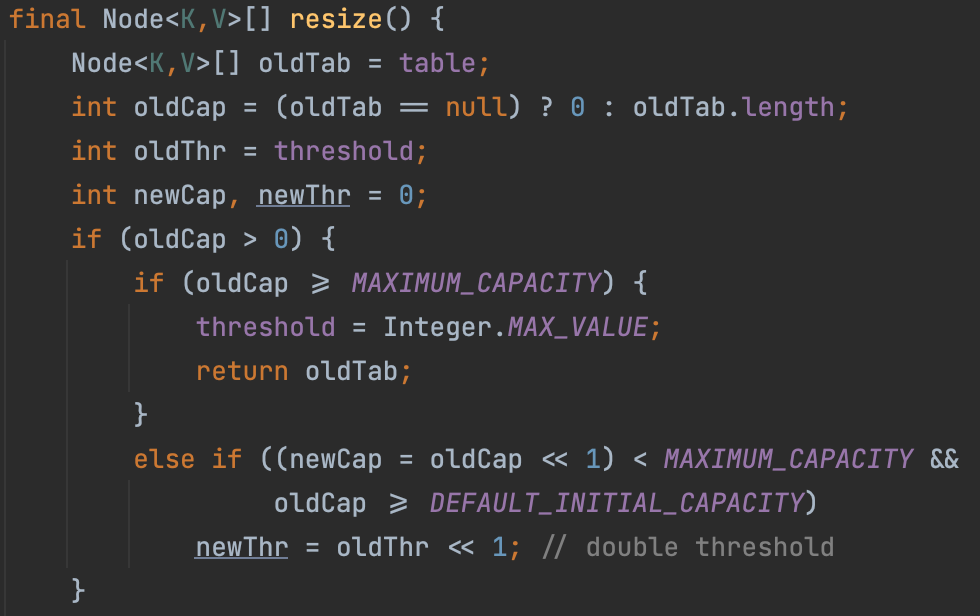
이 코드에서는 newThr = oldThr << 1; 구문을 통해 기존 임계값(oldThr)을 두 배로 늘리고 있다. 이렇게 함으로써 HashMap의 크기가 확장될 때 임계값도 함께 증가하여, 충분한 공간을 확보한다. newCap = oldCap << 1 부분은 기존 용량(oldCap)을 두 배로 늘리는 연산이다. 이것이 바로 재해싱 과정의 일부다.
HashMap의 경우, 특정 로드 팩터를 초과할 때마다 배열 크기를 두 배로 확장한다. 이렇게 함으로써 충돌 가능성을 줄이고 성능을 개선할 수 있다.
배열 크기를 두 배로 확장한 후에는 기존의 모든 엔트리들을 새롭게 해시하여 새로운 버킷 위치에 배치하는 작업이 이루어지기 까지가 재해싱 과정이다.
새로운 해시 계산: 각 엔트리의 키에 대해 새롭게 해시 함수를 적용. 이때, 해시 함수는 변경되지 않지만, 배열 크기가 두 배로 늘어나므로 버킷 위치가 달라진다. (해시 값 h와 배열 크기 n에 대해 h % n)
새로운 버킷 위치 결정: 각 엔트리를 위해 계산된 새로운 해시 값을 사용하여 해당 엔트리가 위치할 새로운 버킷을 결정 후 각각의 엔트리를 새로운 버킷으로 재배치시킨다.
- 체이닝 방식을 사용하여 해시 충돌을 처리하는 동안 한 버킷에 너무 많은 엔트리가 모여 성능 저하가 우려될 때 레드-블랙 트리로 변환하는 작업을 수행
static final int TREEIFY_THRESHOLD = 8;
변수 binCount는 현재 버킷의 엔트리 수를 나타내며, TREEIFY_THRESHOLD는 연결 리스트를 레드-블랙 트리로 변환하기 시작하는 엔트리 수의 임계값으로 기본적으로 값은 8이다.
조건문이 참일 경우 treeifyBin(tab, hash); 메서드를 호출하여 해당 버킷의 연결 리스트 구조를 레드-블랙 트리 구조로 변환한다. 이렇게 하면 검색 시간 복잡도가 O(n)에서 O(log n)으로 줄어들어 성능 향상을 가져온다.
멀티쓰레드 환경에서는 어떨까?
HashMap은 일반적으로 스레드 안전하지 않은 구조다. 멀티쓰레드 환경에서 동시에 여러 스레드가 HashMap에 접근하면 예기치 않은 결과가 발생할 수 있다. 이러한 문제는 어떻게 해결할까?
