Boosting이란?
-
오분류된 데이터 (= 정확도가 낮은 데이터)에 더 많은 가중치를 주는 기법
-
가장 처음 learner에서는 모든 데이터가 동일한 가중치를 가지나, 라운드가 종료될 때마다 가중치와 중요도를 계산
-
이후 복원 추출을 진행할 때, 가중치의 분포를 고려해서 추출
-
가중치의 분포를 고려한다는 것은 오분류된 데이터에 가중치를 더 얻게 되어 다음 라운드에서 더 오분류된 데이터를 추출할 가능성이 높다는 것
-
AdaBoost, LPBoost, LogitBoost, Gradient Boosting 들이 존재
AdaBoost
- 가장 기본적인 Boosting 기법
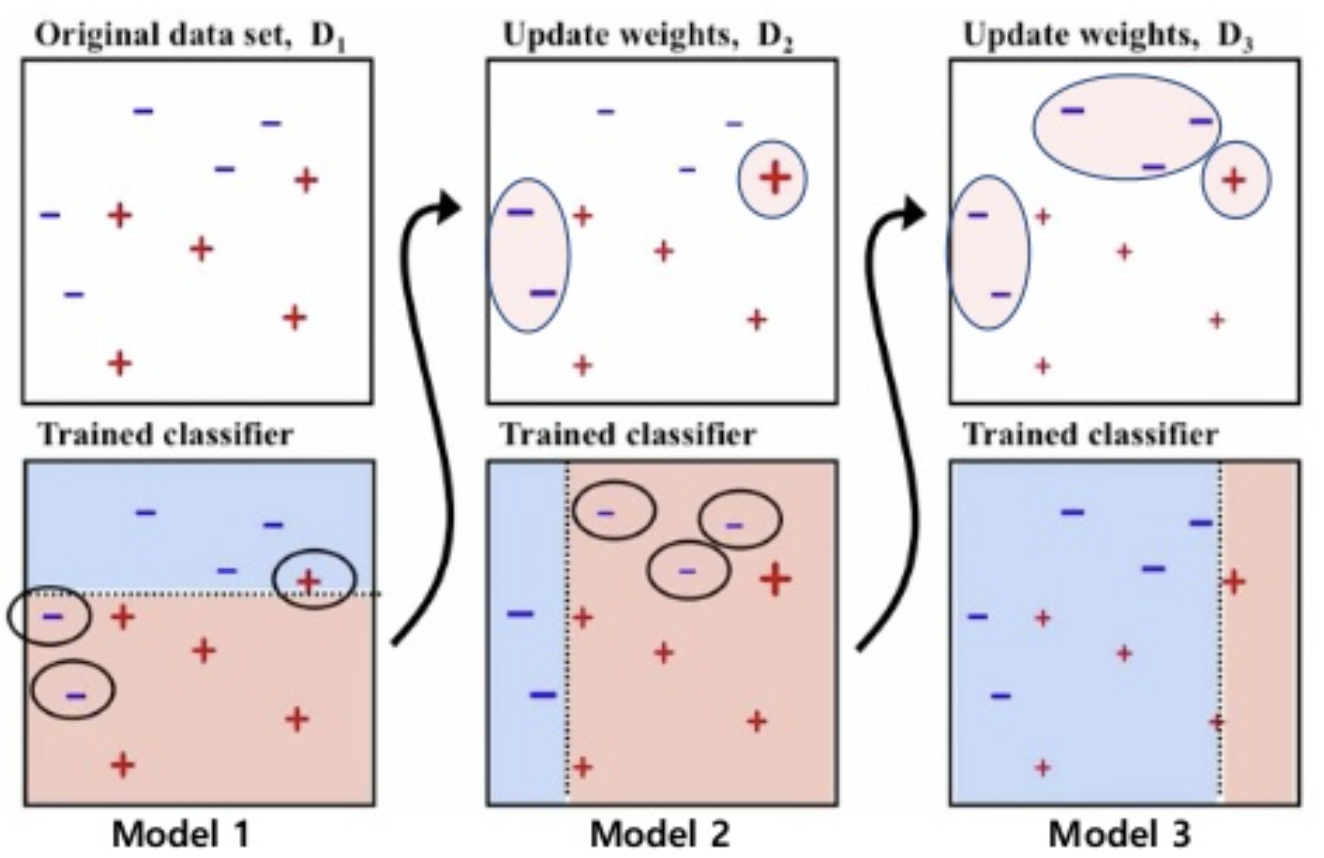
-
dataset 파란색 -와 빨간색 +를 분류하는 경우
-
Model 1에서 1차적으로 분류를 진행
-
1차적으로 분류된 데이터에서 잘못 분류된 데이터를 더 잘 분류하도록 가중치를 크게 주어 재분류(Model2)
-
Model 1과2가 잘못 분류한 데이터를 더 잘 분로하도록 가중치를 크게 주어 분류 (반복)
-
3개의 모델별 가중치를 계산해 최종 분류 모형을 생성
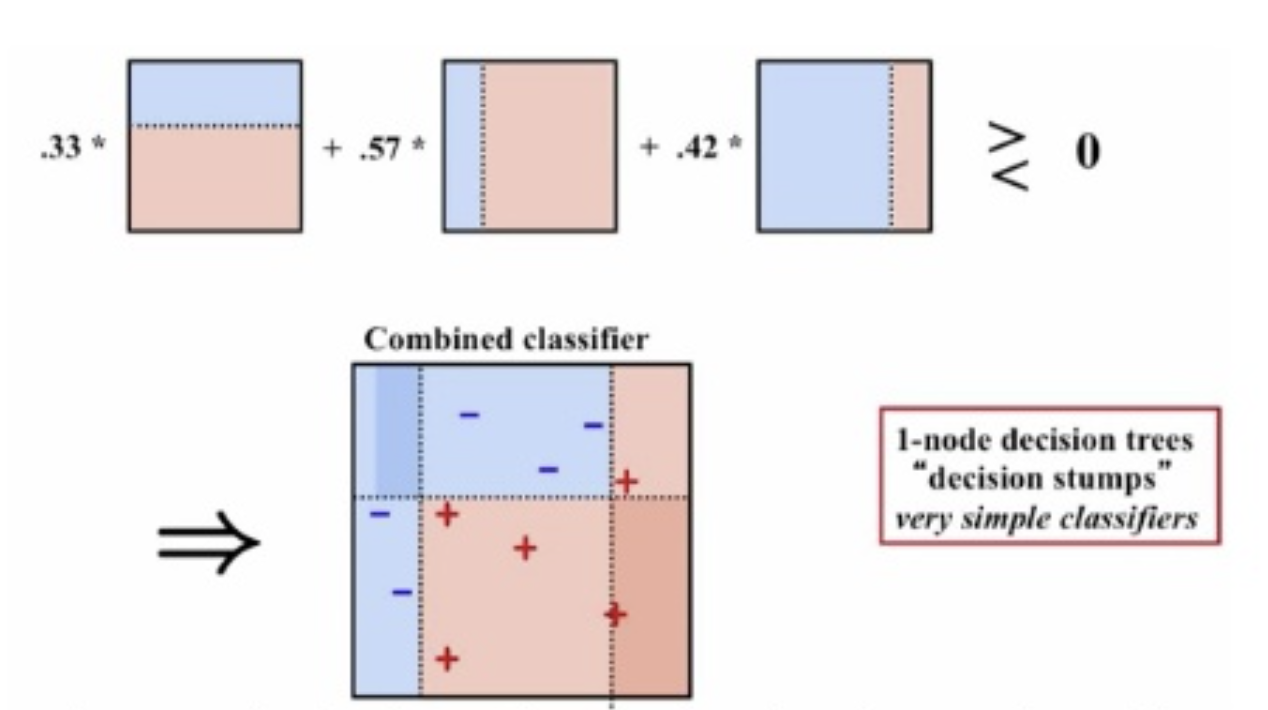
-
: 최종 분류기 (final classifier)
-
: m번째 라운드에서 생성된 약한 분류기(오분류)에 대한 가중치
이 작다는 것은 m번째 라운드의 분류기가 안좋은 성능을 보인다는 것 -
: m번째 라운드에서 생성된 약한 분류기(오분류)를 의미
Gradient Boosting의 원리
-
