협업 필터링
정의
- 사용자의 구매 패턴이나 평점을 가지고 다른 사람들의 구매 패턴, 평점을 통해서 추천하는 방법
- 추가적인 사용자의 개인정보나 아이템 정보가 없이도 추천할 수 있음
장점
-
도메인 지식 필요X
-
사용자의 새로운 흥미를 발견하기 좋음
-
시작 단계의 모델로 선택하기 좋음
단점
-
새로운 아이템에 대해서 다루기 힘듬
-
Side feature(고객 개인정보, 아이템 추가정보)를 포함시키기 어려움
1. Neighborhood based method
정의
- 메모리 기반 알고리즘으로 협업 필터링을 위해 개발된 초기 알고리즘
알고리즘
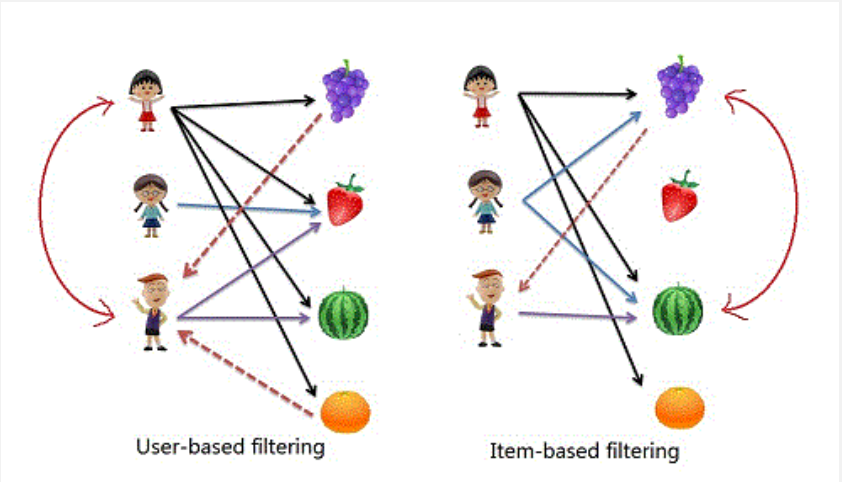
- User-based collaborative filtering
- 사용자의 구매 패턴(평점)과 유사한 사용자를 찾아서 추천 리스트 생성
- Item-based collaborative filtering
- 특정 사용자가 준 점수간의 유사한 상품을 찾아서 추천 리스트 생성
1-1. KNN (K Nearest Neighbors)
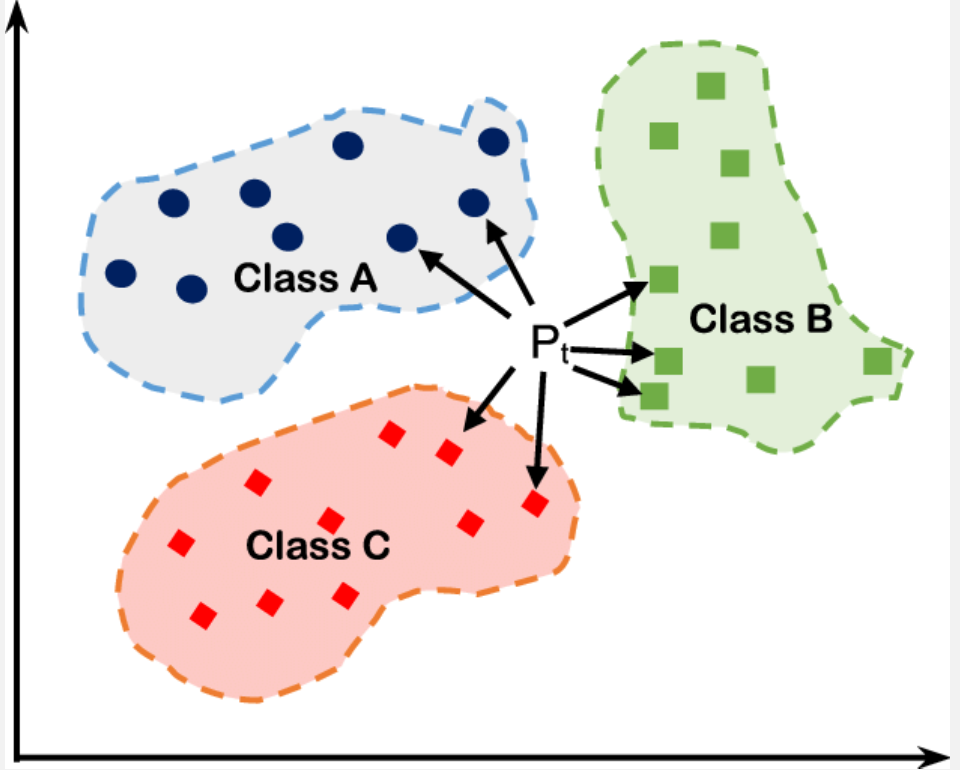
- 가장 근접한 K 명의 neighbors를 통해서 예측하는 방법
