CoMPM: Context Modeling with Speaker’s Pre-trained Memory Tracking for Emotion Recognition in Conversation(2022) 논문 읽기②
4. Experiments
4-1. Dataset
본 논문에서는 4가지 벤치마크 데이터셋에 대해서 실험을 진행한다.
MELD와 Emory NLP는 multi-party(다자간 대화) datasets이고, IEMOCAP과 DailyDialog는 dyadic-party(이진 대화) datasets이다.
아래의 이미지는 데이터셋의 통계이다.
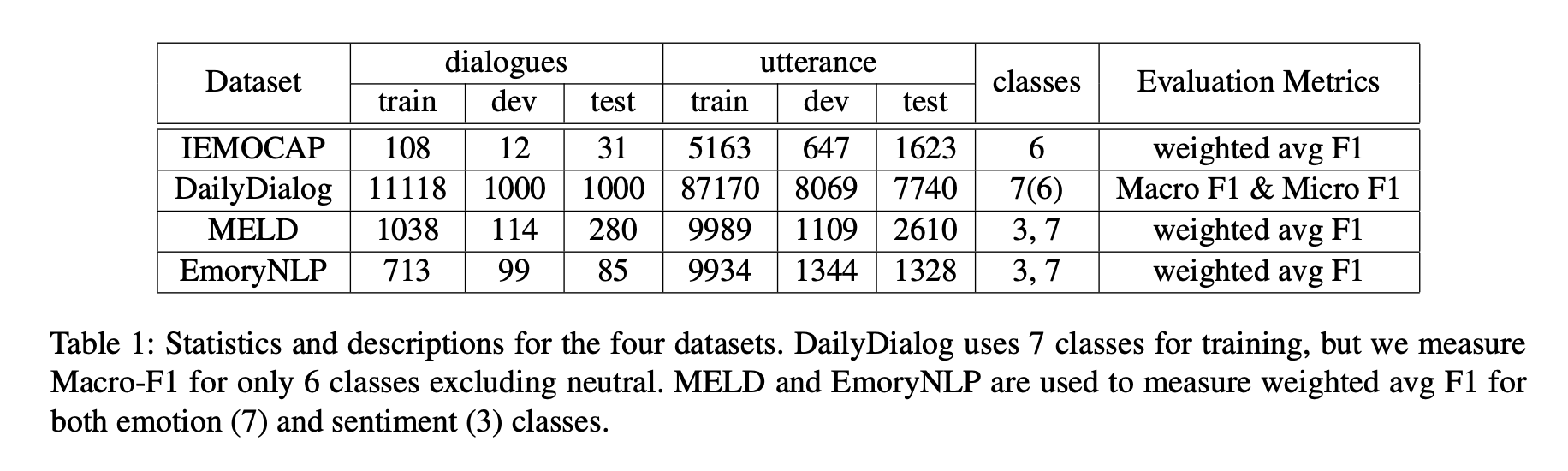
IEMOCAP는 10명의 화자가 참여하는 데이터 세트로, 각 대화에는 2명의 화자가 참여하며 "행복, 슬픔, 분노, 흥분, 좌절 및 중립"의 감정으로 구성되어 있다.
train과 dev 데이터셋은 8명의 화자가 참여하는 대화이며, 비율은 9대1이고, test 데이터셋은 나중에 2명의 화자가 참여하는 대화이다.
DailyDialog는 두 화자 사이의 일상 대화 데이터셋으로, "분노, 혐오, 두려움, 기쁨, 놀라움, 슬픔 및 중립"의 감정으로 구성되어 있다.
데이터의 82% 이상이 중립으로 태그되기 때문에 이전 연구에서 그랬던 것처럼 Micro-F1으로 평가할 때 중립 감정은 제외된다.
MELD는 Friends TV 쇼를 기반으로 하는 데이터 세트이며 감정과 정서라는 두 가지 분류법을 제공한다.
emotion-inventory은 "분노, 혐오, 슬픔, 기쁨, 놀라움, 두려움, 중립"으로, sentiment-inventory은 "긍정, 부정, 중립"으로 주어진다.
