Efficient Estimation of Word Representations in Vector Space(2013) 논문 읽기②
3. New Log-linear Models
이 섹션에서는 computational complexity를 최소화하면서 distributed representation을 학습하기 위한 두가지 모델 구조를 제안한다.
이전 섹션의 주요 관찰은 대부분의 복잡성이 모델의 non-linear hidden layer에 의해 발생한다는 것이었다.
본 논문은 신경망만큼 정확하게 데이터를 표현할 수 없을지도 모르지만 훨씬 더 효율적으로 데이터에 대해 훈련될 수 있는 더 간단한 모델을 탐구하기로 결정했다.
3-1. Continuous Bag-of-Words Model (CBOW)
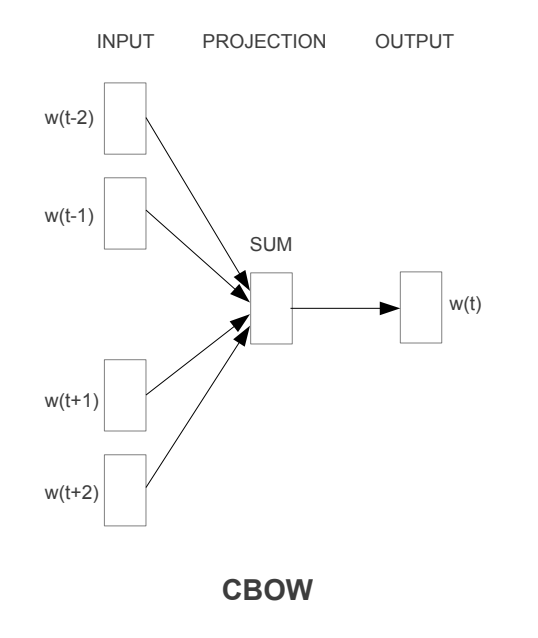
첫번째 제안된 아키텍쳐는 non-linear hidden layer가 제거되고 projection layer가 모든 단어를 위해 공유되는 feedforward NNLM과 비슷하다.
모든 단어는 동일한 위치에 projected된다(벡터는 평균화된다)
우리는 단어의 순서가 projection에 영향을 끼지치 않기 때문에 이 구조를 bag-of-word 모델이라고 부른다. 게다가, 우리는 미래로부터 단어를 사용한다.
즉, 우리는 input으로 4 future and 4 history words로 log-linear classifier을 구축하여 다음 section에서 소개할 task에서 가장 좋은 성능을 얻을 수 있었다.
훈련의 복잡도는 다음과 같다.
우리는 이 모델을 앞으로 CBOW라고 부를 것이다.
이것은 context의 continuous distributed representation를 사용한다.
input과 projection layer 사이의 가중치 매트릭스는 NNLM과 같은 방식으로 모든 단어 위치를 위해 공유된다.
3-2. Continuous Skip-gram Model
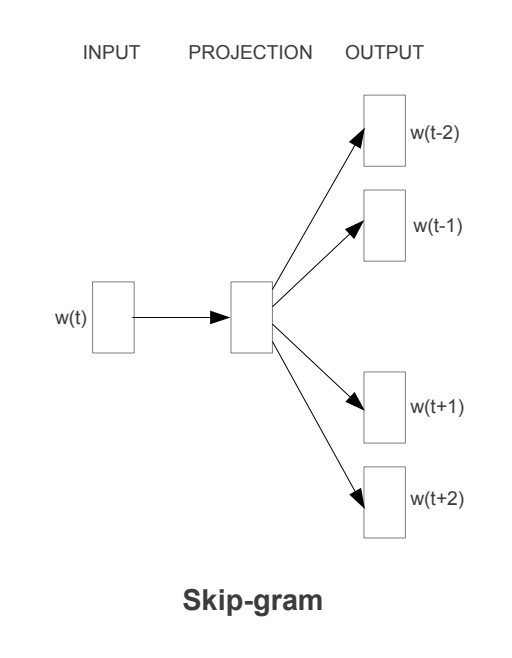
두번째 아키텍쳐는 CBOW와 비슷하지만, context에 기반해 현재 단어를 예측하는 대신에 같은 문장의 다른 단어에 기반한 단어의 분류를 극대화한다.