알고리즘 예시
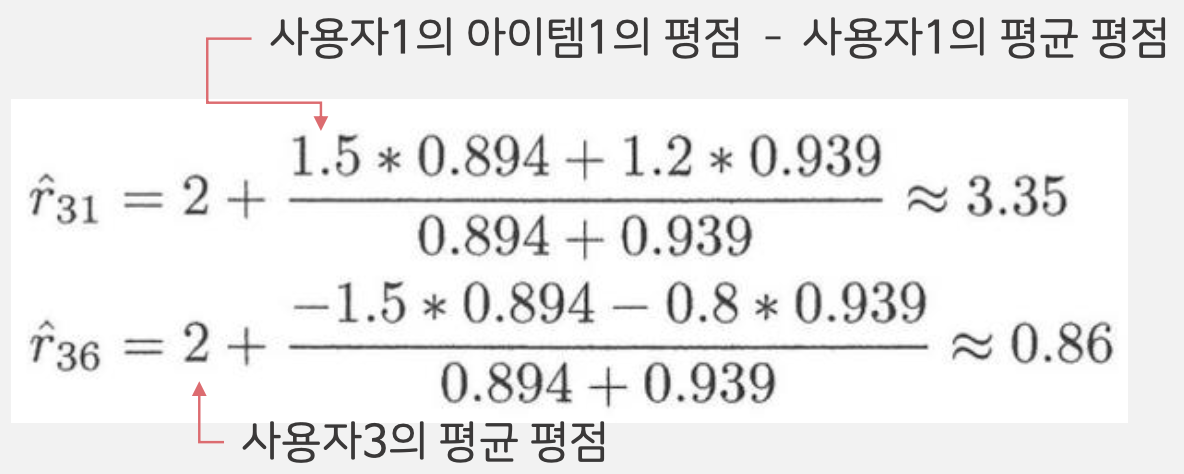
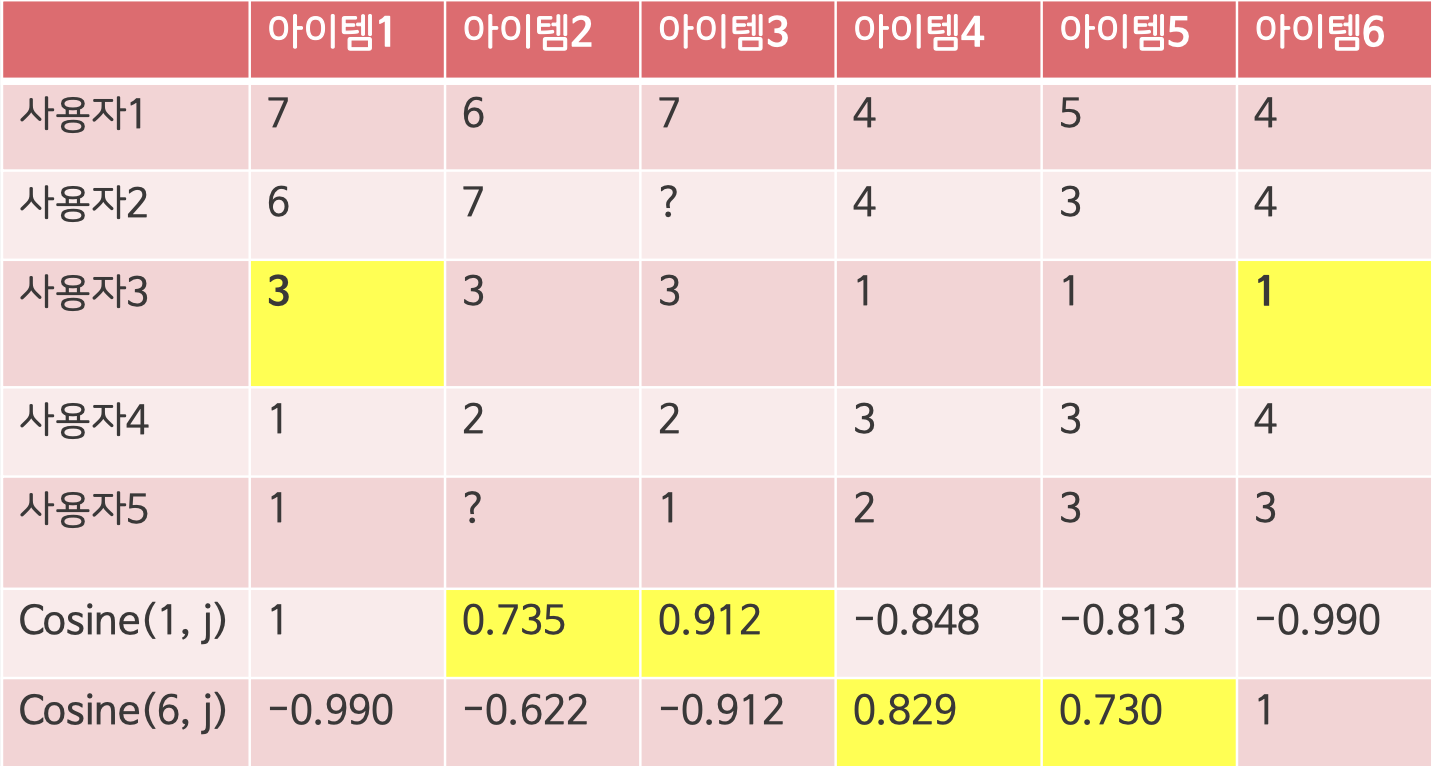
사용자 3의 아이템 1과 6을 추천해주는 예시
1. 유사도계산 (= Cosine / Pearson)
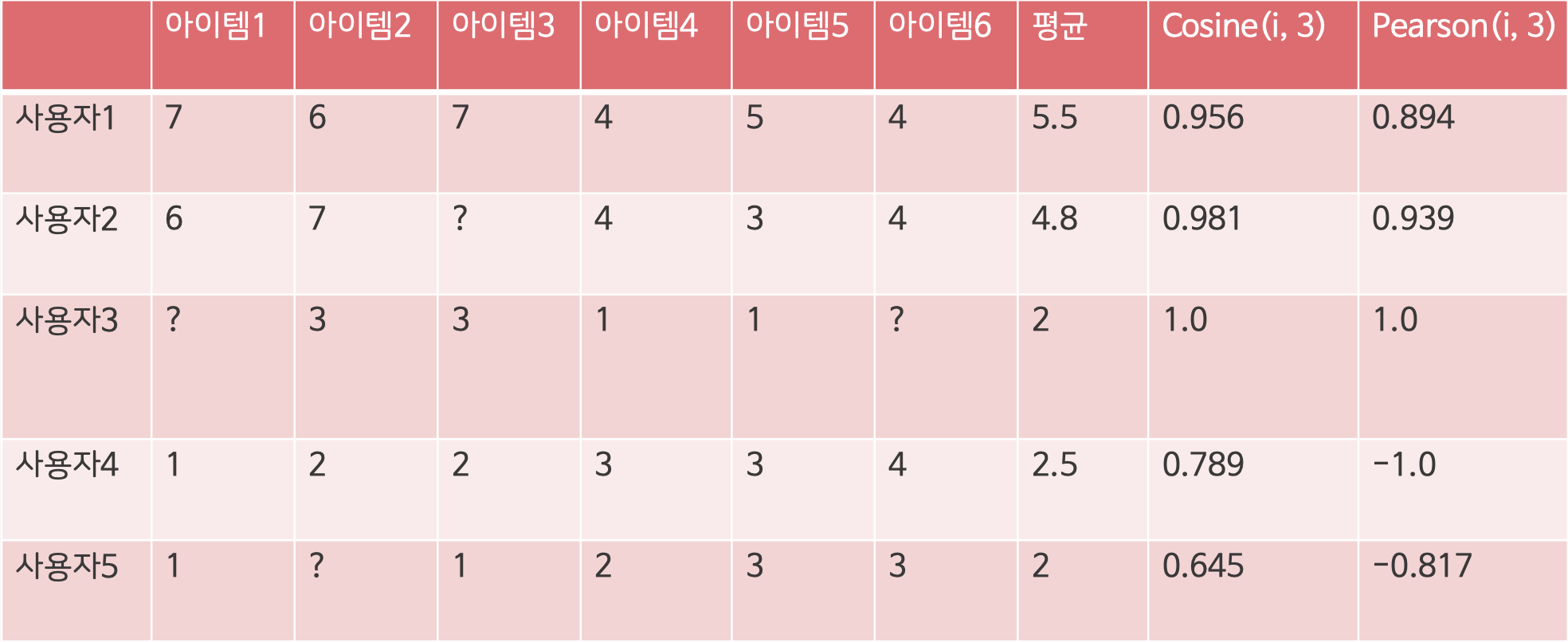
2. 사용자 1과 사용자 2의 아이템 1과 6이 사용자 3과 비슷하기 때문에 두 사용자의 데이터를 활용해서 평균평점을 계산
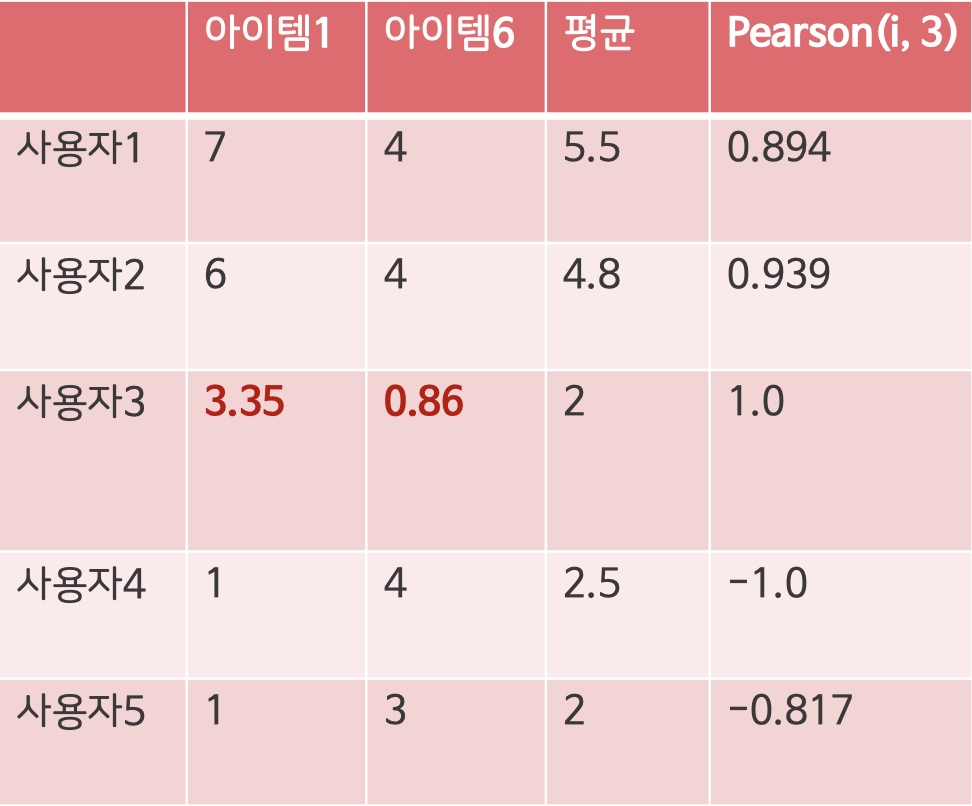