XGBoost / LightGBM / CatBoost 등이 존재
-
이전 round 분류기의 데이터 별 오류를 예측하는, 또 다른 분류기를 학습시키는 방식
-
즉, 데이터의 오차를 학습하는 또 다른 분류기를 형성하는 것
-
Loss function의 negative gredient를 다음 학습의 정답으로 사용 하는 방식
-
Loss의 negative gradient = residual(잔차)
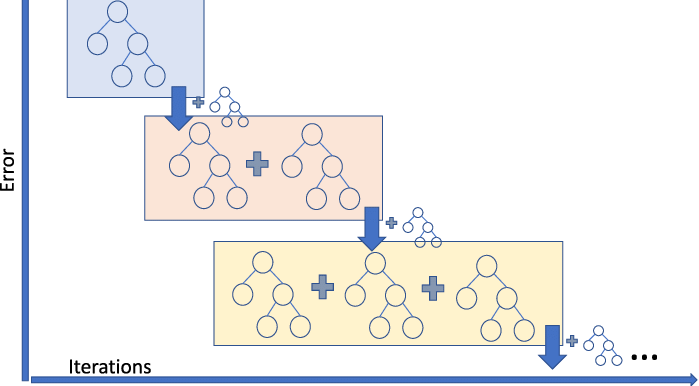
-
A 모델은 전체 데이터의 target varible의 평균으로 예측값을 생성
-
실제값(target) - A 모델의 예측값(평균값) = 잔차(residual_1)
-
위에서 생성된 residual_1은 B 모델이 학습할 정답
-
B 모델은 A 모델 학습에 사용했던 feature를 가지고 residual_1을 맞추는 방식으로 학습을 진행
-
실제값(residual_1) - A 모델의 예측값(평균값) - (learning_rate * B 모델의 예측값) = 새로운 잔차(residual_2)
-
C 모델은 A 모델의 학습에 사용했던 feature를 가지고 새로운 잔차(residual_2)를 맞추도록 학습
-
실제값(residual_2) - A 모델의 예측값 - (learning_rate B 모델의 예측값) - (learning_rate C 모델의 예측값) = 새로운 잔차(residual_3)
-
모든 학습을 완료한 경우, 최종 예측값은 모든 모델의 예측값의 Weighted Sum이 된다.
