함수형 프로그래밍이란
부수효과가 없는 순수 함수를 작성하여 가독성을 높이고 유지보수를 용이하게 해주는 프로그래밍 방법이다. 부수효과가 없는 순수 함수는 데이터의 값을 변경시키지 않고 객체의 필드를 설정하는 등의 작업을 하지 않는 것을 의미한다.
(순수 함수: 동일한 입력에 대해 항상 동일한 출력을 반환하는 함수, 외부의 상태를 변경하거나 영향을 받지 않는 함수)
대입문을 사용하지 않는 프로그래밍이라고도 한다. 부수효과(변수의 값이 바뀌거나 객체의 필드값을 설정하거나 예외나 오류가 발생하여 실행이 중단되거나..)가 없다.
람다식이란
-자바에서 함수형 프로그래밍을 구현하는 방식으로 함수의 이름과 반환타입 없이 손쉽게 함수를 선언할 수 있다. 자바8부터 지원되고 함수형 인터페이스를 선언해야 한다. 람다식이 함수형 인터페이스의 구현체이다. 외부 변수를 사용하지 않고 매개 변수만을 사용하기 때문에 외부 자료에 대한 side effect이 발생하지 않는다. 외부에 영향을 미치지 않으므로 병렬처리가 가능하고 확장성 있는 안정적인 프로그래밍이 가능하다.
-@FunctionalInterface 어노테이션을 사용하면 함수형 인터페이스라는 의미이다. 람다식을 다루기 위한 인터페이스이다. 이 어노테이션을 선언하면 함수형 인터페이스에서는 오직 하나의 추상 메서드만 선언되어야 한다.
-메서드를 람다식으로 표현하면 메서드의 이름과 반환값이 없어지므로 익명 함수라고도 한다. (익명함수는 일급 객체이다.)
public class StringTest {
public static void main(String[] args) {
StringConcatImpl impl = new StringConcatImpl();
impl.makeString("hello", "world");
StringConcat concat = (s, v) -> System.out.println(s + " , " + v);
concat.makeString("hello", "world");
StringConcat concat2 = new StringConcat() {
@Override
public void makeString(String s1, String s2) {
System.out.println(s1 + " , " + s2);
}
};
concat2.makeString("hello", "world");
}
}-람다식 내에서 참조하는 지역변수는 final이 붙지 않아도 상수로 간주된다.
- 문법
1) 매개 변수가 하나인 경우 괄호 생략 가능 (두개인 경우는 생략 불가)
str -> {System.out.println(str);}
2) 매개 변수의 타입이 있으면 괄호를 생략할 수 없다.
(String str) -> System.out.println(str);3) 중괄호 안에 구현부가 한 문장인 경우 중괄호를 생략할 수 있다.
str -> System.out.println(str);4) 중괄호 안의 구현부가 한 문장이라도 return 문은 중괄호를 생략할 수 없다.
str -> return str.length(); // 오류5) 중괄호 안의 구현부가 반환문 하나라면 return과 중괄호를 모두 생략할 수 있다.
(x, y) -> x+y
str -> str.length()java.util.function 패키지

*참고자료 - Java의 정석
-Predicate는 조건식을 람다식으로 표현하는데 사용된다.
-매개변수가 2개인 함수형 인터페이스는 이름 앞에 접두사 "Bi"가 붙는다.
스트림이란
Array나 Collection같은 데이터를 연속적으로 가공해서 처리할 수 있게 도와주는 클래스이다.
-
특징
-자료의 대상과 관계없이 동일한 연산을 수행할 수 있는 기능 (자료의 추상화)
-배열, 컬렉션에 동일한 연산이 수행되어 일관성 있는 처리가 가능
-한 번 생성하고 사용한 스트림은 재사용할 수 없음
-스트림 연산은 기존 자료를 변경하지 않음 (다른 메모리에서 연산 수행)
-중간 연산과 최종 연산으로 구분된다.