더 정확히 말하자면, 우리는 각 현재의 단어를 continuous projection layer와 함께 log-linear classifier에 사용하고, 현재 단어 전후의 특정 범위 내의 단어를 예측한다.
범위를 늘리면 결과 단어 벡터의 품질이 향상되지만 계산 복잡성도 증가한다는 것을 발견했다.
더 먼 단어는 일반적으로 가까운 단어보다 현재 단어와 관련이 적기 때문에, 훈련 세트에서 해당 단어에서 더 적은 샘플을 추출하여 먼 단어에 가중치를 줄였다.
훈련 복잡도는 다음과 같다.
여기서 C는 단어의 최대 거리이다.
따라서 C = 5를 선택하면 각 훈련 단어에 대해 범위가 < 1; C >인 숫자 R을 무작위로 선택한 다음 현재 단어의 미래에서 R 단어를 올바른 레이블로 사용한다.
4. Results
다른 버전의 단어 벡터의 품질을 비교하기 위해, 이전 논문들은 일반적으로 예제 단어와 가장 유사한 단어를 보여주는 표를 사용하고 직관적으로 이해한다.
비록 프랑스라는 단어가 이탈리아와 아마도 몇몇 다른 나라들과 유사하다는 것을 보여주는 것은 쉽지만, 다음과 같이 더 복잡한 유사성 과제에서 이러한 벡터들을 다루는 것은 훨씬 더 어렵다.
본 논문에서는 이러한 방식에서 한 발 더 나아가 word 사이의 상관 관계를 뽑아내 다른 word에 적용시키는 방식을 도입했다.
예를 들면 “big”-“biggest”와 유사한 상관 관계를 갖는 word를 “small”에 대해 찾아 “smallest”를 맞추는 것이다.
위 질문의 답은 대수 연산을 수행하면 된다.
vector X = vector(”biggest”)−vector(”big”) + vector(”small”)를 계산한 다음
코사인 거리로 측정된 X에 가장 가까운 단어를 벡터 공간에서 검색하여 질문에 대한 답으로 사용합니다.
단어 벡터가 잘 훈련되면 이 방법을 사용하여 정답(단어 최소값)을 찾을 수 있다.
마지막으로, 우리는 많은 양의 데이터에 대해 고차원 단어 벡터를 훈련할 때, 결과 벡터가 도시와 그것이 속한 국가와 같은 단어 사이의 매우 미묘한 의미적 관계에 대답하는 데 사용될 수 있다는 것을 발견했다.
프랑스와 파리는 독일과 베를린과 같다. 이러한 의미적 관계를 가진 단어 벡터는 기계 번역, 정보 검색 및 질문 응답 시스템과 같은 많은 기존 NLP 응용 프로그램을 개선하는 데 사용될 수 있으며, 다른 것을 가능하게 할 수 있다.
4-1. Task Description
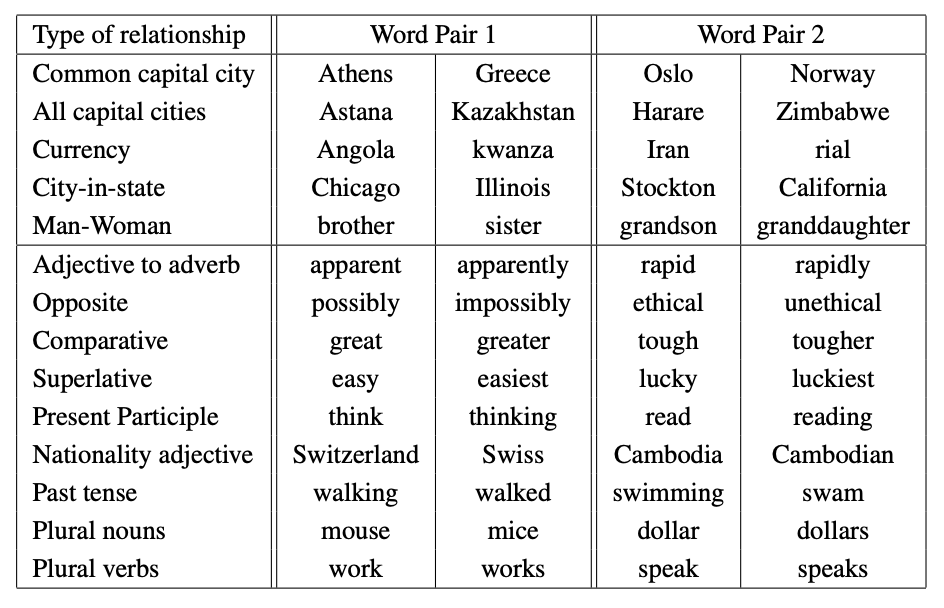
Word Vector의 품질을 측정하기 위해 5가지 유형의 의미 질문과 9가지 유형의 구문 질문을 포함하는 포괄적인 Testset을 정의한다.
