
Multilevel Paging and Performance
- Address space가 더 커지면 다단계 페이지 테이블이 필요(비는 공간이 더 많아질테니까)
- 각 단게의 페이지 테이블이 메모리에 존재하므로 logical address의 physical address 변환에 더 많은 메모리 접근 필요
- TLB를 통해 메모리 접근 시간을 줄일 수 있음
- 4단계 페이지 테이블을 사용하는 경우

Valid / Invalid Bit in a Page Table

- proection: 연산을 위한 권한을 표시하기 위한 bit
ex) code영역: read-only, instruction을 수행하기 위한 read만 가능, data, stack: 읽고, 수정하는 모든 권한 가능 - Valid - invalid bit: 프로세스가 그 주소 부분을 사용하지 않고 있거나, 그 주소 부분이 swap area에 있는 경우에는 invalid 표시를 통해 접근할 수 없음을 나타냄
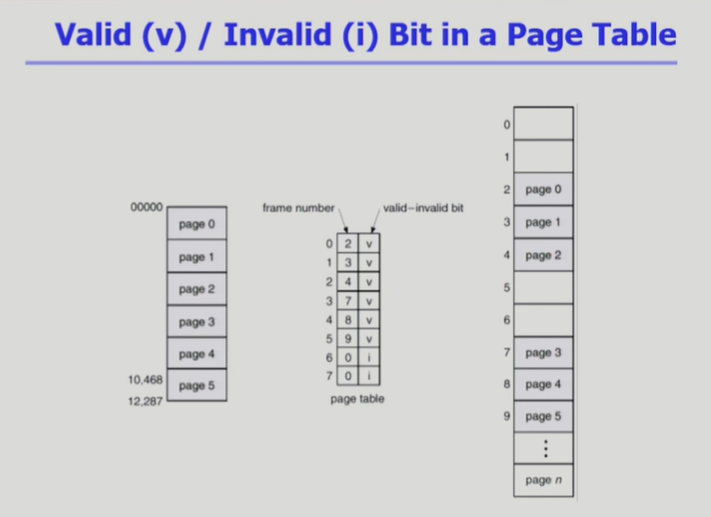
Q.entry는 총 몇 bit고 뭐뭐가 표시됨 그럼??
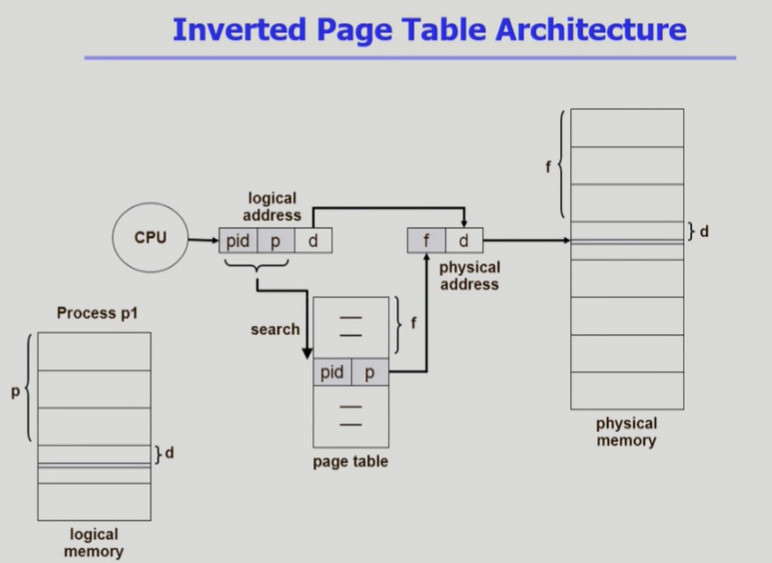
Inverted Page Table
- 지금까지 본 page table은 모든 process 별로 각각 logical address에 대응하는 모든 page에 대해 page table entry가 존재 했음
- 대응하는 page가 메모리에 있든 아니든 간에 page table에 entry로 존재
- Inverted page table은 page table이 프로세스별로 전부 존재하지 않고, 딱 하나만 존재