-최종 연산이 수행되어야 모든 연산이 적용되는 지연 연산이다. -
Stream API는 3가지 종류가 있다.
1) 시작 연산
Stream 객체가 아닌 다른 source로부터 Stream 객체를 얻는 연산이다. (ex) Arrays.stream(arr))
2) 중간 연산 - filter(), map()
조건에 맞는 요소를 추출 (filter()) 하거나 요소를 변환함 (map())
연산결과를 스트림으로 반환하기 때문에 중간 연산을 연속해서 연결할 수 있다.
최종 연산이 수행되기 전까지는 중간 연산이 수행되지 않는다.
3) 최종 연산
스트림의 자료를 소모하면서 연산을 수행한다. 최종 연산 후에 스트림은 더 이상 다른 연산을 적용할 수 없다.
forEach(): 요소를 하나 씩 꺼내옴
count(): 요소의 개수
sum(): 요소의 합 등..
3) reduce 연산
정의된 연산이 아닌 프로그래머가 직접 지정하는 연산을 적용하는 것으로 최종 연산으로 스트림의 요소를 소모하며 연산을 수행한다. 람다식으로 구현할 수도 있고 직접 구현해서 메서드 호출을 통해 사용할 수도 있다.
class CompareString implements BinaryOperator<String> {
@Override
public String apply(String s1, String s2) {
if (s1.getBytes().length >= s2.getBytes().length)
return s1;
else return s2;
}
}
public class ReduceTest {
public static void main(String[] args) {
String[] greetings = {"안녕하세요~~", "hello", "Good morning", "반갑습니다."};
// System.out.println(Arrays.stream(greetings).reduce("", (s1, s2) -> {
// if (s1.getBytes().length >= s2.getBytes().length)
// return s1;
// else return s2;
// }));
System.out.println(Arrays.stream(greetings).reduce(new CompareString()).get());
}
}스트림 수직적인 구조
Stream API는 수직적인 구조로 진행이 되기 때문에 실행 순서를 고려하는 것이 상당히 중요하다. 잘못된 실행 속도는 연산의 횟수를 불필요하게 증가시키기 때문이다.
Stream.of("a", "b", "c", "d", "e")
.filter(s -> {
System.out.println("filter : " + s);
return true;
})
.forEach(s -> System.out.println("forEach : " + s));이 결과는 filter가 모두 수행되고 forEach가 수행되는 수평적인 구조가 아니라 filter a / forEach a, filter b / forEach b ... 이렇게 각각의 데이터에 대해 filter와 forEach가 먼저 수행되는 수직적인 구조이다.
Stream.of("a", "b", "c", "d", "e")
.map(s -> {
System.out.println("map : " + s);
return s.toUpperCase();
})
.anyMatch(s -> {
System.out.println("anyMatch : " + s);
return s.startsWith("A");
});이 결과는 map 5번, anyMatch 1번으로 총 6번 실행할 것 같지만 실제로는 map 1번(a), anyMatch 1번(A) 총 2번 실행하게 된다.
스트림 연산 순서 고려하기
Stream.of("a", "b", "c", "d", "e")
.map(s -> {
System.out.println("map : " + s);
return s.toUpperCase();
})
.filter(s -> {
System.out.println("filter : " + s);
return s.startsWith("A");
})
.forEach(s -> System.out.println("forEach : " + s));이 결과는 map a filter A forEach A, map b filter B, ... 로 map과 filter가 각각 5번씩 불려지고 forEach는 1번 불려진다. 이 코드를 다음과 같이 수정하면 실행 연산 수를 줄일 수 있다.
Stream.of("a", "b", "c", "d", "e")
.filter(s -> {
System.out.println("filter : " + s);
return s.startsWith("A");
})
.map(s -> {
System.out.println("map : " + s);
return s.toUpperCase();
})
.forEach(s -> System.out.println("forEach : " + s));이 결과는 filter A map A forEach A, filter b, filter c, filter d, filter e로 filter 5번, map 1번, forEach 1번 불리게 되어 위 코드보다 실행 연산 수가 줄었다.
