CoMPM: Context Modeling with Speaker’s Pre-trained Memory Tracking for Emotion Recognition in Conversation(2022) 논문 읽기①
0. Abstract
대화형 기계의 사용이 증가함에 따라 대화에서 감정 인식(ERC) 작업이 더욱 중요해졌다.
기계가 만들어낸 문장들이 감정을 반영한다면 더 인간다운 공감 대화가 가능할 것이다.
이전 발화를 고려하지 않을 경우 감정 인식이 부정확하기 때문에 많은 연구들은 대화의 맥락을 반영하여 성능을 향상시키고 있다.
최근의 많은 접근 방식은 외부 구조화된 데이터에서 학습한 모듈에 지식을 결합하여 성능 향상을 보여주고 있다.
그러나 구조화된 데이터는 영어가 아닌 언어로 접근하기 어려워 다른 언어로 확장하기가 어렵다.
따라서, 우리는 pre-trained language model을 외부적인 지식를 뽑아내는 것으로 사용하여 pre-trained memory를 추출한다.
우리는 화자의 pre-trained memory와 Context model을 결합한 CoMPM을 소개하고, pre-trained memory가 Context model의 성능을 크게 향상시킨다는 것을 발견했다.
CoMPM은 모든 데이터에서 첫 번째 또는 두 번째 성능을 달성하며 구조화된 데이터를 활용하지 않는 시스템 중에서 SOTA 성능을 보인다.
또한, 우리의 방법은 이전 방법과 달리 구조화된 지식이 필요하지 않기 때문에 다른 언어로 확장될 수 있음을 보여준다.
1. Introduction
최근 많은 사용자들이 사용하는 대화형 챗봇이나 소셜 미디어와 같은 애플리케이션의 수가 급격히 증가함에 따라 자연어 처리에서 ERC(Emotion Recognition in Conversation)가 더욱 중요한 역할을 하고 있으며, 많은 연구가 이루어지고 있다.
ERC 모듈은 대화의 질을 높이고 사용자에게 맞춤형 푸시 메시지를 보낼 때 활용할 수 있다.
또한 감정인식은 개인화된 결과를 제공함으로써 서비스 품질을 향상시킬 수 있는 opinion mining, recommender systems(추천 시스템), healthcare systems(헬스케어 시스템) 등에 효과적으로 활용될 수 있다.
이러한 대화형 기계가 증가함에 따라 ERC 모듈은 점점 더 중요한 역할을 한다.
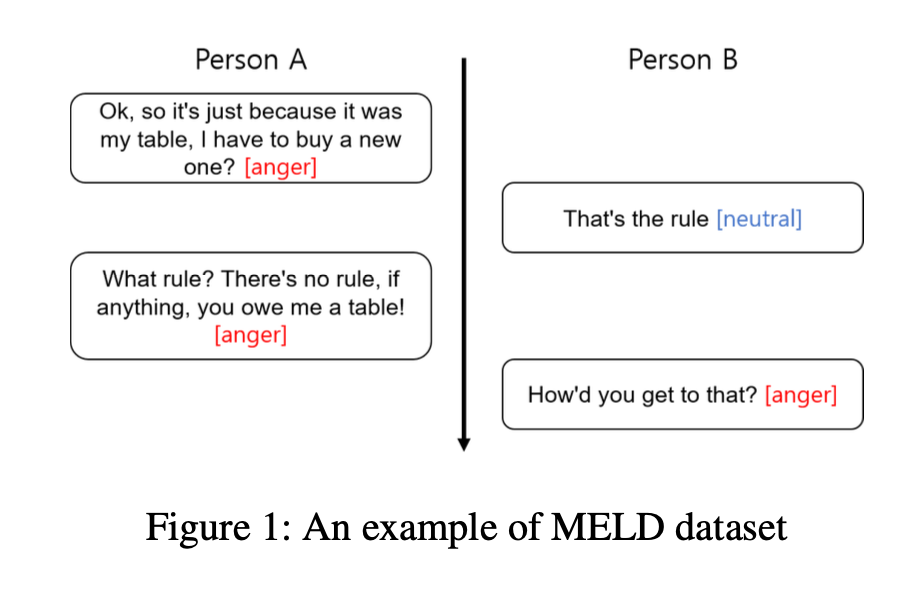
위 그림은 두 화자가 서로에게 화난 감정을 가지고 있는 경우의 대화이다.
