-
아이템 42: 익명 클래스보다는 람다를 사용하라
-타입을 명시해야 코드가 더 명확할 때만 제외하고는 람다의 모든 매개변수 타입은 생략하자.
-람다는 이름이 없고 문서화도 못하기 때문에 코드 자체로 동작이 명확히 설명되지 않거나 코드 줄 수가 많아지면 람다를 쓰지 말아야함
-열거 타입 생성자 안의 람다는 열거 타입의 인스턴스 멤버에 접근할 수 없음
-람다는 자기 자신을 참조할 수 없음 (람다에서 this 키워드는 바깥 인스턴스를 가리킴)
-람다는 직렬화를 삼가야함, 직렬화해야만 하는 함수 객체가 있다면(Comparator) private 정적 중첩 클래스의 인스턴스를 사용하자. -
아이템 43: 람다보다는 메서드 참조를 사용하라
-map.merge(key, 1, (count, incr) -> count + incr);
-> map.merge(key, 1, Integer::sum);
-인스턴스 메서드를 참조하는 유형 2가지
1) 수신 객체를 특정하는 한정적 인스턴스 메서드 참조
-함수 객체가 받는 인수와 참조되는 메서드가 받는 인수가 똑같음
2) 수신 객체를 특정하지 않는 비한정적 인스턴스 메서드 참조
-함수 객체를 적용하는 시점에 수신 객체를 알려줌, 주로 스트림 파이프라인에서의 매핑과 필터 함수에 쓰임
-5가지 메서드 참조
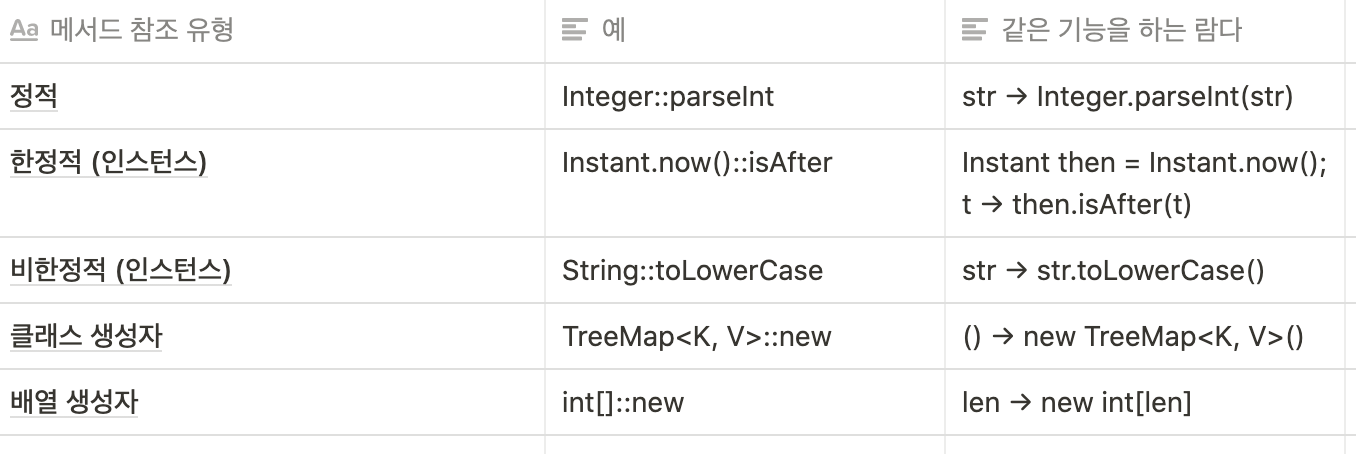
-메서드 참조 쪽이 짧고 명확하다면 메서드 참조를 쓰고, 그렇지 않을 때만 람다를 사용하라. -
아이템 44: 표준 함수형 인터페이스를 사용하라
-람다를 지원하면서 템플릿 메서드 패턴(상위 클래스의 기본 메서드를 재정의해 원하는 동작을 구현)의 매력이 크게 줄었음
-> 템플릿 메서드 패턴을 대체하는 것은 같은 효과의 함수 객체를 받는 정적 팩터리나 생성자를 제공하는 것
-> 함수 객체를 매개변수로 받는 생성자와 메서드를 더 많이 만들어야함, 이때 함수형 매개변수 타입을 올바르게 선택해야함
-필요한 용도에 맞는 게 있다면, 직접 구현하지 말고 표준 함수형 인터페이스를 활용하라.
-@Functional Interface 애너테이션을 사용하는 이유
1) 인터페이스가 람다용으로 설계된 것임을 알려줌
2) 인터페이스가 추상 메서드를 오직 하나만 가지고 있어야 컴파일되게 해줌
3) 누군가 실수로 메서드를 추가하지 못하게 막아줌
-직접 만든 함수형 인터페이스에는 항상 @Functional Interface 애너테이션을 사용하라
-서로 다른 함수형 인터페이스를 같은 위치의 인수로 받는 메서드들을 다중 정의해서는 안됨 -
아이템 45: 스트림은 주의해서 사용하라
-스트림은 데이터 원소의 유한 혹은 무한 시퀀스를 뜻함
-스트림 파이프라인은 이 원소들로 수행하는 연산 단계를 표현하는 개념
-스트림 API는 메서드 연쇄를 지원하는 플루언트API
-> 파이프라인 하나를 구성하는 모든 호출을 연결하여 단 하나의 표현식으로 완성할 수 있음
-람다에서는 타입 이름을 자주 생략하므로 매개변수 이름을 잘 지어야 스트림 파이프라인의 가독성이 유지됨
-char 값들을 처리할 때는 스트림을 삼가는 편이 낫다.