- physical memory의 물리적 frame을 page table에 표시
- page entry에는 frame번호가 적히는 것이 아니라, pid와 page번호가 적혀 있음
- 논리주소를 보고 쭉 탐색하면서 pid와 page번호를 발견하면 그만큼 떨어진 frame이 실제 물리 공간의 frame임을 확인하고 값을 읽어옴.
- 기존에는 page 번호를 통해 idx 접근하여 frame번호를 알아냈다면, pid와 page 번호를 통해 frame의 위치를 찾음
- page table을 1개만 만들어 저장하므로 공간 절약, 하지만 frame을 알아내기 위한 search로 인해 시간적 overhead 존재
- associative regiter에 저장해서 병렬 검색 활용하여 search 시간 단축
Q.process별로 하나씩 전부 존재할 때 각 page table은 모두 어디에 올라가 있었더라...? 저장위치?
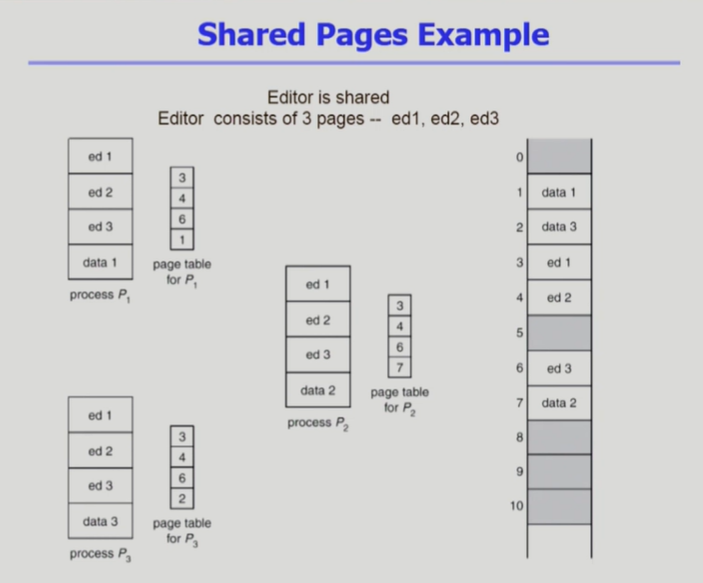
Shared Page