화자B의 발언 ("How’d you get to that?")의 감정은 화가 나있는 감정이다.
이전 발언을 고려하지 않았다면 감정을 제대로 인식하기 어렵다.
이전 발화를 고려하지 않은 발화 수준의 감정 인식은 한계가 있고 실험 결과 성능이 저하된다는 것을 보여준다.
따라서, 최근의 연구들은 이전의 발언들을 고려하면서 감정을 인식하려고 시도하고 있다. 대표적으로 DialogueRNN은 이전 발언의 맥락과 화자의 감정을 추적하여 현재의 감정을 인식하고 있으며, AGHMN은 GRU를 사용한 메모리 요약을 통해 이전 발언을 주의 깊게 고려하고 있다.
최근의 많은 연구는 ERC의 성능을 향상시키기 위해 external knowledge(외부 지식)을 사용했다.
그러나 외부 지식은 종종 영어로만 이용할 수 있었다.
기존의 방법을 다른 나라의 언어로 활용하기 위해서는 external knowledge data를 새롭게 구축해야 하기 때문에 비용이 많이 들고 활용이 어려웠다.
사전 훈련된 언어 모델은 unsupervised learning에 의해 훈련되기 때문에, 이러한 모델은 언어 유형에 관계없이 비교적 유용한 접근법이다.
Petroni et al.(2019)은 이러한 언어 모델이 지식 기반으로 사용될 수 있으며 구조화된 지식 기반에 비해 많은 이점을 가지고 있다고 소개한다.
이러한 연구를 바탕으로 구조화된 외부 데이터에 대한 의존성을 없애고 pre-trained language model을 지식을 추출하는 feature로 사용한다.
본 논문에서 소개된 CoMPM은 대화에서 이전 발화를 고려하는 2개의 모듈로 구성이 된다.
(1) 첫 번째는 모든 이전 발언을 Context로 반영하는 Context Embedding Module(CoM)이다.
CoM은 대화의 이전 발언과 현재 발언 사이에서 Attention을 통해 현재의 감정을 예측하는 auto-regressive model(자동 회귀 모델)이다.
(2) 두 번째는 발화에서 Memory를 추출하는 pre-trained memory module(PM) 이다.
pre-trained language model의 Output을 언어 모델로 전달되는 Memory Embedding으로 사용한다.
이는 화자의 언어적 선호와 특성을 고려하여 화자의 감정을 예측하는 데 도움을 준다.
본 논문에서는 다자간 데이터 세트인 MELD, EmoryNLP, 이진 데이터 세트인IEMOCAP, DailyDialog 4개의 다른 영어 ERC Dataset에 대해서 실험한다.
CoMPM은 이전의 모든 시스템과 비교하여 첫 번째 또는 두 번째 성능을 달성하였다.
추가 실험의 경우 본 논문의 접근 방식이 다른 언어에서도 사용될 수 있으며 데이터 수가 제한될 때에도 CoMPM의 성능을 보여준다.
2. Related Work
최근의 많은 연구는 ERC 성능을 향상시키기 위해 외부 지식을 사용한다.
KET는 labeled edges를 사용하여 자연어로 된 단어와 구문을 연결하는 지식 그래프인 ConceptNet과 감성 어휘인 NRC_VAD를 commonsense knowledge(상식적 지식)를 기반한 외부 지식으로 사용했다.
COSMIC과 Psychological은 이전 발언에 대한 commonsense knowledge을 추출하여 감정 인식 성능을 향상시켰고, commonsense knowledge는 텍스트로 표현된 if-then 형식의 commonsense knowledge로 9개의 문장 관계 유형을 가지고 있는 ATOMIC으로 훈련된 COMET을 통해 추출되고 활용하였다.
ToDKAT는 COMET을 이용한 commonsense knowledge와 VHRED를 이용한 topic discovery를 모델에 결합하여 성능을 향상시켰다.