- Pearson을 활용해 사용자들의 Bias를 제거하고 계산
3. 아이템 간의 유사도 계산
장점
- 간단하고 직관적인 접근 방식을 통해 구현 및 디버그가 쉬움
- 특정 Item을 추천하는 이유를 정당화하기 쉽고 Item 기반 방법의 해석 가능성이 두드러짐
- 추천 리스트에 신규 Item과 User가 추가 되어도 상대적으로 안정적
단점
- User 기반 방법의 시간, 속도, 메모리가 많이 필요
- 희소성에 따른 제한 범위 존재
- Top-K에만 관심이 있음
- 평가 값이 없다면 해당 Item 혹은 User에 대한 예측 제공이 불가능
2. Latent Factor
정의
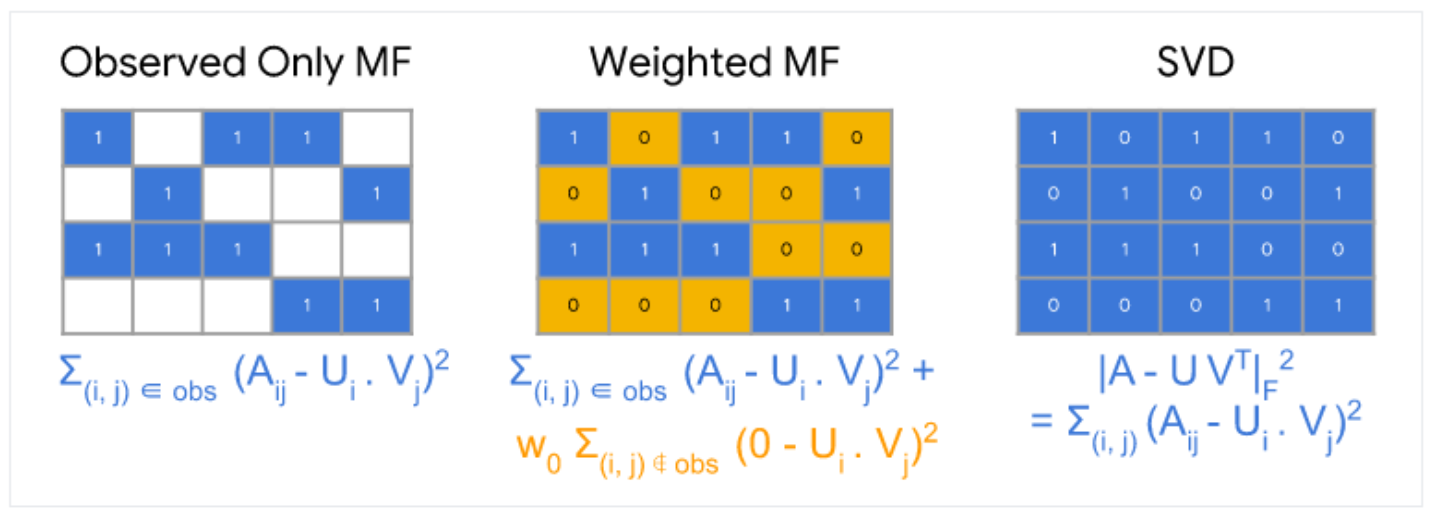
- Rating Matrix에서 빈 공간을 채우기 위해서 사용자와 상품을 잘 표현하는 차원을 찾는 방법
원리
- 사용자의 잠재요인과 아이템의 잠재요인을 내적해서 평점 Matrix을 계산
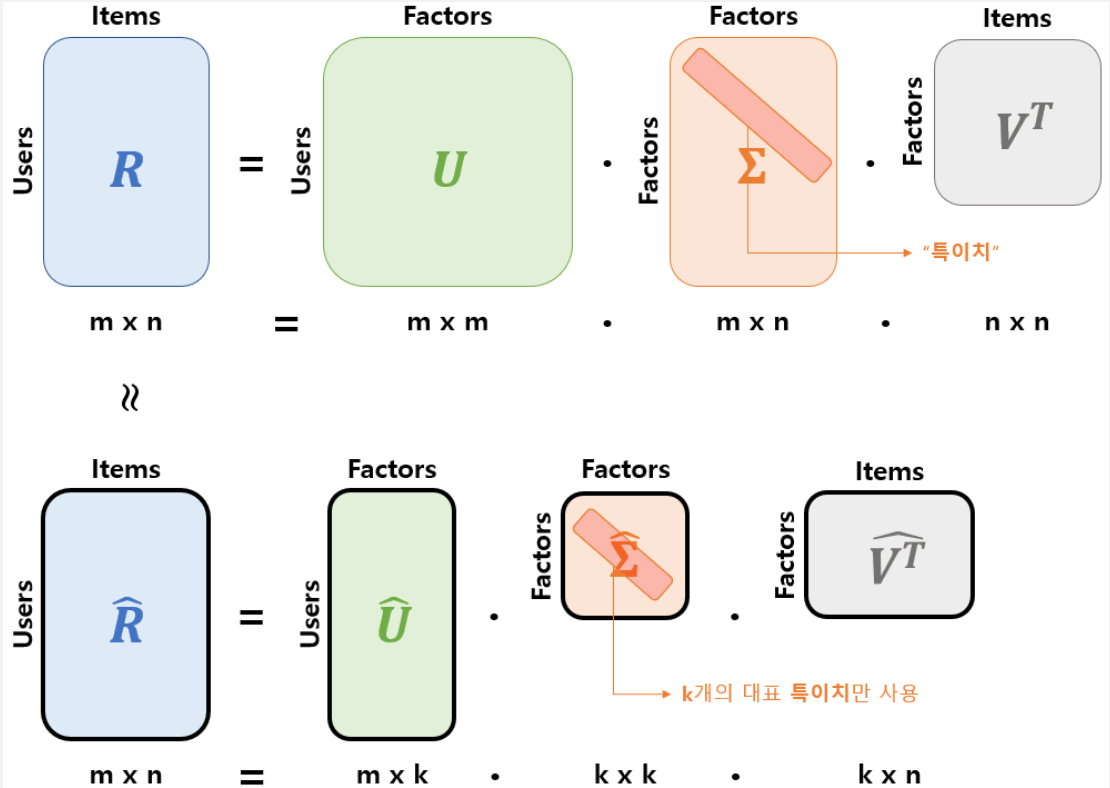
2-1. SVD
- 특이값 분해와 같은 행렬을 대각화 하는 방법
한계
- 결측치가 없는 데이터가 필요함
- 하지만 대부분의 현업 데이터는 Sparse한 데이터
2-2. SGD