따라서 데이터가 커질 경우 성능 차이를 불러 일으킬 수 있으므로 스트림 api를 사용할 때는 연산 순서를 고려해야 한다.
병렬 스트림 사용 시 주의 사항
스트림은 대량 데이터 처리를 위해 런타임 성능을 높이기 위해 병렬로 실행할 수 있는 기능인 병렬 스트림을 제공하고 있다. 병렬 스트림은 각각 스레드에서 처리할 수 있도록 스트림 요소를 여러 청크로 분할한 스트림이다. 멀티 코어 프로세서가 각각의 청크를 처리하도록 할당되어진다. 내부적으로 병렬 처리를 위해 포크 조인풀을 사용한다.
- stream.parallel()
-순차 처리 스트림에 parallel()을 호출하면 병렬 처리 스트림으로 변환해서 리턴한다. (다시 순차 처리 스트림으로 변환하려면 sequential()을 호출하면 된다.) - Collection.parallelStream()
-컬렉션으로부터 바로 병렬 스트림 리턴한다. - 성능
1) 요소의 수가 많고 요소 당 처리시간이 긴 경우에 사용하자.
-> 병렬 스트림은 쓰레드풀을 생성하고 쓰레드를 생성하기 때문에 요소의 수가 작다면 오히려 순차 처리가 빠르다.
2) 스트림 소스의 종류를 확인하자.
ArrayList나 배열은 인덱스로 요소를 관리해 분리가 쉽지만, HashSet, TreeSet은 요소를 분리하기 쉽지 않고 LinkedList는 랜덤 액세스를 지원하지 않아 링크를 따라가야 하기 때문에 분할을 위해서는 전체 탐색을 해야해서 효율이 좋지 못하다.
3) 코어의 수를 확인하자.
싱글 코어인 경우는 순차 처리가 빠르다. 싱글 코어로 병렬 처리를 할 경우 쓰레드의 수만 증가하고 번갈아 가면서 스케줄링을 해야하므로 효율이 좋지 않다. 코어가 많으면 많을 수록 병렬 작업 처리 속도는 빨라진다.
4) 박싱을 최소화하자.
박싱/언박싱은 성능을 크게 하락시키기 때문에 타입이 기본형이라는 것이 확실하다면 기본형 스트림(IntStream, LongStream, DoubleStream)을 사용하자.
5) 순서에 의존하는 연산을 사용할 때는 순서를 고려하자.
순서에 의존하는 연산은 스트림에서 순서를 잘못 고려하면 큰 비용을 유발한다. 순서가 중요하지 않다면 findFirst() 보다는 findAny()가 좋고, 단순 limit() 보다는 unordered().limit()이 더 효율적이다.