EmoryNLP도 MELD와 마찬가지로 Friends TV 쇼를 기반으로 하는 데이터 세트지만, emotion-inventory는 "즐거움, 평화, 힘, 두려움, 광기, 슬픔, 중립"으로 주어진다.
Sentiment labels은 제공되지 않으나, Sentiment classes는 positive : {즐거운, 평화로운, 강력한}, negative : {무서운, 미친, 슬픈}, neutral : {중립}으로 그룹화 할 수 있다.
4-2. Training Setup
본 논문은 hugging face library에서 pre-trained model을 사용한다.
Optimizer는 AdamW, learning_rate는 1e-5, Scheduler는 get_linear_schedule_with_warmup이며, Gradient Clipping은 최대값인 10이 사용된다.
또한 Validation set에서 최고 성능을 가진 모델을 선택한다. 모든 실험은 32GB의 메모리를 갖춘 V100 GPU에서 실험된다.
4-3. Previous Method
본 논문에소는 다양한 baseline 및 sota method를 비교하여 효과적인 접근 방식을 보여주고 있다.
KET는 hierarchical self-attention으로 contextual utterances(맥락과 관련된 발언)을 반영하고, 맥락을 인식하는 효과적인 graph attention mechanism을 사용하여 외부 commonsense knowledge를 활용하는 Knowledge Enriched Transformer이다.
DialogueRNN은 GRU 네트워크를 사용하여 대화에서 개별 당사자 상태를 추적하여 감정을 예측한다.
이 모델은 감정 예측에는 화자, 이전 발언의 맥락, 이전 발언의 감정이라는 3 가지 요소가 있다고 가정한다.
또한 다른 연구자는 pre-trained RoBERTa를 통해 Token의 vector를 추출해 RoBERTa + DialogueRNN의 성능을 보여주기도 하였다.
RGAT+P는 relational graph structure(관계형 그래프 구조)를 반영한 position encodings with sequential information을 제안하며, 화자 의존성과 sequential information를 모두 확인할 수 있음을 보여준다.
HiTrans는 Transformer기반 context 및 화자의 발언에 민감한 모델이다.
HiTrans는 BERT를 low-level의 transformer로 활용해 local utterance representations을 생성하고, 이를 high-level transformer로 넘기는 모델이다.
COSMIC은 정신 상태, 사건, 인관관계와 같은 다양한 상식 요소를 통합하여 대화 참가자간의 관계를 학습하는 모델이다. 이 모델은 pre-trained RoBERTa를 feature extractor로 활용하고, ATOMIC으로 훈련된 COMET을 commonsense knowledge로 활용한다.
ERMC-DisGCN은 대화자의 자기 화자 의존성을 관계형 컨볼루션으로, 종속적 발언의 유익한 단서를 게이트 컨볼루션으로 활용하는 담화 인식 그래프 신경망을 제안한다.
Psychological는 commonsense knowledge를 enrich edges로 사용하고 graph transformer로 처리한다. 이 모델은 과거의 맥락뿐만 아니라 미래의 맥락에서도 발언의 의도를 활용하여 감정 인식을 수행한다.
DialogueCRN은 situation-level과 speaker-level contexts를 모두 이해하는 직관적인 검색 프로세스인 추론 모듈을 도입하였다.
ToDKAT는 topic detection이 추가된 LM을 제안하고, 이를 commonsense knowledge과 결합하여 성능을 향상시킨 모델이다.