-
고유값 분해와 같은 행렬을 대각화 하는 방법
-
평점이 있는 부분에 대해서 Matrix Factorization을 시행하고 해당 부분의 오차를 최소화하는 것
-
이때, Gradient Descent처럼 오차를 최소화하는 방향을 찾기 위해 편미분을 수행
-
딥러닝을 수행하다 보면 보통 특정 Weight가 커지는 문제점이 생기고 이를 방지하기 위해서 Regularization을 수행
알고리즘 예시
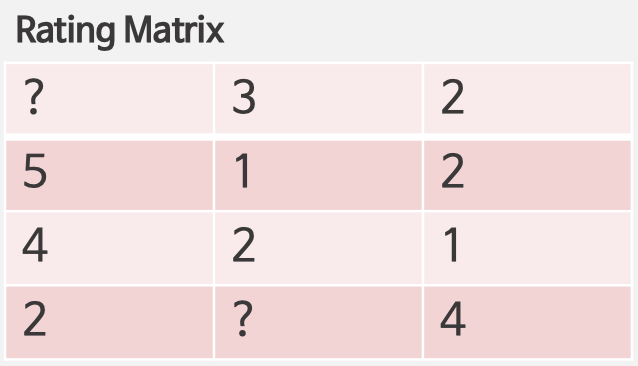
1. User Latent와 Item Latent을 Random Initialization 후 Dot-product 수행

