앙상블이란?
-
여러개의 기본 모델을 활용해 하나의 새로운 모델로 만드는 것
-
기본 모델을 weak learner / classifier / base learner / single learner 라고 부름
-
bagging / boosting / random forest / stacking 등의 기법이 존재
-
원칙
-
앙상블에 쓰일 base learner의 정확도는 적어도 0.5 보다는 커야한다.
-
각각의 base learner는 독립이다.
-
앙상블의 종류
-
Bagging
-
모델을 다양하게 만들기 위해 데이터를 재구성
-
동일 데이터를 반복 복원추출을 통해 다양한 데이터셋을 만들고 학습시켜
-
voting을 통해 결과를 도출
-
-
Boosting
-
맞추기 어려운 데이터에 가중치를 두어 학습을 하는 것
-
즉, 정확도가 낮은 데이터를 집중적으로 학습
-
Adaboost, Xgboost, LightGBM, Catboost 등
-
-
Random Forest
-
모델을 다양하게 만들기 위해 데이터 및 변수 재구성
-
즉, Bagging 처럼 데이터를 반복 복원 추출하지만 변수의 조합 또한 랜덤 추출을 진행
-
특정 변수만 사용하는 형상이 될 수 있음
-
-
Stacking
- 모델의 Output을 새로운 독립변수로 하여 다른 학습 모델의 input으로 넣는 것
Bagging
-
복원 추출한 데이터들을 합치는 것 (=Bootstrap Aggregating)
-
Bootstrap
-
반복 복운 추출을 통해 데이터를 N번 반복해서 뽑는 것
-
복원이 가능하기에 중복도 가능
-
ex) dataset = [1,2,3,4,5,6,7]
Bootstrap_sample_1 = [1,2,3]
Bootstrap_sample_2 = [4,2,6]
Bootstrap_sample_3 = [1,7,5]
Bootstrap_sample_N = [2,7,3]
-
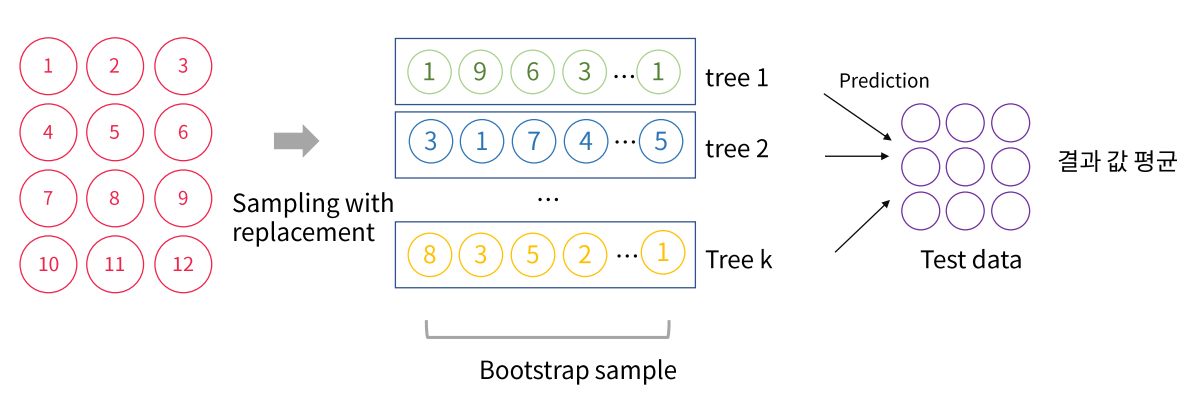
Bagging의 원리
-
Bootstrap sample은 크기 N 만큼 생성하고 N개의 sample dataset을 각각 학습
-
이후 결과를 모두 합쳐 voting을 진행하거나 평균을 내는 방식
-
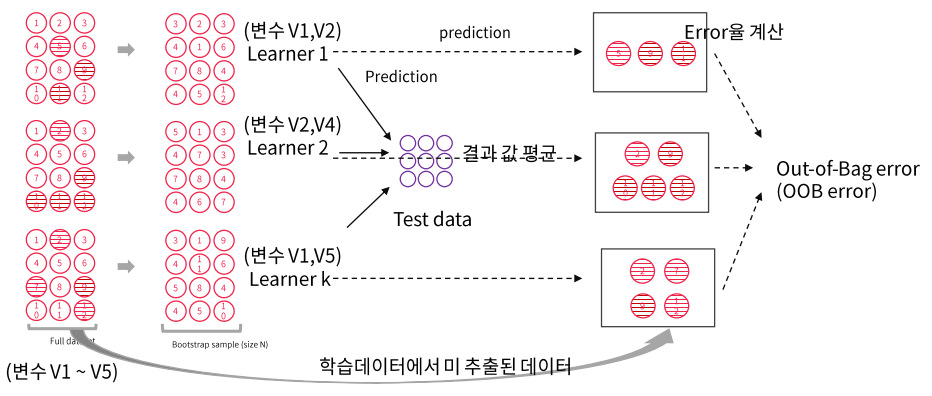
Bagging에 사용되는 base learner의 error는 Bootstrap에서 제외된 데이터를 사용
-
만약 전체 데이터셋 [1,2,3,4,5,6,7]이 있을 때
-
base learner data = [1,3,4,6]이라면
-
제외된 데이터인 [2,5,7]을 test dataset으로 사용해 error를 계산
사용되지 않은 데이터를 OOB(Out-Of-Bag error)라고 부름 -
전체 모델의 error는 각 error들의 평균을 통해 계산
-
-
장점
-
편향은 유지하되 분산을 감소시킴으로써 학습 데이터의 Noise에 영향을 덜 받게된다.
기존 Decision Tree의 경우 Depth가 커지면 편향은 감소하지만, 분산은 증가가 유발됨 -
과적합에 대한 강점을 가지고 있다.
-
단점
-
과정을 해석하기 어렵다
-
복원 추출을 진행하기 때문에 독립이라는 보장이 없음
-
공분산이 0이라는 조건을 만족하지 않아 비슷한 Tree가 만들어질 가능성이 크다.
-
Random Forest
Bagging의 경우 복원 추출을 하기 때문에 중복 데이터가 존재하게 된다.
그렇기 때문에 독립이 아니게 되고, base learner간의 공분산이 발생하게 된다.
(비슷한 Tree가 만들어질 가능성이 높다)
공분산을 줄이기 위해 나온 방법이 random forest이다.
-
Bagging처럼 반복 복원 추출 + 변수 random 추출
-
개별 나무들의 상관성을 줄여 예측력을 향상 시킨 모델
-
개별 나무 내에서 특성이 따라 분리할 경우 랜덤으로 변수 후보를 선택하기 때문에 개별 나무들끼리 같이질 가능성이 적다 (=상관성이 작아진다)
-
장점
-
분류, 회귀 문제에 모두 사용 가능
-
결측치를 다루기 쉽다.
-
대용량 데이터 처리에 용이하다.
-
과적합 문제에 강점이 있다,
-
특성별 중요도를 구할 수 있다.
-
-
단점
-
데이터 크기에 비례해서 수 많은 트리를 형성하기에 시간이 오래 걸린다.
-
모든 트리 모델을 다 확인하기 어렵기에 해석 가능성이 떨어진다.
-
