Elasticsearch는 시간이 갈수록 증가하는 문제를 처리하는 분산형 RESTful 검색 및 분석 엔진입니다. Elastic Stack의 중심으로, Elasticsearch는 손쉽게 확장되는 번개처럼 빠른 검색, 정교하게 조정된 정확도, 강력한 분석을 위해 데이터를 중앙에 저장합니다
키바나(Kibana)는 ELK(Elasticsearch, Logstash, Kibana)라는 엘라스틱서치 스택의 주요 솔루션 중 하나로 엘라스틱서치와 연계를 이루면서 비주얼라이징(Visualizing)을 통한 유저 인터페이스(User Interface, UI)를 제공하는 솔루션입니다.
키바나를 설치하면 엘라스틱서치의 데이터를 쉽게 확인할 수 있고, 비주얼라이징을 통한 데이터 분석도 할 수 있으며, 관리기 역할까지 수행할 수 있습니다.
https://www.elastic.co/downloads/kibana 사이트로 이동하여, OS에 맡는 파일을 다운로드하면 키바나를 설치할 수 있습니다.
사용법
출처: https://blog.nerdfactory.ai/2019/04/29/django-elasticsearch-restframework.html
pip install elasticsearch==6.3.1
Python ES API를 사용하실 때 공식 메뉴얼(https://elasticsearch-py.readthedocs.io/en/master/api.html)을 참고하시면 도움이 많이 됩니다.
Elastic에서 개발한 한국어 형태소 분석기 nori를 이용하기 위해 elasticsearch-plugin 설치를 해줍니다.
C:\Users\user\elasticsearch-6.6.2\bin>elasticsearch-plugin install analysis-nori
인덱스 설정 및 생성
Elasticsearch는 “Hello to the world”라는 문자열을 [“Hello”, “to”, “the”, “world”]로 토크나이징해서 인덱스하기도 하고 중요한 단어인 [“Hello”, “world”]만을 토크나이징해서 인덱스하는 등 유연하게 다양한 방식으로 인덱스를 생성해서 전문 검색에 특히 뛰어납니다. 이를 활용해서 한국어 백과사전 검색에 적합한 인덱스를 생성하기 위해 한글 형태소 분석기 nori를 통해 데이터를 토크나이징할 수 있도록 설정합니다. search_app 디렉터리에 setting_bulk.py 파일을 생성해서 따로 구현해주었습니다.
# search_app/setting_bulk.py
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.indices.create(
index='dictionary',
body={
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer"
}
}
}
}
}
}
)그다음으로는 mapping 설정을 해주어야 합니다. mapping은 관계형 데이터베이스의 schema와 비슷한 개념으로, Elasticsearch의 인덱스에 들어가는 데이터의 타입을 정의하는 것입니다. mapping 설정을 직접 해주지 않아도 Elastic에서 자동으로 mapping이 만들어지지만 사용자의 의도대로 mapping 해줄 것이라는 보장을 받을 수 없습니다. mapping이 잘못된다면 후에 Kibana와 연동할 때도 비효율적이기 때문에 Elastic에서는 mapping을 직접 하는 것을 권장합니다. 각 필드의 타입을 정의하고 위에서 설정해준 분석기 ‘my_analyzer’로 title과 content를 분석할 수 있도록 설정해줍니다.