negative gradient는 loss function이 줄어드는 방향을 의미
즉, gradient가 양수라면 음수 방향(=negative gradient의 방향)으로 이동해야 loss function이 줄어드는 것
gradient가 음수라면 양수 방향(=negative gradient의 방향)으로 이동해야 loss function이 줄어들게 된다.
XGBoost
-
기존 Gradient Boosting식에 Regularization term을 추가한 것
-
Regularization term을 추가해 복잡한 모델에 패널티를 부여해 과적합을 방지시키는 목적
-
level wise 방식
-
병렬 학습이 지원되도록 구현한 라이브러리
-
회귀, 분류 모두 사용 가능하고 성능과 자원 효율에 장점
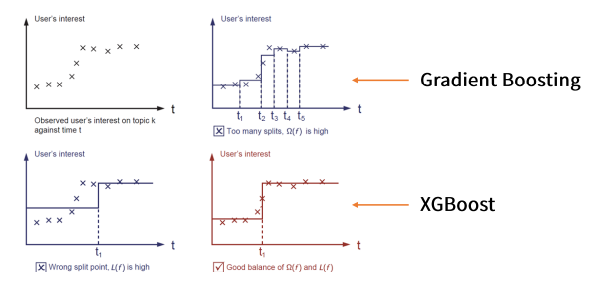
Gradient Boosting에 비해 상대적으로 오버피팅이 해소된 것을 볼 수 있다.
LightGBM
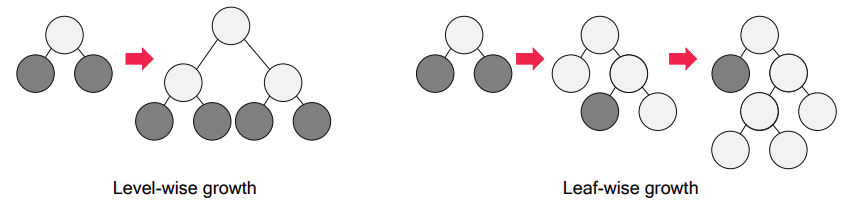
- 기존 level wise(균형 트리 분할) 방식과 다르게 leaf wise(리프 중심 트리 분할)방식을 채택
Tree의 균형을 고려하지 않고 최대 손실 값(max data loss)를 가지는 leaf node를 지속적으로 분할하면서 tree의 깊이가 깊어지고 비대칭적인 tree가 형성
깊이가 깊어지기는 하지만 최대 손실 값을 가지는 leaf node를 지속적으로 분할해 생성된 규칙 트리는 학습을 반복하면서 level wise보다 예측 오류 손실을 최소화 할 수 있다.
