왜 서버의 로그들을 수집해야하는가?
우리는 서버의 모든 요청, 에러, 예외상황에 따른 로그들을 기록하여 저장하려 한다. 로그는 서버에서 발생한 이벤트와 동작의 기록을 제공한다. 문제가 발생했을 때 로그를 분석하면 문제의 근본 원인을 파악하고 디버깅에 도움이 된다. 로그는 오류 메시지, 예외 상황, 경고 및 기타 중요한 정보를 포함하므로 문제 해결에 필수적인 자료로 활용된다.
지난번 글에서도 winston을 통한 서버의 로그들을 기록하는 방법을 배웠다. 이 데이터들을 이제 폴더에만 저장하지 않고 Elasticsearch에 저장하여 Kibana를 통해 확인하려 한다.
로그 수집 flow
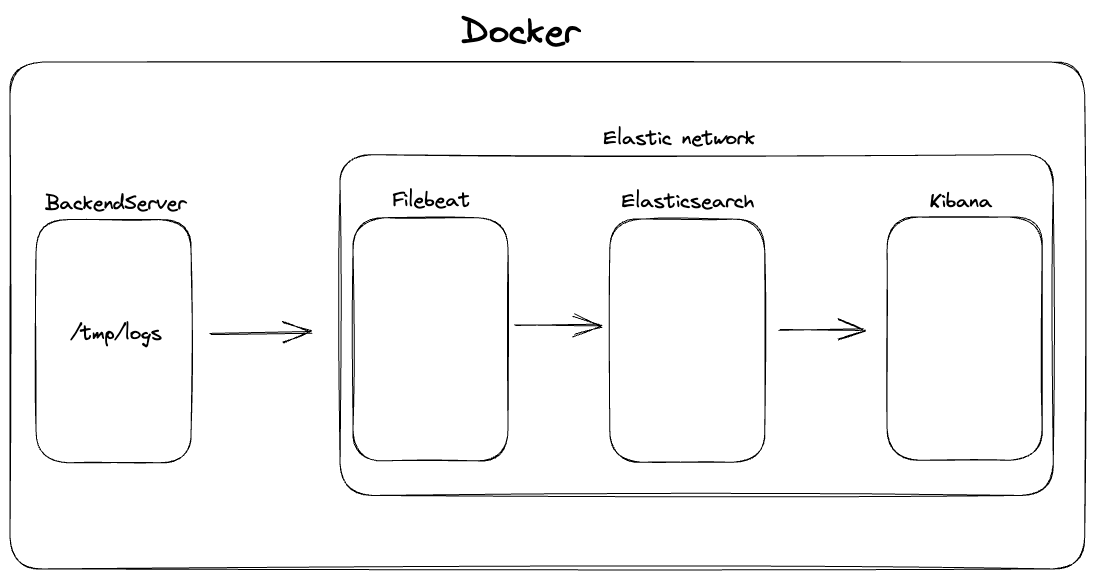
우리 서버는 우선 로그가 발생하면 /tmp/logs에 저장하도록 되어있다. 하지만 우리 서버는 컨테이너로 올라가 있어 로그가 생성된다고 하여도 우리 리눅스의 /tmp/logs에 저장되는 것이 아닌 컨테이너 내부의 /tmp/logs에 저장된다. 어떻게 파일들을 Filebeat가 변경될때마다 확인하여 Elasticsearch에 보낼 수 있는것일까? ELK스택을 하나씩 도커로 띄워보며 확인해보자.
Elasticsearch
docker network create elastic우선 ELK 스택들을 하나의 네트워크로 묶어주기 위해 elastic 네트워크를 생성해준다.
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.17.11Elasticsearch 이미지를 다운받는다. 최신버전은 8.x 버전이지만, 8.x버전 부터는 https통신이 요구되기 때문에 7.x버전으로 선택하였다. 나중에 nginx를 적용하고 https가 적용되면 8.x버전으로 올릴 것이다.
docker run --name elasticsearch --net elastic -d \
-p 127.0.0.1:9200:9200 -p 127.0.0.1:9300:9300 \
-e "discovery.type=single-node" \
docker.elastic.co/elasticsearch/elasticsearch:7.17.11그 다음, 이미지를 elastic 네트워크에 묶어 9200번과 9300번 포트에서 실행해준다.
