Word2Vec
통계기반의 방법 단점
- 대규모 말뭉치를 다룰 때, 메모리상의 문제가 발생
- 한번에 학습 데이터 전체 진행에 어려움
- GPU와 같은 병렬처리를 기대하기 힘듬
- 학습을 통해서 개선 어려움
추론기반의 방법
- 주변 단어(맥락)이 주어졌을 때, 어떤 단어(중심 단어)가 들어가는지를 추측하는 작업
- 잘못 예측시에도 학습을 통해서 개선이 가능함
Word2Vec 정의
-
단어간 유사도를 반영해 단어를 벡터로 바꿔주는 임베딩 방법론
-
One-Hot 벡터 형태의 Sparse Maxtrix이 가지는 단점을 해소하고자 저차원의 공간에 벡터로 매핑하는 것이 특징
-
"비슷한 위치에 등장하는 단어들은 비슷한 의미를 가진다"라는 가정을 통해서 학습
-
저차원에 학습된 단어의 의미를 분산하여 표한하기에 단어 간 유사도를 계산 가능
1. CBOW
- 주변에 있는 단어들을 가지고 중간에 있는 단어들을 예측하는 방법

방법
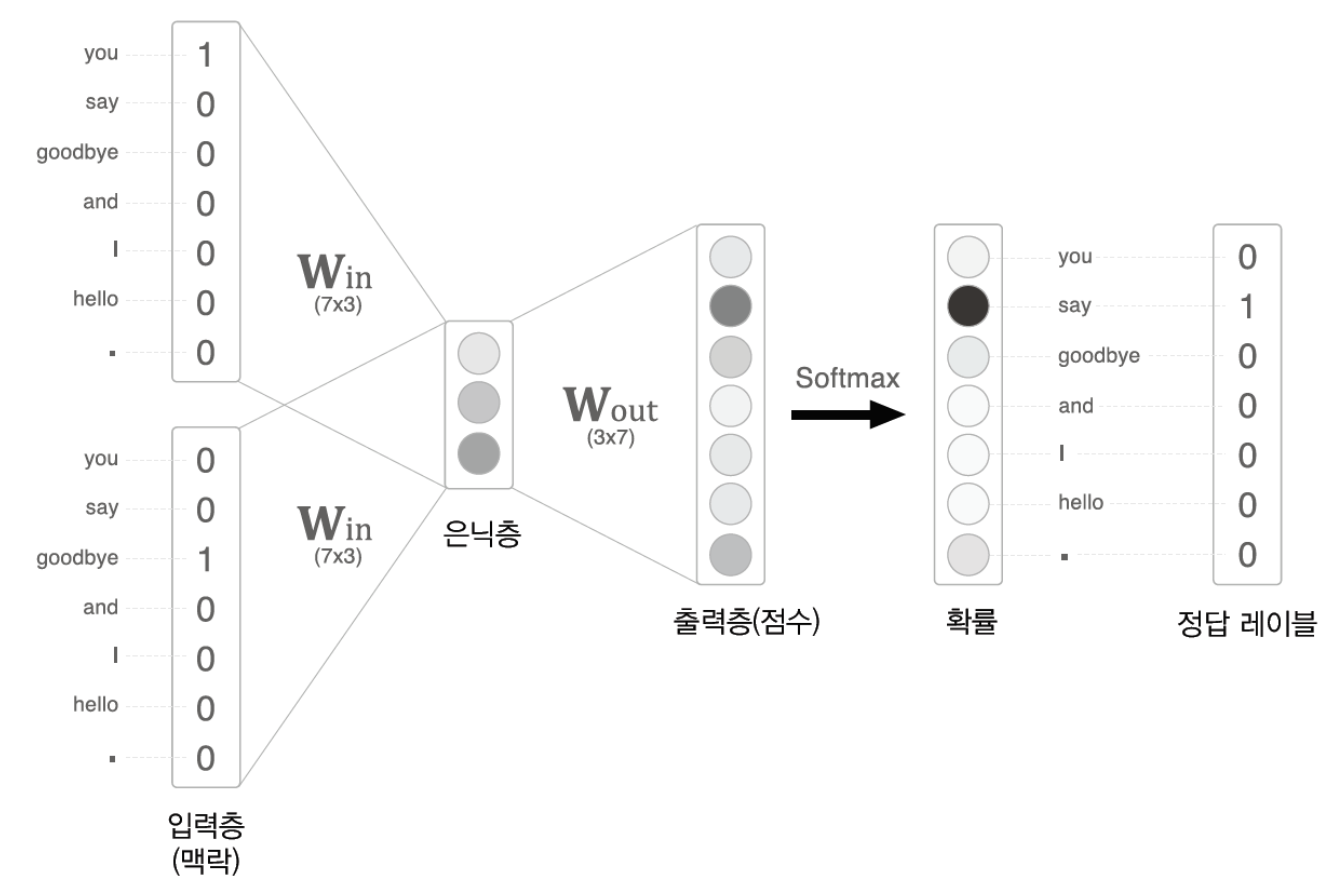
-
One-Hot Vector의 형태의 입력값을 받는다.
- you -> say 예측
- goodbye -> say 예측
-
One-Hot Vector 형태의 입력값을 과 곱해 hidden Layer를 계산한다.
-
Hidden State의 값을 과 곱해서 Score를 추출한다.
-
Score에 Softmax를 취해서 각 단어가 나올 확률 을 계산한다.
-
정답과 Cross Entropy Loss를 계산한다.
-
계산한 Loss를 가지고 Backpropagation 과정을 통해 Weight를 업데이트
2. Skip-gram
- 중간에 있는 단어로 주변 단어들을 예측하는 방법

