- 이 chapter는 paging 기법을 사용한다고 가정
- 실제로도 대부분이 paging 기법을 사용해 시스템을 구성함
Demand Paging

- 실제로 필요할 때 page를 메모리에 올리는 방법
- I/O 양 감소: 방어적인 소프트웨어 구현으로 인해 실제 핵심 기능이 아닌 에러, 버그 처리 등에 대한 코드가 많은데 이 코드들은 잘 실행되지 않음, 필요로 할 때만 메모리에 올릴 수 있기 때문에 I/O 양이 감소함.(필요로 할 때만 디스크에서 읽어오는 작업을 수행하기 때문에)
- Memory 사용량 감소
- 프로그램 여러 개가 동시에 메모리에 올라가는 멀티프로그래밍 환경에서 더 많은 프로그램, 사용자가 동시에 메모리에 올라갈 수 있음
- 이를 통해 빠른 응답시간을 기대할 수 있음
Q. 디스크 I/O가 뭐였지?

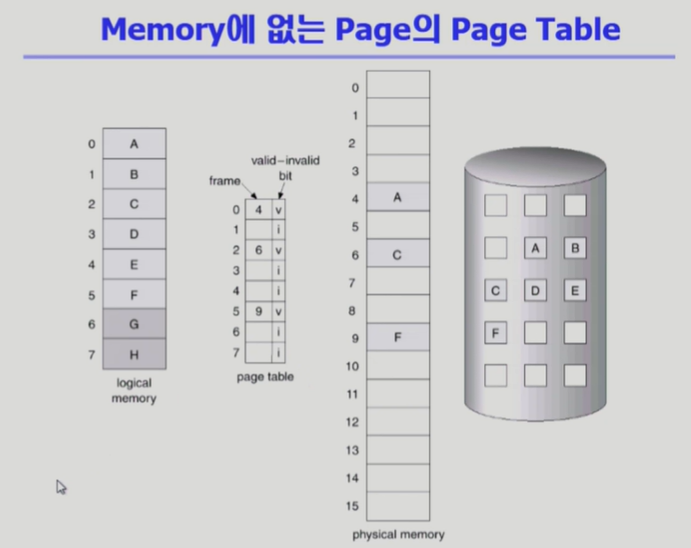
- Disk(Swap Area)에 내려가 있거나, 실제로는 사용하지 않는 공간의 경우 page table에 invalid bit가 표시되어 있음.
- demand paging을 쓰기 때문에 프로그램을 최초로 실행시키면 page table에는 entry가 전부 invalid로 표시되어 있다가, page가 메모리에 올라가면 valid로 바뀌면서 해당하는 frame 번호가 entry에 적히게 됨
page fault

-
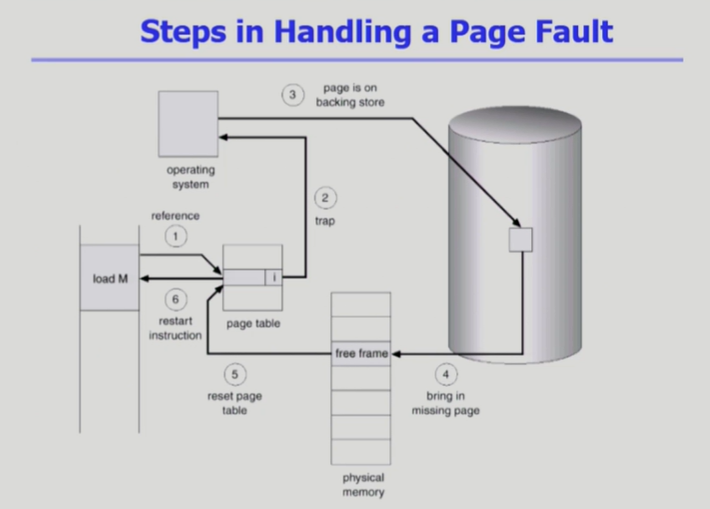
CPU가 logical address를 읽고 paga table에서 frame번호를 가져오려 하는데 invalid 상태이면 디스크에서 I/O를 수행해야 함, 요청한 page가 메모리에 없는 경우를 page fault라고 함, CPU는 자동적으로 운영체제에 넘어가고 운영체제가 CPU를 가지고 falut난 페이지를 메모리에 올리는 작업이 수행됨, page fault에 대한 처리 루틴이 운영체제에 정의되어 있음.
-
page fault 처리 루틴
- 유효한 요청인지 확인(잘못된 주소이거나 protection을 위반하지 않았는지)
- 빈 frame을 가져오거나 없으면 뺏어옴
- 해당 페이지를 disk에서 memory로 읽어옴
- disk I/O가 끝나기까지 이 프로세스는 CPU를 preempt 당함(blocked 상태로 전환), 운영체제는 disk controller 에게 I/O 작업을 지시하고 CPU를 다른 process에게 넘겨줌
- disk i/o가 끝나면 운영체제가 page tables entry를 기록하고 valid 처리
- 나중에 해당 프로세스가 다시 CPU를 잡게 되면 정상적으로 running
- page fault가 났을 때 disk에 접근하는 작업은 시간이 대단히 오래 걸림
- page fault의 비율을 통해 이 시간을 계산해볼 수 있음
- 실제로 시스템에서 조사해보면 거의 1에 가까운 0.0x..로 falut가 발생하고, 대부분이 직접 메모리에서 가져올 수 있음, 하지만 fault가 발생한다면 디스크 I/O 작업 수행을 위한 시간이 메모리 접근에 추가됨
- 메모리 접근 시간을 page fault까지 감안해서 계산한다면 OS & HW 작업, swap in/out 작업 등으로 overhead가 발생하는 시간까지 더해야 함