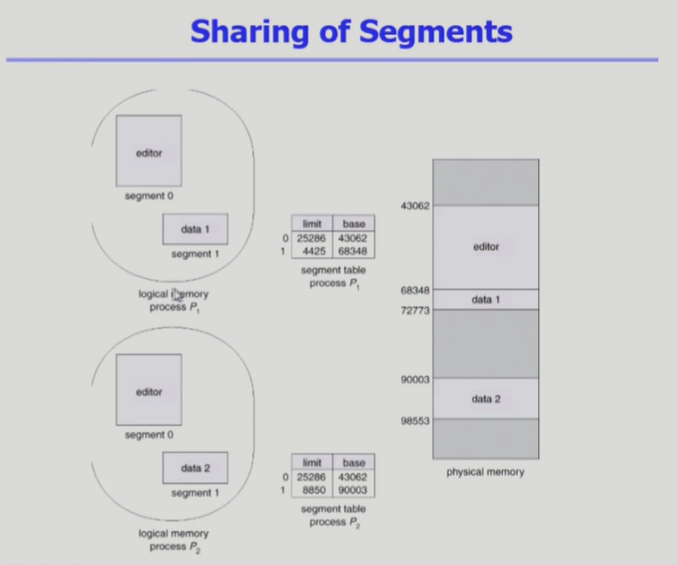
- Text editor와 같이 code영역은 같은 코드를 공유할 수 있고, data, stack 영역만 다른 프로세스들의 경우에 read-only 모드로 하여 code영역만 메모리에 올리고 여러 프로세스가 하나의 코드를 공유하도록 함.
- Shared code는 모든 프로세스의 logical address apce에서 동일한 위치에 있어야 함, 물리 메모리에 올라온 하나의 코드를 공유하는데, 이때 논리주소가 여러 개일 수가 없음, 하나의 논리 주소를 참조해서 editor pages 돌리는데, 공유하고 있는 여러 프로세스들의 논리 주소가 다르면 안 됨.
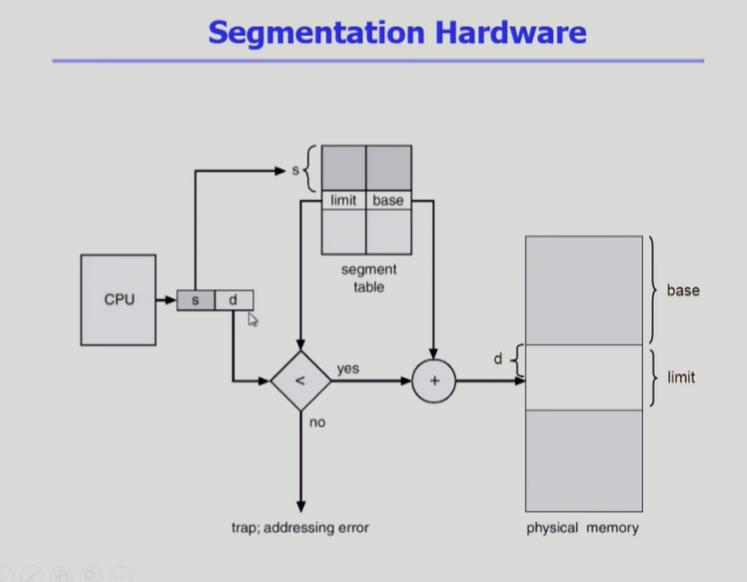
Segmentation
- Segement, 즉 의미 단위로 프로세스를 나누어 메모리에 올리는 방법
- 프로그램은 의미 단위인 여러 개의 segment로 구성
- 작게는 프로그램을 구성하는 함수 하나하나를 세그먼트로 정의
- 크게는 프로그램 전체를 하나의 세그먼트로 정의 가능
- 일반적으로 code, data, stack 부분이 하나씩의 세그먼트로 정의됨
- segment는 다음과 같은 logical unit 들임
- main(), function, global variables, stack, symbol table, arrays...

- logical address는 segment 번호와, segment에서 떨어진 위치로 구성됨
- segment table에서 segment 번호와 offset을 이용해 물리 주소인 base위치와 offset(d)를 찾음
- 의미 단위 갯수에 따라서 segment table의 entry 개수가 결정됨
- 페이징 기법과 달리 segment는 각각의 길이가 다르므로 limit을 가지고 있음
- s가 segment의 길이(segment의 수)보다 작은지 STLR에 저장된 값을 통해 확인하고, offset이 segment의 limit보다 작은지 table 값을 통해 확인하여 trap에걸리지 않으면(두 조건을 만족하면) 주소변환함

