RNN의 단점
기존 자연어 처리는 RNN을 토대로 이루어졌습니다.
하지만 RNN은 큰 단점이 있습니다.
- 하나의 고정된 크기 벡터에 모든 정보를 압축하기 때문에 정보 손실이 발생
- RNN의 고질적인 문제인 기울기 소실(Vanishing Gradient) 문제 존재
다음과 같은 문제로 인해 기계번역 분야에서 문장의 길이가 길어지면 번역의 품질이 떨어지는 문제가 발생합니다.
이를 해결하기 위해 나온 것이 Attention 입니다.
어텐션 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고하는 것인데요.
다만, 모두 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야 할 단어와 연관성 있는 입력 단어 부분을 좀 더 집중해서 봅니다.
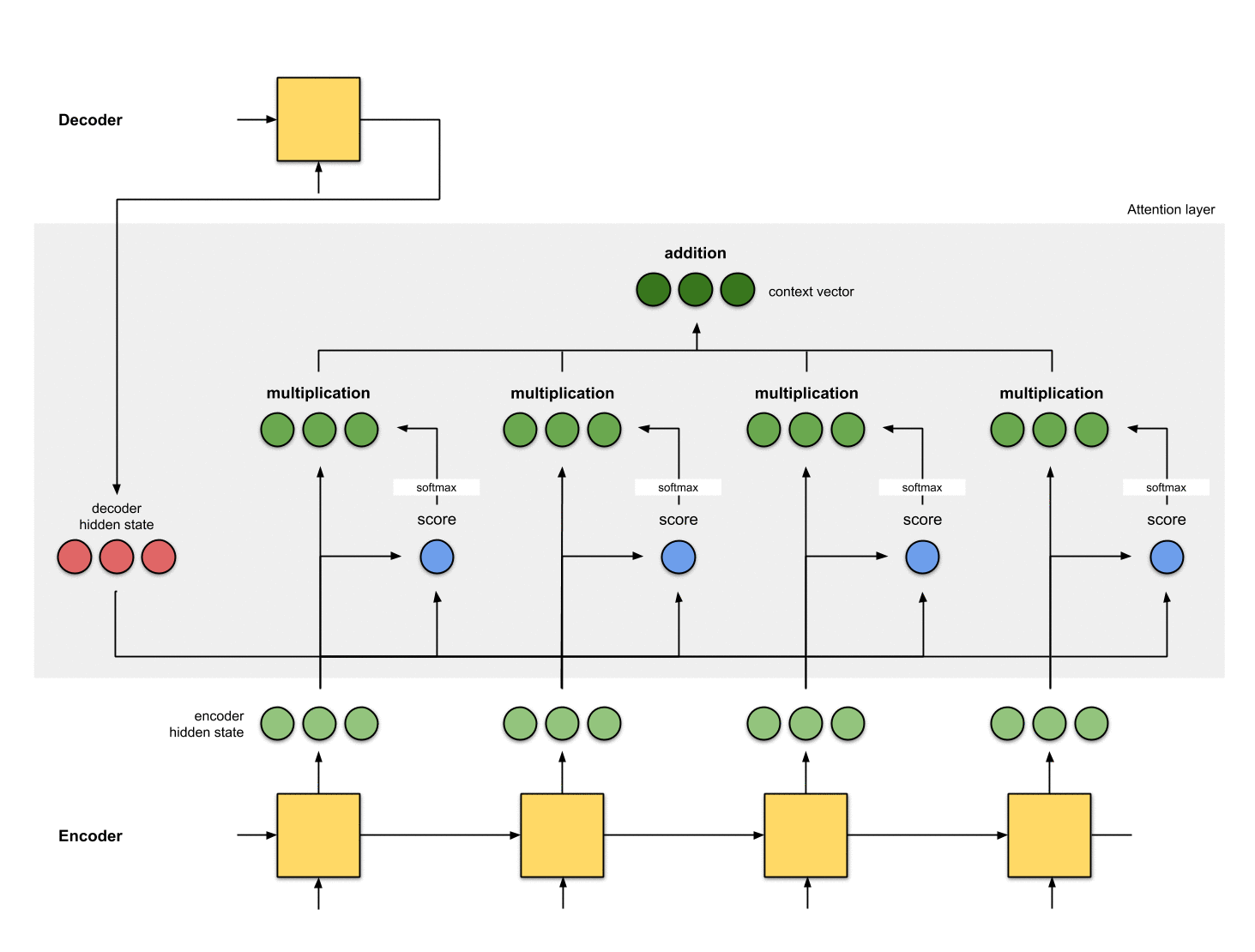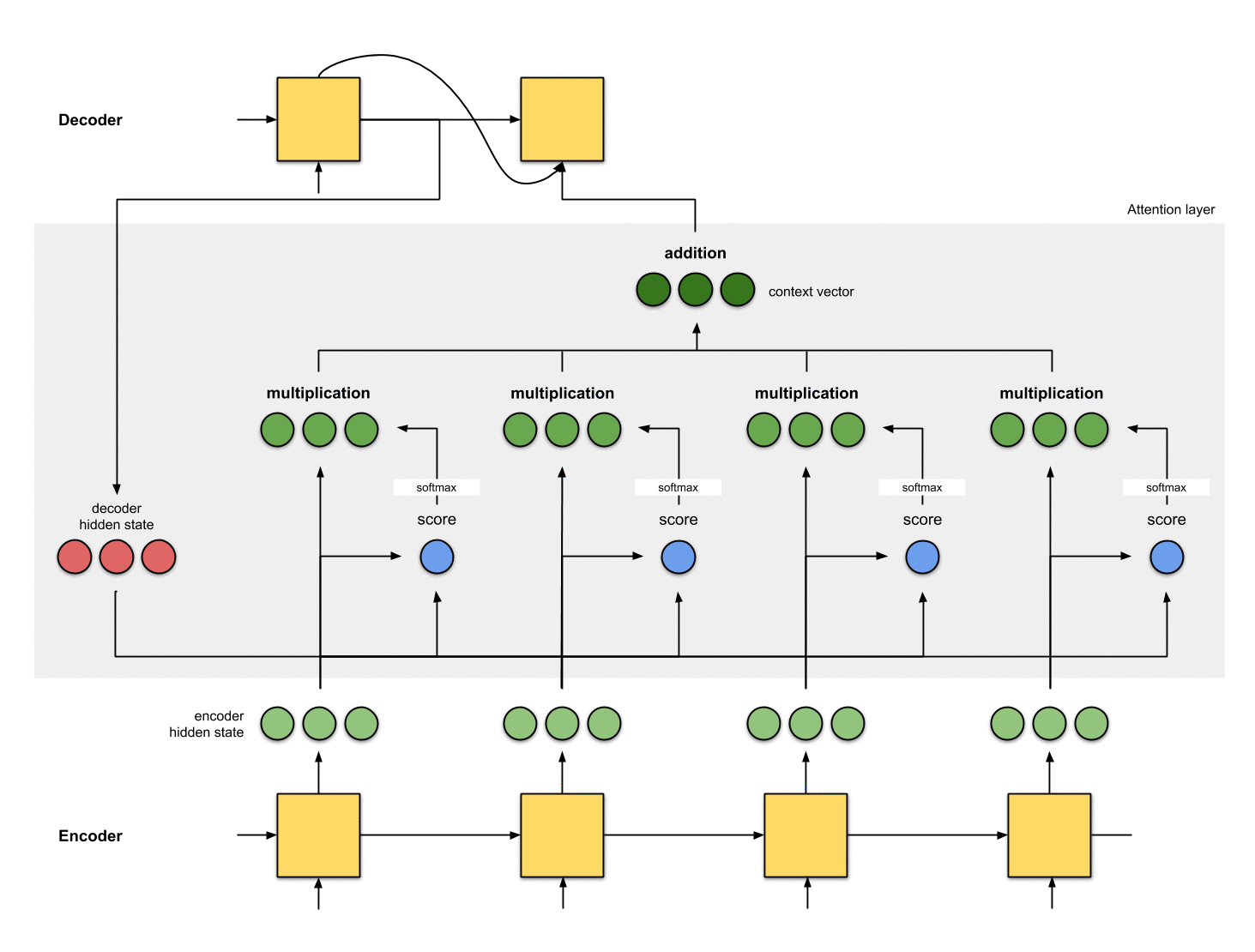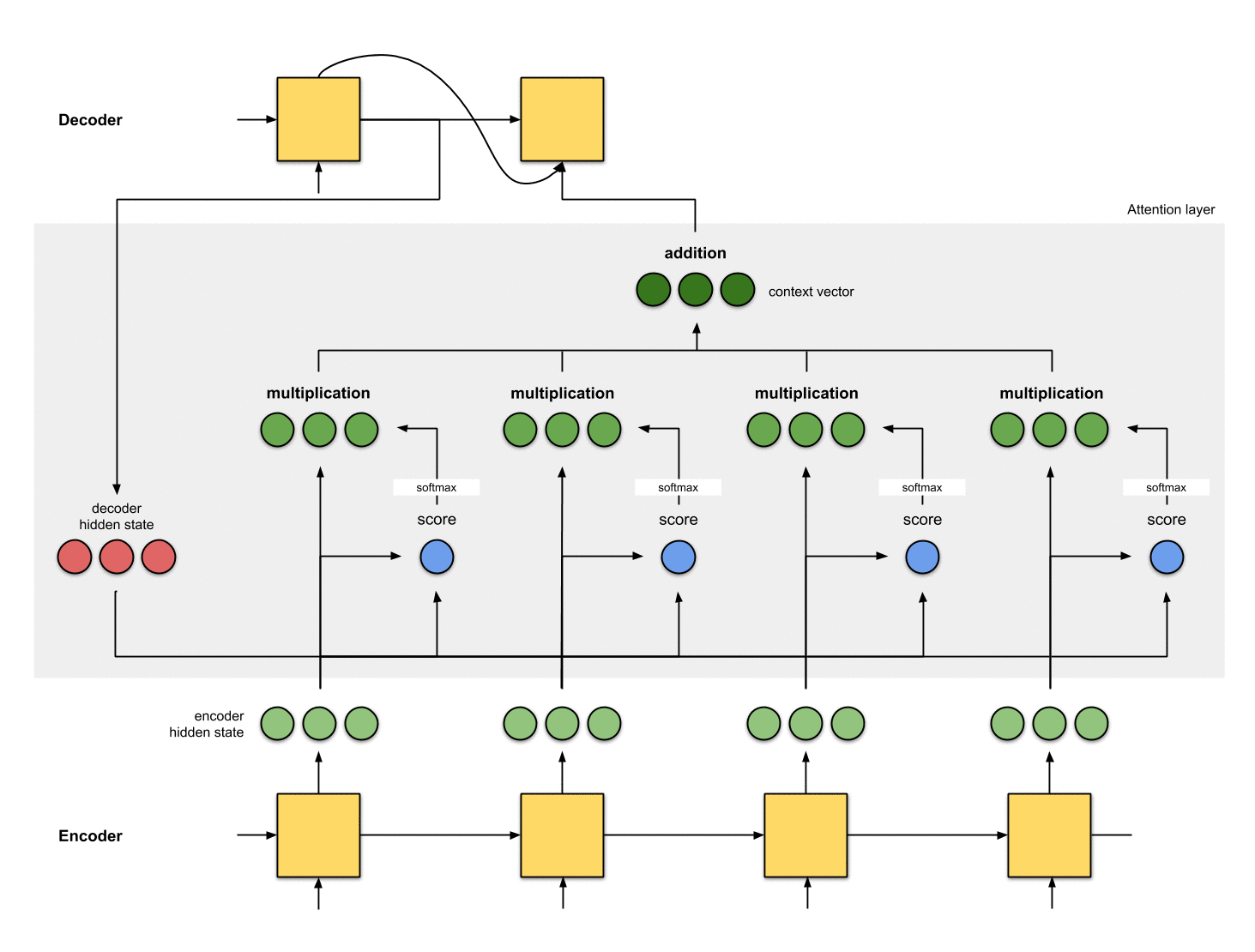
Attention Layer의 구현
Attention Layer의 구현은 다음과 같습니다.
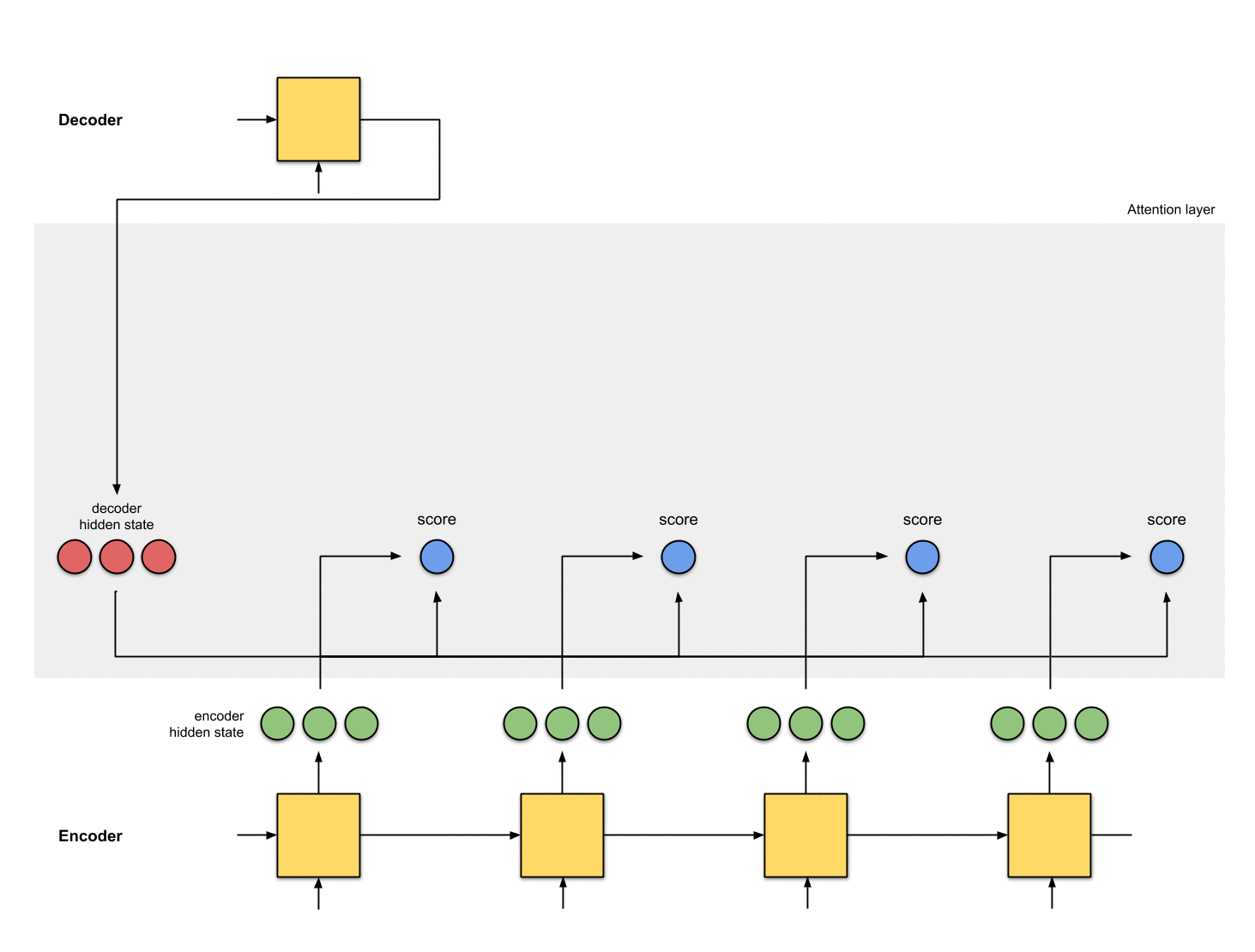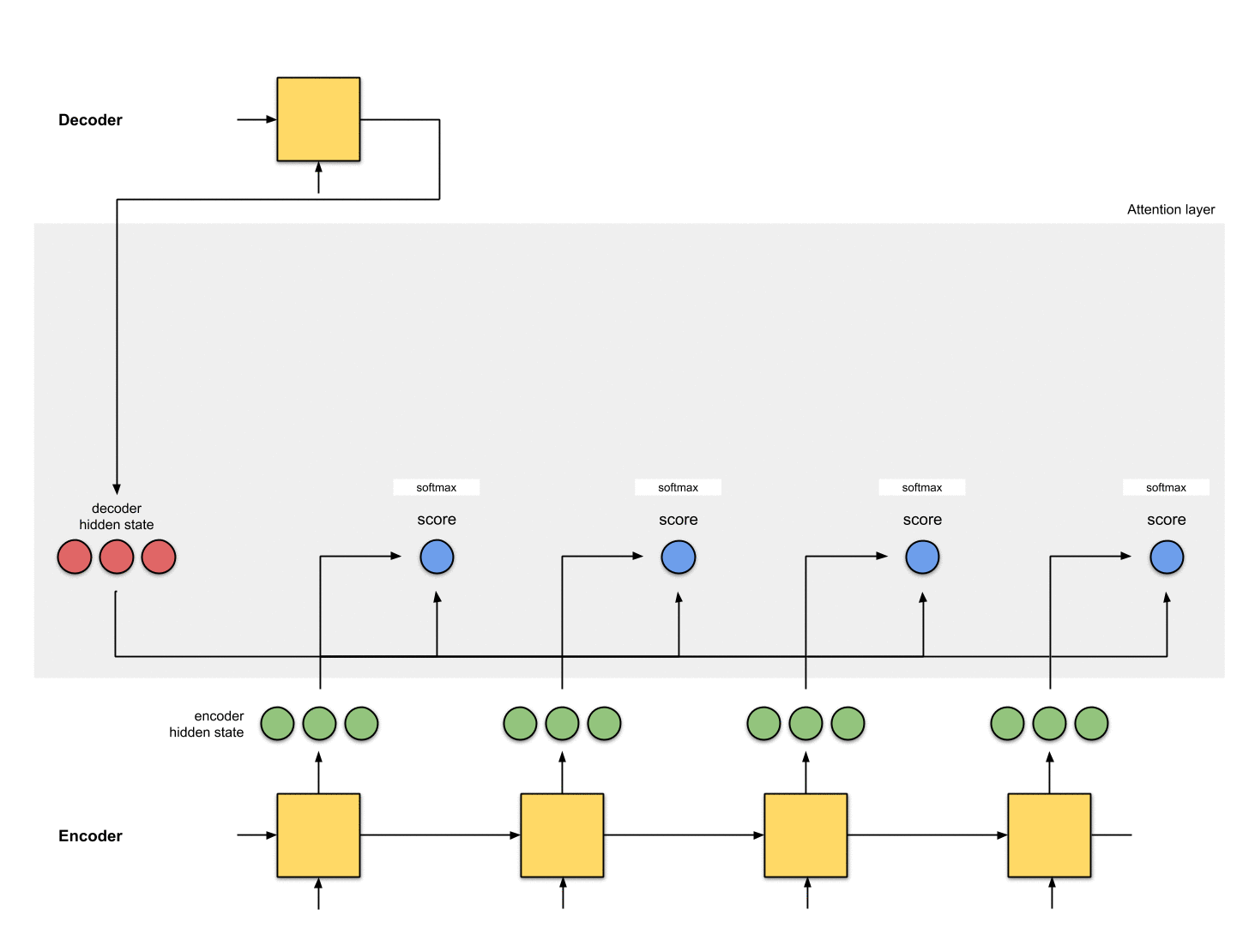
1. hidden state 준비

첫 번째 디코더 hidden state과 사용 가능한 모든 인코더 hidden state 를 준비합시다.
