해쉬테이블 개요
- 해시(Hash): 데이터를 입력받아 완전히 다른 모습의 데이터로 바꾸는 작업
- 해시 테이블, 암호화, 데이터 축약등에 사용
- 데이터를 담을 테이블을 미리 크게 확보해놓은 후 입력받은 데이터를 해싱하여 테이블 내 주소를 계산하고 이 주소에 데이터를 담는 것
- 해시 테이블 -> 공간을 팔아 시간을 얻는다.
- 해싱으로 주소값을 얻는 과정은 상수 시간에 완료 : 테이블의 크기에 따른 성능 변화는 없다.
해시 함수
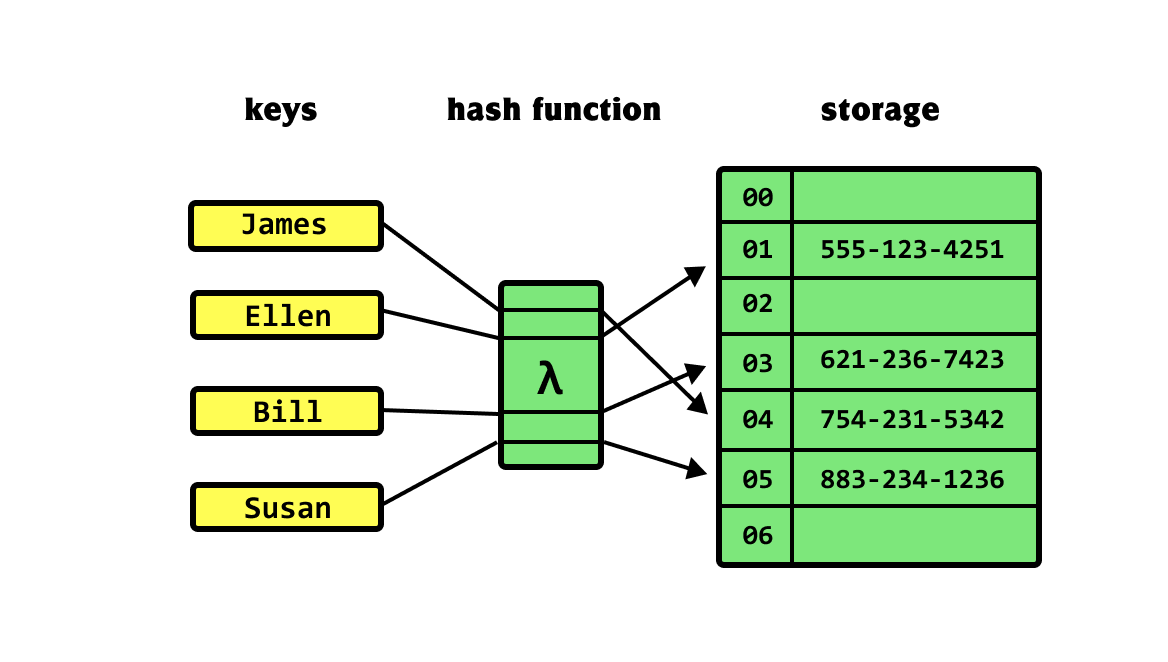
- Key : 주소로 사용할 데이터, Value : Key로 얻어낸 주소에 저장할 데이터, 유일한 값
- Value 값 자체를 인덱스로 사용할 수 없음 : value의 범위가 정해져 있지 않으며, value가 정수가 아닐 수 있음.
- Key값 자체를 주소로 사용할수 없음 : Key가 항상 정수가 아님. ex) Key가 사람이름이고 Value가 전화번호인 경우
- 따라서 Key를 주소로 사용하는 것이 아니라 해시 함수에 Key를 넣어 계산된 결과를 주소로 사용
- value와 key는 다른게 일반적이다. : value가 복잡한 구조체인 경우 이를 해싱하는데 어려움이 있을 수 있다.
- 또한 value와 key가 같다면 value를 업데이트 할때 key를 같이 업데이트 해야하는 문제 발생 이러면 key에따른 hash값 달라짐.
나눗셈법
- HashValue = Key % TableSize
- 0 ~ TableSize - 1 의 주소 반환 보장
int hashFunction(int key, int tableSize) {
return key % tableSize;
}
- 서로 다른 key에 대해 같은 hash갑을 반환할 가능성 높다. (Collision)
- 해시 테이블내 일부 지역의 주소들을 집중적으로 반환할 가능성 높다. (Cluster)]
- 충돌과 클러스터를 완전히 해결할 수 있는 알고리즘은 없다.