방법
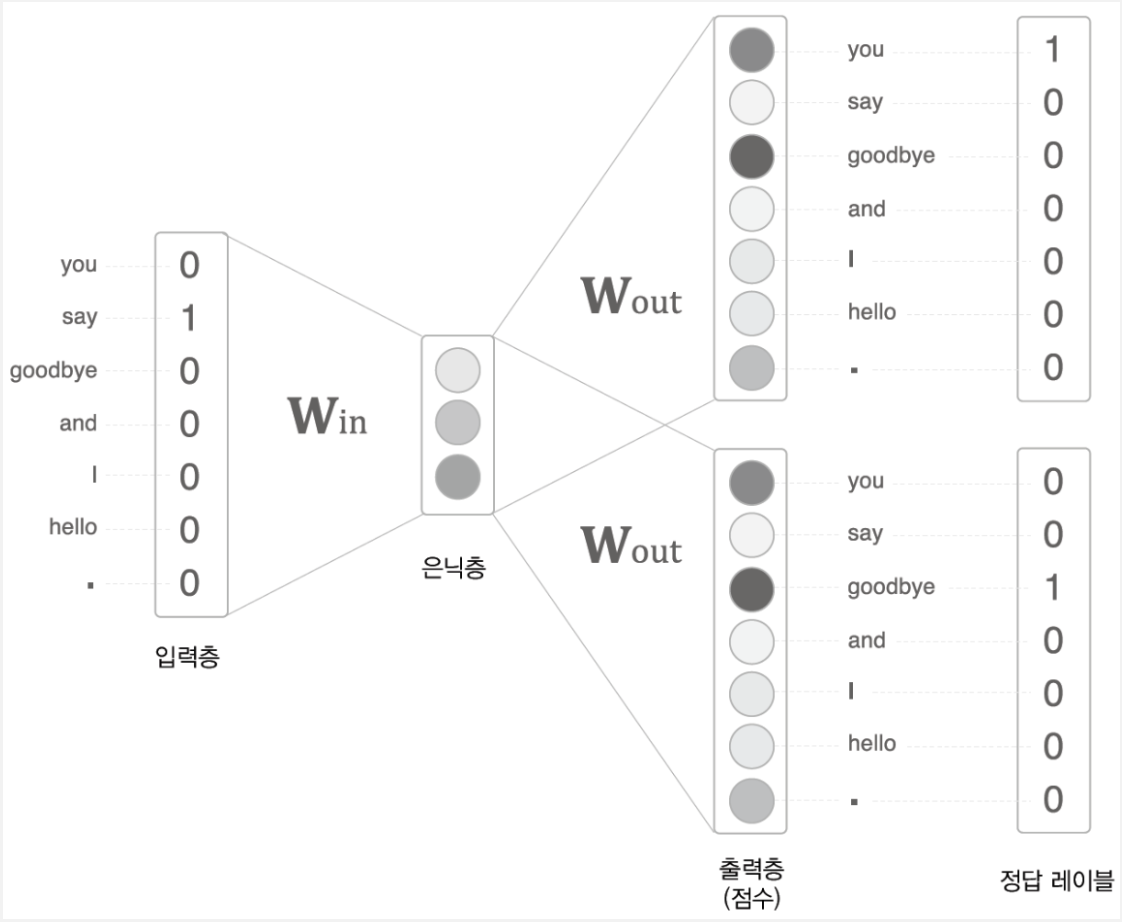
- CBOW와 동일
Skip-gram이 CBOW보다 성능이 좋은 이유
- CBOW는 윈도우 1일 경우 주변단어(2개)의 단어를 토대로 중간 단어(1개)를 맞추는 과정
- Skip-gram은 중간단어(1개)를 토대로 주변 단어(2개)를 맞추는 과정
- 딥러닝에 있어 Skip-gram이 더 어려운 Task를 수행하면서 성능이 향상 되기 때문
콘텐츠 기반 모델 장단점
장점
-
협업 필터링은 다른 사용자들의 평점이 필요한 반면에, 자신의 평점만을 가지고 추천 시스템을 만들 수 있음
-
item의 feature를 통해서 추천을 하기에 추천이 된 이유를 설명하기 용이함
-
사용자가 평점을 매기지 않은 새로운 item이 들어올 경우에도 추천이 가능함
- Cold start 문제 해결 가능
단점
- item의 feature을 추출해야 하고 이를 통해 추천하기 때문에 feature 추출의 정확도가 중요함
- Domain Knowledge가 분석시 필요함
- 기존의 item과 유사한 item 위주로만 추천하기에 새로운 장르의 item을 추천하기 어려움
- 새로운 사용자에 대해서 충분한 평점이 쌓이기 전에는 추천이 힘듬

딥러닝 지식의 백지에서 깜지까지