# search_app/setting_bulk.py
es.indices.create(
index='dictionary',
body={
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer"
}
}
}
}
},
"mappings": {
"dictionary_datas": {
"properties": {
"id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "my_analyzer"
},
"content": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
}
)데이터 삽입
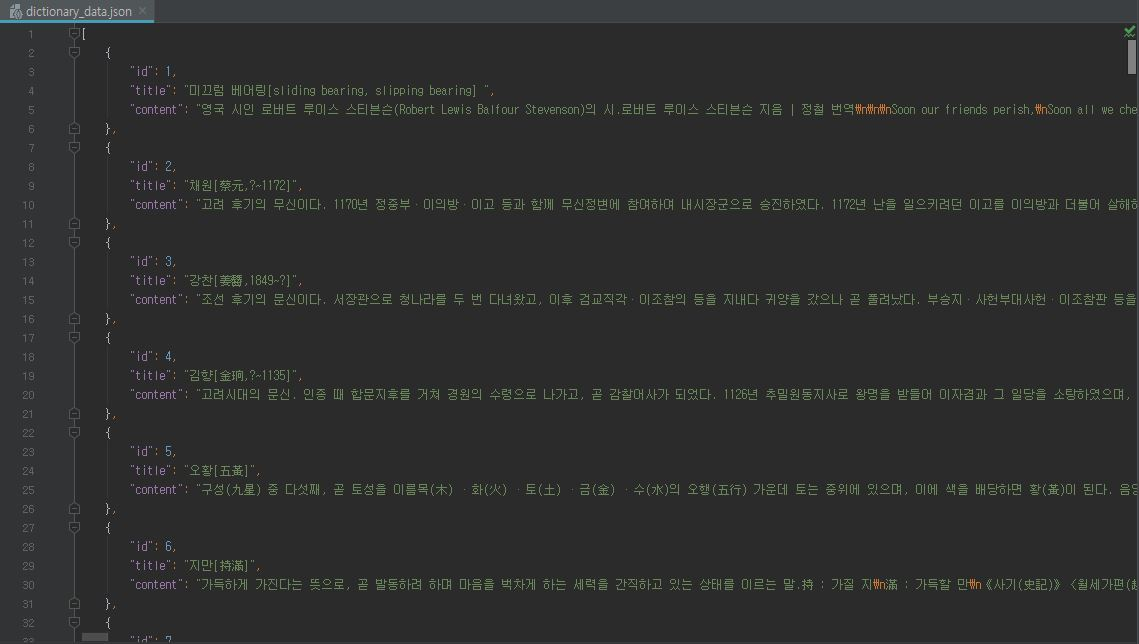
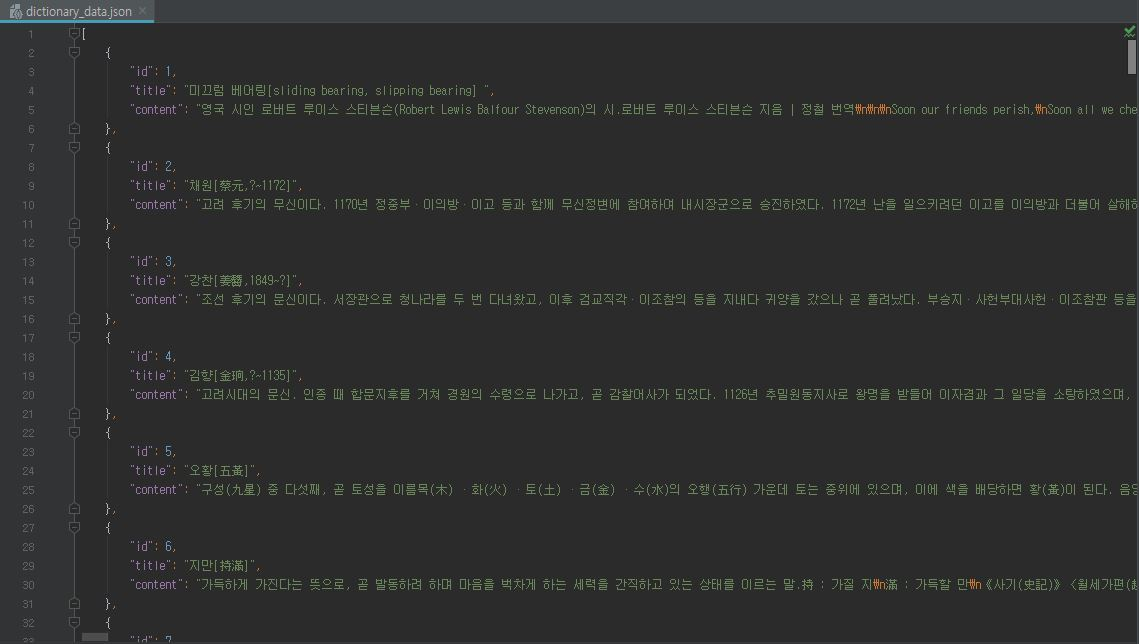
백과사전의 일부를 데이터셋으로 활용하였습니다.
# search_app/setting_bulk.py
import json
with open("dictionary_data.json", encoding='utf-8') as json_file:
json_data = json.loads(json_file.read())
body = ""
for i in json_data:
body = body + json.dumps({"index": {"_index": "dictionary", "_type": "dictionary_datas"}}) + '\n'
body = body + json.dumps(i, ensure_ascii=False) + '\n'
es.bulk(body)view 구현
클래스 기반 뷰로 API를 작성할 계획이며 GET Method를 통해 요청을 하면 parameter로 전달된 검색어에 해당하는 검색 결과를 응답하도록 해줍니다.
# search_app/views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import status
from elasticsearch import Elasticsearch
class SearchView(APIView):
def get(self, request):
es = Elasticsearch()
# 검색어
search_word = request.query_params.get('search')
if not search_word:
return Response(status=status.HTTP_400_BAD_REQUEST, data={'message': 'search word param is missing'})
docs = es.search(index='dictionary',
doc_type='dictionary_datas',
body={
"query": {
"multi_match": {
"query": search_word,
"fields": ["title", "content"]
}
}
})
data_list = docs['hits']
return Response(data_list)