콘텐츠 기반 모델
- 콘텐츠 기반 추천시스템은 사용자가 이전에 구매한 상품중에서 좋아하는 상품들과 유사한 상품들을 추천하는 방법
- Item을 Vector 형태로 표현
- Vector들간 유사도 계산
유사도 함수
1. 유클리디안 유사도

장점
- 계산하기 쉬움
단점
- p와q의 분포가 다르거나 범위가 다른 경우에 상관성을 놓침
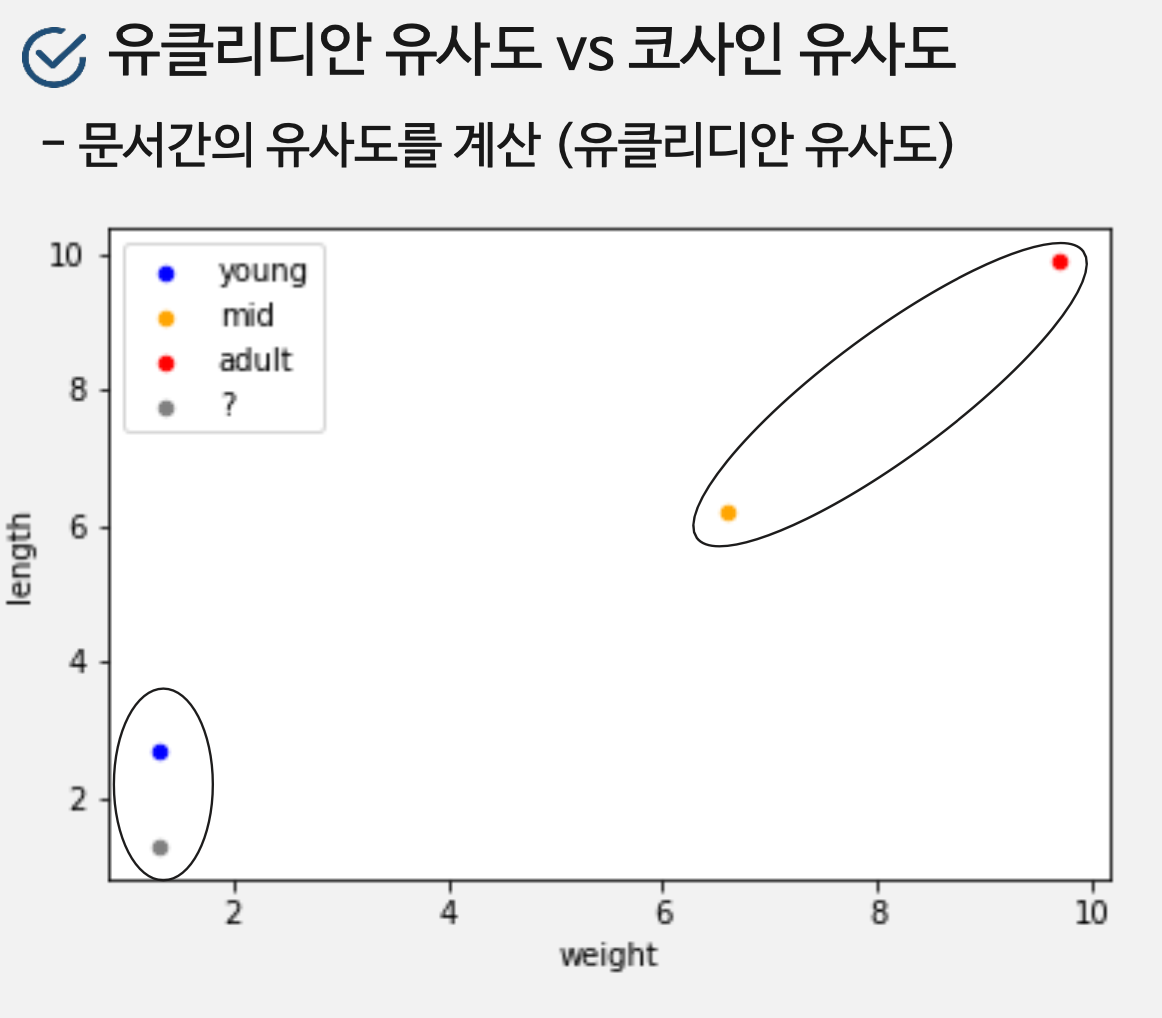
- 가장 가까운 벡터를 찾음
2. 코사인 유사도
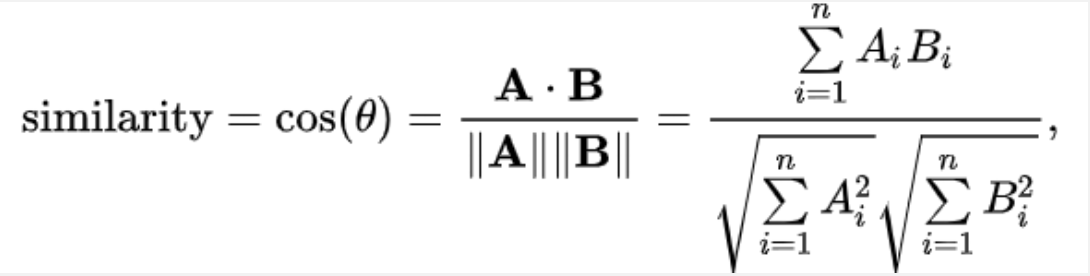
- 가 0으로 동일한 방향을 가지면 유사도는 1
- 가 90도 방향을 가지면 유사도는 0
- 가 -180 or 180의 정반대 방향을 가지면 유사도는 -1로 가장 작은 값을 가짐
장점
- Vector의 크기가 중요하지 않은 경우에 거리를 측정하기 위한 메트릭으로 사용
단점
- Vector의 크기가 중요한 경우에 대해서 잘 작동하지 않음
