📌 1. 뷰(View)
View는 DBMS에서 사용할 수 있는 일종의 가상 테이블이다. DB에 존재하는 데이터들을 원하는 대로 조합하여 하나의 뷰로 만들 수 있다.
📍 1-1. 뷰의 사용 목적
- 작업시 자주 조회하는 데이터들이 있다. 여러 테이블을
join해서 가져오는 등 복잡한 쿼리를 작성해야 하는 경우 뷰를 만들어 놓으면 원하는 데이터를 쉽게 조회할 수 있다. - 원하는 컬럼만 공개하여 원천데이터 테이블을 공개하지 않고 선택적으로 데이터를 제공할 수 있으므로 보안에도 유리하다.
📍 1-2. 뷰의 특징
- 원천데이터가 변경되면
View의 데이터도 자동으로 변경된다. - 뷰의 검색은 자유로우나 삽입, 수정, 삭제에는 제약이 있다.
- 뷰생성 쿼리에 함수를 사용하면 반드시
alias를 지정해야 한다.
📍 1-3. 뷰 생성법
-
CREATE VIEW 뷰이름(포함할 컬럼 나열) AS+SELECT문으로 생성한다. -
SELECT문으로 뷰에 포함시킬 데이터를 가져오면 된다.EMPLOYEES테이블에서JOB_ID가ST_CLERK인 데이터의 5개 열을 가져온다.CREATE VIEW V_EMP(EMP_ID, FIRST_NAME, JOB_ID, HIREDATE, DEPT_ID) AS SELECT EMPLOYEE_ID , FIRST_NAME , JOB_ID , HIRE_DATE , DEPARTMENT_ID FROM EMPLOYEES e WHERE JOB_ID = 'ST_CLERK' ;
-
뷰 생성 마지막에
WITH READ ONLY옵션을 붙이면 뷰에서 직접 원본 데이터를 수정하는 것을 막을 수 있다.CREATE VIEW .... AS SELECT ... WITH READ ONLY ;
📌 2. 시퀀스(Sequence)
📍 2-1. 시퀀스의 사용 목적
- 시퀀스란 연속적인 번호를 만들어주는 기능으로, 자동으로 순차적으로 증가하는 순번을 반환하는 데이터베이스 객체이다.
- 보통
PK값에 중복값을 방지하기 위해 사용한다.
📍 2-2. 시퀀스 생성법
- 시퀀스를 생성하는 기본 문법은 다음과 같다.
CREATE SEQUENCE seq_serial_no INCREMENT BY 1 -- 증가값 START WITH 100 -- 시작값 MAXVALUE 110 -- 최대값 / NOMAXVALUE 무제한 MINVALUE 99 -- 최소값 / CYCLE이 없으면 생략 가능 CYCLE -- 순환 여부(MAXVALUE 도달시 다시 MINVALUE로 돌아간다) -- NOCYCLE이 기본값(작성하지 않으면 NOCYCLE) CACHE 2 -- CACHE: 메모리 보관값 ;
INCREMENT BY,START WITH으로 매번 증가시킬 값과 시작할 값을 지정한다.MAXVALUE는 어디까지 증가시킬 것인지를 정하는 최대값 옵션으로,NOMAXVALUE로 지정하면 제한 없이 증가시킬 수 있다.MINVALUE는 최소값 옵션으로CYCLE옵션을 사용하지 않으면 생략 가능하다.CYCLE은MAXVALUE에 도달 시 다시MINVALUE로 돌아가 증가를 반복하겠다는 옵션이다.NOCYCLE로 작성하거나 아예 옵션을 작성하지 않으면 사이클을 사용하지 않는다.CACHE는 보관할 메모리 값을 지정한다.
📍 2-3. 시퀀스 사용법
-
시퀀스명.
NEXTVAL명령어로 현재 인덱스 값의 다음 값을 사용할 수 있다.INSERT INTO GOOD VALUES(SEQ_SERIAL_NO.NEXTVAL,'제품1');
-
시퀀스명.