Ekman은 인간의 얼굴 표정으로부터 6가지 공통 감정(기쁨, 슬픔, 두려움, 분노, 놀라움, 혐오)의 분류법을 구성하며, multiple emotions recognition(다중 감정 인식)을 위해서는 multi-modal view가 중요하다고 Ekman은 설명했다.
MELD 및 IEMOCAP와 같은 다중 모드 데이터는 감정 인식에 사용할 수 있는 표준 데이터 세트 중 일부이며 텍스트, 음성 및 비전 기반 데이터로 구성된다.
Datcu and Rothkrantz(2014)는 음성과 시각 정보를 이용하여 감정을 인식하였고, Alm(2005)는 텍스트 정보를 기반으로 감정을 인식하려고 시도했다.
MELD와 ICON은 multi-modal information를 많이 사용할수록 성능이 향상되고 텍스트 정보가 가장 중요한 역할을 한다는 것을 보여준다.
multi-modal information는 대부분의 소셜 미디어, 특히 텍스트 기반 시스템으로 구성된 챗봇 시스템에서는 제공되지는 않는다.
본 논문에서는 신경망을 이용한 text-based emotion recognition system을 설계하고 도입하고자 한다.
3. Approach
3-1. Problem Statement
대화에서 M개의 순차 발화는 로 주어진다. 는 화자가 내뱉은 말, 는 대화 참가자 중 하나이다.
와 는 동일한 화자일 수 있지만, 고유한 대화 참가자의 수는 최소 2명 이상이어야 한다.
ERC는 이전 발화 이 주어졌을 때 t번째 턴의 발화인 의 감정을 예측하는 작업이다.
감정은 데이터 세트에 따라 미리 정의된 클래스 중 하나로 분류되며, 본 논문의 실험에서는 6개 또는 7개의 이다.
또한 긍정, 부정 및 중립으로 구성된 감정 레이블을 제공하는 감정 분류 데이터 세트를 실험했다.
3-2. Model Overview
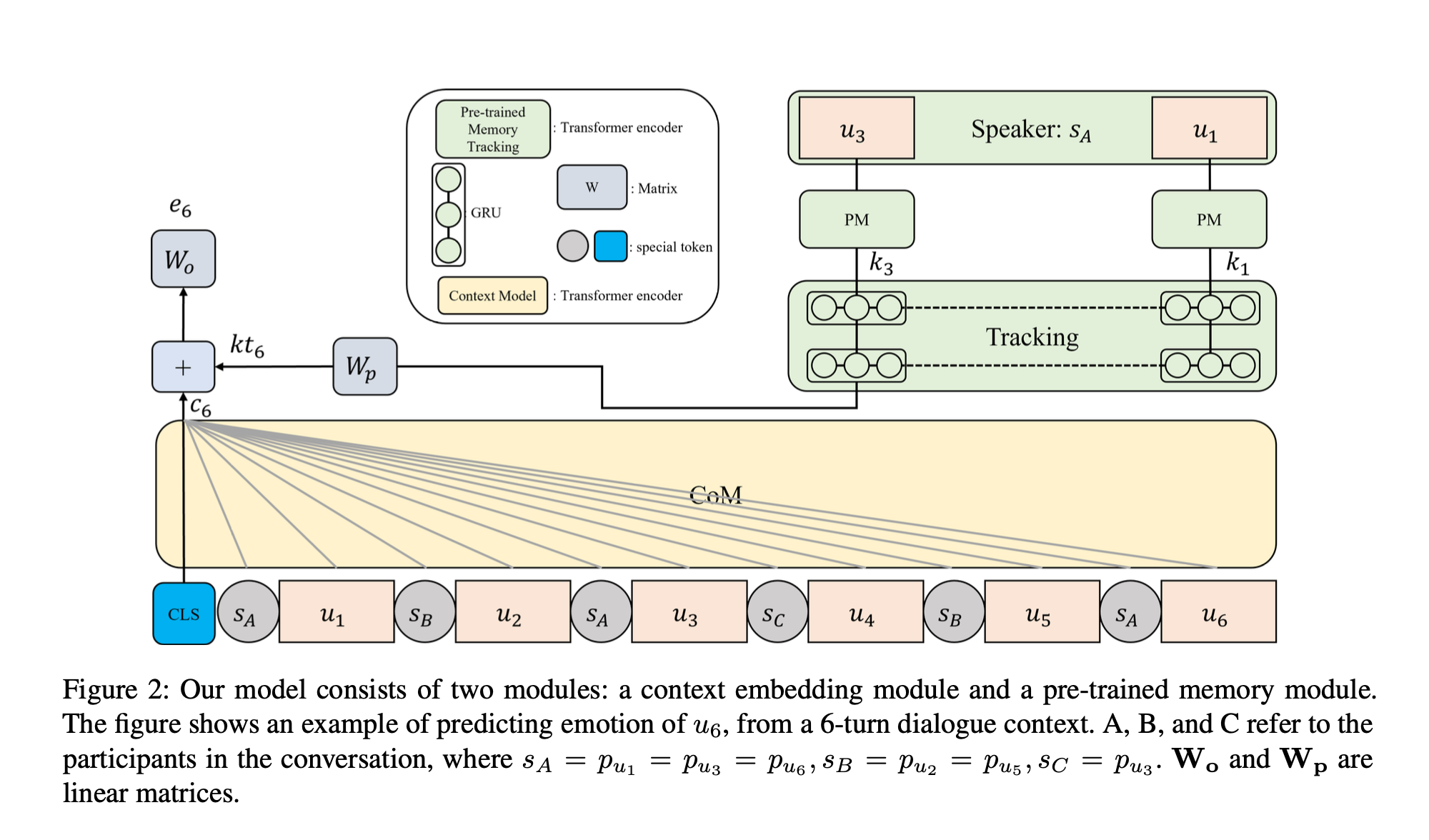
위 그림은 모델의 개요이다.
우리의 ERC 신경망 모델은 두 개의 모듈로 구성되어 있다.