4-4. Result and Analysis
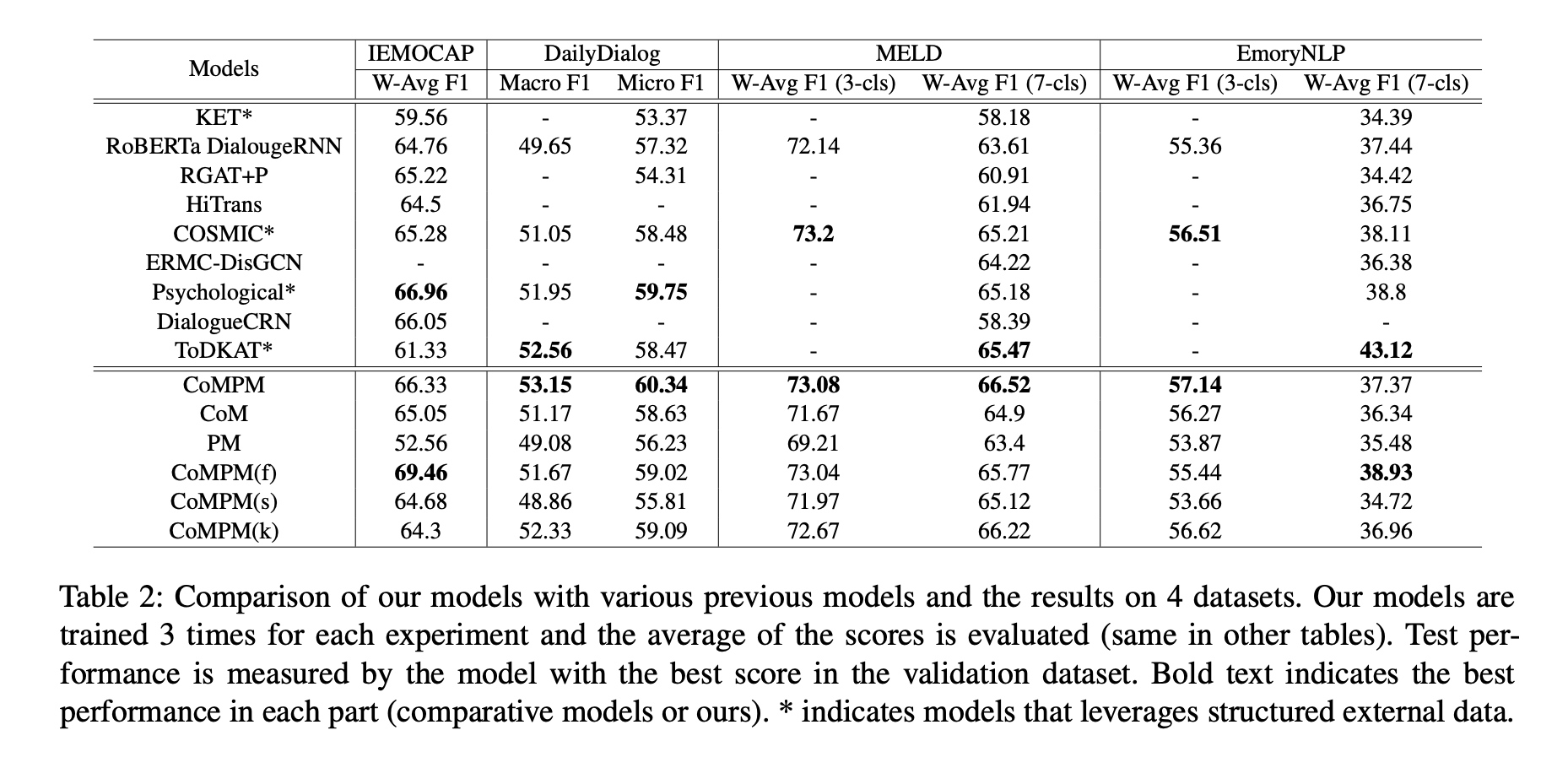
위 그림은 이전에 소개한 방법들과 우리 모델의 성능을 보여준다.
단독으로 사용되는 CoM은 PM을 활용하지 않으며 대화 맥락만 고려하여 감정을 예측하고,
단독으로 사용되는 PM은 메모리 모듈로 사용되지 않지만 동일한 backbone이 사용되고, 문맥을 고려하지 않고 현재 턴의 발화만으로 감정을 예측한다.