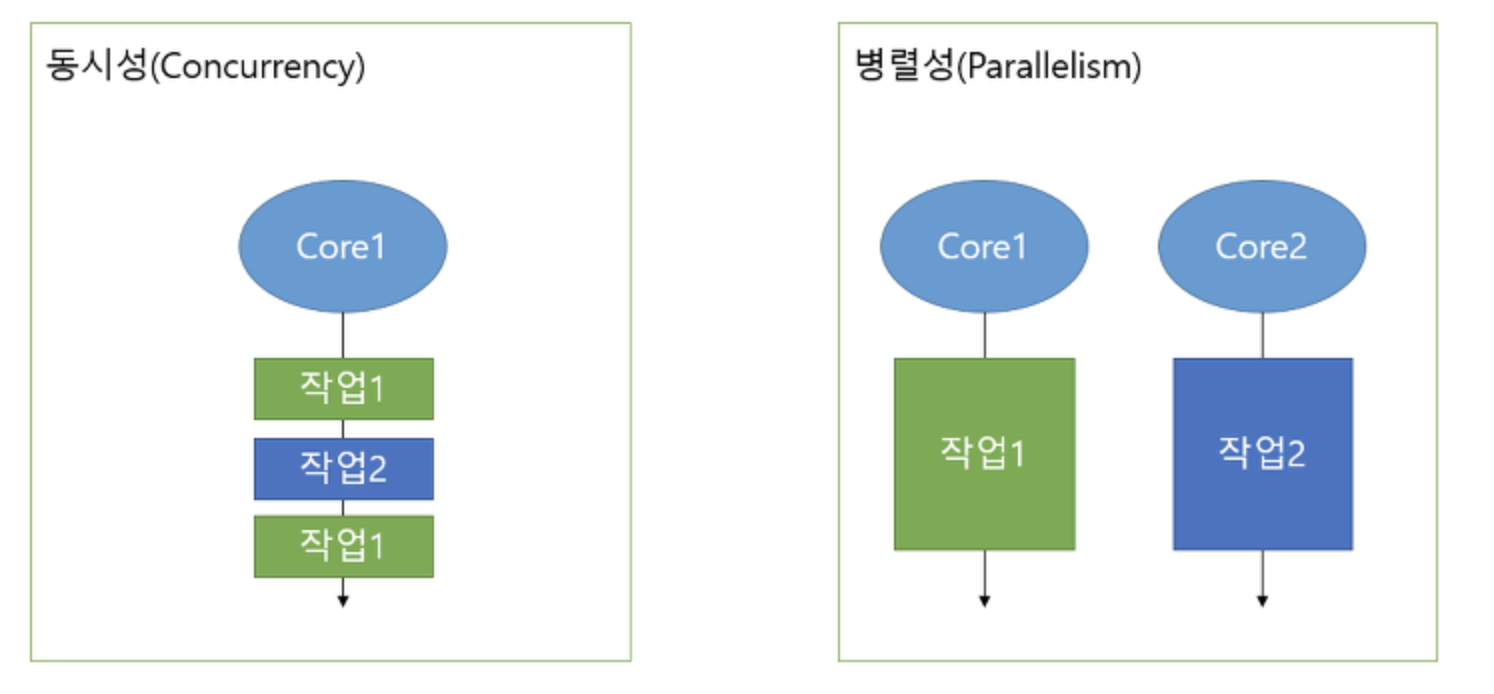
동시성과 병렬성
동시성은 멀티 작업을 위해 멀티 쓰레드가 번갈아가며 실행하는 것이고, 병렬성은 멀티 작업을 위해 멀티 코어를 이용해서 동시에 실행하는 것을 의미한다. 싱글 코어를 통한 멀티 작업은 병렬적으로 실행되는 것으로 보이지만 번갈아가면서 실행되는 동시성 작업이다.
Collection.forEach와 Stream.forEach의 차이점
Collection.forEach는 객체를 생성하지 않고 forEach 메서드를 호출한다. forEach 메서드는 Iterable 인터페이스의 디폴트 메서드인데 Collection 인터페이스에서 Iterable 인터페이스를 상속하고 있기 때문에 바로 호출할 수 있다.
public interface Iterable<T> {
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
}
public interface Collection<E> extends Iterable<E> {
....
}Stream.forEach는 Collection 인터페이스의 디폴트 메서드인 stream()으로 Stream 객체를 생성해야 forEach를 호출할 수 있다.
public interface Collection<E> extends Iterable<E> {
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
}단순 반복의 목적이라면 Stream.forEach는 stream()으로 생성된 Stream 객체가 버려지는 오버헤드가 있기 때문에 filter, map 등의 중간 연산을 할 때 사용하고 그게 아니라면 Collection.forEach를 쓰는 것이 좋다.
*참고 자료
https://mangkyu.tistory.com/111
https://mangkyu.tistory.com/112
https://gsmesie692.tistory.com/267
https://mangkyu.tistory.com/115
https://dundung.tistory.com/247
https://multifrontgarden.tistory.com/254
https://girawhale.tistory.com/131
https://ict-nroo.tistory.com/43