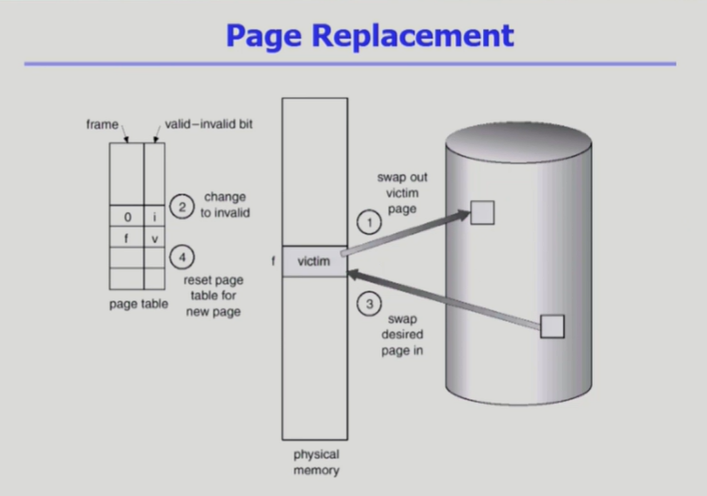
- Page replacement: O.S가 수행, algorithm으로 page-fault rate를 낮게 만들어야 함
- reference string: 시간 순으로 참조된 page 번호를 나타낸 것
- 만약 victim의 내용이 변경된 것이 있으면 disk에 변경 사항을 적용하고 swap out을 마무리 해야 함
replace algorithms

- page fault를 가장 적게하는 algorithm
- reference string을 알고 있다는 가정 하에 구현됨(실제로는 알 수 없음)
- 가장 먼 미래에 참조되는 page를 replace
- 실제 시스템에서 사용할 수는 없어서, offline optimal alogirhtm이라고도 함
- 빨간색은 page fault가 발생한 상황, 연보라는 memory에서 직접 가져온 상황을 가리킴
- 총 6번의 page faults 발생, 다른 어떤 알고리즘도 이보다 적게 fault를 낼 수 없음
- 다른 알고리즘들에 대한 upper bound 제공
- 어떤 paga를 참조할 지 미래를 모를 때 사용하는 알고리즘들
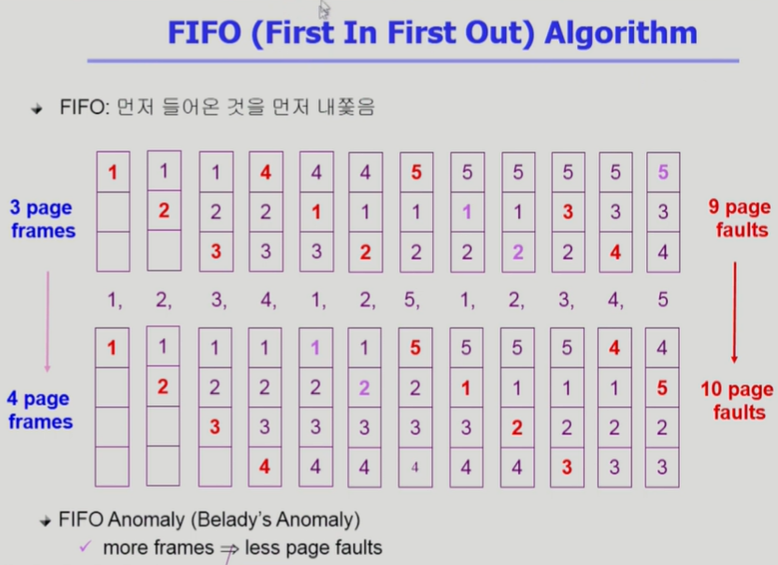
- FIFO: 가장 먼저 들어온 것을 쫓아냄
- FIFO Anomaly: 더 많은 frame을 사용해도 더 적은 page faults로 이어지지 않을 수 있음(성능이 나빠짐)
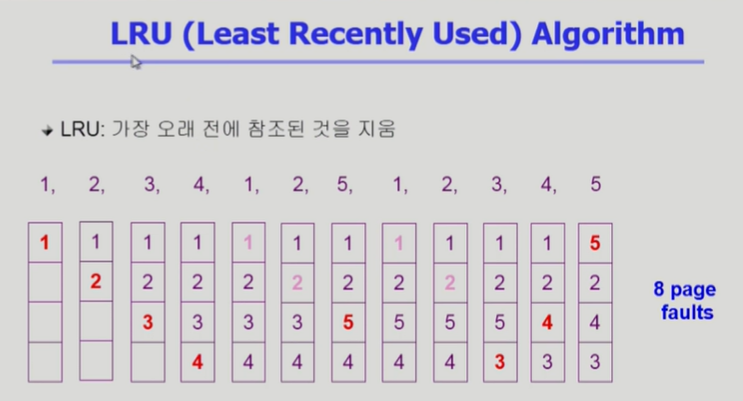
- LRU: 가장 오래전에 사용된 frame을 쫓아냄
- 가장 먼저 들어왔어도 재사용이 된 frame는 쫓아내지 않음

