나이브(Naive)의 뜻
본래 자연적으로 각 단어, 즉 각 특징들 사이에 어느 정도의 상관관계가 존재한다.
그러나 나이브 베이즈 분류에서는 각각의 특징 간에 서로 아무 상관관계가 없다는 가정, 즉, 특정들이 서로 조건부 독립이라는 가정을 하게 된다.
만약 서로 다른 두 특징 A,B간의 조건부 독립이 성립한다면 아래 조건도 성립하게 된다.
P(A,B)=P(A∩B)=P(A∣B)P(B)=P(A)P(B)
여러 특징들을 일반화 하면 우도는 아래와 같다.
P(X∣Y=k)
P(X=x1,x2,…,xN∣Y=k)
P(X=x1∣Y=k)P(X=x2∣Y=k)…P(X=xN∣Y=k)
∏i=1NP(X=xi∣Y=k)
즉, 나이브 가정하에선 조건부 독립인 확률변수가 가지는 확률들의 곱으로 우도가 표현
x1,x2는 특증을 나타내고, K는 특정 분포 or 클래스를 나타낸다.
결론적으로 나이브 가정없이 베이즈 추론을 하려면 각 확률변수 사이의 상관관계도 고려해야 하기에 계산이 복잡해진다. 그러나 연관된 확률변수 간에 서로 독립이라는 가정을 함으로써 더 쉽게 베이즈 추론을 할 수 있다.
최대 우도 추정(Maximum Likelihood)
θ^=argmaxθP(D∣θ)
- θ^는 P(D|θ)를 최대로 하는 θ의 값
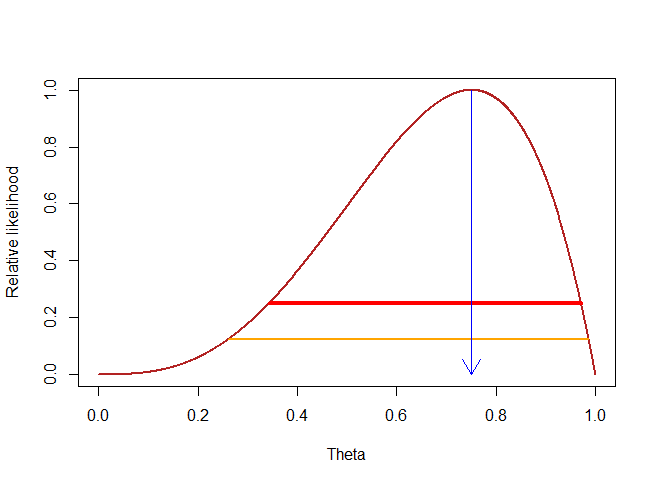
특정 사건의 확률 θ가 (0,1)사이의 범위일 때, 특정 데이터셋 D가 나올 확률 P(D|θ)는 위 그래프의 빨간선과 같다고 할때
최대 우도 추정은 위 그래프에서 확률의 최대인 점의 θ를 찾는 과정
θ^=argmaxθP(D∣θ)=argmaxθθaH(1−θ)aT
θ^=argmaxθlnP(D∣θ)=argmaxθaHlnθ+aTln(1−θ)
로그 함수(ln)는 (0,1)에서 단조 증가 함수 이므로 argmax이후의 식에서 함수를 취해도 변화하지 않는다
특정 함수의 도함수가 0이 되는 지점이 있다면 그 점이 원래 함수의 최대값 혹은 최소값일 가능성이 있기 때문에 미분을 통해 미분한 식의 값이 0이 되는 θ를 구하면 이 값이 데이터셋이 일어날 확률을 최대로 하는 특정 사건이 일어날 확률 θ를 구하는 값이 된다.

단조 함수는 주어진 순서를 보존하는 함수
실수 단조 함수의 그래프는 왼쪽에서 오른쪽으로 쭉 상승하거나 하강한다.
최대 사후 확률 추정(Maximun a Posterior Estimation)
P(θ∣D)=P(D)P(D∣θ)P(θ)
사후확률(Posterior)=정규화상수(NormalizingConstant)우도(Likelihood)×사전확률(Prior)
P(θ)=B(α,β)θα−1(1−θ)β−1
B(α,β)=γ(α+β)γ(α)γ(β),γ(α)=(α−1)!
베타 분포(Beta distribution) 정규 분포와 비슷하게 생겼지만 사건값의 범위가 정해져 있다는 차이가 있다. 정
규 분포에서 사건값의 범위는 [−∞,∞] 이지만 베타 분포의 사건값은 [0,1] 범위를 갖으며 기호로는 Beta(α,β) 로 나타낸다.
베타 분포는 특정한 모양을 가지고 있지 않으며 두 매개변수 α,β 의 값에 따라서 다양한 모양을 갖는다.
- P(θ)의 값을 알기에 식을 재정리 할 수 있다.
P(D∣θ)P(θ)=θαH(1−θ)αT×θα−1(1−θ)β−1⇒θαH+α−1(1−θ)αT+β−1
- 최대 사후 확률 추정의 목표는 사후확률인 P(θ|D)를 최대화(argmax)하는 것이다.
θ^=argmaxθP(θ∣D)
θ^=argmaxθP(θ∣D)P(θ)⇒argmaxθ[θαH+α−1(1−θ)αT+β−1]
- 최대 우도 추정과 동일하게 argmax 이하의 식에 로그를 취해준 뒤 미분하여 해당 값이 0이 되는 θ를 찾는다.
θ^=argmaxθ[θαH+α−1(1−θ)αT+β−1]
=argmaxθln[θαH+α−1(1−θ)αT+β−1]
=argmaxθ[(αH+α−1)lnθ+(αT+β−1)ln(1−θ)]
dθd[(αH+α−1)lnθ+(αT+β−1)ln(1−θ)]=0
θ(αH+α−1)−(1−θ)(αT+β−1)=0
θ^MAP=αH+α+αT+β−2αH+α−1
최대 사후 확률 추정(MAP)과 최대 우도 추정(MLE)비교
-
두 추정값의 비슷한 점은 어떤 특징 or 사건(X)이 발생했을 때 그 사건의 발생 가능성을 최대화하는 데이터 분포(Y) or 클래스를 추론한다는 점에서는 비슷하다.
-
가장 큰 차이점은 사전확률(Prior)의 개입 유무 이다.
-
사전 확률은 과거의 경험에서 나오는 값이다 따라서 사전 확률에는 인간의 개입 여지가 있다. 그 말인 즉슨, 같은 문제라도 서로 다른 사전확률을 사용해 접근할 수 있다는 말이 된다.
-
만약 사전확률을 모를경우 최대 사후 확률 = 최대 우도 추정이 된다.
나이브 베이즈 분류기의 특징
- 장점
- 결과 도출을 위해 조건부 확률(우도, 사후확률)만을 계산하면 되기 때문에 간단하고 계산량이 적어 속도가 빠르다.
- 큰 데이터셋에 적합하며, 작은 데이터셋으로도 충분히 훈련이 가능하다
- 다중 클래스 예측에도 사용 가능하다.
- 단점
- 나이브 가정을 만족하기 위해서는 특징간 독립성이 있어야 한다.
- 연속형 보다 이산형 데이터에서 성능이 좋다
