이 글에서는 강화 학습(Reinforcement Learning, RL) 알고리즘을 공부하면서 필요한 용어들과 분류가 어떻게 이루어지는지에 대해 알아보겠다.
강화 학습(RL) 관련 용어
먼저 강화 학습(RL)과 관련된 용어들이다.
에이전트
에이전트는 RL에서 학습을 수행하는 주체, 즉 행위자를 뜻한다. 에이전트는 환경을 관찰하고, 행동을 선택하며, 보상을 받으면서 최적의 정책을 학습하는 역할을 수행한다.
환경
환경은 에이전트가 상호작용하며 학습을 하는 공간으로, 에이전트가 행동을 취했을 때 상태를 변화시키고 보상을 에이전트에게 제공하는 역할을 수행한다.
상태
상태는 에이전트가 환경에서 관찰할 수 있는 정보들의 집합으로, 현재의 상황을 나타내며, 에이전트가 다음 행동을 결정할때 사용한다.
행동
행동은 에이전트가 현재 상태에서 선택할 수 있는 동작으로, 에이전트의 행동은 환경에 영향을 주고, 새로운 상태와 보상을 초래한다.
보상
보상은 에이전트의 행동 결과로 환경에서 받은 신호로 숫자 값으로 받는다. 학습을 진행하며 에이전트는 이 보상의 총합을 최대화하는 것을 목표로 한다.
정책
정책은 에이전트가 각 상태에서 어떤 행동을 취할지 결정하는 전략으로, 확률적 정책과 결정론적 정책으로 나뉜다.
- 확률적 정책(Stochastic Policy): = 특정 상태에서 행동 a를 선택할 확률을 보여준다.
- 결정론적 정책(Deterministic Policy): = 특정 상태에서 하나의 행동 a를 보여준다.
가치 함수
가치 함수는 상태 혹은 상태-행동 쌍의 장기적 보상(가치)를 평가하는 함수로, 해당 환경과 행동을 취했을 때 이후에 받을 모든 보상들의 가중합으로 상태 가치 함수, 상태-행동 가치 함수가 있다.
- 상태 가치 함수 V(s): 상태 s에서 시작했을 때 받을 것으로 기대되는 총 보상
- 상태-행동 가치 함수 Q(s,a): 상태 s에서 행동 a를 했을 때 받을 것으로 기대되는 총 보상
할인 요인()
할인 요인은 미래 보상을 현재 가치로 할인하는 비율로 0에서 1까지의 값을 가지며, 즉각적인 보상과 장기적인 보상 간의 균형을 조절하는 역할이었다. 만약 이면, 미래 보상은 현재 보상의 90% 가치로 간주한다.
모델 기반(Model-Based) vs 모델 프리(Model-Free)
모델 기반과 모델 프리는 강화 학습(RL)에서 에이전트가 환경을 이해하고 학습하는 방식에 따라 구분된다.
모델 기반(Model-Based)
모델 기반은 에이전트가 환경의 모델을 학습하거나 알고 있다고 가정하고, 이를 활용해 행동을 계획하는 방식으로 주요 특징은 다음과 같다.
- 환경 모델 학습: 환경의 전이 확률 및 보상 함수를 명시적으로 학습한다.
- 계획: 학습한 모델을 기반으로 앞으로의 행동을 시뮬레이션하고 최적의 정책을 수립한다.
- 탐색 효율성: 환경의 동작을 시뮬레이션하기 때문에 샘플 효율성이 높다.
- 계산 비용: 모델 학습 및 계획 과정에서 계산 비용이 많이 든다.
모델 프리(Model-Free)
모델 프리는 환경의 모델을 명시적으로 학습하지 않고, 경험에 기반하여 정책이나 가치 함수를 직접 학습하는 방식으로, 주요 특징은 다음과 같다.
- 직접 학습: 상태-행동 쌍에 대한 가치를 학습하거나 정책을 직접 학습한다.
- 샘플 효율성 낮음: 모델을 학습하지 않으므로 많은 데이터를 필요로 한다.
- 단순성: 모델 학습 과정이 없기 때문에 구현이 단순하다.
위 두가지를 표로 정리하면 다음과 같이 나타낼 수 있다.