CoMPM은 사전 훈련된 LM의 초기 상태에서 CoM 및 PM 매개 변수가 모두 업데이트되는 모델이다.
CoMPM(f)은 PM 매개 변수가 초기 상태(사전 훈련된 LM)에서 동결되어 더 이상 훈련되지 않는 모델이며,
CoMPM(s)은 PM이 처음부터 훈련되는 모델이고,
CoMPM(k)은 PM이 ConceptNet에서 훈련되는 모델이다.
이전 연구에 이어 PM(k)의 각 토큰에 대한 평균 vector를 발화의 특징으로 사용하고 hugging face에서 제공하는 pre-trained model을 PM(k)으로 사용한다.
PM의 효과는 CoM과 CoMPM의 성능 비교를 통해 확인할 수 있으며, CoM과 PM의 결과를 비교하여 CoM의 효과를 확인할 수 있다.
PM은 context를 고려하지 않기 때문에 CoM보다 성능이 떨어졌으며, 평균 대화 턴 수가 높은 IEMOCAP 데이터 세트에서 성능 차이가 더 크다.
결과적으로 CoM과 PM의 조합이 더 나은 성능을 달성하는 데 효과적이라는 것을 보여준다.
본 논문에서는 CoMPM(s)의 성능을 통해 모델에서 PM 구조의 영향을 확인한다.
PM 매개변수가 동결되지 않고 무작위로 초기화되면 성능이 저하된다.
CoMPM(s)은 CoMPM보다 성능이 떨어지며, 심지어 MELD를 제외한 다른 데이터 세트에서 CoM보다 성능이 떨어진다.
즉, 매개 변수가 무작위로 초기화되기 때문에 PM은 pre-trained memory로 간주할 수 없으며, 단순히 모델 복잡성을 증가시키는 것은 성능 향상에 도움이 되지 않는다.
CoMPM(f)은 CoMPM과 유사한 성능을 보이며 데이터에 따라 더 나은 성능을 달성한다.
PM(f)은 데이터에 대해 fine-tuned되지 않지만 pre-trained language model에서 일반적인 pre-trained memory를 추출한다.
또한 CoMPM(k)은 IEMOCAP을 제외하고 CoM, PM 및 CoMPM(s)보다 우수한 성능을 보여주며, IEMOCAP에서 CoMPM(k)은 CoM보다 성능이 낮다.
모든 데이터 세트에 대해 CoMPM(k)은 CoMPM보다 성능이 약간 떨어진다.
즉, ConceptNet은 CoMPM의 성능을 향상시키지만 pre-trained memory만큼 효과적이지는 않다.
결과적으로, 우리는 pre-trained memory를 외부 지식과 유사한 역할을 할 수 있는 compressed knowledge으로 간주한다.
본 논문의 접근 방식 중 최고 성능은 pre-trained memory를 결합한 CoMPM 또는 CoMPM(f)이다. 구조화된 외부 데이터를 활용하지 않는 모든 시스템에서 최첨단 성능을 달성하고 외부 데이터를 활용하는 시스템을 포함하여 첫 번째 또는 두 번째 성능을 달성한다. 따라서, 우리의 접근 방식은 구조화된 외부 데이터 없이도 다른 언어로 확장될 수 있다.
4-5. Combinations of CoM and PM
본 논문은 다양한 언어 모델의 사전 훈련된 메모리의 효과를 실험한다.
PM 구조의 영향을 제거하기 위해 PM의 매개 변수를 동결하고 feature extractor 로 사용한다.