-기존 코드는 스트림을 사용하도록 리팩터링하되, 새 코드가 더 나아 보일 때만 반영하자
-스트림을 적용하기 좋은 일들
1) 원소들의 시퀀스를 일관되게 변환
2) 원소들의 시퀀스를 필터링
3) 원소들의 시퀀스를 하나의 연산을 사용해 결함(더하기, 연결하기, 최솟값 구하기 등..)
4) 원소들의 시퀀스를 컬렉션에 모음(공통된 속성을 기준으로 묶어서..)
5) 원소들의 시퀀스에서 특정 조건을 만족하는 원소를 찾음 -
아이템 46: 스트림에서는 부작용 없는 함수를 사용하라
-스트림 패러다임의 핵심은 계산을 일련의 변환으로 재구성하는 부분임
-> 각 변환 단계는 가능한 한 이전 단계의 결과를 받아 처리하는 순수 함수여야함
-> 순수 함수: 오직 입력만이 결과에 영향을 주는 함수, 다른 가변 상태를 참조하지 않고, 함수 스스로도 다른 상태를 변경하지 않음
-forEach 연산은 스트림 계산 결과를 보고할 때만 사용하고, 계산하는 데는 쓰지말자.
-collector(수집기)는 스트림의 원소들을 객체 하나에 취합한다는 뜻
-toList(), toSet(), toCollection(collectionFactory)
-Collectors의 멤버를 정적 임포트하여 쓰면 스트림 파이프라인 가독성이 좋아짐
-toMap(keyMapper, valueMapper)는 스트림 원소를 키에 매핑하는 함수와 값에 매핑하는 함수를 인수로 받음
-groupingBy는 입력으로 분류 함수를 받고 출력으로는 원소들을 카테고리별로 모아 놓은 맵을 담은 수집기를 반환함, 분류 함수는 입력받은 원소가 속하는 카테고리를 반환함, 이 카테고리가 해당 원소의 맵 키로 쓰임
-가장 중요한 수집기 팩터리는 toList(), toSet(), toMap(), groupingBy, joining -
아이템 47: 반환 타입으로는 스트림보다 컬렉션이 낫다
-객체 시퀀스를 반환하는 메서드를 작성하는데, 이 메서드가 오직 스트림 파이프라인에서만 쓰일 걸 안다면 마음 놓고 스트림을 반환하고, 반대로 반환된 객체들이 반복문에서만 쓰일 걸 안다면 Iterable을 반환하자.
-Collection 인터페이스는 Iterable의 하위 타입이고 stream 메서드도 제공하니 반복과 스트림을 동시에 지원함, 따라서 원소 시퀀스를 반환하는 공개 API의 반환 타입에는 Collection이나 그 하위 타입을 쓰는 게 일반적으로 최선임
-Stream.concat 메서드는 반환되는 스트림에 빈 리스트를 추가하며, flatMap 메서드는 모든 프리픽스의 모든 서픽스로 구성된 하나의 스트림을 만든다. -
아이템 48: 스트림 병렬화는 주의해서 적용하라
-데이터 소스가 Stream.iterate거나 중간 연산으로 limit를 쓰면 파이프라인 병렬화로는 성능 개선을 기대할 수 없음
-스트림의 소스가 ArrayList, HashMap, HashSet, ConcurrentHashMap의 인스턴스거나 배열, int 범위일 때 병렬화의 효과가 가장 좋음
-종단 연산 중 병렬화에 가장 적합한 것은 축소(파이프라인에서 만들어진 모든 원소를 하나로 합치는 작업)
-> reduce 메서드 중 하나 혹은 min, max, count, sum과 같이 완성된 형태로 제공되는 메서드 중 하나를 선택해 수행
-anyMatch, allMatch, noneMatch 처럼 조건에 맞으면 바로 반환되는 메서드도 병렬화에 적합
-반대로, 가변 축소를 수행하는 Stream의 collect 메서는 병렬화에 적합하지 않음(컬렉션들을 합치는 부담이 크기 때문)
-Stream, Iterable, Collection이 병렬화의 이점을 제대로 누리게 하고 싶다면 spliterator 메서드를 반드시 재정의하고 결과 스트림의 병렬화 성능을 강도 높게 테스트해라.
-무작위 수들로 이뤄진 스트림을 병렬화하려면 ThreadLocalRandom(혹은 구식인 Random) 보다는 SplittableRandom 인스턴스를 이용하라.
-계산도 올바로 수행하고 성능도 빨라질 거라는 확신 없이는 스트림 파이프라인 병렬화는 시도조차 하지 말라.