왜 두개의 포트에서 실행해주는가?
Elasticsearch는 분산 검색 및 분석 엔진으로, 9200번 포트와 9300번 포트 두 개를 사용하여 작동한다.
9200번 포트는 Elasticsearch의 RESTful API를 통해 클라이언트와 상호 작용하는 데 사용된다. 간단하게 말해서 우리가 우리의 서버에서 Elasticsearch로 데이터를 보내는 REST API요청을 할때 사용된다는 것이다. 이를 통해 원격으로 Elasticsearch 클러스터에 액세스하고 데이터를 쿼리하거나 수정할 수 있다.
9300번 포트는 Elasticsearch 클러스터 내의 노드 간의 상호 통신에 사용된다. Elasticsearch는 분산 시스템으로 구성될 수 있으며, 클러스터에 속한 노드들은 데이터를 공유하고 작업을 분산하여 처리한다. 9300번 포트는 클러스터 내의 노드들이 서로 통신하고 데이터를 동기화하는 데 사용된다. 노드 간의 데이터 전송과 클러스터 관리 작업은 9300번 포트를 통해 이루어진다.
따라서, 9200번 포트는 Elasticsearch에 대한 외부 요청을 처리하고 데이터를 제공하며, 9300번 포트는 Elasticsearch 클러스터 내의 노드 간에 상호 통신을 지원한다.
하지만 아직 우리는 싱글노드방식을 이용하기 때문에 Elasticsearch 클러스터 내에 단일 노드만 존재하므로, 노드 간의 상호 통신이 필요하지 않다. 따라서 9300번 포트는 필요없게 된다. 하지만 싱글 노드 방식은 개발 및 테스트 환경 또는 작은 규모의 배포에 적합한 방식이다. 이는 Elasticsearch를 단독으로 실행하고 데이터를 로컬에서 처리하고 검색하는 데 사용할 수 있다. 하지만 나중에 멀티 노드 환경으로 수정할 것이기 때문에 9300번 포트도 사용할 예정이다.
멀티노드 방식은 싱글노드에 비해 무슨 이점이 있는가?
- 고가용성 및 장애 허용성: 멀티 노드 환경은 노드 간 데이터 복제 및 분산을 통해 고가용성을 제공한다. 데이터를 여러 노드에 분산 저장하고, 복제하여 하나의 노드가 고장나더라도 데이터의 손실을 방지하고 시스템의 가용성을 유지할 수 있다.
- 확장성: Elasticsearch는 수평 확장이 가능한 시스템다. 멀티 노드 환경에서는 새로운 노드를 추가하여 클러스터를 확장할 수 있다. 데이터 및 작업이 여러 노드로 분산되므로 시스템의 처리량을 증가시킬 수 있다.
- 검색 및 질의 성능: 멀티 노드 환경은 검색 및 질의 성능을 향상시킬 수 있다. 작업이 여러 노드에 분산되므로 데이터 처리 속도가 향상되고, 병렬 처리를 통해 대량의 데이터를 더 빠르게 처리할 수 있다.
- 부하 분산: 멀티 노드 환경에서는 요청을 여러 노드로 분산시켜 부하를 분산시킬 수 있다. 이를 통해 더 많은 동시 요청을 처리할 수 있고, 성능과 응답 시간을 향상시킬 수 있다.
- 데이터 복구 및 복제: 멀티 노드 환경에서는 데이터의 안정성과 신뢰성을 높일 수 있다. 데이터는 여러 노드에 복제되므로 하나의 노드가 실패해도 데이터는 여전히 사용 가능하며, 복구가 가능하다.
- 분산 작업 처리: 멀티 노드 환경에서는 작업이 여러 노드로 분산되므로 병렬 처리가 가능하다. 이를 통해 대량의 데이터를 처리하거나 복잡한 작업을 효율적으로 처리할 수 있다.