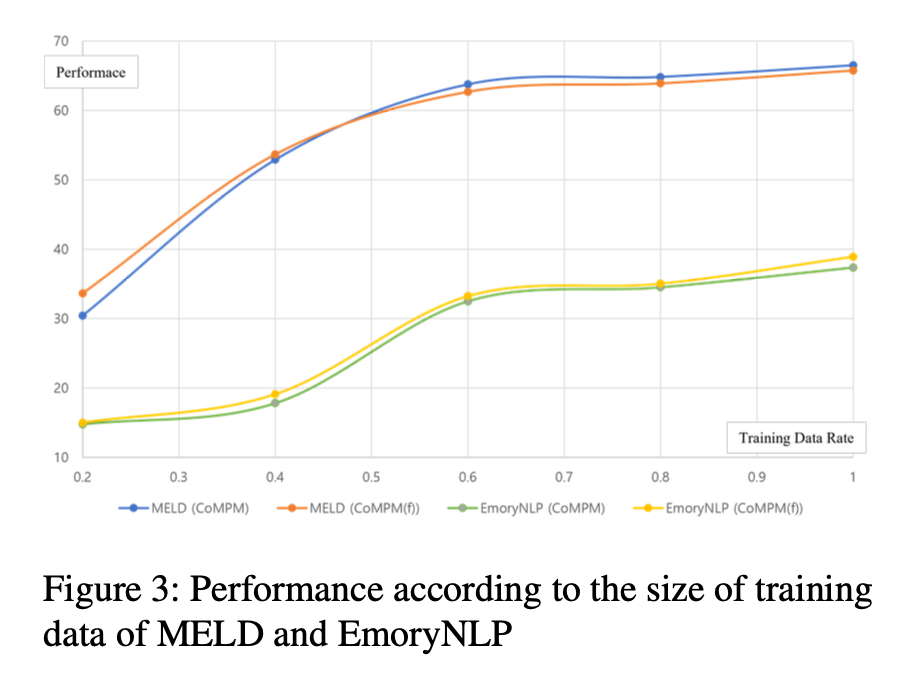
위 그림은 다양한 언어 모델에 의해 추출된 pre-trained memory의 성능을 보여준다.
PM과 CoM이 서로 다른 backbone을 기반으로 하는 경우 pre-trained memory는 context output의 dimension(차원)으로 를 통해 투영된다.
RoBERTa+BERT와 RoBERTa+GPT2(CoM과 PM(f))는 RoBERTa+RoBERTa보다 성능이 낮다.
이는 RoBERTa의 pre-trained memory가 BERT와 GPT2보다 더 다양한 정보를 포함하기 때문으로 추론된다.
diallydialog에는 많은 Train 데이터가 있고 는 pre-trained memory와 context representation을 서로 이해하기 위해 Fine-tuned 된다.
따라서 diallydialog에서 PM이 변경되더라도 성능이 감소하지 않는다고 추론한다.
그러나 다른 PM을 사용하더라도 CoM만 사용하는 것에 비해 성능이 향상되므로 다른 언어 모델의 pre-trained memory는 감정 인식에도 효과적이다.
BERT+RoBERTa는 RoBERTa+BERT보다 성능 저하가 더 크다. 특히 문맥상 평균 턴의 수가 긴 IEMOCAP 데이터에서는 성능이 크게 저하된다.
또한 BERT+RoBERTa의 성능은 CoM(RoBERTa)보다 낮으며, 이는 CoM의 성능이 pre-trained memory의 사용보다 더 중요한 요소임을 증명한다.
즉, 성능을 위해 우리의 시스템에서 CoM이 PM보다 중요하며, 대화 속 감정 인식 연구에서 external knowledge보다 context modeling에 초점을 맞추는 것이 효과적임을 증명한다.
4-6. Training with Less Data
CoMPM은 외부 소스에 대한 의존성을 제거하는 접근 방식이며 모든 언어로 쉽게 확장할 수 있지만, 다른 언어(또는 실제 서비스)에서 사용할 수 있는 감정 데이터의 수가 충분하지 않은 것이 문제로 남아 있다.
따라서 데이터가 너무 많지도 작지도 않은 MELD와 EmoryNLP에서 훈련 데이터의 사용 비율에 따라 추가 실험을 수행한다.
아래 그림은 train dataset의 비율에 따른 모델 성능을 보여준다.