각 범주의 두 가지 예는 위 이미지에 나와 있다.
전체적으로 8869개의 의미론적 문제와 10675개의 통사론적 문제가 있다.
각 범주의 질문은 두 단계로 작성되었다.
첫째, 유사한 단어 쌍의 목록이 수동으로 작성되었고, 두 단어 쌍을 연결하여 많은 질문 목록이 생성 하였다.
예를 들어, 우리는 68개의 미국 대도시와 그들이 속한 주들의 목록을 만들었고, 무작위로 두 단어 쌍을 선택하여 약 2.5K 질문을 만들었다.
우리는 우리의 테스트 세트에 오직 single token words만 포함했기 때문에 multi-word entities가 없다.
위의 방법을 사용하여 계산된 벡터에 가장 가까운 단어가 질문의 올바른 단어와 정확하게 동일한 경우에만 정답을 맞춘 것으로 가정하며 동의어는 실수(오답)로 간주 된다.
이는 또한 현재 모델에는 단어 형태에 대한 입력 정보가 없기 때문에 100% 정확도에 도달하는 것이 불가능할 가능성이 높다는 것을 의미한다.
그러나 특정 응용 프로그램에 대한 단어 벡터의 유용성은 이 정확도 메트릭과 양의 상관관계가 있어야 한다고 생각한다.
4-2. Maximization of Accuracy
우리는 단어 벡터를 훈련시키기 위해 Google News corpus를 사용했다.
이 말뭉치에는 약 6B개의 토큰이 포함되어 있다.
우리는 단어 크기를 가장 자주 사용하는 단어 100만 개로 제한했다.
최상의 model architecture 선택을 위해 먼저 모델을 평가했다.
가장 자주 사용하는 30k 단어로 제한된 어휘를 사용하여 훈련 데이터의 하위 집합에 대해 훈련되었다.
word vector dimensionality의 선택이 다르고 훈련 데이터의 양이 증가하는 CBOW 아키텍처를 사용한 결과는 아래에 나와 있다.
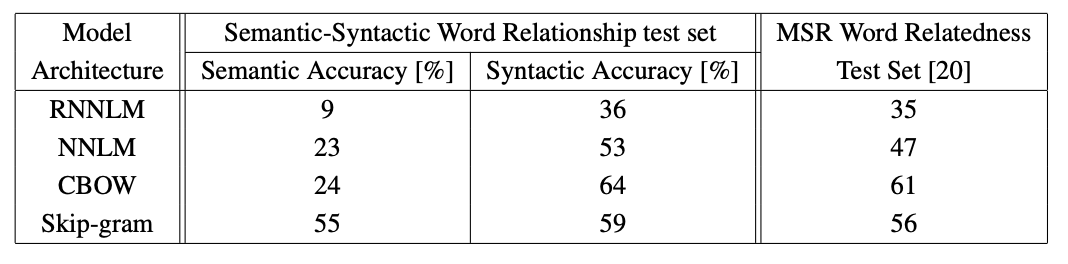
어느 시점 이후에 더 많은 차원을 추가하거나 훈련 데이터를 더 추가하면 개선 효과가 감소한다는 것을 알 수 있다.