동기화 (Synchronization): HashMap을 쓰레드 환경에서 안전하게 만들기 위해 동기화 메커니즘을 사용할 수 있다. 자바에서는 ConcurrentHashMap과 같은 클래스를 생각할 수 있다. 이 클래스는 내부적으로 스레드 안전한 방식으로 구현되어 여러 스레드가 동시에 접근해도 안전하게 작동한다.
분할(Segmentation): ConcurrentHashMap은 내부 데이터를 여러 세그먼트로 분할한다. 이로 인해 한 번에 하나의 스레드만 해당 세그먼트에 접근할 수 있으므로, 전체 맵에 락을 걸 필요가 없다.
💡 내부 데이터를 여러 세그먼트로 분할한다?
HashMap에서 내부 데이터는 주로 키-값 쌍을 저장하는 버킷을 의미한다. HashMap은 키의 해시값을 계산하고, 이 값을 인덱스로 사용하여 해당 키-값 쌍을 배열 형태의 버킷에 저장한다.
그러나 ConcurrentHashMap에서 "내부 데이터를 여러 세그먼트로 분할한다"는 말은 이런 버킷들이 아니라 전체 Map 자체가 여러 개의 부분(세그먼트)으로 나뉘어 관리된다는 것을 의미한다. 각 세그먼트는 독립적인 락(lock)에 의해 보호되며, 따라서 다른 스레드가 다른 세그먼트에 있는 데이터를 동시에 접근하더라도 서로 간섭하지 않는다.예를 들어, 1000 개의 버킷을 가진 해시맵을 10 개의 세그먼트로 분할한다. 그렇다면 각 세그먼트는 대략 100 개의 버킷을 관리하게 된다. 이렇게 되면 여러 스레드가 동시에 접근하더라도 서로 다른 세그먼트를 작업하면서 충돌 없이 안전하게 데이터를 처리할 수 있다.
첫 번째 스레드가 첫 번째 세그먼트에 접근하여 작업을 수행하는 동안, 두 번째 스레드는 두 번째 세그먼트에 접근하여 별도의 작업을 수행할 수 있다. 이런 방식으로 ConcurrentHashMap은 동시성을 높인다.
세그먼트당 락(lock)을 걸면 생기는 문제점?
Java 8 이전의 ConcurrentHashMap에서 세그먼트라는 개념은 전체 맵을 여러 부분으로 나누어 각각을 독립적으로 잠글 수 있게 한 것이다. 즉, 전체 맵에 락을 거는 대신 각 세그먼트에 락을 걸어서 동시성(concurrency)를 향상시켰다. 하지만 이 방식은 여전히 락 경합이 발생할 가능성이 있다.
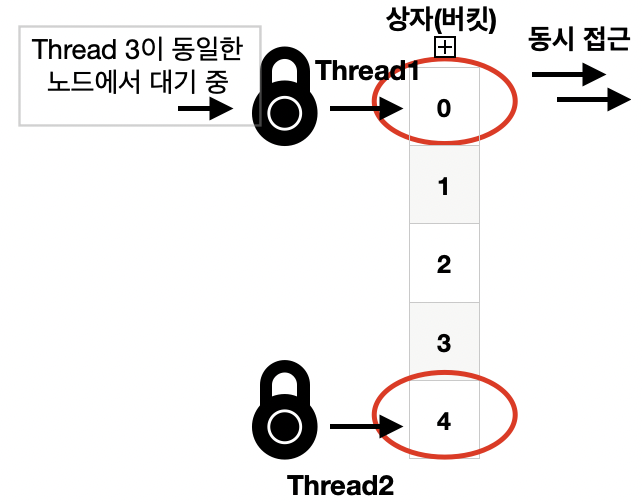
Java 8부터 ConcurrentHashMap에서는 버킷 당 하나의 락 혹은 노드 당 하나의 락이라는 개념을 도입하여 이 문제를 해결했다. 각각의 버킷 혹은 노드가 고유한 락을 가지게 되어, 특정 버킷 혹은 노드만 잠글 수 있게 되었다. 이로 인해 여러 스레드가 서로 다른 버킷 혹은 노드에 접근할 때 경합 없이 동시에 접근할 수 있게 되었고 병목현상을 줄였다.
💡 락 경합(lock contention): 멀티스레드 환경에서 두 개 이상의 스레드가 동시에 같은 락을 획득하려고 할 때 발생하는 현상
한 스레드가 이미 특정 락을 보유하고 있으면, 다른 스레드들은 그 락이 해제될 때까지 기다리게 된다. 이런 상황이 반복되면, 스레드들이 대기하는 시간이 길어져서 성능 저하를 일으킬 수 있다.