Few-Shot Learning 이란?
- Few-Shot Learning이란 말 그대로 Few(적은) 데이터도 잘 분류할 수 있다는 것이다.

-
아르마딜로와 천산값을 한 번도 본 적이 없는 사람에게 왼쪽 4장을 보여준 후 오른쪽 한 장을 보여주면 대부분 오른쪽 사진을 보고 천산값이라고 응답을 할 것이다.
-
이전 딥러닝 모델의 경우 위와 같은 시도는 해볼 엄두 조차 나지 않으며, 이를 맞추기 위해서는 각 몇만장 씩의 데이터로 학습을 진행하여 할 것이다.
-
인간이 과연 어떻게 맞췄을까? 이는 바로 "구분 하는 법"을 배웠기 때문이다.
이런 구분하는 방법을 배우는 것을 Meta Learning이라고 한다. -
물론 인간도 아르마딜로와 천산갑을 비교하는 법을 배우기 위해서는 이전에 토끼, 고양이, 강아지 등 각 동물들이 다르다는 점을 배우고 시행착오를 거쳤기 때문에 구분을 할 수 있게 되는 것이다.
-
Few-Shot Learning을 위해서는 Training_set / Support_set / Query_set 3가지가 필요하다.
-
Training_set을 통해서는 "구분 하는 방법"을 배우고
-
Query_set을 통해서는 Support_set 중 어떤 것과 같은 종류인지를 맞추는 일을 하는 것이다.
-
다시말하면 Query_set을 통해서 어떤 클래스에 속하느냐의 문제를 푸는 것이 아니라 어떤 클래스와 같은 클래스냐의 문제를 푸는 것이다.
-
Transfer Learning과 다른점은?

- Transfer Learning 이나 Supervised Learning은 Test_img의 클래스가 Train_set에 포함되어 있다.
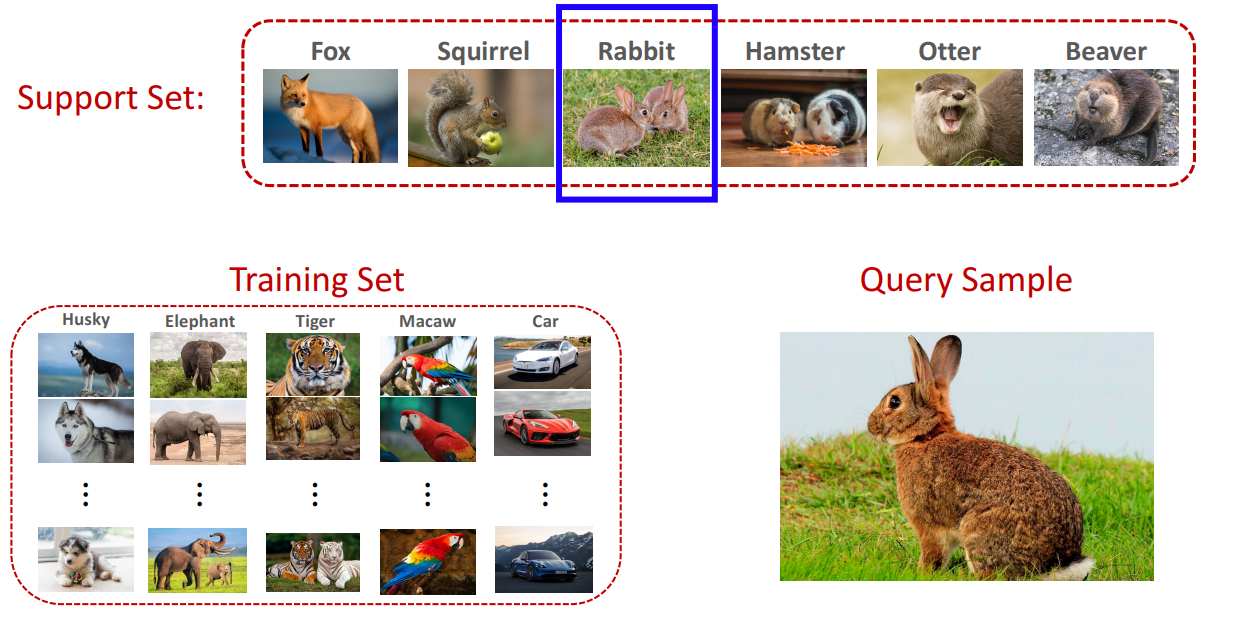
- 하지만 Few-Shot Learning은 Test_img가 Train_set에 없는 클래스를 맞추는 문제이다.
Few-Shot에서는 Support_set의 클래스 개수와 샘플 수를 k-way와 n-shot이라고 한다.
k-way는 Support_set이 k개의 클래스로 이루어져 있다는 것이고, 이는 Query_img가 k개의 클래스 중 어떤 것과 같은지 묻는 문제가 되므로 k가 클수록 모델의 정확도는 낮아지게 된다.
n-shot은 각 클래스가 가진 sample의 개수로 비교해볼 사진의 개수를 뜻하는 것으로, 비교해볼 사진이 많으면 많을 수록 어떤 클래스에 속하는지 알기 쉽기 때문에 n이 클수록 모델의 정확도는 높아지게 된다. (n = 1일 경우에는 one-shot learning이 된다.)
Prototype Network
-
few-shot learning의 방법 중 하나이며 제한된 데이터 체계에서 유익하고 단순한 유도 편향을 반영하여 우수한 결과를 달성한 방법이다
-
각 class의 Prototype Representation까지의 거리를 구해 Classification을 수행하는 metric space(거리 공간)을 학습하는 방법이다.
-
Protonet은 각 class에 대해 Single Prototype Representation이 있는 Embedding을 기본으로 접근한 방법이다.
-
이를 위해 Neural Network를 사용하여 Embedding 공간에 대한 input값의 비선형 매핑을 학습하고, Embedding 공간에서 설정된 Support_set의 평균으로 class의 Prototype을 만든다.
-
따라서 Protonet은 각 class의 Prototype 역할을 하기위해 Meta-data를 공유 공간에 Embedding 하는 것을 학습한다.
- 각 Class의 평균으로 Prototype을 만들고 유클리드 거리를 이용해서 Query Point와의 거리를 계산하고 이 거리중 가장 가까운 Prototype을 결정한 후 Query Point의 Class를 해당 Prototype의 Class로 예측하는 방식이다.

위 이미지는 - 3-Way 5-Shot의 구조
-
C1의 초록색 부분만 계산한 다고 가정할 시
X1 ~ X5 (회색 네모)는 Support set의 tensor data
-
해당 tensor data를 모델에 넣으면 Z1 ~ Z5(초록색 원)이 만들어지게 된다.
-
각각의 Z값을 모두 평균한 값이 C1 (검은색 원)이 되고 이것이 하나의 Class의 Prototype이 된다.
-
위 과정을 반복해 C1, C2, C3처럼 3가지 Class의 Prototype을 구성하게 된다.
-
이후 Query set의 data 하나를 가져와 어떤 Class에 속하는지 예측하는 경우
-
Query set의 tensor data는 Xq가 되고 Xq를 모델에 넣으면 Zq가 나오게 된다. (우측 하단 초록색 원)
-
Zq를 가지고 C1, C2, C3와 각각 유클리드 거리를 계산한 후 - 를 붙이면 유사도가 된다.
(거리가 멀수록 즉, 값이 클수록 유사도는 낮은거니까 -를 붙여주면 값이 클수록 유사도가 커지게 된다.)
이런 구조를 통해 Prototype을 구성하고 예측하는 구조이다.