따라서, 우리는 벡터 차원과 훈련 데이터의 양을 함께 늘려야 한다.
이러한 관찰은 사소한 것처럼 보일 수 있지만, 현재 상대적으로 많은 양의 데이터에서 단어 벡터를 훈련시키는 것이 일반적이지만 크기가 충분하지 않다는 점에 유의해야 한다(예: 50 - 100).
에서 훈련 데이터의 양을 두배로 증가시키면 벡터 크기를 두배로 증가시키는 것과 거의 동일한 계산 복잡성이 증가한다.
우리는 stochastic gradient descen(확률적 경사 하강)과 backpropagation(역전파)를 가진 세 가지 training epochs를 사용했다.
우리는 시작 learning rate 0.025를 선택하고 선형적으로 낮췄다.
마지막 training epoch이 끝날 때 0에 가까워진다고 한다.
단순히 training dataset의 크기만을 늘려가며 성능을 높이려 했지만, 많은 word가 train된다면 이에 대한 정보들을 담을 수 있는 충분한 dimension이 확보되어야 한다.
4-3. Comparison of Model Architectures
먼저 동일한 Training data를 사용하고 640개의 동일한 Dimensionality Vector를 사용하여 Word Vector를 도출하기 위해 서로 다른 Model Architecture를 비교한다.
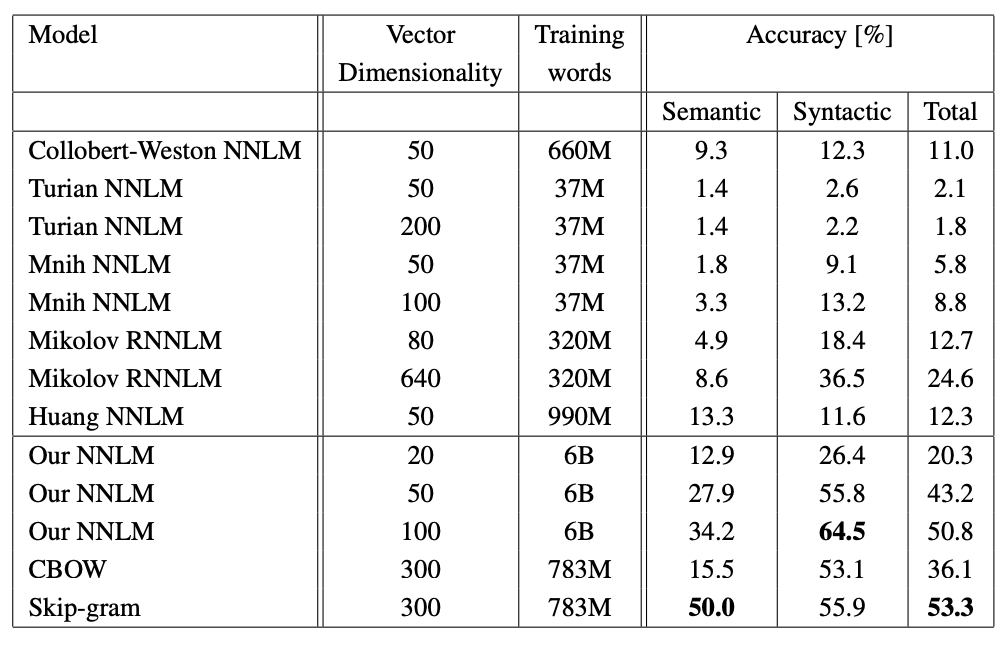
RNNLM이 가장 낮은 성능을 보였다.
CBOW와 Skip-gram은 3가지 Task(semantic, syntactic, relatedness)에서 모두 NNLM을 능가했다.
특히나 Skip-gram은 Semantic Accuracy에서 다른 model들에 비해 압도적인 모습을 보여준다.
