Recurrent Neural Networks(RNN)에 대한 이해를 돕기위해 작성하였습니다.
RNN이란?
RNN은 시퀀스 데이터 처리에 강점을 가진 신경망 입니다.
[시퀀스 데이터란? | 순서를 가진 데이터라고 볼 수 있으며 대표적으로는 시계열 데이터 / 자연어 처리가 있습니다.]
시계열에서는 일수 별로 특정 시점들이 순서를 가지는 것이고,
자연어 처리에서는 'I love you'와 같은 문장에서 각 단어들이 연결된 시퀀스로 볼 수 있는 것 입니다.
RNN의 구조
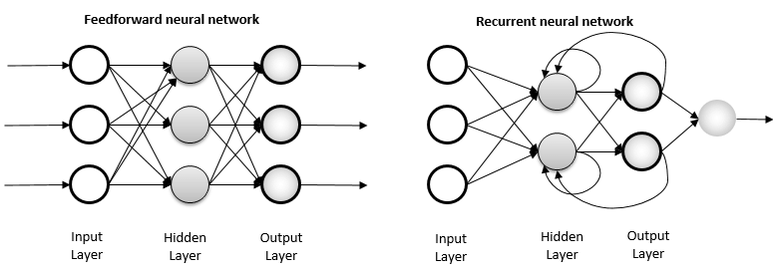
RNN은 오직 은닉층에서 활성화 함수를 지난 값이 출력층의 방향으로만 이동하는 피드 포워드 신경망과는 다르게
은닉층에서 활성화 함수를 지난 값이 출력층의 방향으로도 이동하지만 더불어 다시 은닉층의 노드의 다음 계산의 입력으로 보내는 특징이 있습니다.
해당 그림을 간단하게 표현하면 아래와 같습니다
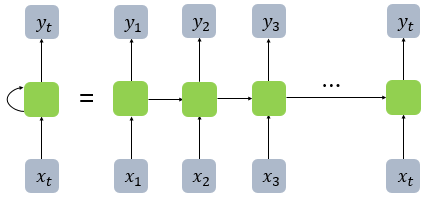
결국 RNN은 전 시점(t-1)의 어떤 정보를 다음 시점(t)으로 넘겨준다고 볼 수 있습니다.
다음 시점(t)의 정보는 전 시점(t-1)의 정보만이 아니라 이전까지의 정보(t-2 + t-3 + ... + t-n)들을 모두 가지고 있을 것입니다.
그리고 이처럼 정보를 가지고 있는 것을 cell이라고 하며 현재 cell이 가지고 있는 정보, 즉 다음 시점으로 넘겨줄 정보를 hidden state라고 합니다.
다시 말하자면
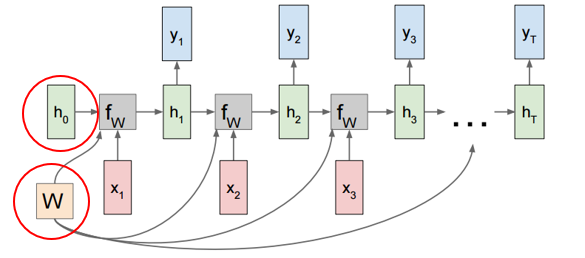
1) 전 시점의 hidden과 현 시점의 x에 함수 f()를 취하여 현 시점의 h를 구합니다.
2) 현 시점의 h로 현 시점의 y 출력값을 구합니다.
3) 다시 h를 넘겨주며 반복합니다.
하지만 주의할 점은 빨간색 동그라미의 h0, W입니다.
기본적으로 처음 시점에 대해 연산을 할 때 전 시점의 hidden state가 없기 때문에 초기 hidden state는 랜덤값을 활용합니다.
그리고 ht를 구하기 위해 ht-1에 연산할 가중치, xt에 연산할 가중치 matrix는 각 타입 스텝에서 동일하게 적용됩니다.
순전파로 loss를 구하는 과정의 이미지는 아래와 같습니다.
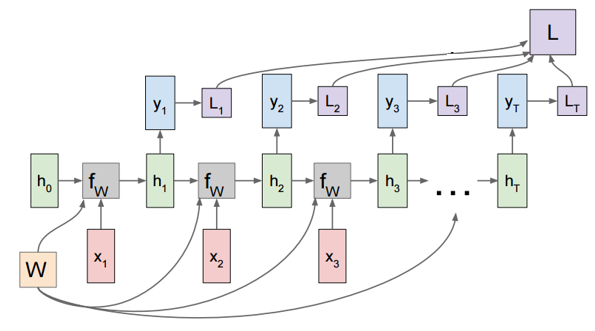
RNN BPTT(BackPropagation Through Time)
BPTT는 RNN에서 계산되는 back propagation으로
sequential data의 특성으로 인해 발생하는 hidden state를 따라 역행하면서 전파되는 gradient의 계산 방법입니다.
Back Propagation Through Time는 사실 따지고 보면 단순한 역전파 계산과 동일하다고 볼 수 있습니다.
다만, RNN 구조상 이전의 값(hidden state)를 참고하기 때문에
역전파를 진행할 때도 현재 시간 단계만을 고려하는 것이 아닌 이전의 시간 단계까지 모두 고려해야한다.
이러한 역전파 방식을 BPTT라고 부릅니다.
다만 이러한 과정에서 문제가 발생합니다.
Vanishing Gradients Problem 입니다.
RNN이 시간을 거슬러 올라가면서 학습을 하는데 과거로 올라가면 올라갈수록 gradient 값이 계산이 잘 되지 않습니다.
그 이유는 gradient 계산이 곱셈 연산으로 이루어져 있기 때문입니다.
1보다 큰 값들을 계속해서 곱하면 발산하겠지만
1보다 작은 값들을 계속해서 곱하면 0으로 수렴해 사라져 버립니다.
gradient가 사라져 버리는 것은 의미있는 값을 전달할 수 없다는 것이므로 문제가 됩니다.

이러한 문제점을 해결하기 위해 등장한 것이 LSTM / GRU 모델 입니다.
해당 모델에 대한 포스팅은 다음에 정리하도록 하겠습니다.
