카프카의 특징
카프카 내부 구조
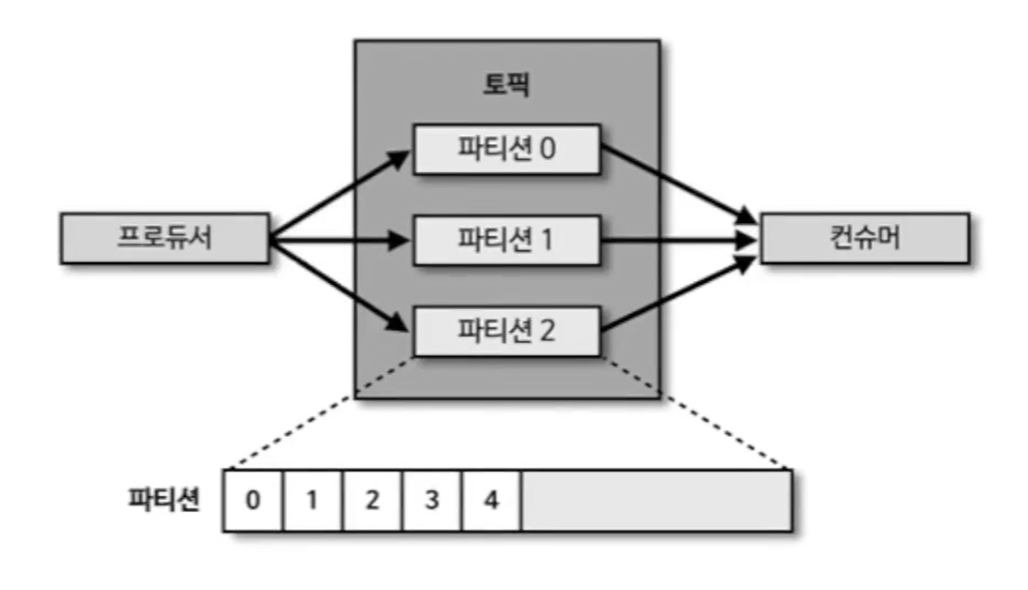
- 소스에서 생성되는 데이터를 어느 타깃으로 보낼 것인지 고민하지 않고 카프카에 넣으면 됨
- 프로듀서에서 메시지를 보내면, 여러 파티션에서 하나의 파티션에 데이터가 적재
- 적재된 데이터를 하나씩 가져가더라도 파티션의 데이터는 삭제되지 않음
- 특정 컨슈머가 파티션에서 가져가는 데이터를 기록하는 것을 '커밋'
- 파티션은 FIFO(First in First Out) 방식의 큐 자료구조와 유사
높은 처리량
- 카프카는 데이터를 묶어서 전송하여 네트워크 비용 최소화 >프로듀서가 브로커로 데이터를 보낼 때와 컨슈머가 브로커로부터 데이터를 받을 때 모두 묶어서 전송하여 묶음 단위로 처리
- 네트워크 통신 횟수를 최소화하여 동일 시간 내에 더 많은 데이터를 전송 > 많은 양의 데이터를 송수신할 때 맺어지는 네트워크 비용은 상당한 규모가 될 수 있음.
- 배치 처리에 적합하여 대용량의 실시간 로그 데이터를 효율적으로 처리 > 이를 통해 대용량의 실시간 로그 데이터를 효율적으로 처리
- 데이터를 파티션 단위로 분배하여 병렬로 처리할 수 있습니다. > 파티션 개수만큼 컨슈머 개수를 늘려서 동일 시간당 데이터 처리량을 늘림
확장성
- 카프카는 가변적인 데이터 양과 환경에서 안정적으로 처리 가능하도록 설계
- 데이터 양에 따라 브로커 개수를 조절하여 스케일 아웃 및 스케일 인이 가능하여 데이터 처리량을 효율적으로 관리할 수 있음
- 클러스터의 무중단 운영을 지원하여 365일 24시간 데이터 처리가 보장되어 비즈니스 모델에서도 안정적인 운영이 가능하며, 커머스나 은행과 같은 업계에서 신뢰성 있는 데이터 파이프라인 구축가능
- 카프카는 대규모 데이터 처리를 위해 디스크 기반의 파일 시스템을 활용하여 안정적인 데이터 보존과 처리를 지원
영속성
- 카프카는 전송받은 데이터를 메모리 대신 파일 시스템에 저장하여 영속성을 보장
- 운영체제의 페이지 캐시를 활용하여 파일 성능을 향상시키며, 카프카는 이를 최대한 활용
- 디스크 기반의 파일 시스템을 활용하여 데이터를 안전하게 보존하고 장애 시에도 데이터 복구 가능
- 브로커 애플리케이션의 재시작을 통해 이전에 저장된 데이터를 다시 처리 가능
- 카프카의 영속성 기능은 안정적이고 신뢰할 수 있는 데이터 처리를 지원
고가용성
- 카프카 클러스터 구성: 카프카 클러스터는 3개 이상의 서버로 구성
- 무중단 데이터 처리: 클러스터는 장애가 발생해도 데이터 처리를 무중단으로 지속
- 데이터 복제: 전송받은 데이터는 여러 브로커에 복제되어 저장
- 장애 대응: 한 브로커에 장애가 발생해도 다른 브로커에 저장된 복제 데이터를 활용하여 데이터 처리 가능
- 리전 단위 장애 대응: 카프카는 온프레미스나 퍼블릭 클라우드의 리전 단위 장애에도 대응할 수 있는 브로커 옵션을 제공
- 고가용성 보장: 데이터의 복제와 장애 대응 기능을 통해 카프카는 고가용성을 보장하며, 지속적인 데이터 처리를 수행할 수 있음

하늘하늘한 하늘