| 특징 | 모델 기반 (Model Based) | 모델 프리 (Model Free) |
|---|---|---|
| 환경 모델 필요 여부 | 필요(전이 확률, 보상 모델 학습) | 불필요 |
| 샘플 효율성 | 높음 | 낮음 |
| 계산 비용 | 높음 | 상대적으로 낮음 |
| 복잡한 환경 적응력 | 낮음 | 높음 |
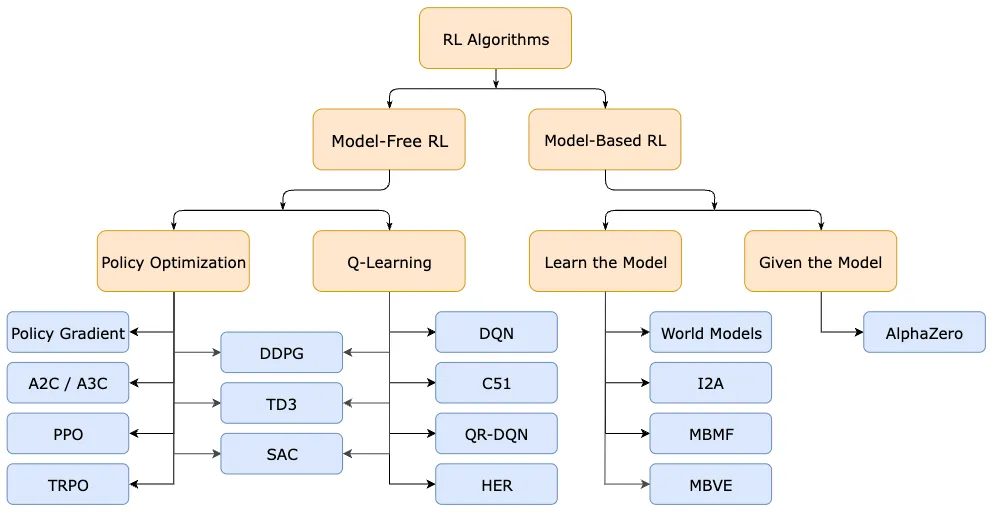
강화 학습(RL)의 분류
강화 학습(RL) 알고리즘은 크게 모델 프리(Model-Free)와 모델 기반(Model-Based)으로 나눌 수 있다.
Model-Free RL
Model-Free RL에서는 정책 자체를 학습하여 최적화하는 정책 최적화(Policy Optimization)와 가치 함수를 학습하여 행동을 선택하는 Q-Learning이 있다.
정책 최적화(Policy Optimization)
정책 최적화는 정책 자체를 학습하여 최적화하는 방법으로 주요 알고리즘은 Policy Gradient, A2C/A3C, PPO, TRPO가 있다.
- Policy Gradient: 정책의 그래디언트를 계산하여 업데이트
- A2C / A3C: 동시 다중 에이전트로 정책과 가치 함수를 학습
- PPO(Proximal Policy Optimization): 정책 업데이트의 안정성을 높인 알고리즘
- TRPO(Trust Region Policy Optimization): 정책 업데이트를 제한하여 안정성을 보장
Q-Learning
Q-Learning은 상태-행동 가치 함수를 학습하여 행동을 선택하는 방법으로 주요 알고리즘은 DDPG, TD3, SAC, DQN, C51, QR-DQN, HER가 있다.
- DDPG(Deep Deterministic Policy Gradient): 연속적 행동 공간에서 Q-Learning과 정책 기반 학습을 결합한 알고리즘
- TD3(Twin Delayed DDPG): DDPG의 개선 버전으로, 더 안정적인 학습
- SAC(Soft Actor-Critic): 최대 엔트로피 원칙을 사용해 탐색과 안정성을 높임
- DQN(Deep Q-Learning): 딥러닝을 활용해 Q-Learning 확장
- C51: 분포 기반의 Q-Learning 알고리즘
- QR-DQN(Quentile Regression DQN): Q-Learning에서 분포를 학습
- HER(Hindsight Experience Replay): 희소 보상 환경에서 학습을 가속화
Model-Based RL
Model-Based RL에서는 환경 모델을 학습하는 Learn the Model과 환경 모델이 주여진 경우인 Given the model이 있다.
Learn the Model(모델 학습)
Learn the Model은 환경 모델을 학습한 뒤 이를 활용해 행동을 결정하는 방법으로 주요 알고리즘은 World Models, I2A, MBMF, MBVE가 있다.
- World Models: 환경을 시뮬레이션하여 에이전트의 계획을 지원
- I2A(Imagination-Augmented Agent): 환경 모델을 기반으로 상상력을 통해 행동을 계획
- MBMF(Model-Based Model-Free): 모델 기반과 모델 프리 방법을 결합
- MBVE(Model-Based Value Expansion): 미래의 보상을 예측하여 가치 추정 정확도를 높임
Given the Model(모델이 주어진 경우)
Given the Model의 경우는 환경 모델이 이미 주어진 상황에서 학습을 하며, 주요 알고리즘은 AlphaZero가 있다.
- AlphaZero: 체스, 바둑 등 환경 모델이 명확한 게임에서 최적의 정책을 학습하는 알고리즘.(주의, 알파고와 같이 특정 게임에 종속되지는 않으며, 다양한 게임에 적용이 가능하다.)
다음은 위 설명한 분류 내용을 그림으로 나타낸 것이다.
출처: https://spinningup.openai.com/en/latest/spinningup/rl_intro2.html