이 예제에서는 4개의 인코더 hidden state와 현재 디코더 hidden state가 있습니다.
2. 모든 인코더 hidden state의 점수 얻기
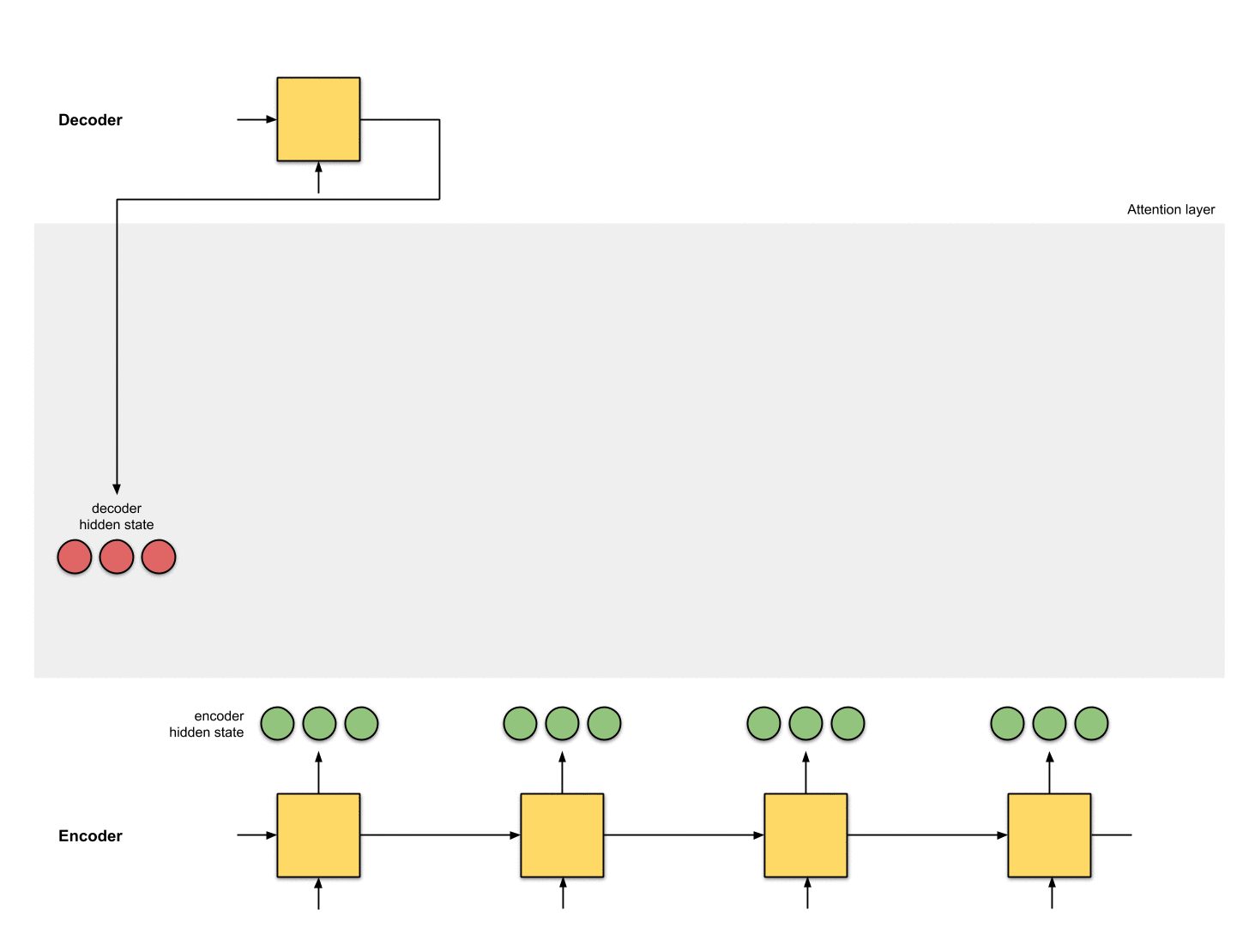