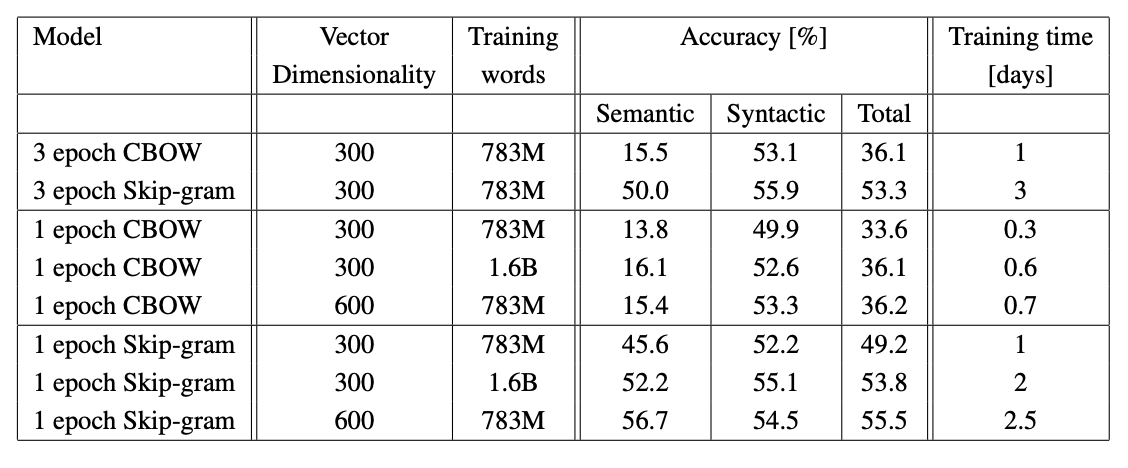
다른 여러 NNLM과 RNNLM과 비교했을 때에도 CBOW와 skip-gram은 훨씬 더 좋은 성능을 보여준다.
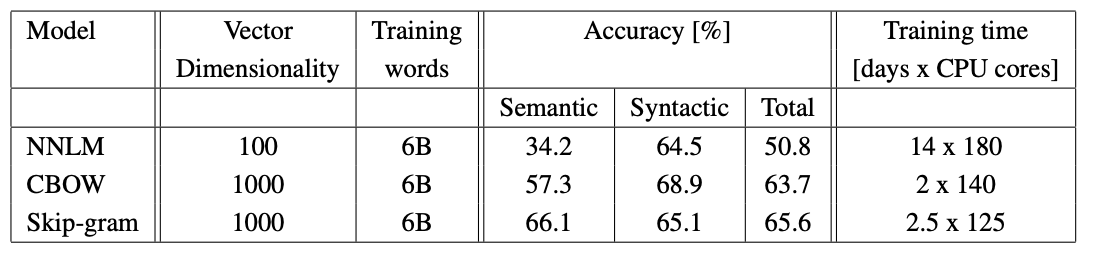
1 epoch을 사용하여 두 배의 데이터에 대해 모델을 훈련시, 동일한 데이터에 대해 3 epoch을 반복하는 것과 비교했을 때, 더 나은 결과를 얻을 수 있으며 추가적인 속도 향상을 제공한다.
4-4. Large Scale Parallel Training of Models
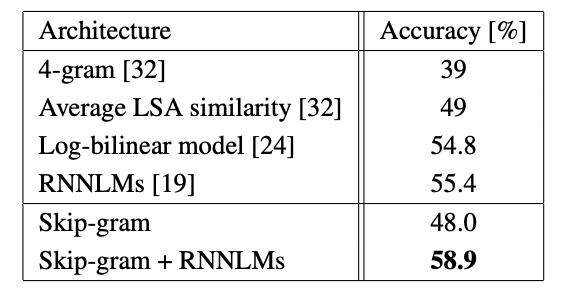
앞서 언급했듯이, 우리는 DistBelief라는 분산 프레임워크에서 다양한 모델을 구현했다.
Google News 6B 데이터 세트에서 mini-batch asynchronous gradient descent(미니 배치 비동기 그레이디언트 강하) 및 Adagrad라는 adaptive learning rate procedure(적응형 학습 속도 절차)로 훈련된 여러 모델의 결과를 보여준다.