2. Gradient Desent 수행
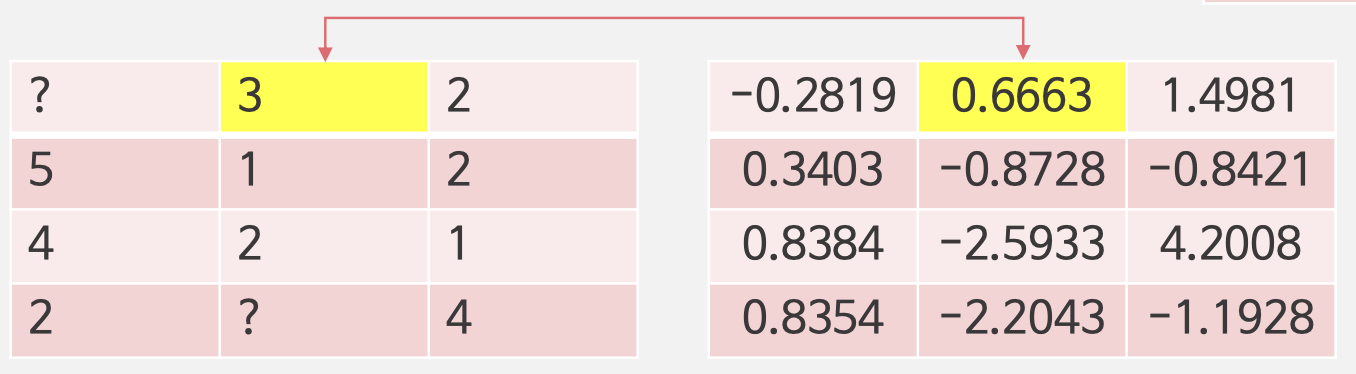

3. Weight Update

4. 모든 평점에 대해서 반복
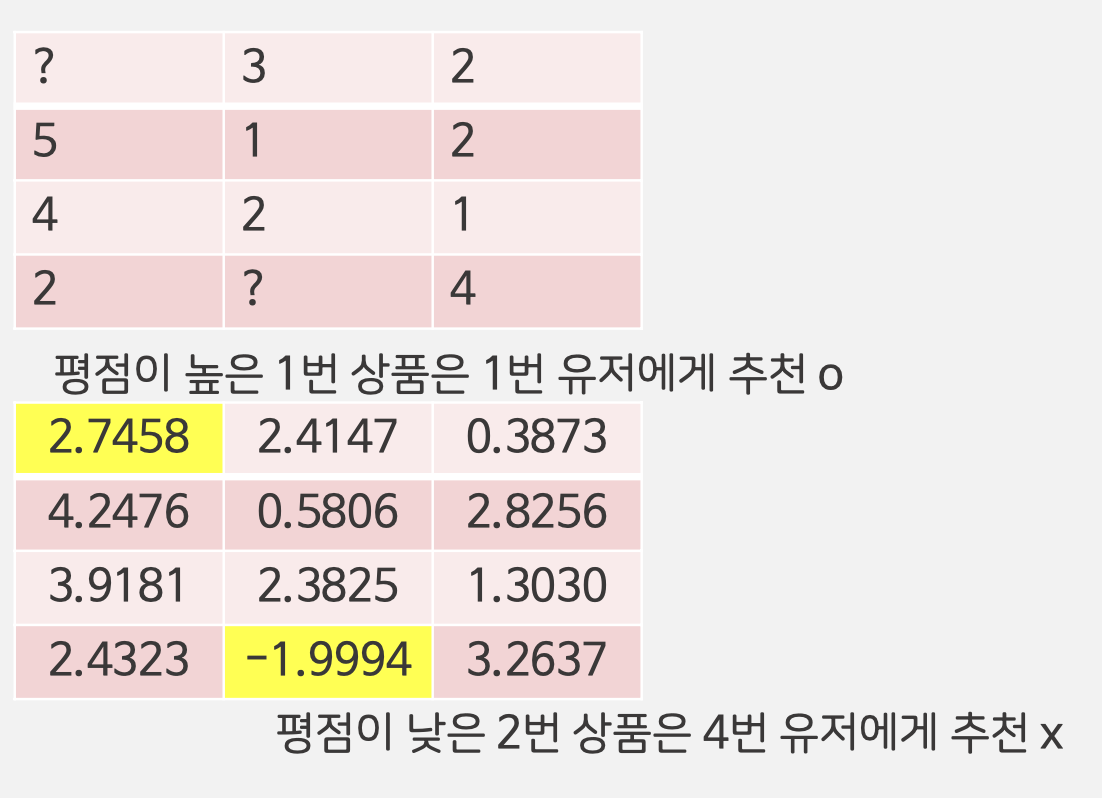
장점
- 매우 유연한 모델로 다양한 Loss Function을 사용 가능
- Parallelized 가능
단점
- 수렴 속도가 매우 느림
2-3 ALS
-
기존의 SGD가 두개의 행렬을 동시에 최적화 하능 방법이라면