- paging기법과 다른 점
- segment의 limit은 결국 offset인 d를 표현할 수 있는 bit수에 의해 제한됨, 반면 page는 크기가 균일하기 때문에 offset의 크기가 페이지의 크기에 의해 결정됨(limit은 일정)
- paging은 물리메모리가 page크기와 동일한 크기의 frame으로 나뉘어져 있어서, frame 번호를 통해 물리메모리에 접근할 수 있지만, segment는 정확한 물리 주소의 시작 byte단위를 알아야 접근할 수 있음
- segment는 가변분할방식처럼 segment의 크기가 균일하지 않기 때문에 external fragmentation이 발생하고, first / best fit 방식을 사용해야 함(단점)
- segmentation의 장점?
- segment별로 protection을 할 수 있는데, 의미 단위인 code, data, stack 등의 기준 별로 protection을 부여하는 것은 자연스러움
- 반면 paging은 이렇게 의미 단위로 나눌 수 없어, 서로 다른 보안처리를 위한 추가적인 보완이 필요
- sharing에 있어서도 이렇게 의미 단위 공유가 자연스러워 효과적
- table을 위한 메모리 공간도 paging 기법이 훨씬 더 많이 차지함
- 실제 프로그램을 사용하면 의미단위로 나눌 때 쪼개지는 갯수가 크지 않음, 따라서 segment table도 굉장히 작음, paging 기법은 page table이 4KB로 나눴을 때 100만개 entry 존재했음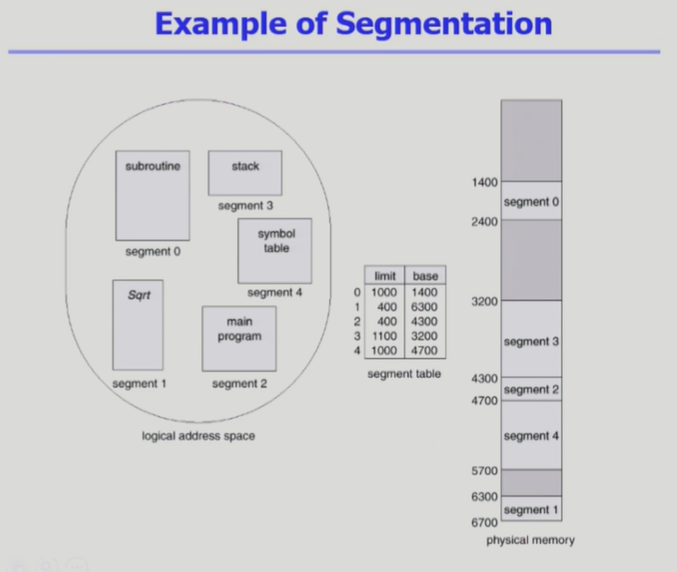
Segment with Paging(Paged Segment)
- segment를 여러 개의 page로 나눔
- 물리 메모리에는 page 단위로 올라감 -> allocation 문제 발생 X
- 의미단위가 유용한 보안같은 업무는 segment 레벨에서 진행
- 두 가지 장점 모두 가져감
- only segment system은 실제로 사용 X
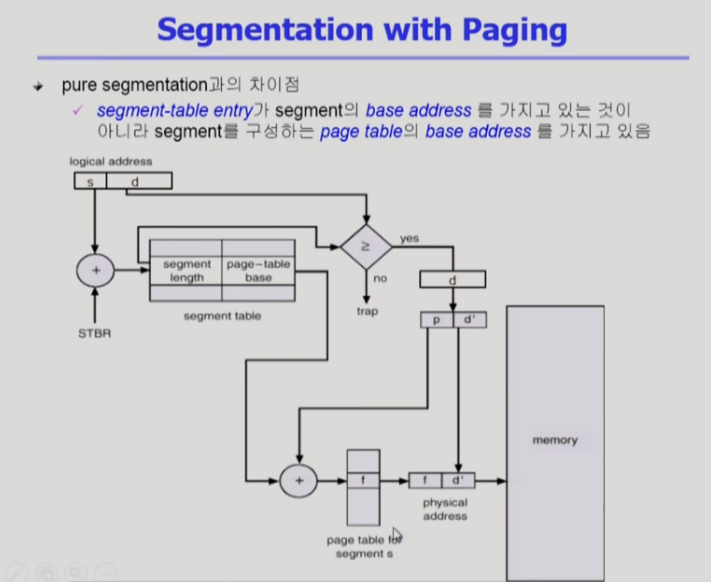
- segment번호 s와 segment table의 시작위치(from STBR)을 가지고 segment를 찾음
- segment table에서 page-table 시작위치를 찾음
- segment의 offset인 d를 page table for segment의 페이지 위치 p와 해당 페이지에서의 offset d"로 변환
- page table에서 p로 프레임 번호를 찾음
- 물리 메모리 주소로 변환
주소변환에서 운영체제의 역할은?
- 주소변환은 전부 HW가 해주는 역할, OS의 역할은 없었음
- Why? CPU는 logical address에서 physical address로 변환하여 memory에 접근하는 과정에서 운영체제의 개입을 받지 않음
- 만약 운영체제의 개입을 받는다면, CPU가 기계어 하나하나를 처리할 때마다 운영체제로 넘어가야 함
- 즉 주소변환과 연산의 과정때마다 운영체제 - 프로세스가 왔다 갔다하는 건 말이 안 됨
- HW가 도와주는 것임
- 운영체제에게 넘어가야 했던 것은 I.O나 DISK 접근할 때였음.
- 가상 메모리에서는 운영체제가 중요한 역할을 하게 될 것임.

Hello World