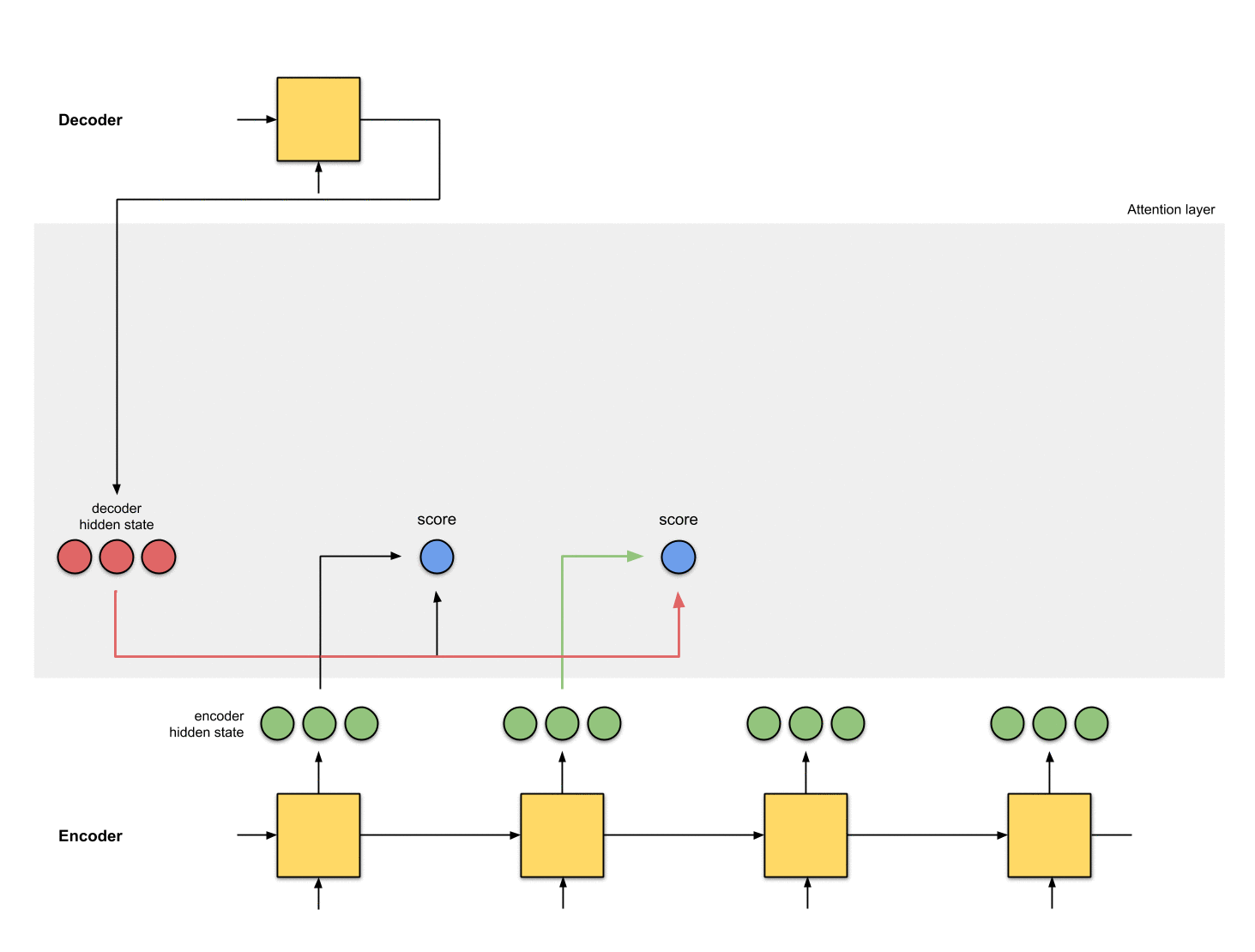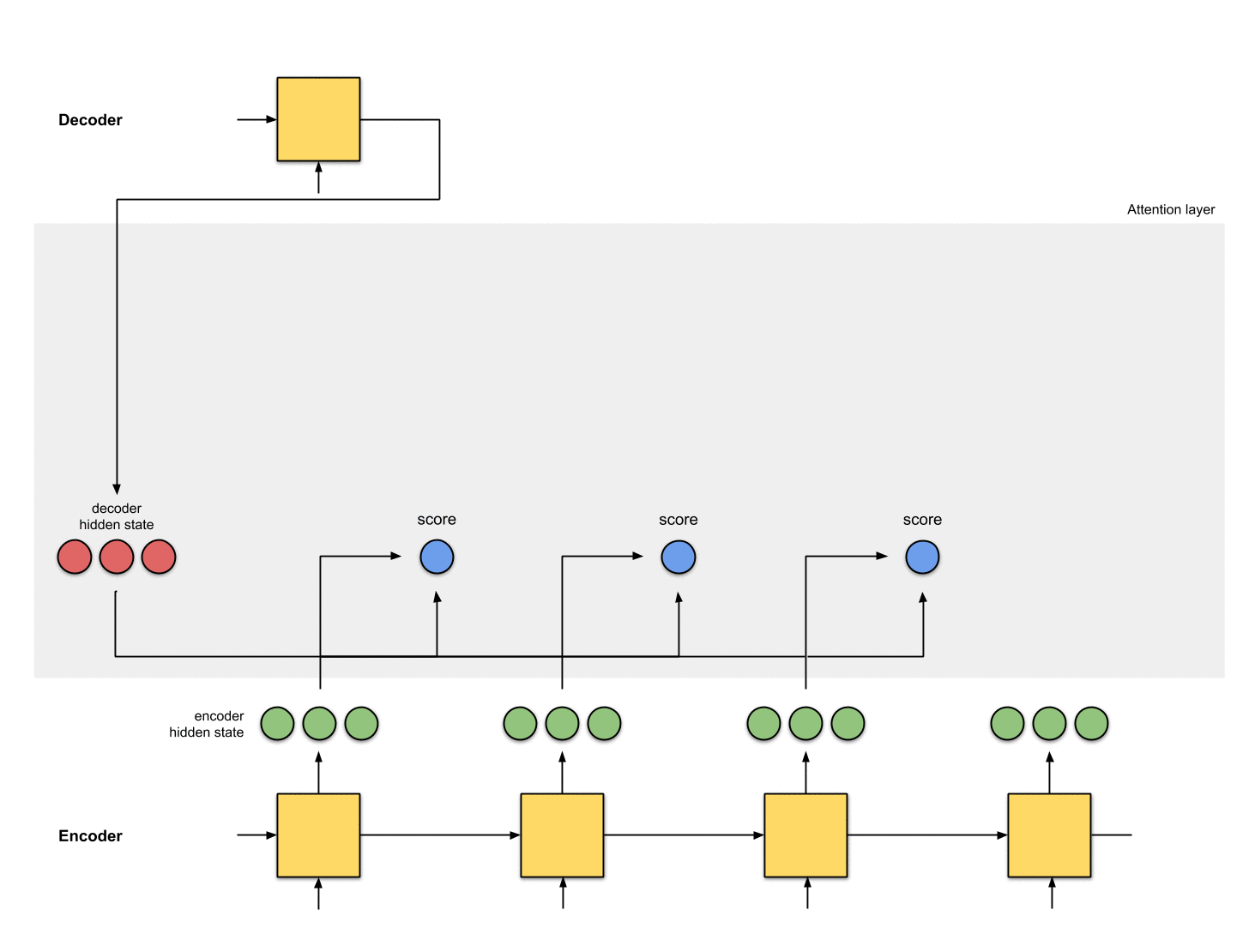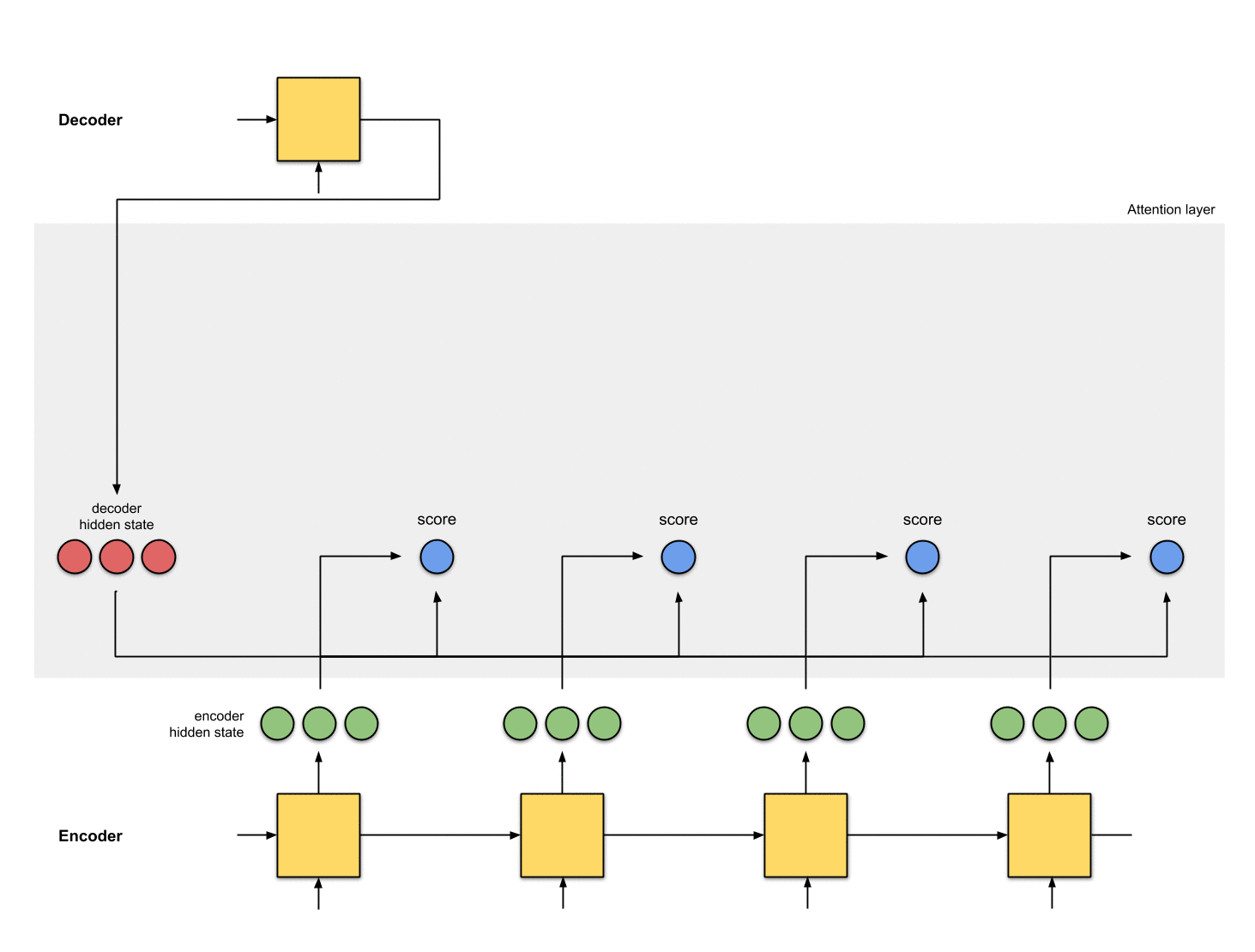
Score(스칼라)는 평가 함수에 의해 얻어집니다.