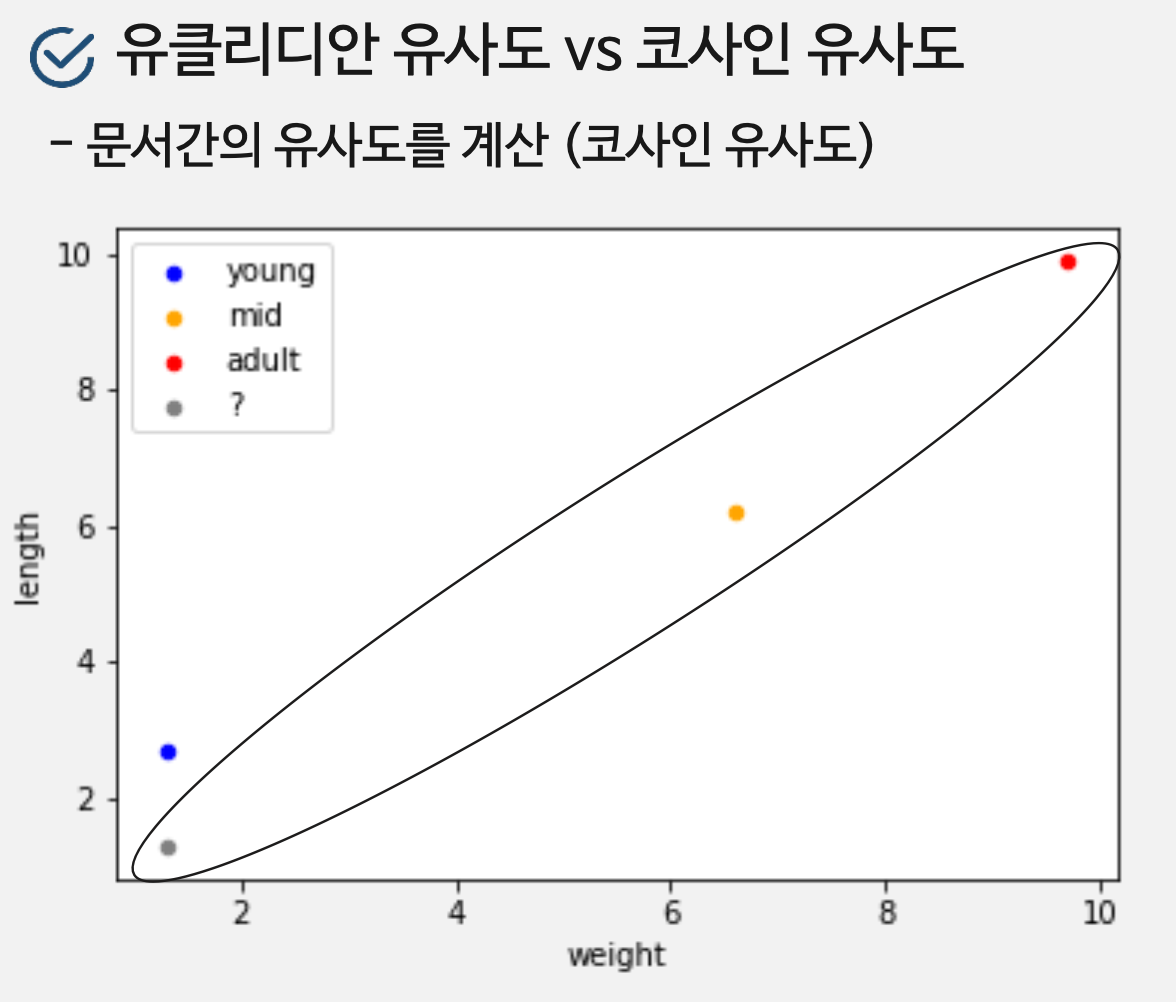
- Vector간의 방향을 살펴보기 때문에 3가지(회/노/빨)가 묶임
3. 피어슨 유사도
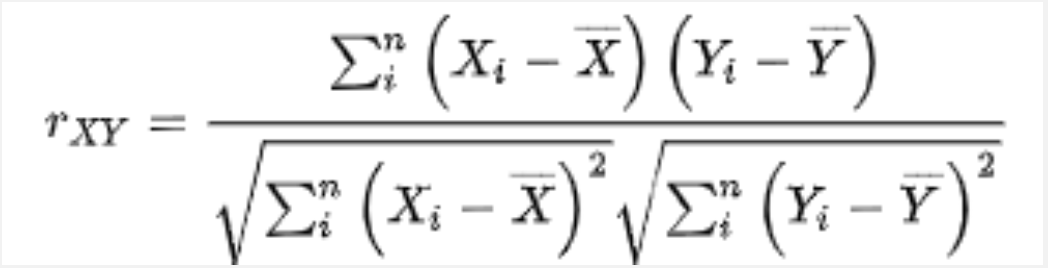
- 상관관계 분석시 사용하는 알고리즘
4. 자카드 유사도
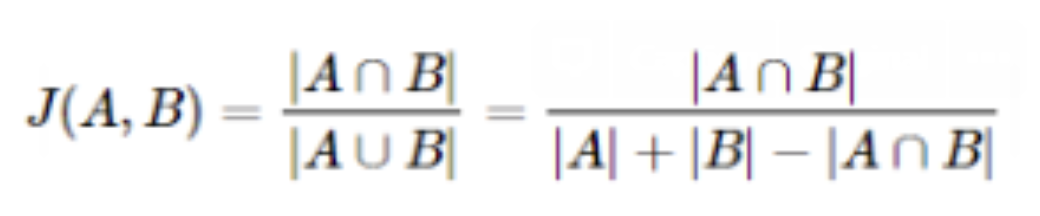
- 집합에서 얼마나 결합되는 부분이 있는지로 계산
TF-IDF
단어 정의
- 단어 빈도 = TF(d,t)
- 특정 문서 내에 특정 단어가 얼마나 자주 등장하는지
- 특정 문서 d에서 특정 단어 t의 등장 횟수
- 역문서 빈도 = DF(t)
- 전체 문서에서 특정 단어가 얼마나 자주 등장하는지
- 특정 단어 t가 등장한 문서의 수
- IDF(d,t)
- DF(t)에 반비례하는 수
정의
-
TF와 DF를 통해 다른 문서에서는 등장하지 않지만, 특정 문서에서만 자주 등장하는단어를 찾아서 문서 내 단어의 가중치를 계산하는 방법
-
문서의 핵심어 추출 / 문서들 사이의 유사도 계산 / 검색 결과의 중요도 선정 등
사용하는 이유

- item이라는 콘텐츠를 Vector로 "Feature Extract"과정을 수행해 준다.
- 빈도수를 기반으로 많이 나오는 중요한 단어들을 잡아준다. 이러한 과정을 Counter Vectorizer라고 한다.
- 하지만 Counter Vectorizer는 단순 빈도만을 계산하기 때문에 조사, 관사와 같은 의미 없는 단어에 빈도수를 높게 계산하는 한계가 존재한다.
- 이러한 단어들에 패널티를 줘서 적절하게 중요한 단어만을 잡아내는 것이 TF-IDF이다.
장점
- 직관적인 해석이 가능함
단점
- 대규모 말뭉치를 다룰 때, 메모리상의 문제가 발생함
- 높은 차원
- 매우 sparse한 형태의 데이터

딥러닝 지식의 백지에서 깜지까지