ALS는 두 행렬 중 하나를 고정시키고 다른 하나의 행렬을 순차적으로 반복하면서 최적화 하는 방법 -
기존의 최적화 문제가 convex 형태로 바뀌기에 수렴된 행렬을 찾을 수 있는 장점 존재
알고리즘 예시
1. 초기 아이템, 사용자 행렬 초기화
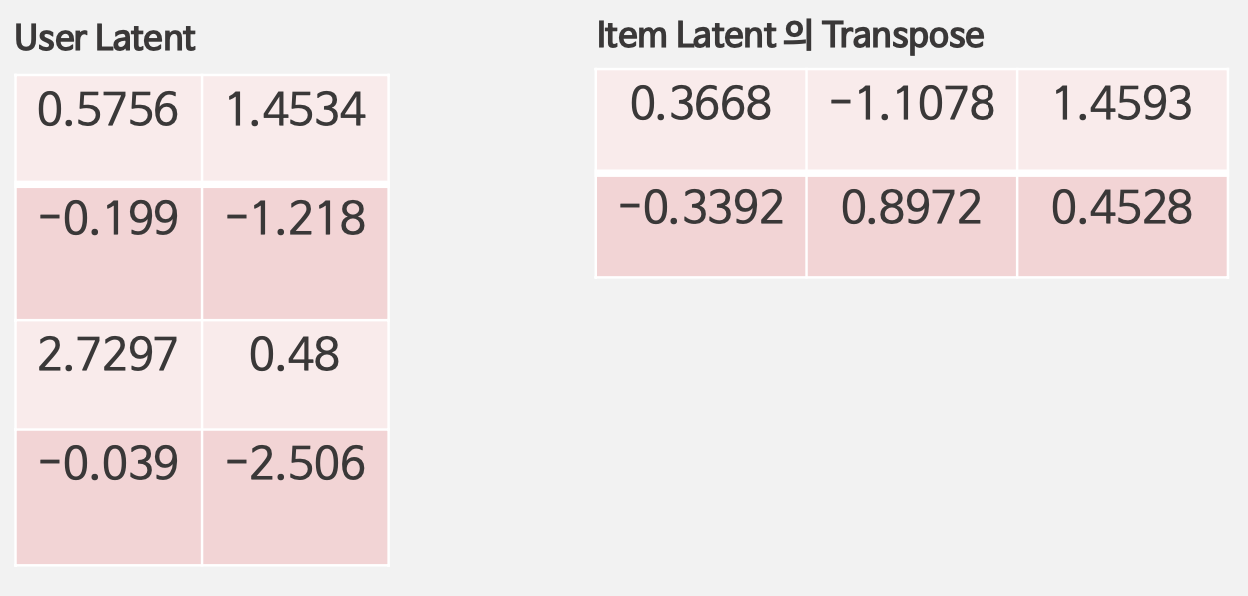
2. 아이템 행렬을 고정하고 사용자 행렬을 최적화

3. 사용자 행렬을 고정하고 아이템 행렬을 최적화

4. 과정 반복
장점
- SGD 보다 수렴속도가 빠름
- Parallelized 가능
단점
- 오직 Loss Squares만 사용가능