이 예제에서, 평가 함수는 디코더와 인코더 hidden state 사이의 내적입니다.
[일반적인 attention 설명을 위해 내적을 사용했을 뿐,
Bahdanau attention에서 실제 평가 함수는 아래와 같이 특정 벡터 공간으로 매핑된 두 Hidden State의 합을 사용]
3. 모든 점수를 softmax 레이어를 통해 실행
Score(스칼라)가 0 ~ 1이 되도록 softmax 층에 점수를 둡니다.
[모든 softmax를 더하면 1]
이 softmax 점수는 attention 분포를 나타냅니다.
4. 각 인코더 hidden state에 softmax 점수 곱하기
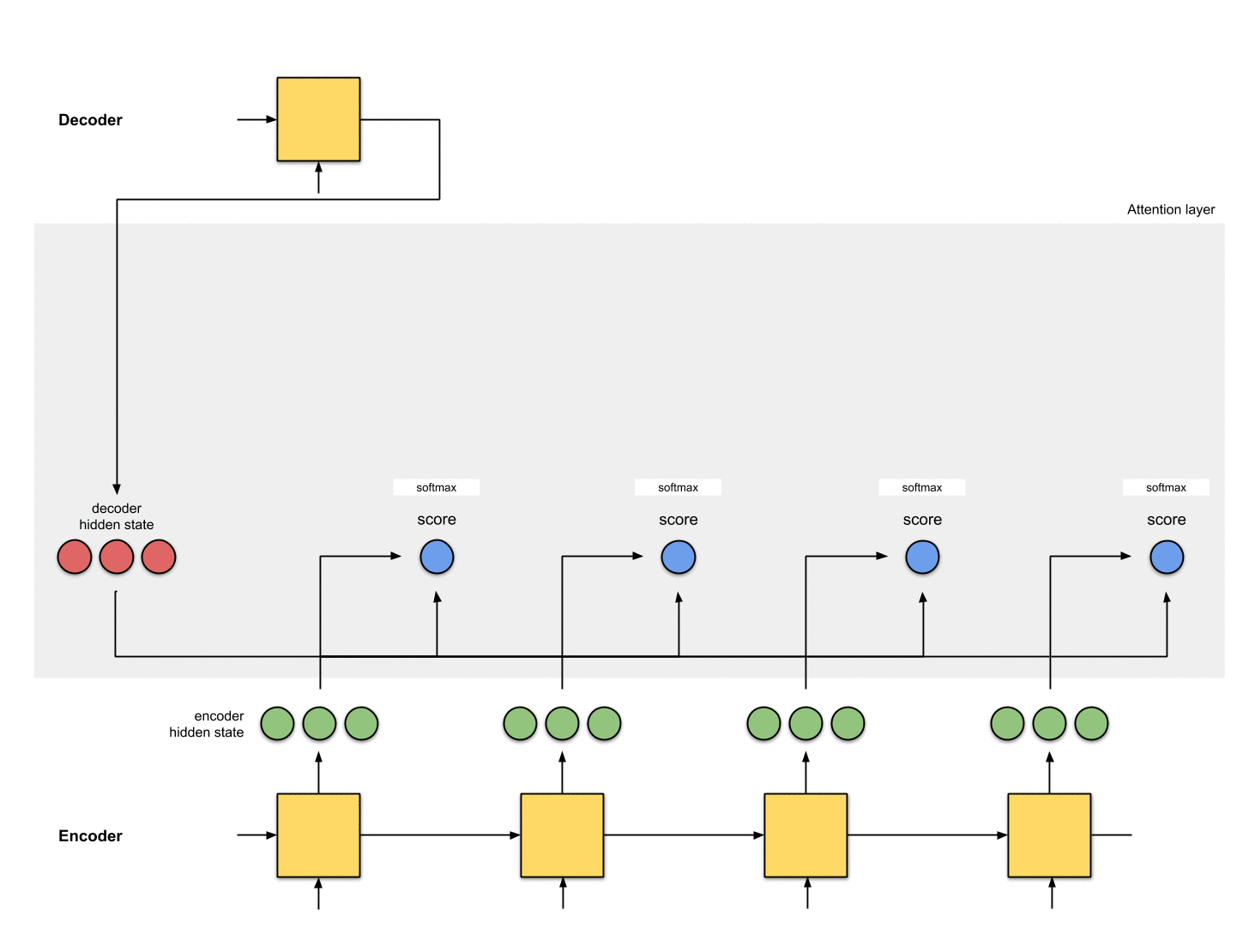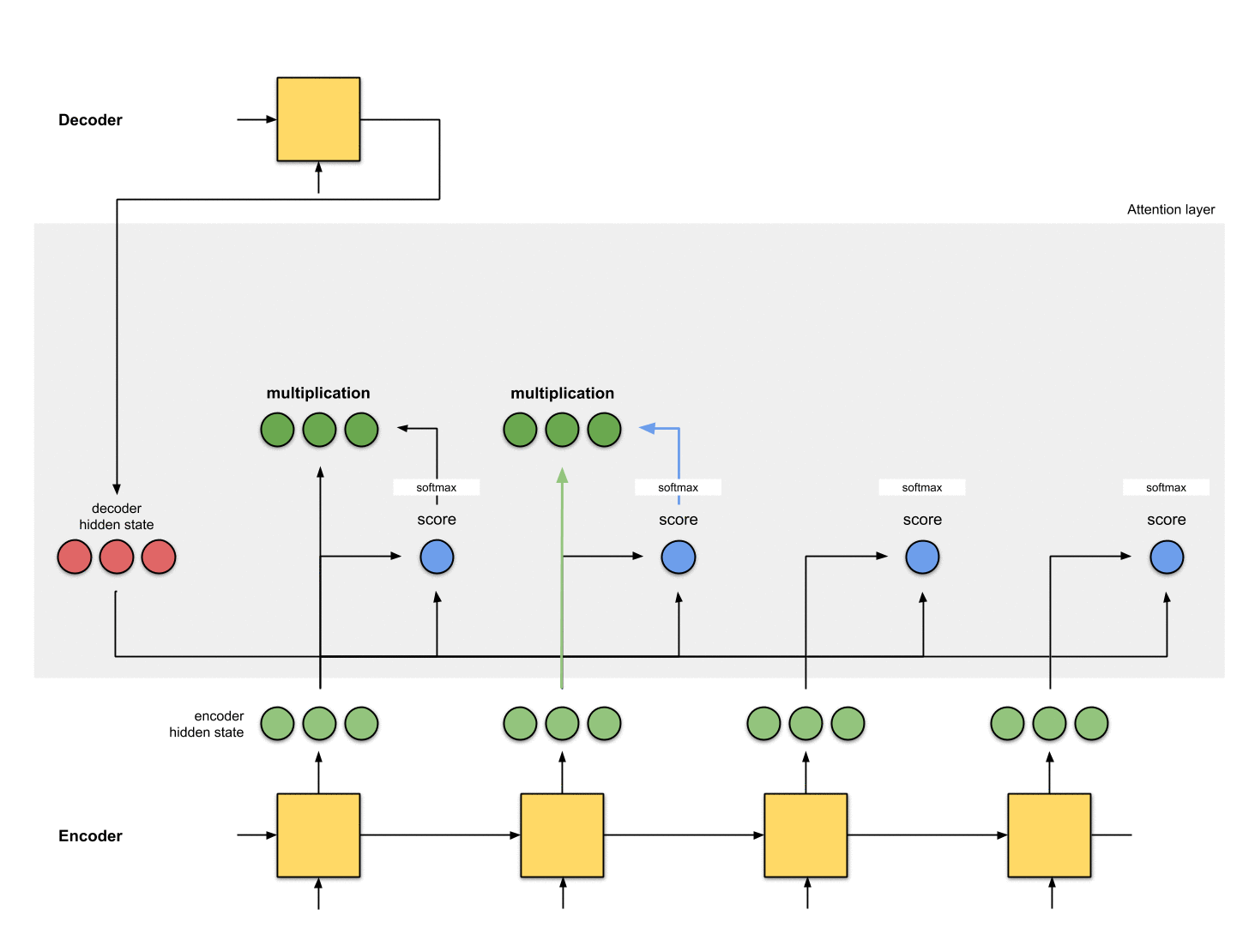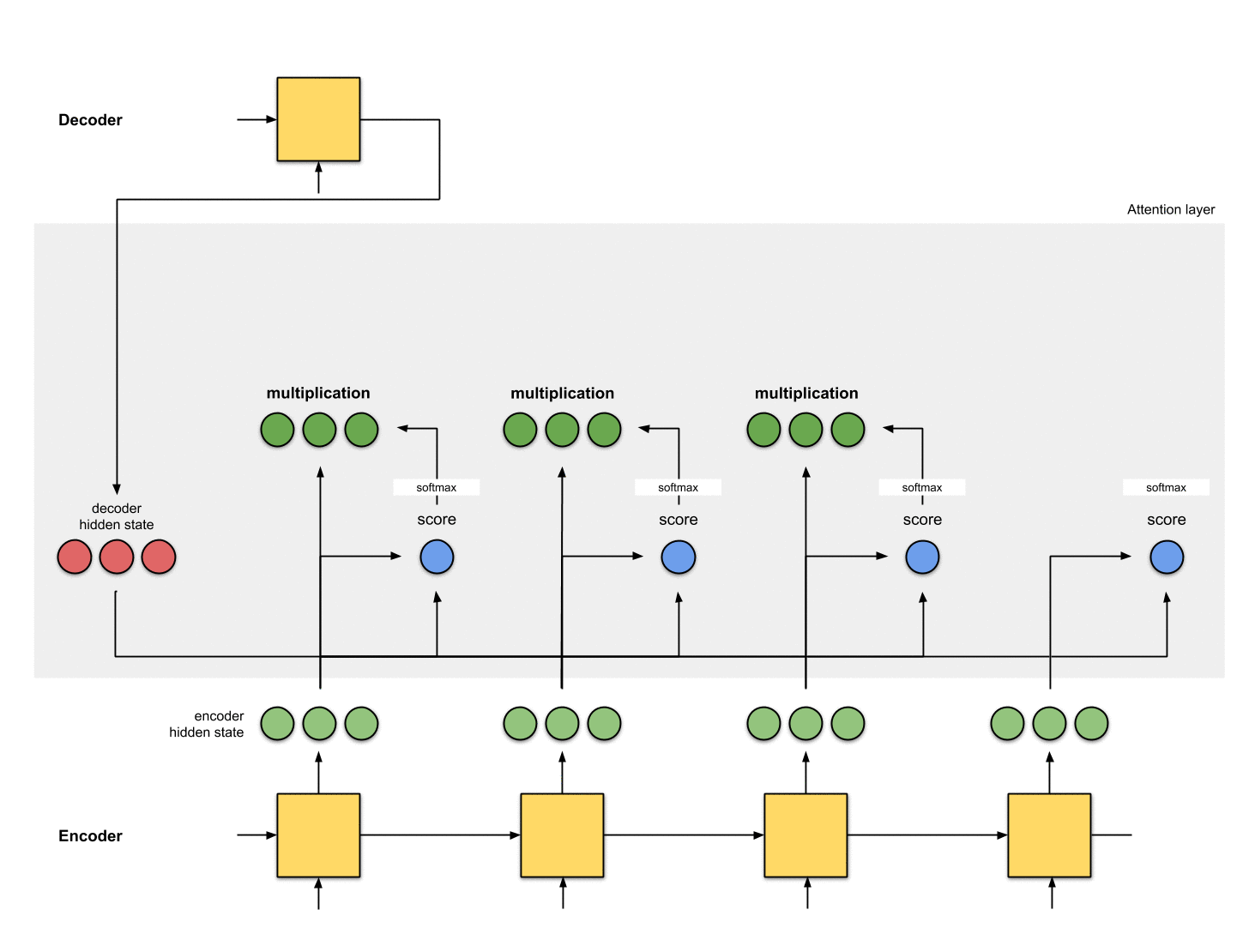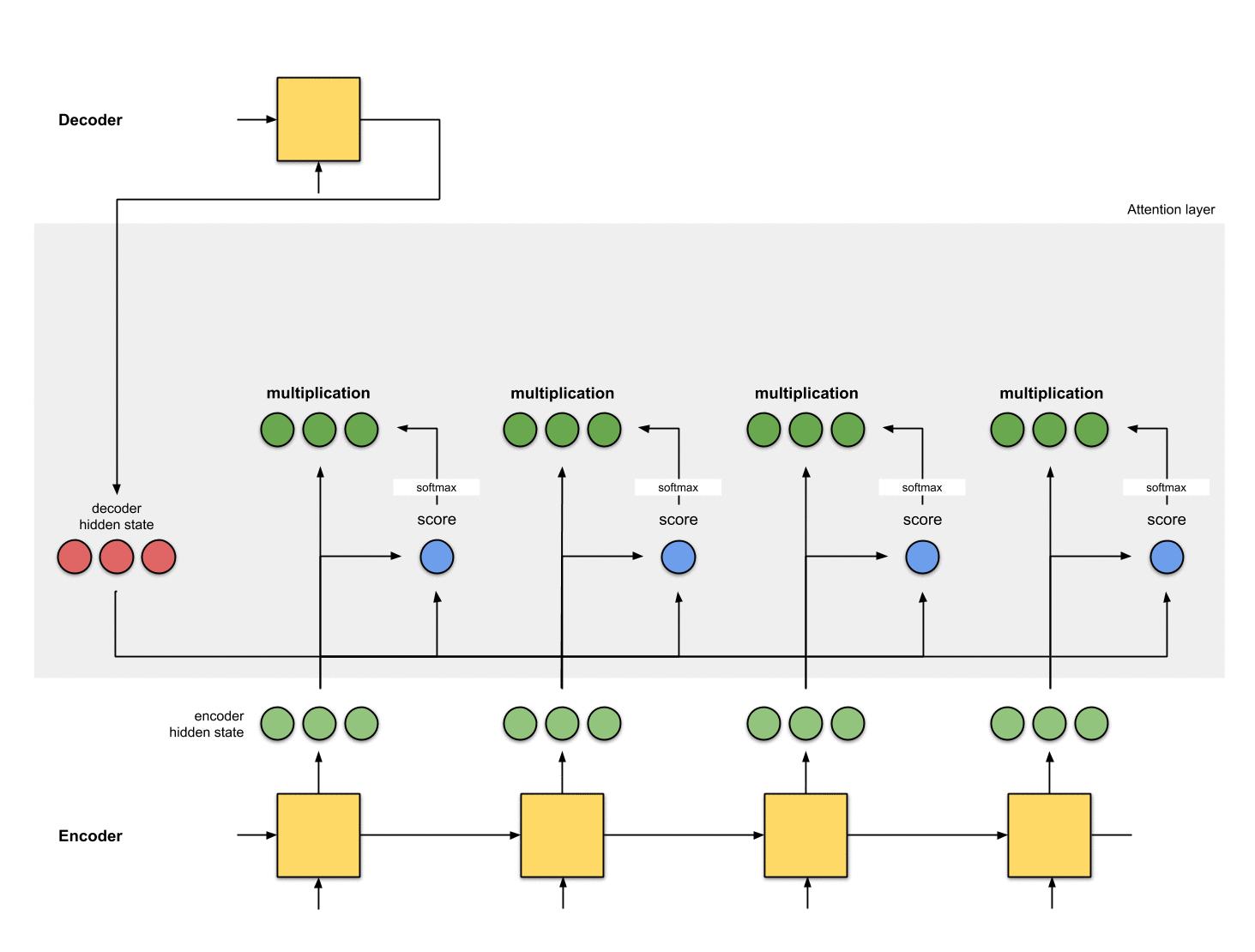
각 인코더 hidden state에 softmax score(스칼라)를 곱하여
얼라이먼트 벡터 또는 annotation 벡터을 얻습니다.
이것은 attention이 이루어지는 메커니즘입니다.