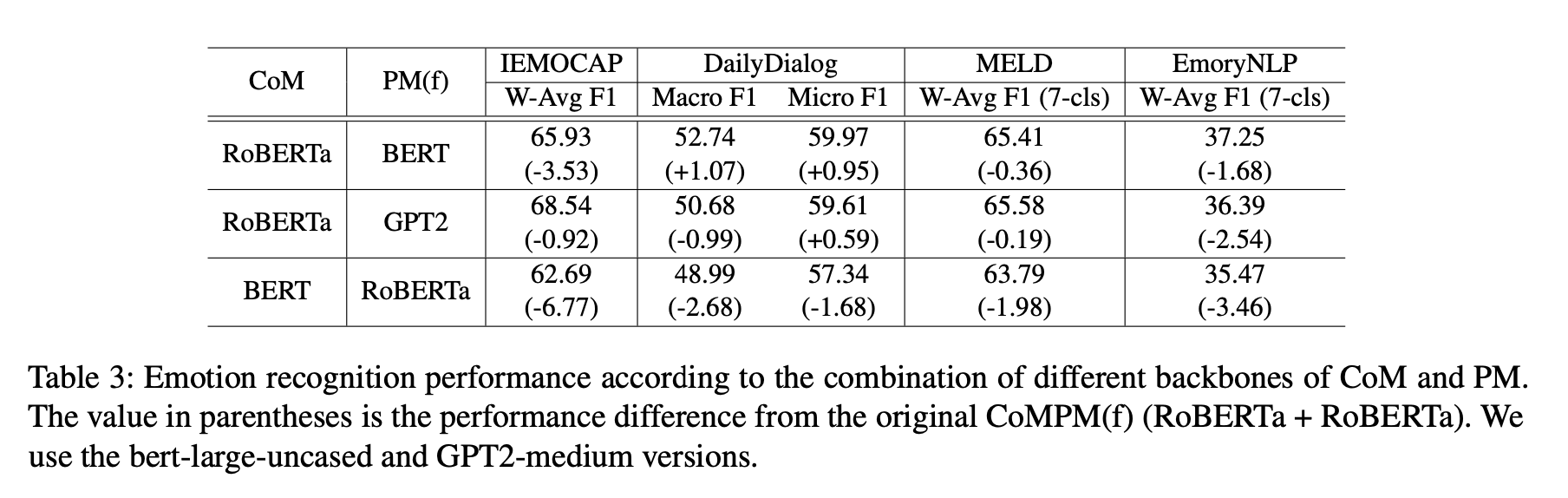
MELD와 EmoryNLP에서는 각각 60%와 80%만 사용해도 성능이 3점 감소하는 데 그쳤다.
[Table 2] 는 다른 설정보다 훈련 데이터가 적은 IMEOCAP와 EmoryNLP의 감정 분류에서 CoMPM(f)이 CoMPM보다 더 나은 성능을 달성함을 보여준다.
반면 훈련 데이터가 많으면 CoMPM이 더 나은 성능을 보여준다.
[Table 3]는 데이터의 수가 감소할수록 CoMPM(f)이 CoMPM보다 우수한 결과를 보여주며, 이는 훈련 데이터의 수가 부족할 때 PM의 파라미터를 동결하는 것이 더 성능이 좋다는 것을 나타낸다.
따라서 실제에서 훈련 데이터가 많다면 CoMPM이 좋은 성능을 보일 것이며, 반대로 적다면 CoMPM(f)이 좋은 성능을 보일 것이다.
4-7. ERC in other languages
이전 연구는 대부분 성능을 향상시키기 위해 외부 지식을 활용하지만, 이러한 접근 방식에는 publicly available data가 필요하며, 이 데이터는 주로 영어에서 사용할 수 있다.
실제로 다른 언어에서는 구조화된 지식과 ERC 데이터가 부족하다.
본 논문의 접근 방식은 추가적인 외부 지식을 구축하지 않고도 다른 언어로 확장될 수 있으며, 단순히 pre-trained model을 사용하는 것보다 더 나은 성능을 달성한다.
