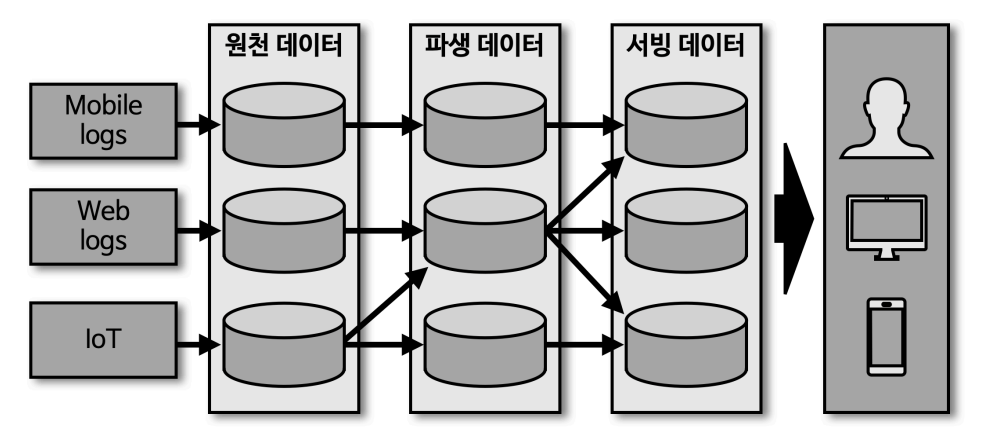
초기 빅데이터 플랫폼

- 초기 빅데이터 플랫폼은 end-to-end
- 유연하지 못하고 빠른 전달 불가
- 히스토리 파악 어려움
- 데이터의 가공으로 데이터가 파편화되면서 데이터 거버넌스를 지키기 어려움
람다 아키텍처
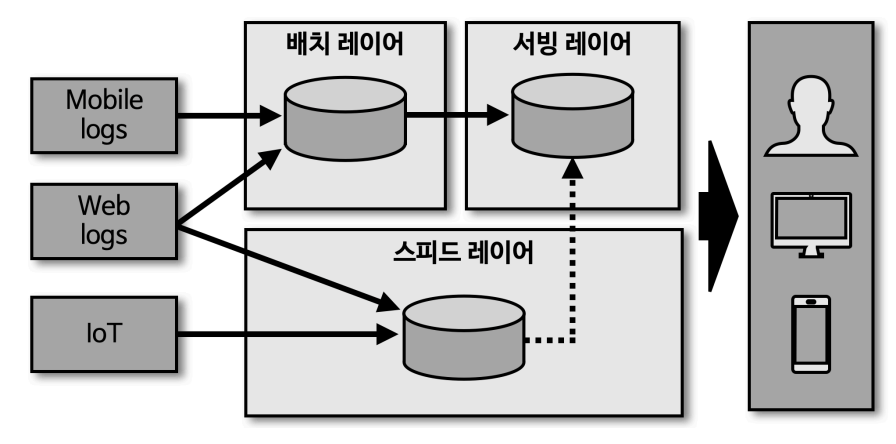
- 배치 레이어 : 원하는 시간, 타이밍에 배치하여 일괄 처리
- 서빙 레이어 : 가공된 데이터 저장 공간
- 스피드 레이어 : 실시간으로 빠르게 분석(kafka 위치)
- 배치와 처리가 분리되어 명확히 구분 가능하지만 배치 데이터와 실시간 데이터를 융합하여 처리할 때는 유연하지 못한 한계를 가짐
카파 아키텍처
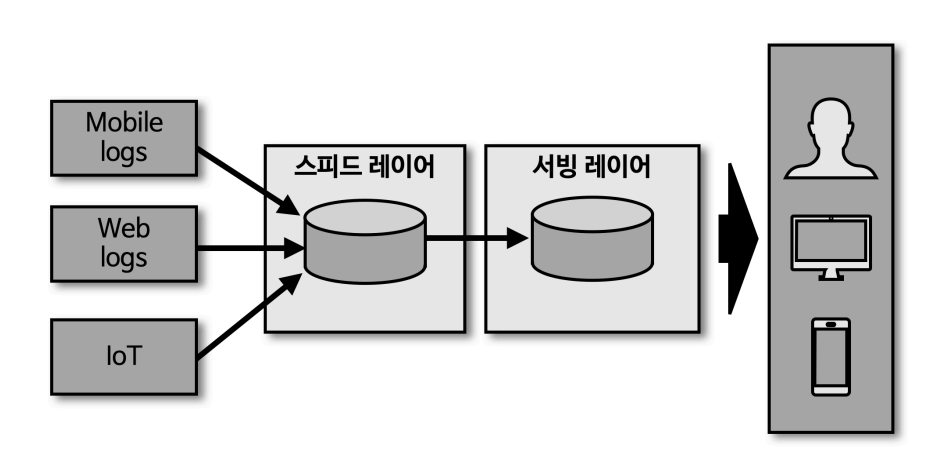
- 람다에서 배치 레이어를 제거함
- 스피드 레이어에서 모든 데이터를 처리
배치 데이터와 스트림 데이터 비교
| 배치 데이터 | 스트림 데이터 |
|---|---|
| 한정된 데이터 처리 | 무한 데이터 처리 |
| 대규모 배치 데이터를 위한 분산 처리 수행 | 지속적으로 들어오는 데이터를 위한 분산 처리 수행 |