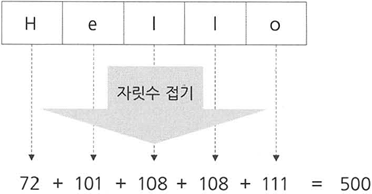
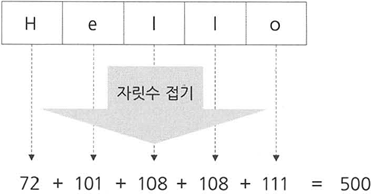
자릿수 접기
- 숫자의 각 자릿수를 더해 해시값을 만드는 것
- 문자열을 키로 사용하는 해시 테이블에 특히 잘어울림
int CHT_Hash(char* Key, int KeyLength, int TableSize) {
int hashValue = 0;
for (int i = 0; i < KeyLength; i++)
{
hashValue = (hashValue << 3) + Key[i]; // 놀게되는 앞 3bit 이용하도록
}
return hashValue % TableSize; // tablesize를 넘는 index가 안나오도록 조치
}충돌 해결 기법
- 충돌 : 해시 함수가 서로 다른 입력값에 대해 동일한 해시 테이블 주소를 반환 하는것.
- 해시 함수를 사용하는 한 충돌은 피할 수 없다.
- 해결방안
1) 해시 테이블 주소공간 바깥에 새로운 공간을 할당하여 문제를 수습 (Open Hashing)
2) 처음에 주어진 해시 테이블의 공간 안에서 문제를 수습 (Closed Hashing)
체이닝
- Open Hashing
연습문제
01
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef char* KeyType;
typedef char* ValueType;
typedef struct tagNode
{
KeyType Key;
ValueType Value;
struct tagNode* Next;
} Node;
typedef struct tagSet
{
Node* Setinfo;
KeyType data;
} Set;
typedef Node* List;
typedef struct tagHashTable
{
int TableSize;
List* Table;
} HashTable;
HashTable* CHT_CreateHashTable(int TableSize);
void CHT_DestroyHashTable(HashTable* HT);
Node* CHT_CreateNode(KeyType Key, ValueType Value);
void CHT_DestroyNode(Node* TheNode);
void CHT_Set(HashTable* HT, KeyType Key, ValueType Value);
ValueType CHT_Get(HashTable* HT, KeyType Key);
int CHT_Hash(KeyType Key, int KeyLength, int TableSize);
HashTable* CHT_CreateHashTable(int TableSize)
{
HashTable* HT = (HashTable*)malloc(sizeof(HashTable));
HT->Table = (List*)malloc(sizeof(List) * TableSize); // List = Node* 이므로 Node*의 배열은 Node**가 가르켜야 한다.
memset(HT->Table, 0, sizeof(List) * TableSize); // 포인터에서는 NULL = 0
HT->TableSize = TableSize;
return HT;
}
void CHT_DestroyHashTable(HashTable* HT)
{
for (int i = 0; i < HT->TableSize; i++)
{
List L = HT->Table[i];
CHT_DestroyNode(L);
}
free(HT->Table);
free(HT);
}
Node* CHT_CreateNode(KeyType Key, ValueType Value)
{
Node* NewNode = (Node*)malloc(sizeof(Node));
NewNode->Key = (char*)malloc(sizeof(char) * (strlen(Key) + 1));
strcpy(NewNode->Key, Key);
NewNode->Value = (char*)malloc(sizeof(char) * (strlen(Value) + 1));
strcpy(NewNode->Value, Value);
NewNode->Next = NULL;
return NewNode;
}
void CHT_DestroyNode(Node* TheNode)
{
free(TheNode->Key);
free(TheNode->Value);
free(TheNode);
}
void CHT_Set(HashTable* HT, KeyType Key, ValueType Value) // 노드 삽입
{
int index = CHT_Hash(Key, strlen(Key), HT->TableSize);
Node* NewNode = CHT_CreateNode(Key, Value);
if (HT->Table[index] == NULL) // 충돌발생 X
{
HT->Table[index] = NewNode;
}
else // 충돌발생
{
List list = HT->Table[index];
HT->Table[index] = NewNode;
NewNode->Next = list;
printf("충돌발생 : Key(%s), address(%d)\n", Key, index);
}
}
ValueType CHT_Get(HashTable* HT, KeyType Key) // 다른방식으로 구현
{
int index = CHT_Hash(Key, strlen(Key), HT->TableSize);
List current = HT->Table[index];
while (1)
{
if (current == NULL)
{
break;
}
else if (strcmp(current->Key, Key) == 0)
{
break;
}
else
{
current = current->Next;
}
}
if (current != NULL)
{
return current->Value;
}
}
List CHT_GetList(HashTable* HT, KeyType Key) // 다른방식으로 구현
{
int index = CHT_Hash(Key, strlen(Key), HT->TableSize);
List current = HT->Table[index];
while (1)
{
if (current == NULL)
{
break;
}
else if (strcmp(current->Key, Key) == 0)
{
break;
}
else
{
current = current->Next;
}
}
if (current != NULL)
{
return current;
}
}
int CHT_Hash(KeyType Key, int KeyLength, int TableSize) {
int hashValue = 0;
for (int i = 0; i < KeyLength; i++)
{
hashValue = (hashValue << 3) + Key[i];
}
return hashValue % TableSize; // tablesize를 넘는 index가 안나오도록 조치
}
Set* makeSet(HashTable* HT, KeyType data) { // 집합 생성
Set* newSet = (Set*)malloc(sizeof(Set));
newSet->Setinfo = (Node*)malloc(sizeof(Node));
newSet->Setinfo->Key = data;
newSet->Setinfo->Value = data;
newSet->Setinfo->Next = NULL;
newSet->data = data;
CHT_Set(HT, data, data); // hash table에는 key = value인 상태로 등록
return newSet;
}
ValueType findSet(HashTable* HT, Set* targetSet) { // 집합이 어디에 속해있는지 찾기 : 집합의 data값을 key로했을때 value값
ValueType targetValue;
KeyType key = targetSet->Setinfo->Key;
while (1)
{
targetValue = CHT_Get(HT, key); // key == value인 값이 나올때 그 set이 Root set이다.