- LFU: 가장 덜 참조된(빈번하지 않은) page 쫓아냄

- LRU는 가장 자주 참조된 page임에도 불구하고 1번을 쫓아냄
- LFU는 가장 최근에 참조된 page임에도 불구하고 4번을 쫓아냄
- 이러한 장단점을 보완하기 위한 다양한 알고리즘들이 연구되고 있음
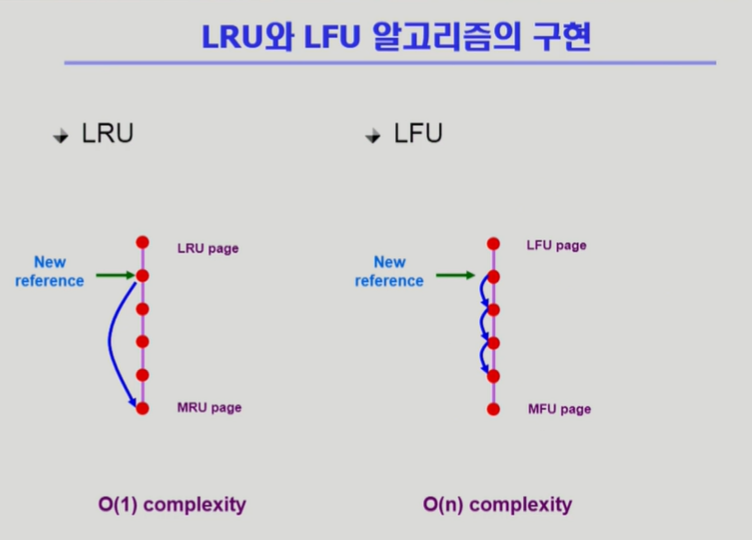
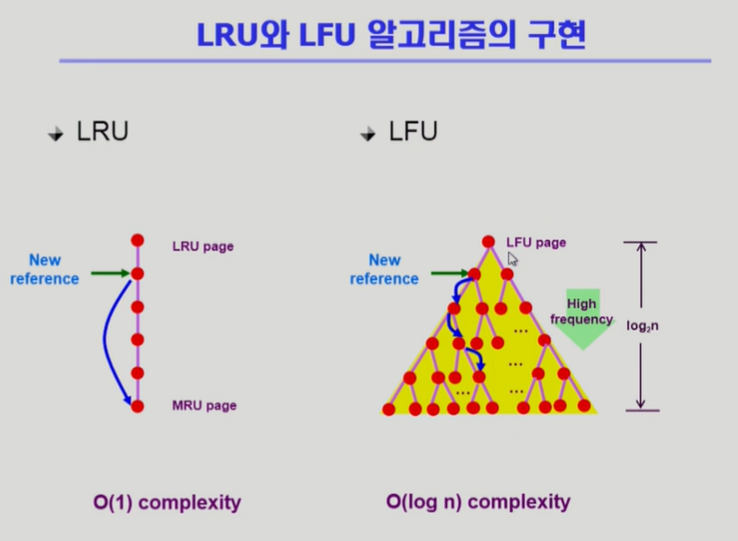
- LRU: LinkedList 형태로 참조된 시간 순에 따라 page를 관리
- 기존 메모리에서 재참조되거나, 혹은 새로 들어온 page가 있으면 가장 뒤쪽으로 보냄
- 재참조의 경우 연결을 끊고 맨 뒤로 보내기
- 쫓아낼 때는 제일 위에 PAGE를 쫓아냄
- 가장 위 page를 쫓아내면 되기 때문에 O(1)의 시간 복잡도를 가짐
- 근데 page가 이미 메모리에 올라와 있는지 찾고 있으면 list의 가장 마지막으로 보내는 건? 찾는 시간이 O(N)일 거 같은데?


Hello World