4-7-1. Korean Dataset
한국어로 두 명의 화자로 구성된 자료를 구성했는데, emotion-inventory은 "놀람, 두려움, 모호함, 슬프, 혐오, 기쁨, 지루, 당황, 중립"으로 구성된다.
총 세션 수는 1000회이며, 평균 발화 턴 수는 13.4회이고, 8:1:1의 비율로 무작위로 train:dev:test로 나눈 데이터를 사용한다.
이 데이터 세트는 실제 서비스를 위한 것이며 공개되지는 않는다.
4-7-2. Results in the Korean Dataset
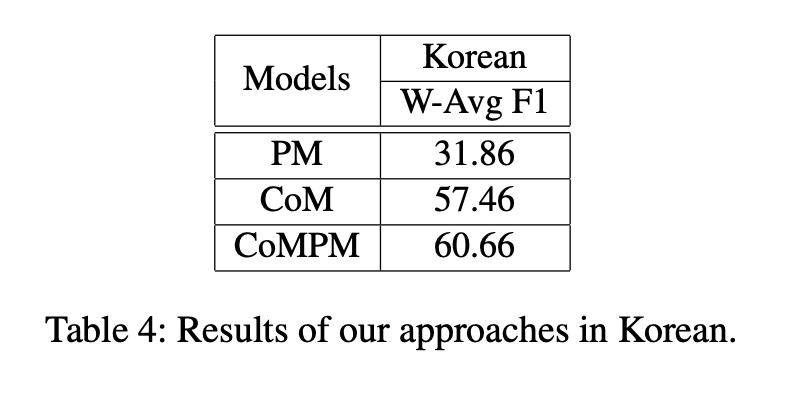
한국어의 결과는 위에 나타나 있다. CoM과 PM의 backbone은 각각 회사가 소유한 Korean-BERT이다.
한국어 데이터 세트는 영어 데이터 세트와 마찬가지로 CoMPM, CoM, PM 순으로 성능이 좋다.
우리의 접근 방식은 언어 모델에 fine-tuned되고 영어뿐만 아니라 다른 언어에서도 잘 작동하는 baselines에서 상당한 성능 향상을 보여준다.
5. Conclusion
본 논문은 pre-trained LM을 사용하여 pre-trained memory를 활용하는 CoMPM을 제안한다.
CoMPM은 context embedding module(CoM)과 pre-trained memory module(PM)로 구성되며, 실험 결과는 각 모듈이 성능 향상에 효과적임을 보여준다.
CoMPM은 dyadic-party(이진) 및 multi-party(다중) 데이터 세트 모두에서 기준선을 능가하고 external knowledge을 사용하지 않는 시스템 중에서 sota 성능을 달성한다.
또한 CoMPM은 언어 모델의 pre-trained memory의 효과인 structured external knowledge을 활용하는 최첨단 시스템에 버금가는 성능을 달성한다.
다른 pre-trained memory를 결합함으로써, 우리는 RoBERTa로 추출된 pre-trained memory가 BERT 또는 GPT2로 추출된 pre-trained memory보다 더 다양하고 효과적이라는 것을 발견했다.
pre-trained memory는 언어 모델의 성능에 비례한다고 믿기 때문에 훈련 말뭉치가 크고 매개 변수가 많은 언어 모델이 더 효과적인 것으로 간주된다.
그러나 우리는 대화에서 감정 인식을 위해 pre-trained memory보다 context modeling이 더 중요하다는 것을 발견했으며, 향후 연구는 context modeling에 초점을 맞출 것이다.
또한 본 논문의 접근 방식은 경쟁력 있는 성능을 달성하며 외부의 구조화된 데이터를 필요로 하지 않는다.
따라서 영어 뿐만 아니라 한국어에서도 쉽게 확장될 수 있다는 것을 보여주며, 다른 나라(언어)에서도 효과가 있을 것으로 기대 된다.