첫 번째는 현재 화자의 감정에 대한 모든 이전 발언의 깔려있는 효과를 포착하는 CoM이다.
따라서 현재 발언과 이전 발언의 관계를 처리하기 위한 context model을 제안한다.
두 번째는 화자의 이전 발언만을 활용하는 PM으로, 우리는 이를 통해 화자의 지식을 반영하고자 한다.
CoM과 PM이 서로 다른 backbones을 기반으로 하는 경우, 우리는 서로의 output representations을 정렬되지 않은 것으로 간주한다.
따라서, 우리는 CoM과 PM의 output representations이 서로 이해할 수 있도록 PM이 CoM을 따르도록 설계한다.
CoM과 PM이 서로 다른 아키텍처를 기반으로 하는 경우,
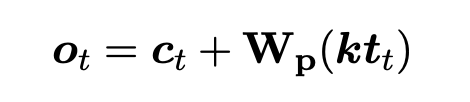
CoMPM은 위 그림의 를 사용하여 치수를 일치시킴으로써 서로의 표현을 이해하도록 훈련된다.
3-3. CoM: Context Embedding Module
CoM은 t번째 턴 전의 모든 발화를 대화 context로 고려하여 설정을 예측한다.
Figure 2는 세 명의 참가자()의 대화가 주어졌을 때 모델이 에 의해 말하는 의 감정을 어떻게 예측하는지 보여준다.
이전 발화는 이며, 와 의 관계를 고려할 때 가 예측된다.
두 명 이상의 연사가 참여하는 다자간 대화를 고려하므로, 대화의 참가자를 구별하고 화자의 종속성을 처리하기 위해 특별한 토큰 을 사용한다. 즉, 동일한 화자의 발언 앞에 동일한 특수 토큰이 나타나게 된다.
우리는 Transformer의 Encoder를 Context Model로 사용한며, label이 없는 텍스트의 large-scale open-domain corpora를 사용한 unsupervised pre-trained model인 RoBERTa를 사용한다.
본 논문에서는 감정을 예측하기 위해 특수 토큰인 <CLS>를 사용하고, <CLS>은 input의 시작 부분에 결합되며, Context Model의 Output은 아래의 식과 같다.