Kibana
docker pull docker.elastic.co/kibana/kibana:7.17.11Kibana이미지 다운로드
docker run --name kibana --net elastic -d \
-p 5601:5601 \
-e "ELASTICSEARCH_HOSTS=http://elasticsearch:9200" \
docker.elastic.co/kibana/kibana:7.17.11Kibana 컨테이너 실행
Filebeat
docker pull docker.elastic.co/beats/filebeat:7.17.11Filebeat 이미지 다운로드
filebeat.inputs:
- type: log
paths:
- /usr/share/filebeat/logs/info/**.log
tags: ["info"]
- type: log
paths:
- /usr/share/filebeat/logs/http/**.log
tags: ["http"]
- type: log
paths:
- /usr/share/filebeat/logs/error/**.log
tags: ["error"]
- type: log
paths:
- /usr/share/filebeat/logs/exception/**.log
tags: ["exception"]
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
hosts: ["http://es01-test:9200"]
#============================== Kibana =====================================
setup.kibana:
host: "http://kib01-test:5601"Filebeat는 실행하기전에 데이터들을 어떻게 처리해줄지, Elasticsearch와 kibana, logstash는 어디에 연결해야할지에 대한 설정파일인 filebeat.yml 수정해주어야 한다. 근데 문제가 생겼다. 우리는 도커로 filebeat를 실행할 건데 이 파일을 어떻게 컨테이너 안으로 넣어주어야 한단 말인가?
직접 파일 주입
docker exec -it filebeat /bin/bash
cd /usr/share/filebeat/filebeat.yml
vim filebeat.yml먼저 컨테이너를 실행한 다음, 컨테이너 내부에 들어가서 직접 파일을 수정해주는 방법이다. 이 방법이 제일 먼저 떠오를 것이지만, 이 방식은 컨테이너를 띄울때마다 파일을 수정해주어야 하므로 좋지않는 방법이다.
바인드 마운트 방식사용
docker run -d --name filebeat --network elastic \
--volume="/Users/minuminu/Desktop/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro" \
docker.elastic.co/beats/filebeat:7.17.11—volume을 이용하여 컨테이너가 실행될때 filebeat 컨테이너 내부에 파일을 넣어줄 수 있다. 이렇게 명령어를 작성해주면 /Users/minuminu/Desktop/ 에 있는 filebeat.yml파일로 컨테이너 내부의 /usr/share/filebeat/ 경로에 filebeat.yml을 덮어써줄 수 있다.
이렇게 도커 컨테이너 내부에 파일을 주입하면 로컬 시스템과 컨테이너 간에 파일의 변경이 서로에게 영향을 미친다. 우리의 로컬에서 filebeat.yml을 수정하면 컨테이너 내부의 filebeat.yml도 수정된다는 것이다.
ro?
ro는 "Read-Only"의 약어로, Docker 볼륨 마운트 시 읽기 전용 옵션을 설정하는 데 사용된다. ro를 볼륨 마운트 옵션으로 지정하면 해당 볼륨은 컨테이너 내부에서 읽기만 가능하고 쓰기가 불가능한 상태가 된다.
일반적으로 로그 파일과 같은 데이터를 볼륨으로 마운트할 때 읽기 전용으로 설정하는 것이 좋다. 이렇게 함으로써 컨테이너 외부에서 로그 파일을 수정하거나 덮어쓰는 등의 예기치 않은 작업을 방지할 수 있다. 또한, 볼륨이 읽기 전용으로 설정되어 있으면 로그 파일을 보다 안전하게 유지할 수 있다.