( annotation : Encoder의 hidden state를 의미)
5. 얼라이먼트 벡터를 합하기
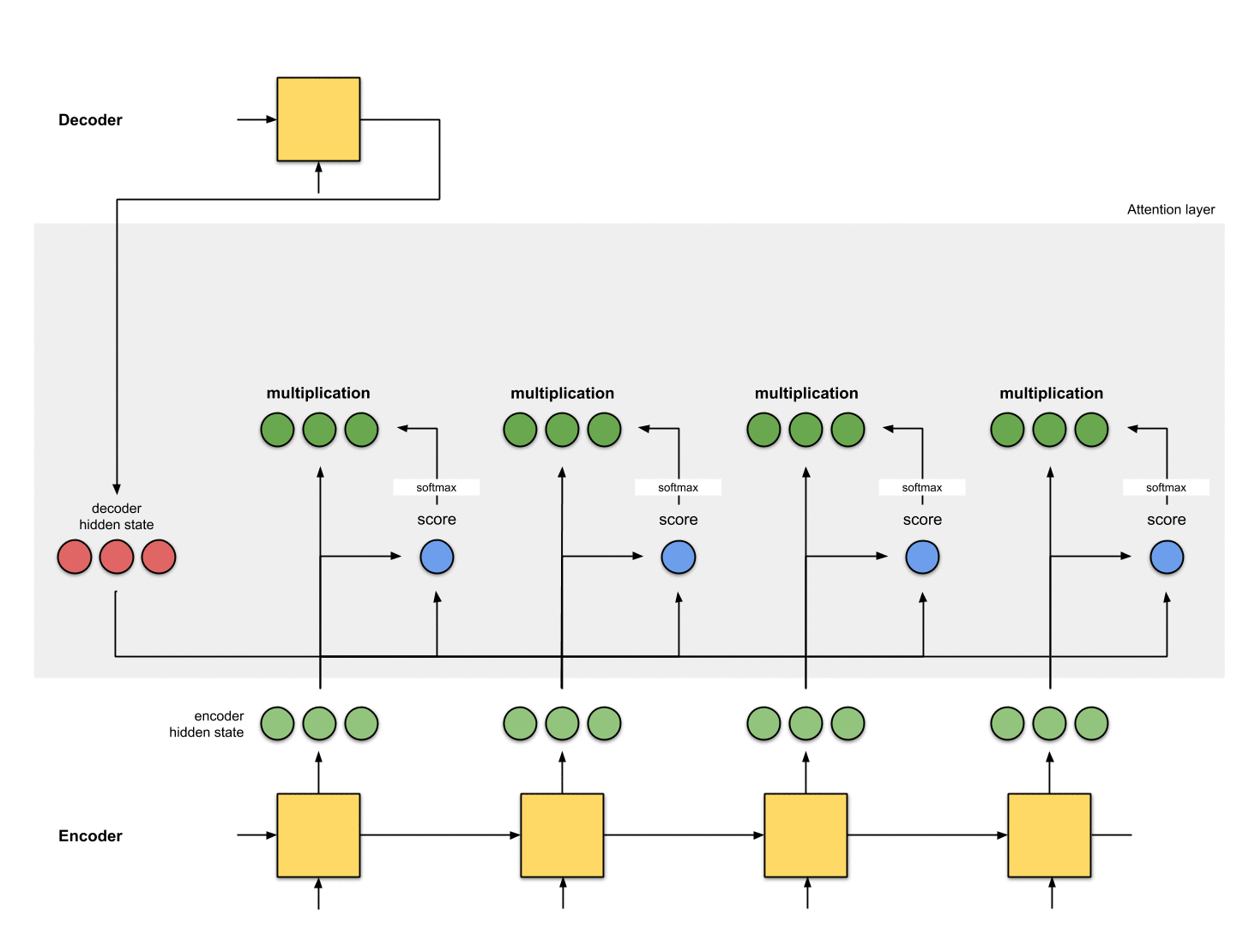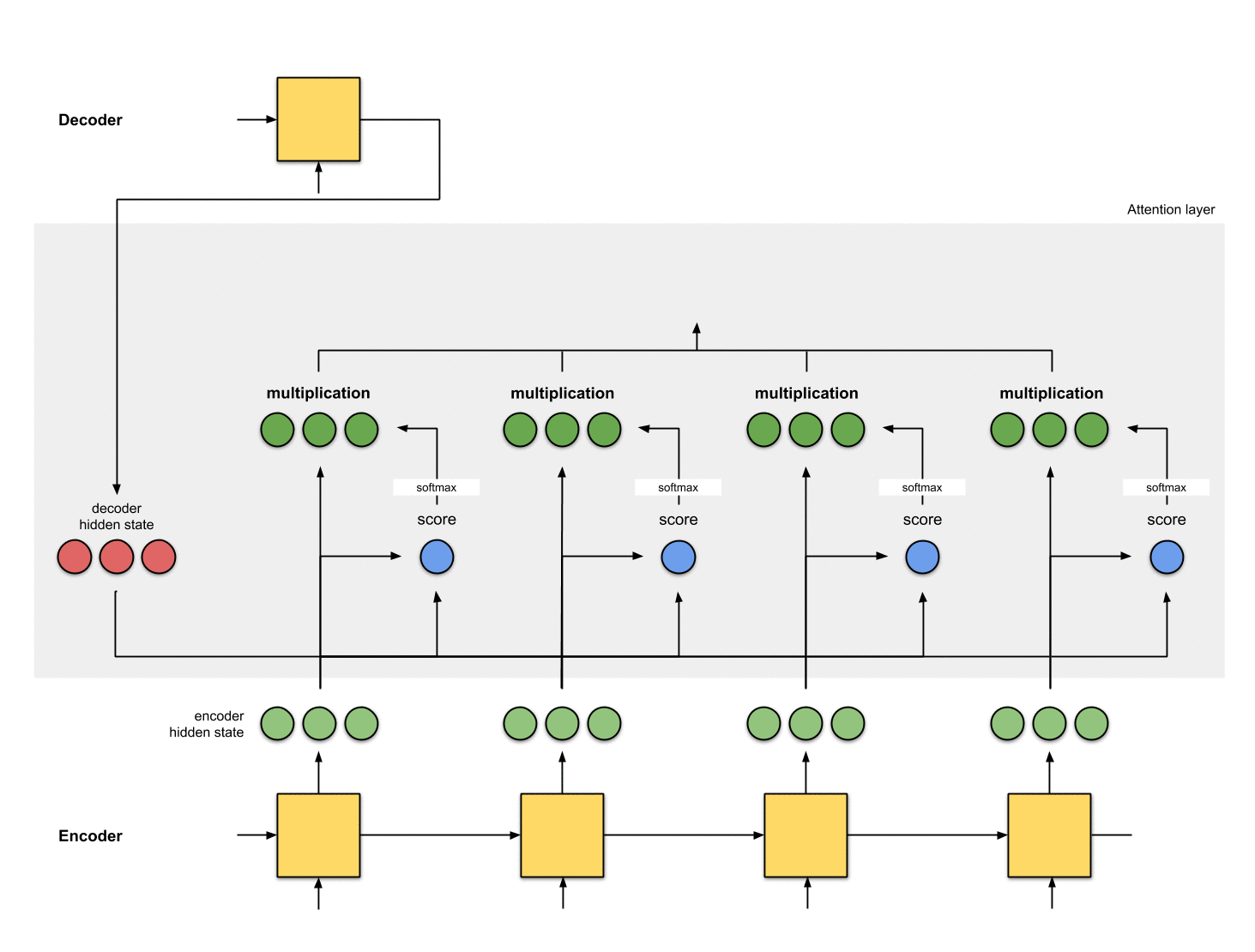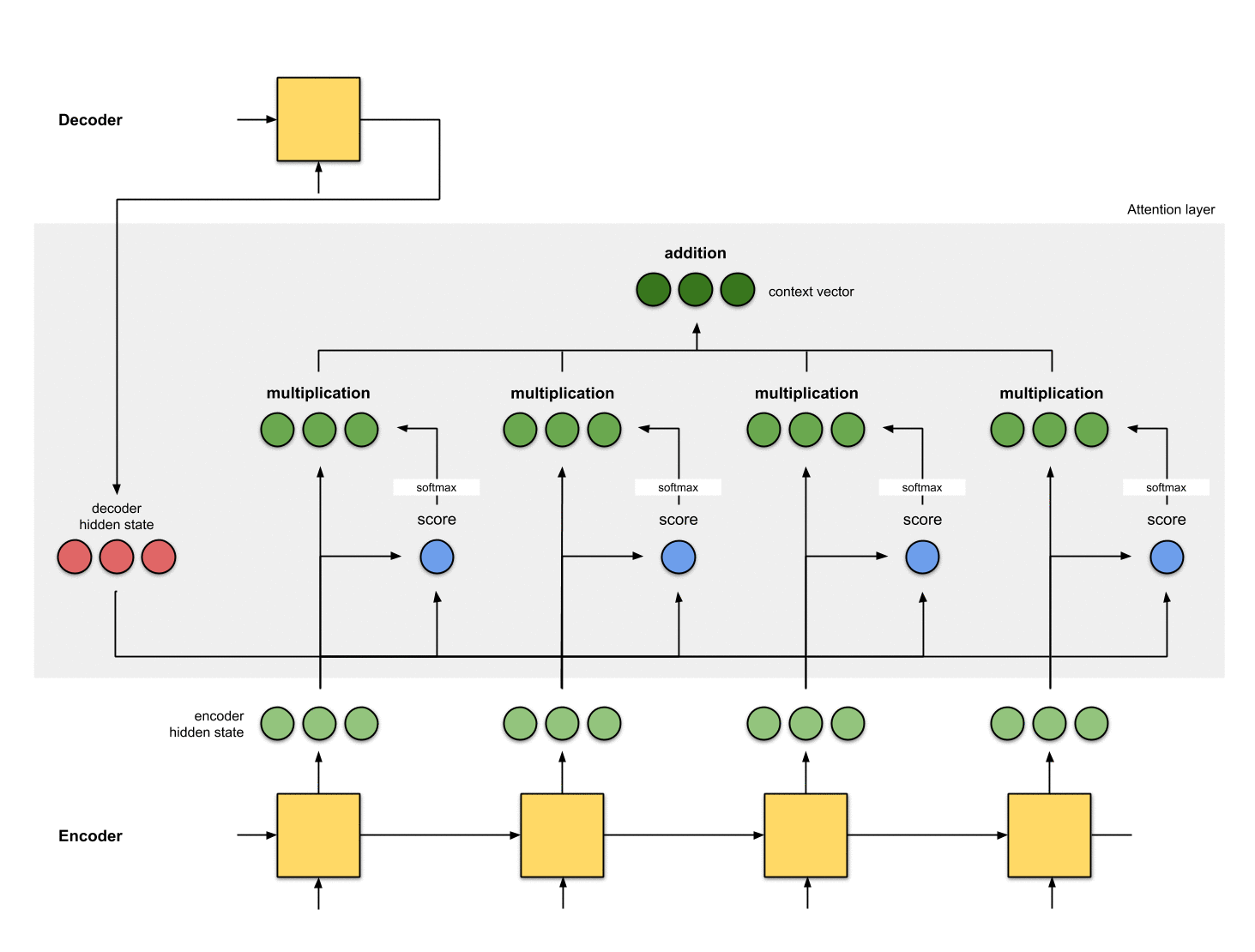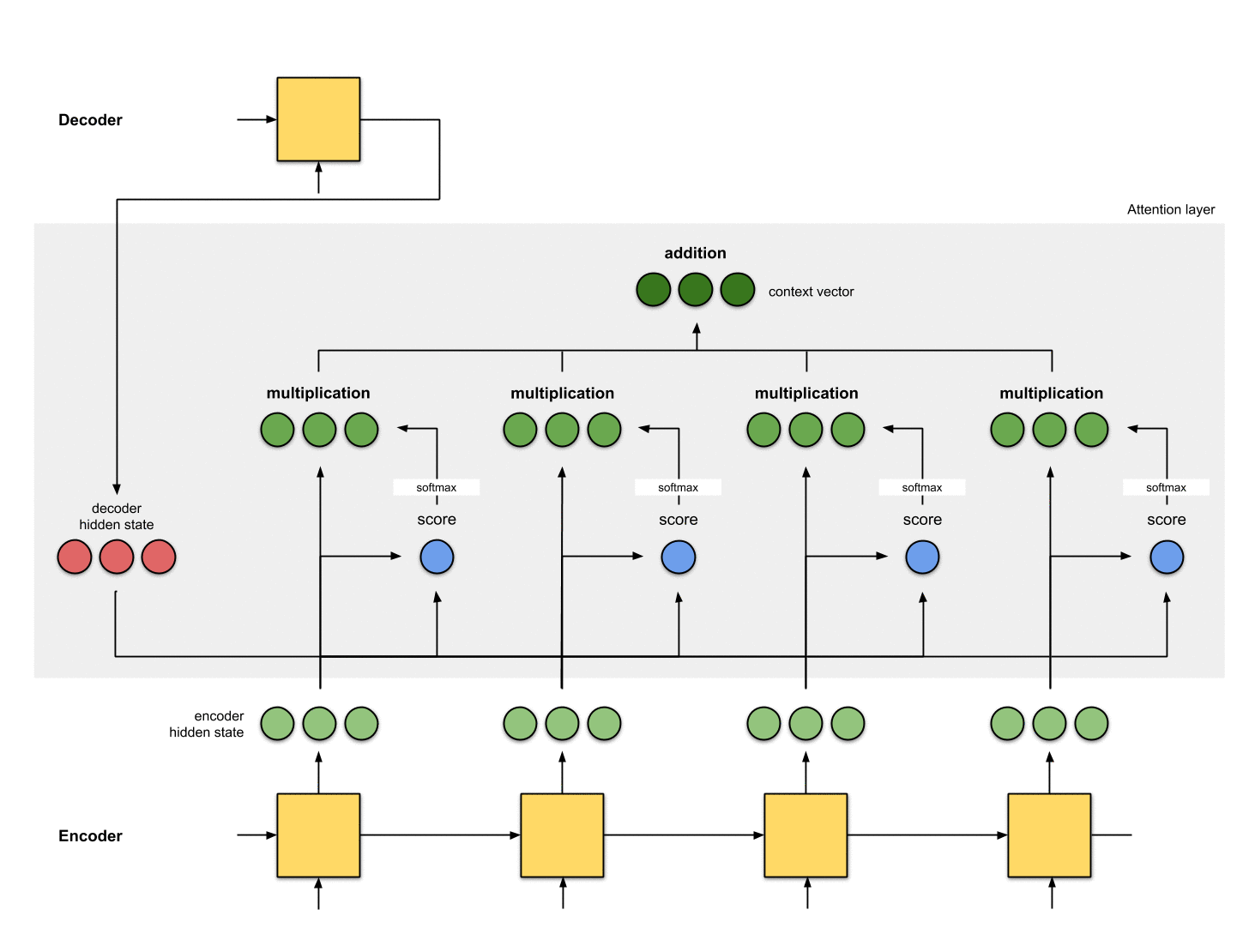