printf("%s -> ", targetValue);
if (targetValue == key)
{
break;
}
key = targetValue;
}
printf("\n");
return targetValue; // rootset의 value 반환
}
void unionSet(HashTable* HT, Set* set_1, Set* set_2) { // 상위 집합의 value를 하위 집합의 value로 업데이트하기
set_2->Setinfo = set_1->Setinfo;
ValueType Value_1 = CHT_Get(HT, set_1->Setinfo->Key);
List List_2 = CHT_GetList(HT, set_2->data);
List_2->Value = Value_1;
}
int main(void) {
HashTable* HT = CHT_CreateHashTable(12289);
Set* set_1 = makeSet(HT, "Han");
Set* set_2 = makeSet(HT, "Kim");
Set* set_3 = makeSet(HT, "Lee");
Set* set_4 = makeSet(HT, "Choi");
Set* set_5 = makeSet(HT, "Park");
//printf("set1 : %s == set2 : %s -> %d\n", findSet(HT, set_1), findSet(HT, set_2), findSet(HT, set_1) == findSet(HT, set_2));
//printf("set1 : %s == set3 : %s -> %d\n", findSet(HT, set_1), findSet(HT, set_3), findSet(HT, set_1) == findSet(HT, set_3));
unionSet(HT, set_1, set_3); // Lee를 Han으로
printf("set1 : %s == set3 : %s -> %d\n", findSet(HT, set_1), findSet(HT, set_3), findSet(HT, set_1) == findSet(HT, set_3));
unionSet(HT, set_2, set_1);
printf("set2 : %s == set3 : %s -> %d\n", findSet(HT, set_2), findSet(HT, set_3), findSet(HT, set_2) == findSet(HT, set_3));
unionSet(HT, set_5, set_2);
printf("set5 : %s == set3 : %s -> %d\n", findSet(HT, set_5), findSet(HT, set_3), findSet(HT, set_5) == findSet(HT, set_3));
printf("set5 : %s == set1 : %s -> %d\n", findSet(HT, set_5), findSet(HT, set_1), findSet(HT, set_5) == findSet(HT, set_1));
unionSet(HT, set_4, set_5);
printf("set4 : %s == set3 : %s -> %d\n", findSet(HT, set_4), findSet(HT, set_3), findSet(HT, set_4) == findSet(HT, set_3));
printf("%s\n", set_3->data);
printf("set1: %s\n", CHT_Get(HT, set_1->Setinfo->Key));
printf("set2: %s\n", CHT_Get(HT, set_2->Setinfo->Key));
printf("set3: %s\n", CHT_Get(HT, set_3->Setinfo->Key));
printf("set4: %s\n", CHT_Get(HT, set_4->Setinfo->Key));
printf("set5: %s\n", CHT_Get(HT, set_5->Setinfo->Key));
}Han -> Han ->
Han -> Han ->
Han -> Han ->
Han -> Han ->
set1 : Han == set3 : Han -> 1
Kim -> Kim ->
Kim -> Kim ->
Kim -> Kim ->
Kim -> Kim ->
set2 : Kim == set3 : Kim -> 1
Park -> Park ->
Kim -> Park -> Park ->
Kim -> Park -> Park ->
Park -> Park ->
set5 : Park == set3 : Park -> 1
Park -> Park ->
Park -> Park ->
Park -> Park ->
Park -> Park ->
set5 : Park == set1 : Park -> 1
Choi -> Choi ->
Kim -> Park -> Choi -> Choi ->
Kim -> Park -> Choi -> Choi ->
Choi -> Choi ->
set4 : Choi == set3 : Choi -> 1
Lee
set1: Park
set2: Choi
set3: Kim
set4: Choi
set5: Choi02
-
레드 블랙 트리 :
장점 : 리스트에 비해 빠른 시간에 탐색을 할 수 있다.
단점 : 여러 자료형에 대해 비교할 수 있는 비교자를 만들어야 함.
트리 규칙을 만족하는데에 연산이 필요 -
해쉬 테이블 :
장점: 충돌이 발생한 케이스에서 값을 찾아내는데 가장 빠른 시간이 걸림
단점: 해쉬 테이블을 이용하는데 막대한 공간이 필요
03
체이닝과 개방 주소법을 같이 사용할 경우 탐사 이동횟수를 덜 할 수 있다.다만 몇 번째 탐색부터 체이닝을 할 것인지 정하지 않는다면 탐사를 제대로 하기도 전에 체이닝 되어 탐색 효율이 떨어질 수 있다.