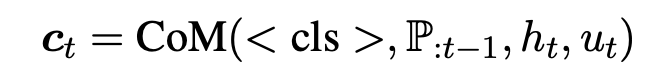
여기서 은 이전 턴 까지 화자의 집합이며, 이고, 는 CoM의 dimension이다.
3-4. PM: Pre-trained Memory Module
외부 지식은 대화를 이해하는 데 중요한 역할을 하는 것으로 알려져 있다.
Pre-trained language models은 수많은 말뭉치에서 훈련될 수 있으며 external knowledge base로 사용될 수 있다.
화자의 지식이 감정을 판단하는 데 도움이 된다는 이전 연구에서 영감을 받아 본 논문에서는 현재 발화의 감정을 활용하기 위해 화자의 이전 발화에서 pre-trained memory를 추출하고 추적한다.
화자가 현재 턴 전에 나타난 적이 없는 경우, pre-trained memory의 결과는 zero vector로 간주된다.
<CLS>는 주로 문장을 분류하는 Task에서 사용되기 때문에 본 논문에서는 아래와 같이 <CLS> 토큰의 embedding output을 발화를 나타내는 vector로 사용한다.
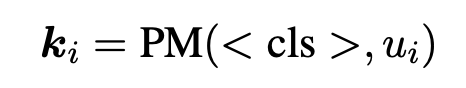
이며, S는 현재 발화의 화자이다.
이고, 는 현재 PM의 dimension이다.
3-5. CoMPM: Combination of CoM and PM
본 논문은 CoM과 PM을 결합해 화자의 감정을 예측한다.
이전 연구들의 많은 대화 시스템을 보면, 현재 발화에서 가까운 발언이 response에 중요하다고 알려져 있다. 따라서 본 논문은 현재 화자의 발언에 가까운 발언이 감정 인식에 중요할 것이라고 가정한다.
3-5-1. Tracking Method
추적 방법으로는 현재 감정에 대한 이전 화자의 모든 발언의 중요성은 동등하지 않고, 현재 화자에 거리에 따라 다르다고 가정한다.
즉, 대화의 흐름은 진행됨에 따라 달라지기 때문에 현재 발언과의 거리에 따라 감정에 미치는 영향이 달라질 수 있다는 것이다.
본 논문은 단방향 GRU를 활용해 의 순차적 위치 정보를 추적한다.
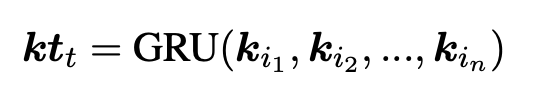
여기서 는 현재 발화의 turn index이고,
n은 이전 발화의 횟수이며, (s = 1,2,...,n)은 각각의 발화이다.
는 의 Output이므로 현재 발화로 부터 먼거리의 발화에 대한 지식이 희석이 되고 현재 발화에 대한 영향이 감소한다.
GRU는 output vector의 dimension이 인 2개의 layer로 구성 되며, Dropout은 0.3으로 설정된다.
마지막 output vector인 는 아래 식에서 와 를 더하면 얻어진다.
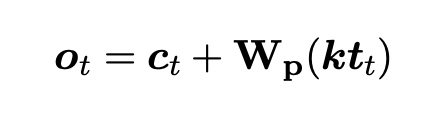
는 pre-trained memory를 context output의 dimension으로 투영하는 행렬이며, PM과 CoM이 서로 다른 pre-trained language models일 경우에만 사용 된다.
3-5-2. Emotion Prediction
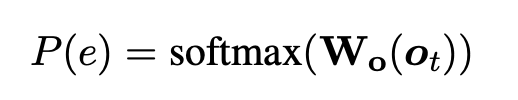
Softmax는 를 곱한 vector와 linear matrix인 에 적용되어 감정 class의 수에 따라 확률 분포를 구한다.
는 감정 클래스 분포에서 가장 큰 확률 지수에 해당하는 사전 예측 감정 클래스이다.
해당 수식의 목표는 가 실제 감정 label과 동일하도록 cross entropy loss를 최소화하는 것이다.