-
학습 시각이 더 빠르고 메모리 사용량도 더 적다
-
categorical feature들의 자동 변환과 최적 분할 방식
-
하지만 작은 dataset을 사용할 경우 과적하의 가능성이 크다.
level wise와 leaf wise 두 방법 모두 트리를 full-depth로 기르고 나면 동일한 트리가 탄생한다.
하지만 보통 full tree를 사용하지 않고 cut-off를 하기 때문에 두 방법은 유의한 차이가 있는 결과를 낸다.
Leaf-wise는 Split(분기)가 발생할때 특정 branch(줄기)를 따르는 것이 아니라 'global loss'를 더 줄일 수 있는 방향으로 확장하는 것을 택한다.
따라서 level-wise보다는 대개의 경우 더 정확도가 높은 트리를 빨리 발견할 수 있다.
CatBoost
-
Categorical Boosting으로 Catagorical feature를 처리하는데 중점을 둔 알고리즘
-
XGBoost와 동일하게 Level wise 방식을 사용
-
기존의 Boosting 기법은 모든 데이터의 잔차(residual)을 일괄 계산하지만,
CatBoost기법은 순서에 따라 모델을 만들고 예측하는 방식인 Ordered Boosting을 사용한다. -
또한 순서를 섞어 주기 위해 data를 Shuffling 하여 뽑아낸다.
- 먼저 x1 의 잔차만 계산하고, 이를 기반으로 모델을 만든다. 그리고 x2 의 잔차를 이 모델로 예측한다.
- x1, x2 의 잔차를 가지고 모델을 만든다. 이를 기반으로 x3, x4 의 잔차를 모델로 예측한다.
- x1, x2, x3, x4 를 가지고 모델을 만든다. 이를 기반으로 x5, x6, z7, x8 의 잔차를 모델로 예측한다.
- 반복
-
Target encoding을 사용
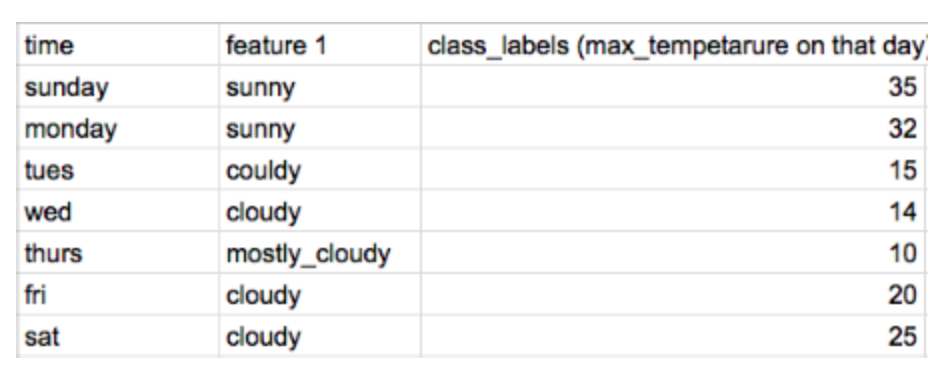
class label을 예측하고자 할때 cloudy 카테고리는 아래와 같이 인코딩 될 수 있다.
cloudy = (15 + 14 + 20 +25) / 4 = 18.5
하지만 이는 예측값이 훈련 feature에도 들어가기 때문에 오퍼피팅을 발생시킬 수 있다.
이에 대한 해결책으로 현재 데이터를 인코딩하기 위해 이전 데이터들의 인코딩된 값을 사용하는 것이다.
Friday에는 이전까지의 값인 (15 + 14) / 2 = 15.5로 인코딩
Saturday에는, 이전까지의 값인 (15 + 14 20) / 3 = 16.3으로 인코딩
즉 현재 데이터를 사용하지 않고 이전 데이터들의 값만 사용해 오버피팅을 방지하는 것이다.