4-5. Microsoft Research Sentence Completion Challenge
Microsoft Sentence Completion Challenge는 1040개의 문장으로 구성되며, 각 문장에서 단어 하나가 누락되고 5개의 선택 목록이 주어지면 나머지 문장과 가장 일관성 있는 단어를 예측하는 Task 이다.
skip-gram 단독일 경우에는 타 모델들에 뒤쳐졌지만, RNNLM과 결합했을 경우 SOTA성능을 보여준다.
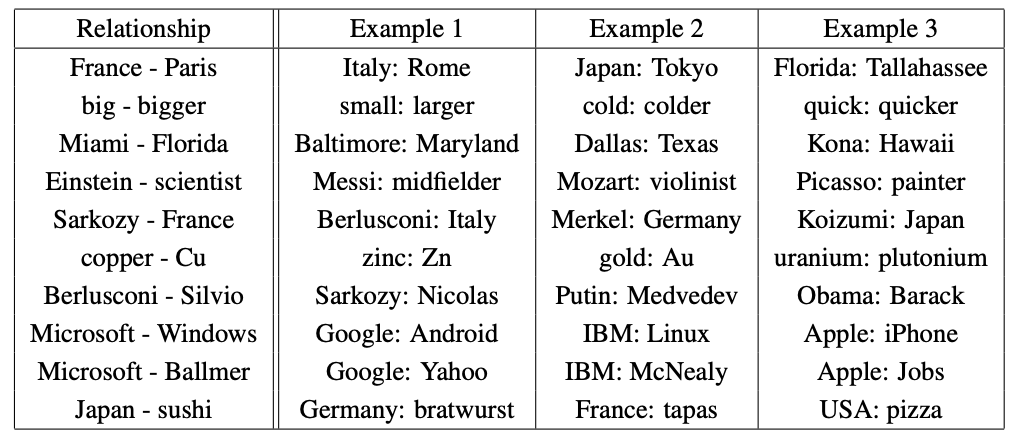
5. Examples of the Learned Relationships
위 표는 다양한 관계를 따르는 단어들을 보여준다.
관계는 두 단어 벡터를 빼서 정의되고, 그 결과는 다른 단어에 추가된다.
예를들자면, 파리 - 프랑스 + 이탈리아 = 로마로 계산이 된다.
정확도는 상당히 우수하지만, 추가적인 개선의 여지는 분명히 많다.
첫 번째, larger dimensionality을 가진 larger data에서 훈련된 단어 벡터가 훨씬 더 나은 성능을 발휘하고 새로운 혁신적인 응용 프로그램의 개발을 가능하게 할 것이라고 믿는다.
두 번째, 두 가지 이상의 예제를 제공하는 것이다.
relationship vector를 형성하기 위해 하나 대신 10개의 예시를 사용함으로써(individual vectors를 함께 평균화), semantic-syntactic test에서 정확도가 약 10% 향상되는 것을 관찰했다.
6. Conclusion
이 논문에서 우리는 통사적 및 의미론적 언어 작업의 모음에서 다양한 모델에 의해 파생된 단어의 벡터 표현 품질을 연구했다.
여러 NNLM과 비교하여 매우 간단한 모델 아키텍처를 사용하여 고품질 단어 벡터를 훈련하는 것이 가능하다는 것을 관찰했다.
더 낮은 계산 복잡성 때문에 훨씬 더 큰 데이터 세트로부터 매우 정확한 high dimensional word vectors를 계산하는 것이 가능하다.
우리의 진행 중인 연구는 Vector라는 Word가 automatic extension of facts in Knowledge Bases와 verification of correctness of existing facts에 성공적으로 적용될 수 있음을 보여준다.
기계 번역 실험의 결과 또한 매우 유망해 보인다.
향후 우리의 기술을 Latent Relational Analysis(잠재 관계 분석) 등 여러 모델과 비교하는 것도 흥미로울 것이다.
우리의 comprehensive test set가 단어 벡터를 추정하기 위한 기존 기술을 개선하는 데 도움이 될 것이라고 믿는다.
또한 고품질 단어 벡터가 향후 NLP 응용 프로그램의 중요한 구성 요소가 될 것으로 기대한다.