얼라이먼트 벡터는 합쳐져 context 벡터를 생성합니다.
[context 벡터는 이전 단계의 얼라이먼트 벡터에 대한 집계 정보]
6. context 벡터를 디코더에 전달
7. 전체 애니메이션

구글링 도중 어텐션 매커니즘을 잘 도식화한 이미지를 찾게되어 참고 자료로 첨부하겠다.
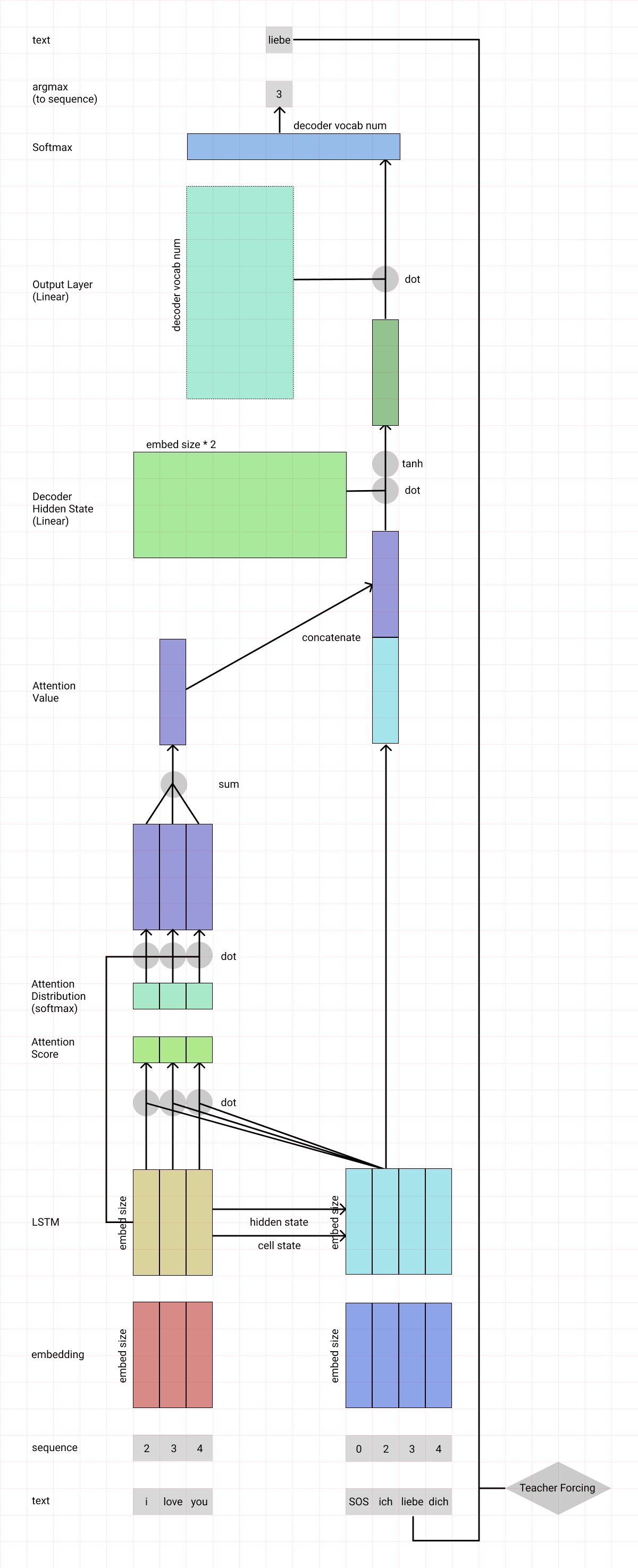
[출처]https://luna-b.tistory.com/29 (B급 개발님 블로그)