| 분,시간,일 단위 처리를 위한 지연 발생 | 분 단위 이하 지연 발생 |
| 복잡한 키 조인 수행/ 활용도가 높음 | 단순한 키 조인 수행 |
스트림 데이터를 카프카에서 배치로 사용하는 방법
- 스트림 데이터를 로그로 사용하는 방법은 로그에 시간을 남기는 것
- 로그에 남겨진 시간을 기준으로 데이터를 처리하면 스트림으로 적재된 데이터도 배치로 처리 가능
- 카프카는 로그에 시간을 남기기 때문에 이런 방식으로 처리가 가능
미래 - 스트리밍 데이터 레이크
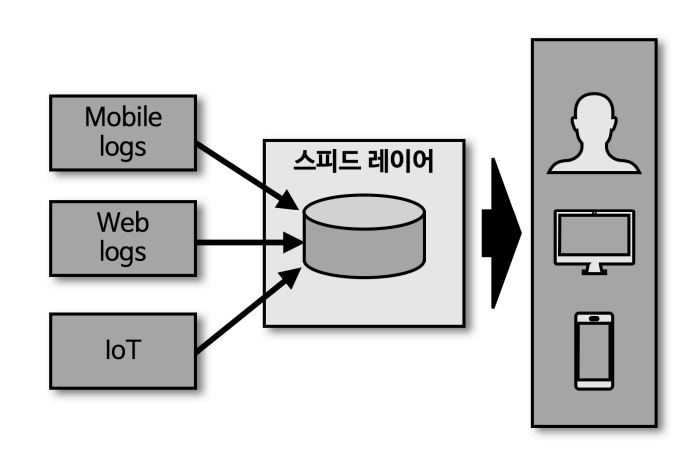
- 스피드 레이어로 사용되는 카프카에 분석과 프로세싱을 완료한 거대한 용량의 데이터를 오랜 기간 저장하고 사용할 수 있다면 서빙 레이어는 제거되어도 됨.
- 서빙 레이어와 스피드 레이어가 이중으로 관리되는 운영 리소스를 줄일 수 있음.
- 이를 위해 자주 사용하는 데이터와 자주 사용하지 않는 데이터를 분리를 개발 중
- 자주 접근하지 않는 데이터를 대용량의 오브젝트 스토리지로 저장하면서 자원을 효율적으로 운영 및 관리

하늘하늘한 하늘