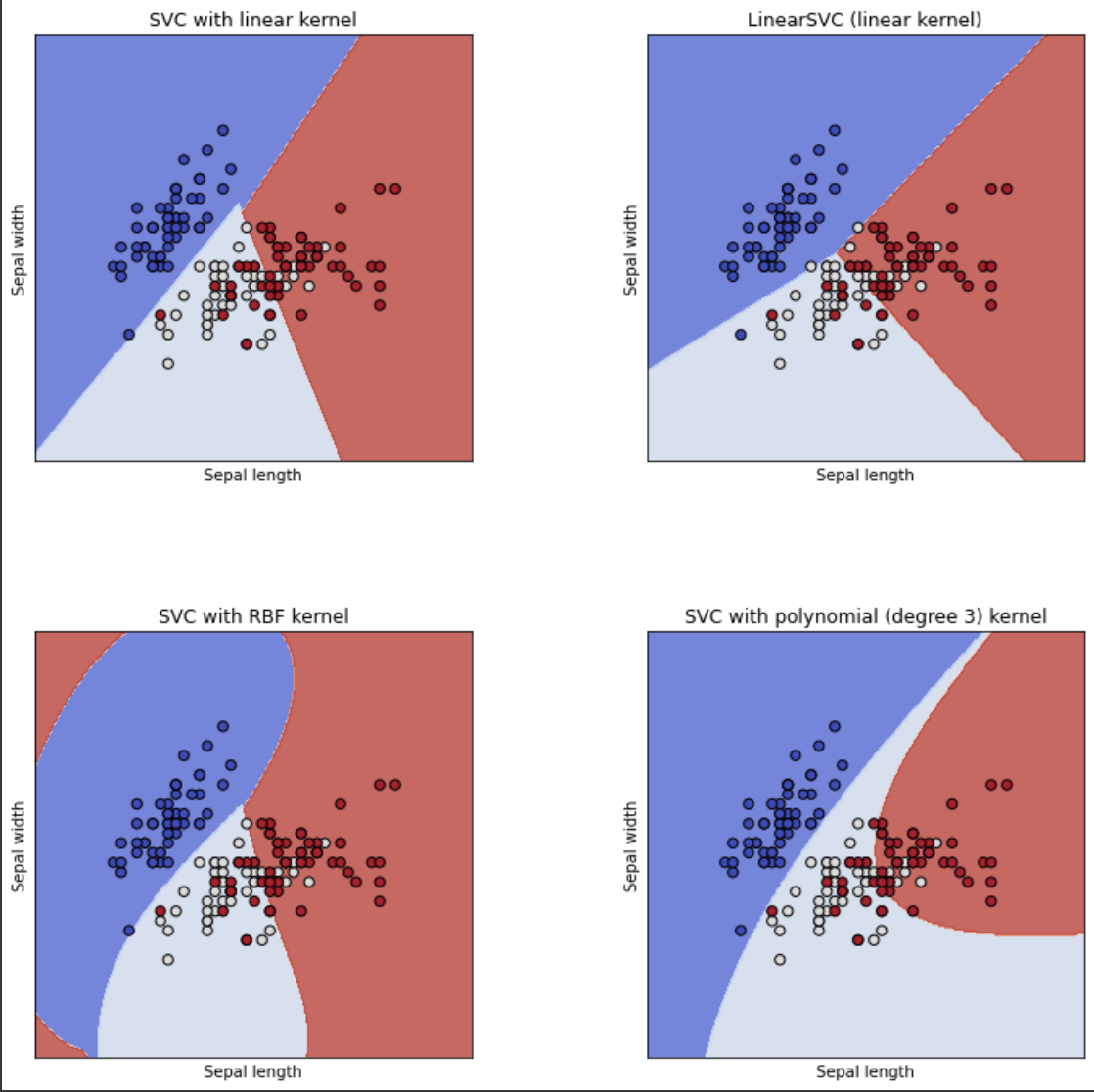
SVM 이란?
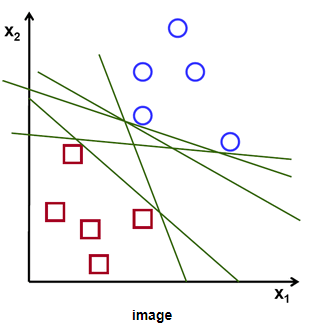
- 두 개의 그룹(데이터)를 분리하는 방법
즉, 데이터들과 거리가 가장 먼 hyperplane(초평면)을 선택해 분리하는 방법
데이터를 분리하기 위해 직선이 필요하지만, 직선이 한쪽으로 치우쳐져 있을 경우 데이터에 변동이나 노이즈가 있을 때 구분을 못하는 경우가 발생하게 된다.
이를 해결하기 위해 Margin을 이용하게 된다.