볼륨을 통한 로그 파일 감시하기
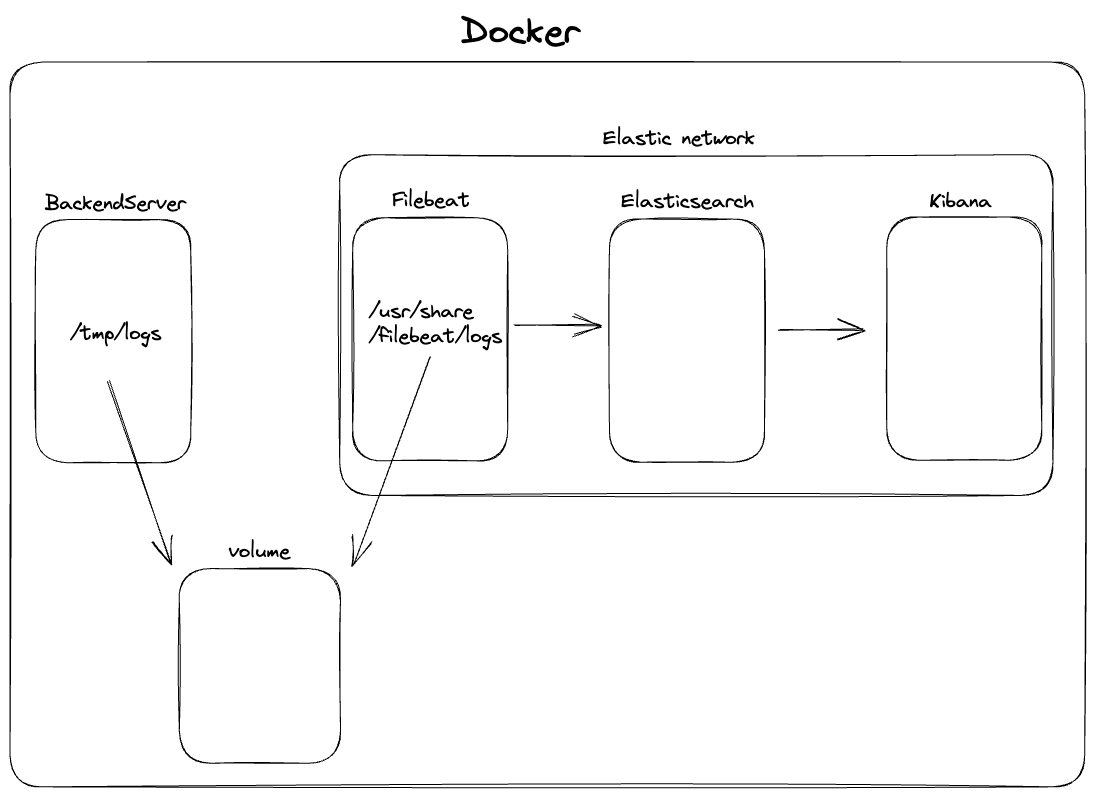
이제 우리는 로그파일들을 filebeat가 감시하여 변경될때마다 elasticsearch로 보내게 해주어야한다. 이번엔 도커 볼륨을 활용하여 우리 서버의 로그들을 filebeat에 연결해 주려한다.
볼륨은 마치 공유폴더와 같다. 우리 서버의 /tmp/logs폴더를 volume에 연결해주고, Filebeat의 /usr/share/filebeat/logs폴더도 같은 volume에 연결해주어서 /tmp/logs가 업데이트 될때마다 filebeat의 /usr/share/filebeat/logs도 업데이트 될 것이고, filebeat는 이 파일들을 Elasticsearch로 보내면 될 것이다.
docker create volume logs먼저 logs란 이름으로 volume을 생성해준다
docker volume lsls 명령어로 생성한 volume들을 확인할 수 있다.
>> docker inspect logs
[
{
"CreatedAt": "2023-07-03T04:26:18Z",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/logs/_data",
"Name": "logs",
"Options": null,
"Scope": "local"
}
]inspect 명령어로 volume을 확인해보면 우리 리눅스 컴퓨터 /var/lib/docker/volumes/logs/_data에 폴더가 생성된 것을 확인할 수 있다. 우리가 서버에 저장한 로그들은 여기에 저장될 것이고, filebeat에도 저장할 것이다.
docker run -d --name filebeat --network elastic \
-v logs:/usr/share/filebeat/logs \
docker.elastic.co/beats/filebeat:7.17.11그리고 logs volume을 filebeat에 이렇게 연결해주며 컨테이너를 실행해주면 된다.
docker run -d --name filebeat --network elastic \
--volume="/Users/minuminu/Desktop/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro" \
-v logs:/usr/share/filebeat/logs \
docker.elastic.co/beats/filebeat:7.17.11앞의 filebeat.yml파일까지 주입하는 명령어까지 추가하면 최종 명령어는 이렇게 된다.
docker run -d -p 80:4000 -v logs:/tmp/logs \
--name to1step ghcr.io/to1step/backend:v1.2.5당연히 우리 서버가 실행되는 컨테이너의 /tmp/logs들도 logs볼륨에 연결해주어야 하기 때문에 이렇게 실행해주어야한다.

이제 Kibana에 들어가보면 우리 서버의 로그들이 쌓여가는 것을 확인할 수 있다.