CURRVAL명령어로 현재 인덱스 값을 사용할 수 있다.INSERT INTO GOOD VALUES(SEQ_SERIAL_NO.CURRVAL,'제품2');
-
DUAL테이블을 사용해 현재 인덱스 값을 확인할 수 있다.SELECT SEQ_SERIAL_NO.CURRVAL FROM DUAL;
-
삭제법은 다른 데이터의 삭제와 동일하다.
DROP SEQUENCE SEQ_SERIAL_NO;
📌 3. 인덱스(Index)
📍 3-1. 인덱스의 사용 목적과 원리
- 인덱스는 색인이란 뜻으로 테이블의 조회속도를 향상시키기 위한 데이터베이스 검색 기술이다.
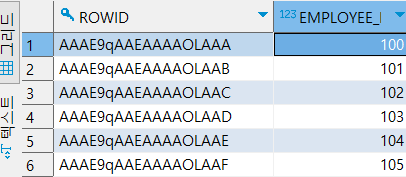
index를 테이블의 특정 컬럼에 한 개 이상 주게 되면index table이 따로 만들어지고, 인덱스 컬럼의 로우값과rowid값이 저장된다. 로우값은 정렬된 트리 구조로 저장시켜 두었다가 검색 시 좀 더 빠르게 해당 데이터를 찾는 데 도움을 준다.SELECT로rowid를 확인할 수 있다.
SELECT rowid, EMPLOYEE_ID FROM EMPLOYEES2 e;
📍 3-2. 인덱스 취약점, 불필요한 경우
DML명령을 사용할 때는update, insert, delete명령의 실행 속도가 느려진다는 단점이 있다.insert: 원본 테이블뿐만 아니라 인덱스 테이블까지 두 개의 테이블에 동시 insert를 수행해야 하게 된다.delete: 원본 테이블에서 데이터를 delete하더라도 인덱스에서는 해당 데이터를 사용하지 않음으로 표시하고 지우지 않는다.update: 원본 테이블에서 데이터가 update할 때 인덱스 테이블에서는 해당 데이터를 delete한 후 새로운 데이터를 insert하는 작업이 이루어진다.
- 따라서
- 데이터가 적은 경우에는 인덱스를 설정하지 않는 것이 오히려 성능에 좋다.
- 조회보다 삽입, 수정, 삭제 처리가 많은 테이블에서는 인덱스를 설정할 필요성이 적다.
📍 3-3. 인덱스 생성법
-
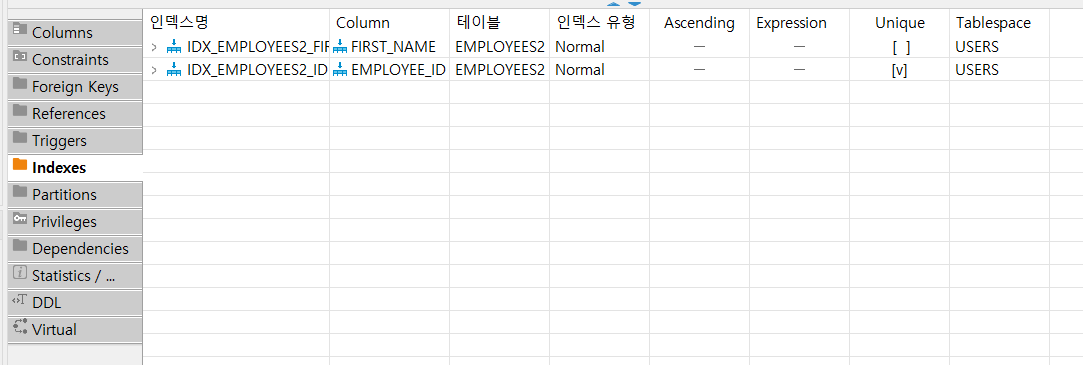
unique index- 인덱스를 사용한 컬럼에 중복값을 허용하지 않는다.
create unique index 인덱스명 on 테이블명(컬럼명);
-
non - unique index- 인덱스를 사용한 컬럼에 중복 데이터 값을 가질 수 있다.
create index 인덱스명 on 테이블명(컬럼명);
-
생성한 인덱스는 해당 테이블의 Indexes 탭이나 Indexes 폴더에서 확인할 수 있다.