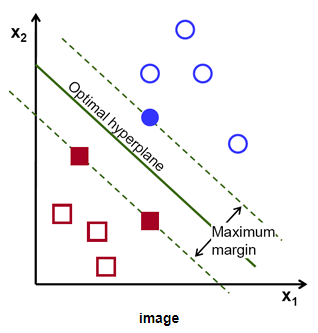
-
위 그림의 직선은 초평면(hyperplane)
-
Margin은 초평면(hyperplane)과 가장 가까이 있는 데이터와의 거리를 의미
-
Support Vector는 데이터를 의미
즉 Margin을 최대로 만드는 직선을 계산해 데이터를 분류 하는 방법
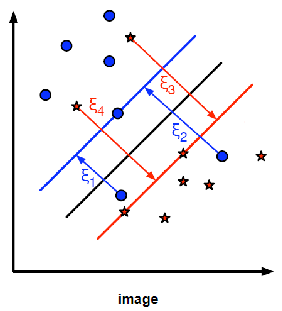
하지만, 일반적인 데이터의 경우 결정경계(boundary)를 넘어서 다른 집단의 데이터가 분포하는 경우가 매우 많이 존재한다.
이 경우 SVM은 적당한 Error를 허용해 최소화하는 Margin을 결정한다.
이때 오분류 에러를 허용하는 파라미터는 C 이다.
-
C값을 크게 설정할 경우 오분류에러는 작아지지만, 반대로 Margin이 작아지게 된다.
-
C값을 작게 설정할 경우 Margin은 커지지만, 반대로 오분류 에러가 커지게 된다.
범주형 변수 : SVC(Support Vector Classification)
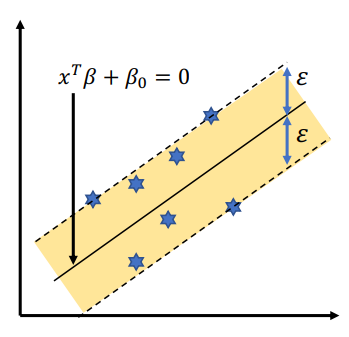
-
SVC와 SVR의 가장 큰 차이는 model의 cost에 존재
-
Margin안에 포함된 점들의 Error를 기준으로 model의 cost를 계산
-
반대 방향으로 분류된 즉, 노란색 boundary를 넘어서 존재하는 점들과 중심 직선 (초평면)과의 Error를 계산
연속형 변수 : SVR(Support Vector Regression)
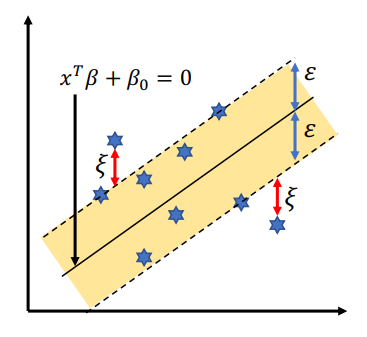
-
일정 Margin의 범위를 넘어선 점들에 대한 Error를 기준으로 model의 cost를 계산
-
Margin 바깥쪽에 위치한 점들과 차이를 계산하는 빨간선이 한 점에 있어서의 Error로 계산
수학적 개념
- Error가 존재하지 않는 경우
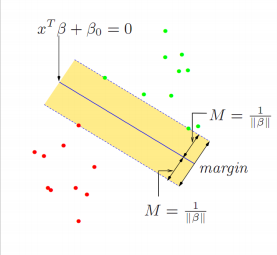
-
의 초평면을 정의
-
를 유일하게 만들기 위해 의 조건이 필요
-
만약 가 다르면 다른 경우마다 다른 해가 발생
-
-
Dicision Rule 정의
-
-
가 항상 양수가 되도록 만들기 위한 Rule을 정의
-
즉, 초평면이 양수이면 y=1 일때, 수식이 양수 반대로 초평면이 음수이면 y=-1일때, 수식이 음수
-
-
Margon을 최대로 만다는 계수를 정의
-
-
즉, 초평면이 M보다 클때, 인 상황에서 M을 최대화 하는 것
-
-
|B|를 최소화 하는 문제로 치환 가능
- |B|를 최소화 하는 것이 곧 M을 최대화 하는 것
- Error가 존재하는 경우
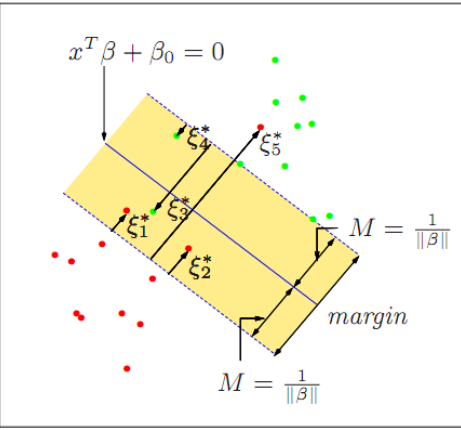
-
의 초평면을 정의
-
Error 발생 시 Margin을 최대화
-
-
ξ가 1을 넘길 경우는 boundary를 넘어 다른 집단에 속하는 경우
-
constant(일정 상수)는 Error 허용 범위를 지정
-
즉, constant가 커지면 Error가 커지는 것
-
-
|B|를 최소화 하는 문제로 치환 가능
- |B|를 최소화 하는 것이 곧 M을 최대화 하는 것
장단점
- 장점
- 분류문제와 예측문제 동시에 사용 가능
- 신경망 기법에 비해 과적합 정도가 덜함
- 예측 정확도가 높음
- 사용성이 용이함
- 단점
- Kernel과 모델 parameter를 조절하기 위해 여러번 반복 시도가 필요
- 학습 속도가 느림
- 결과에 대한 설명력이 떨어짐